 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Multi-Criteria Adversarial Detection in Deep Image Retrieval
Apr 09, 2023
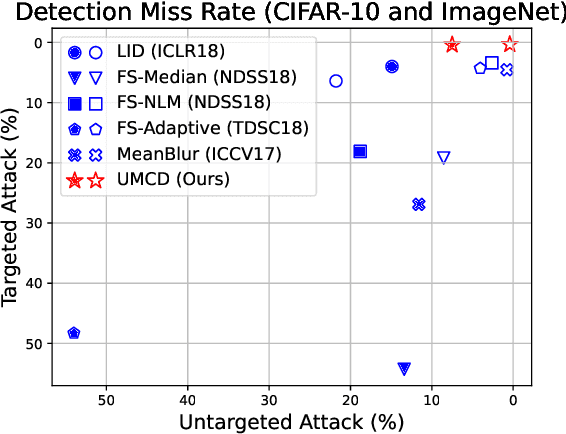
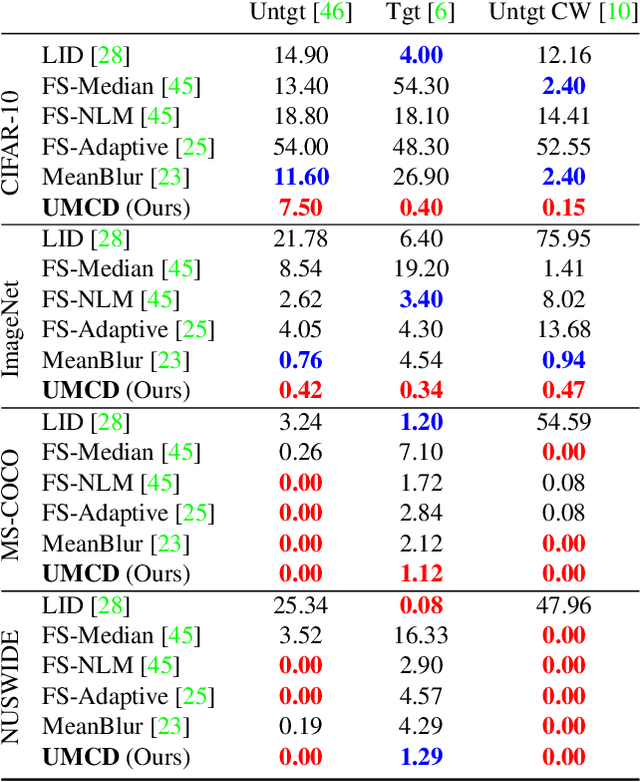
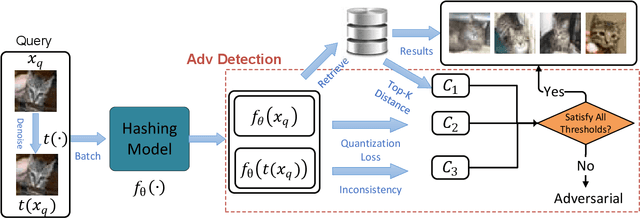
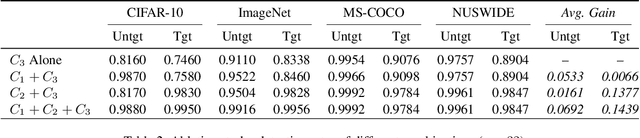
The vulnerability in the algorithm supply chain of deep learning has imposed new challenges to image retrieval systems in the downstream. Among a variety of techniques, deep hashing is gaining popularity. As it inherits the algorithmic backend from deep learning, a handful of attacks are recently proposed to disrupt normal image retrieval. Unfortunately, the defense strategies in softmax classification are not readily available to be applied in the image retrieval domain. In this paper, we propose an efficient and unsupervised scheme to identify unique adversarial behaviors in the hamming space. In particular, we design three criteria from the perspectives of hamming distance, quantization loss and denoising to defend against both untargeted and targeted attacks, which collectively limit the adversarial space. The extensive experiments on four datasets demonstrate 2-23% improvements of detection rates with minimum computational overhead for real-time image queries.
