 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Permutation-Invariant and Orientation-Aware Dataset Distillation for 3D Point Clouds
Mar 28, 2025



We should collect large amount of data to train deep neural networks for various applications. Recently, the dataset distillation for images and texts has been attracting a lot of attention, that reduces the original dataset to a synthetic dataset while preserving essential task-relevant information. However, 3D point clouds distillation is almost unexplored due to the challenges of unordered structures of points. In this paper, we propose a novel distribution matching-based dataset distillation method for 3D point clouds that jointly optimizes the geometric structures of synthetic dataset as well as the orientations of synthetic models. To ensure the consistent feature alignment between different 3D point cloud models, we devise a permutation invariant distribution matching loss with the sorted feature vectors. We also employ learnable rotation angles to transform each syntheic model according to the optimal orientation best representing the original feature distribution. Extensive experimental results on widely used four benchmark datasets, including ModelNet10, ModelNet40, ShapeNet, and ScanObjectNN, demonstrate that the proposed method consistently outperforms the existing methods.
Compression of Large-Scale 3D Point Clouds Based on Joint Optimization of Point Sampling and Feature Extraction
Dec 10, 2024



Large-scale 3D point clouds (LS3DPC) obtained by LiDAR scanners require huge storage space and transmission bandwidth due to a large amount of data. The existing methods of LS3DPC compression separately perform rule-based point sampling and learnable feature extraction, and hence achieve limited compression performance. In this paper, we propose a fully end-to-end training framework for LS3DPC compression where the point sampling and the feature extraction are jointly optimized in terms of the rate and distortion losses. To this end, we first make the point sampling module to be trainable such that an optimal position of the downsampled point is estimated via aggregation with learnable weights. We also develop a reliable point reconstruction scheme that adaptively aggregates the expanded candidate points to refine the positions of upsampled points. Experimental results evaluated on the SemanticKITTI and nuScenes datasets show that the proposed method achieves significantly higher compression ratios compared with the existing state-of-the-art methods.
Lifelong Person Search
Jul 31, 2024Person search is the task to localize a query person in gallery datasets of scene images. Existing methods have been mainly developed to handle a single target dataset only, however diverse datasets are continuously given in practical applications of person search. In such cases, they suffer from the catastrophic knowledge forgetting in the old datasets when trained on new datasets. In this paper, we first introduce a novel problem of lifelong person search (LPS) where the model is incrementally trained on the new datasets while preserving the knowledge learned in the old datasets. We propose an end-to-end LPS framework that facilitates the knowledge distillation to enforce the consistency learning between the old and new models by utilizing the prototype features of the foreground persons as well as the hard background proposals in the old domains. Moreover, we also devise the rehearsal-based instance matching to further improve the discrimination ability in the old domains by using the unlabeled person instances additionally. Experimental results demonstrate that the proposed method achieves significantly superior performance of both the detection and re-identification to preserve the knowledge learned in the old domains compared with the existing methods.
Domain Generalizable Person Search Using Unreal Dataset
Mar 31, 2024Collecting and labeling real datasets to train the person search networks not only requires a lot of time and effort, but also accompanies privacy issues. The weakly-supervised and unsupervised domain adaptation methods have been proposed to alleviate the labeling burden for target datasets, however, their generalization capability is limited. We introduce a novel person search method based on the domain generalization framework, that uses an automatically labeled unreal dataset only for training but is applicable to arbitrary unseen real datasets. To alleviate the domain gaps when transferring the knowledge from the unreal source dataset to the real target datasets, we estimate the fidelity of person instances which is then used to train the end-to-end network adaptively. Moreover, we devise a domain-invariant feature learning scheme to encourage the network to suppress the domain-related features. Experimental results demonstrate that the proposed method provides the competitive performance to existing person search methods even though it is applicable to arbitrary unseen datasets without any prior knowledge and re-training burdens.
Lifelong Person Re-Identification with Backward-Compatibility
Mar 18, 2024Lifelong person re-identification (LReID) assumes a practical scenario where the model is sequentially trained on continuously incoming datasets while alleviating the catastrophic forgetting in the old datasets. However, not only the training datasets but also the gallery images are incrementally accumulated, that requires a huge amount of computational complexity and storage space to extract the features at the inference phase. In this paper, we address the above mentioned problem by incorporating the backward-compatibility to LReID for the first time. We train the model using the continuously incoming datasets while maintaining the model's compatibility toward the previously trained old models without re-computing the features of the old gallery images. To this end, we devise the cross-model compatibility loss based on the contrastive learning with respect to the replay features across all the old datasets. Moreover, we also develop the knowledge consolidation method based on the part classification to learn the shared representation across different datasets for the backward-compatibility. We suggest a more practical methodology for performance evaluation as well where all the gallery and query images are considered together. Experimental results demonstrate that the proposed method achieves a significantly higher performance of the backward-compatibility compared with the existing methods. It is a promising tool for more practical scenarios of LReID.
Context-Aware Unsupervised Clustering for Person Search
Oct 04, 2021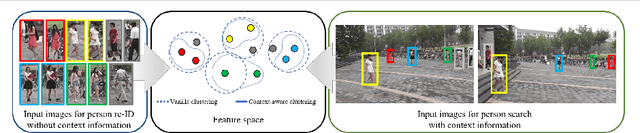
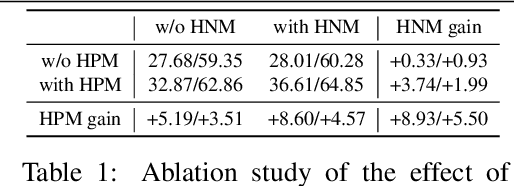
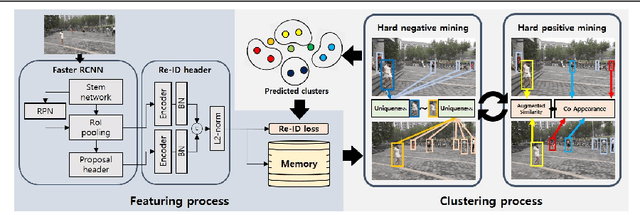
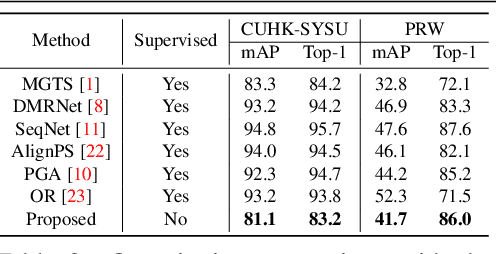
The existing person search methods use the annotated labels of person identities to train deep networks in a supervised manner that requires a huge amount of time and effort for human labeling. In this paper, we first introduce a novel framework of person search that is able to train the network in the absence of the person identity labels, and propose efficient unsupervised clustering methods to substitute the supervision process using annotated person identity labels. Specifically, we propose a hard negative mining scheme based on the uniqueness property that only a single person has the same identity to a given query person in each image. We also propose a hard positive mining scheme by using the contextual information of co-appearance that neighboring persons in one image tend to appear simultaneously in other images. The experimental results show that the proposed method achieves comparable performance to that of the state-of-the-art supervised person search methods, and furthermore outperforms the extended unsupervised person re-identification methods on the benchmark person search datasets.