Identity Encoder for Personalized Diffusion
Apr 14, 2023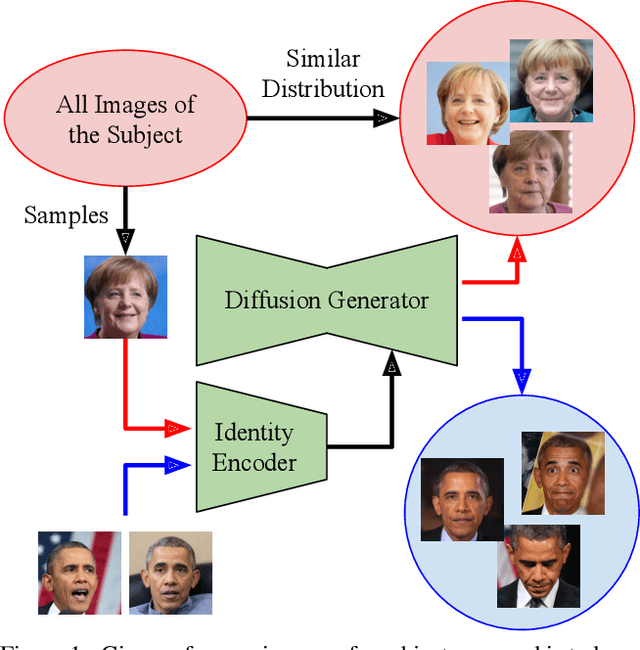
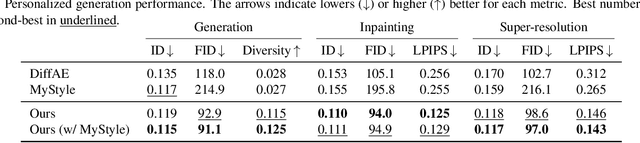
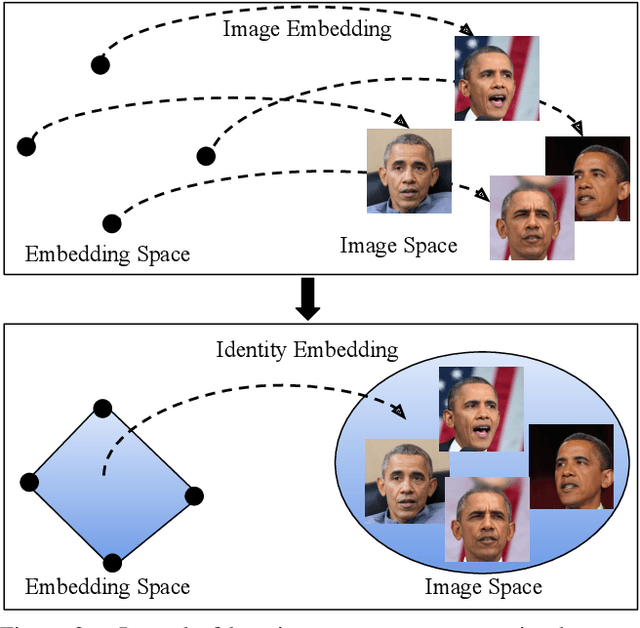
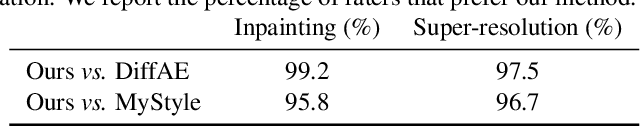
Many applications can benefit from personalized image generation models, including image enhancement, video conferences, just to name a few. Existing works achieved personalization by fine-tuning one model for each person. While being successful, this approach incurs additional computation and storage overhead for each new identity. Furthermore, it usually expects tens or hundreds of examples per identity to achieve the best performance. To overcome these challenges, we propose an encoder-based approach for personalization. We learn an identity encoder which can extract an identity representation from a set of reference images of a subject, together with a diffusion generator that can generate new images of the subject conditioned on the identity representation. Once being trained, the model can be used to generate images of arbitrary identities given a few examples even if the model hasn't been trained on the identity. Our approach greatly reduces the overhead for personalized image generation and is more applicable in many potential applications. Empirical results show that our approach consistently outperforms existing fine-tuning based approach in both image generation and reconstruction, and the outputs is preferred by users more than 95% of the time compared with the best performing baseline.
DCFace: Synthetic Face Generation with Dual Condition Diffusion Model
Apr 14, 2023

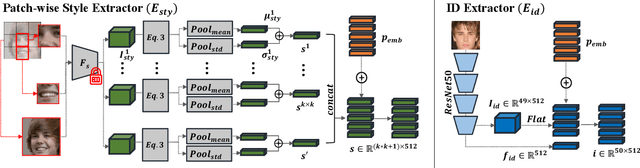
Generating synthetic datasets for training face recognition models is challenging because dataset generation entails more than creating high fidelity images. It involves generating multiple images of same subjects under different factors (\textit{e.g.}, variations in pose, illumination, expression, aging and occlusion) which follows the real image conditional distribution. Previous works have studied the generation of synthetic datasets using GAN or 3D models. In this work, we approach the problem from the aspect of combining subject appearance (ID) and external factor (style) conditions. These two conditions provide a direct way to control the inter-class and intra-class variations. To this end, we propose a Dual Condition Face Generator (DCFace) based on a diffusion model. Our novel Patch-wise style extractor and Time-step dependent ID loss enables DCFace to consistently produce face images of the same subject under different styles with precise control. Face recognition models trained on synthetic images from the proposed DCFace provide higher verification accuracies compared to previous works by $6.11\%$ on average in $4$ out of $5$ test datasets, LFW, CFP-FP, CPLFW, AgeDB and CALFW. Code is available at https://github.com/mk-minchul/dcface
Learning Dynamic Style Kernels for Artistic Style Transfer
Apr 14, 2023
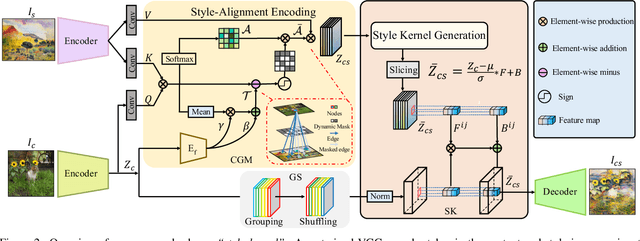


Arbitrary style transfer has been demonstrated to be efficient in artistic image generation. Previous methods either globally modulate the content feature ignoring local details, or overly focus on the local structure details leading to style leakage. In contrast to the literature, we propose a new scheme \textit{``style kernel"} that learns {\em spatially adaptive kernels} for per-pixel stylization, where the convolutional kernels are dynamically generated from the global style-content aligned feature and then the learned kernels are applied to modulate the content feature at each spatial position. This new scheme allows flexible both global and local interactions between the content and style features such that the wanted styles can be easily transferred to the content image while at the same time the content structure can be easily preserved. To further enhance the flexibility of our style transfer method, we propose a Style Alignment Encoding (SAE) module complemented with a Content-based Gating Modulation (CGM) module for learning the dynamic style kernels in focusing regions. Extensive experiments strongly demonstrate that our proposed method outperforms state-of-the-art methods and exhibits superior performance in terms of visual quality and efficiency.
Adapting Meter Tracking Models to Latin American Music
Apr 14, 2023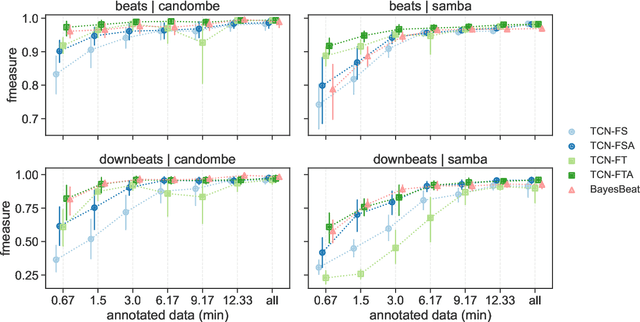

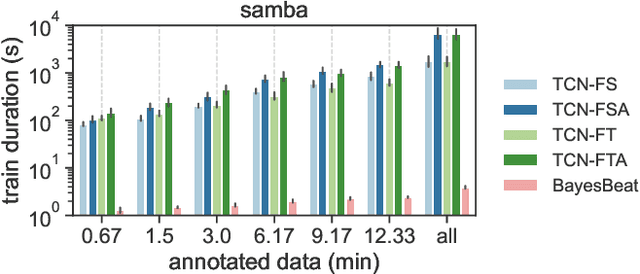
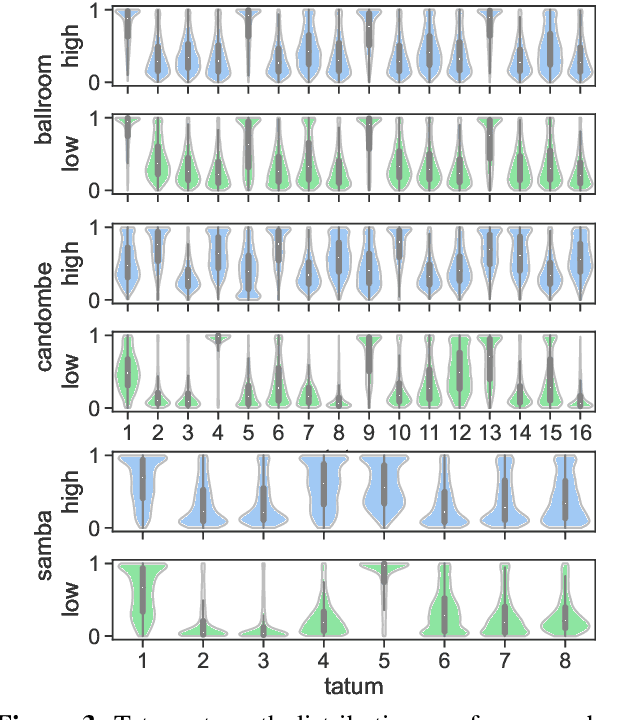
Beat and downbeat tracking models have improved significantly in recent years with the introduction of deep learning methods. However, despite these improvements, several challenges remain. Particularly, the adaptation of available models to underrepresented music traditions in MIR is usually synonymous with collecting and annotating large amounts of data, which is impractical and time-consuming. Transfer learning, data augmentation, and fine-tuning techniques have been used quite successfully in related tasks and are known to alleviate this bottleneck. Furthermore, when studying these music traditions, models are not required to generalize to multiple mainstream music genres but to perform well in more constrained, homogeneous conditions. In this work, we investigate simple yet effective strategies to adapt beat and downbeat tracking models to two different Latin American music traditions and analyze the feasibility of these adaptations in real-world applications concerning the data and computational requirements. Contrary to common belief, our findings show it is possible to achieve good performance by spending just a few minutes annotating a portion of the data and training a model in a standard CPU machine, with the precise amount of resources needed depending on the task and the complexity of the dataset.
Self-Supervised 3D Action Representation Learning with Skeleton Cloud Colorization
Apr 19, 2023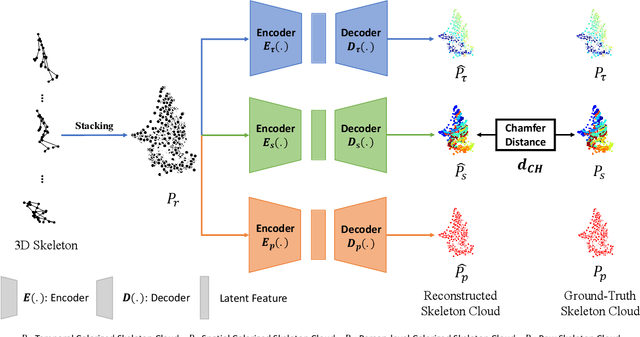

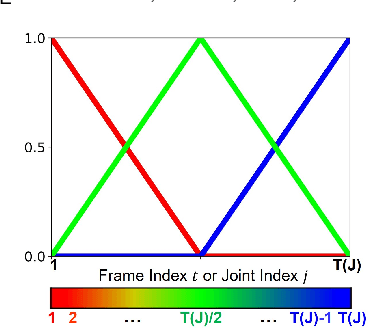

3D Skeleton-based human action recognition has attracted increasing attention in recent years. Most of the existing work focuses on supervised learning which requires a large number of labeled action sequences that are often expensive and time-consuming to annotate. In this paper, we address self-supervised 3D action representation learning for skeleton-based action recognition. We investigate self-supervised representation learning and design a novel skeleton cloud colorization technique that is capable of learning spatial and temporal skeleton representations from unlabeled skeleton sequence data. We represent a skeleton action sequence as a 3D skeleton cloud and colorize each point in the cloud according to its temporal and spatial orders in the original (unannotated) skeleton sequence. Leveraging the colorized skeleton point cloud, we design an auto-encoder framework that can learn spatial-temporal features from the artificial color labels of skeleton joints effectively. Specifically, we design a two-steam pretraining network that leverages fine-grained and coarse-grained colorization to learn multi-scale spatial-temporal features. In addition, we design a Masked Skeleton Cloud Repainting task that can pretrain the designed auto-encoder framework to learn informative representations. We evaluate our skeleton cloud colorization approach with linear classifiers trained under different configurations, including unsupervised, semi-supervised, fully-supervised, and transfer learning settings. Extensive experiments on NTU RGB+D, NTU RGB+D 120, PKU-MMD, NW-UCLA, and UWA3D datasets show that the proposed method outperforms existing unsupervised and semi-supervised 3D action recognition methods by large margins and achieves competitive performance in supervised 3D action recognition as well.
Connection-Based Scheduling for Real-Time Intersection Control
Oct 16, 2022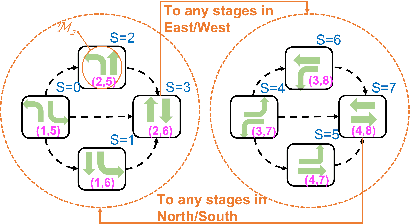
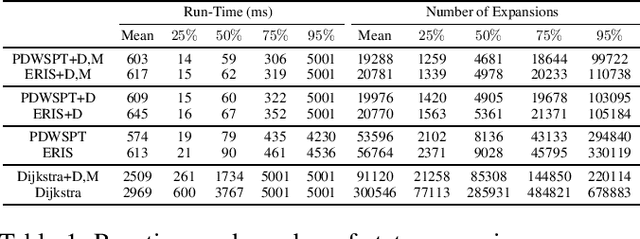
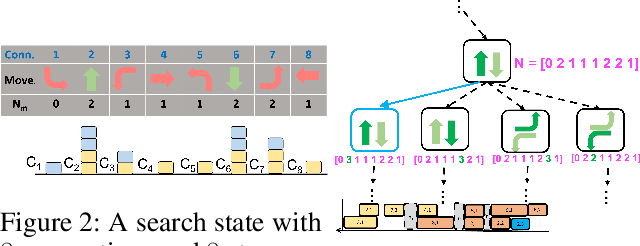
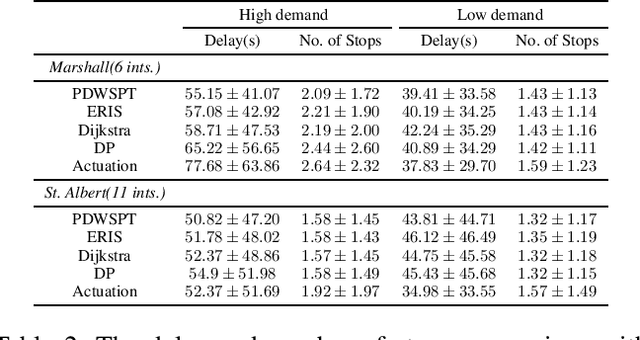
We introduce a heuristic scheduling algorithm for real-time adaptive traffic signal control to reduce traffic congestion. This algorithm adopts a lane-based model that estimates the arrival time of all vehicles approaching an intersection through different lanes, and then computes a schedule (i.e., a signal timing plan) that minimizes the cumulative delay incurred by all approaching vehicles. State space, pruning checks and an admissible heuristic for A* search are described and shown to be capable of generating an intersection schedule in real-time (i.e., every second). Due to the effectiveness of the heuristics, the proposed approach outperforms a less expressive Dynamic Programming approach and previous A*-based approaches in run-time performance, both in simulated test environments and actual field tests.
DDT: A Diffusion-Driven Transformer-based Framework for Human Mesh Recovery from a Video
Mar 29, 2023

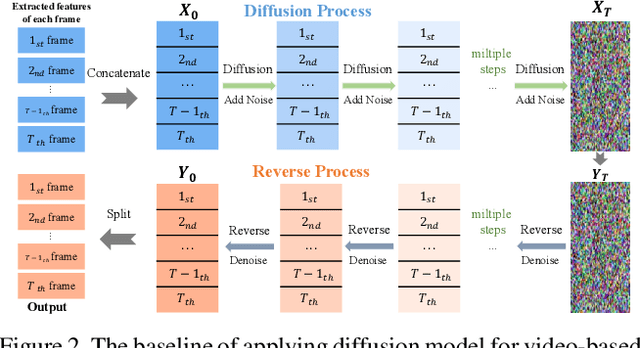
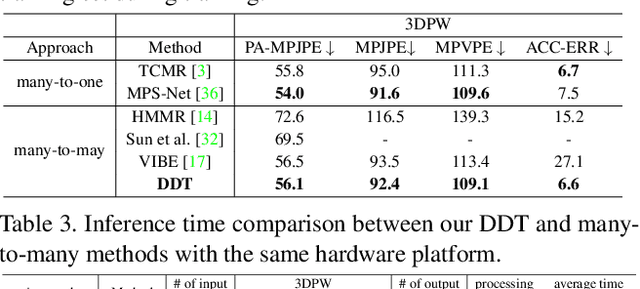
Human mesh recovery (HMR) provides rich human body information for various real-world applications such as gaming, human-computer interaction, and virtual reality. Compared to single image-based methods, video-based methods can utilize temporal information to further improve performance by incorporating human body motion priors. However, many-to-many approaches such as VIBE suffer from motion smoothness and temporal inconsistency. While many-to-one approaches such as TCMR and MPS-Net rely on the future frames, which is non-causal and time inefficient during inference. To address these challenges, a novel Diffusion-Driven Transformer-based framework (DDT) for video-based HMR is presented. DDT is designed to decode specific motion patterns from the input sequence, enhancing motion smoothness and temporal consistency. As a many-to-many approach, the decoder of our DDT outputs the human mesh of all the frames, making DDT more viable for real-world applications where time efficiency is crucial and a causal model is desired. Extensive experiments are conducted on the widely used datasets (Human3.6M, MPI-INF-3DHP, and 3DPW), which demonstrated the effectiveness and efficiency of our DDT.
AVFormer: Injecting Vision into Frozen Speech Models for Zero-Shot AV-ASR
Mar 29, 2023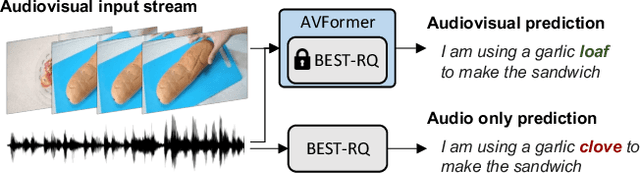
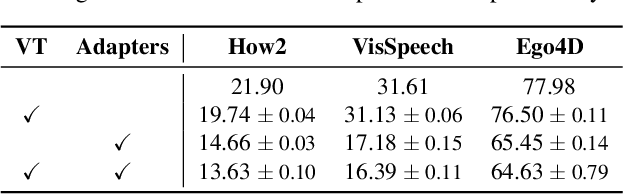
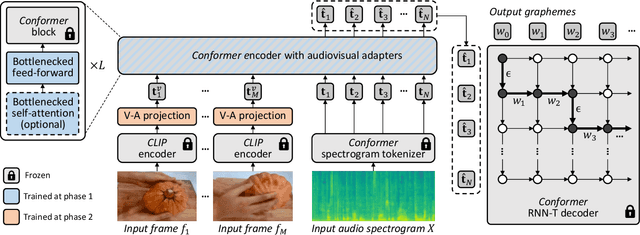

Audiovisual automatic speech recognition (AV-ASR) aims to improve the robustness of a speech recognition system by incorporating visual information. Training fully supervised multimodal models for this task from scratch, however is limited by the need for large labelled audiovisual datasets (in each downstream domain of interest). We present AVFormer, a simple method for augmenting audio-only models with visual information, at the same time performing lightweight domain adaptation. We do this by (i) injecting visual embeddings into a frozen ASR model using lightweight trainable adaptors. We show that these can be trained on a small amount of weakly labelled video data with minimum additional training time and parameters. (ii) We also introduce a simple curriculum scheme during training which we show is crucial to enable the model to jointly process audio and visual information effectively; and finally (iii) we show that our model achieves state of the art zero-shot results on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (LibriSpeech). Qualitative results show that our model effectively leverages visual information for robust speech recognition.
FindVehicle and VehicleFinder: A NER dataset for natural language-based vehicle retrieval and a keyword-based cross-modal vehicle retrieval system
Apr 21, 2023
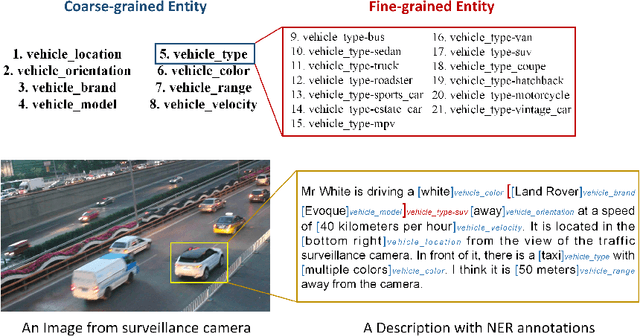
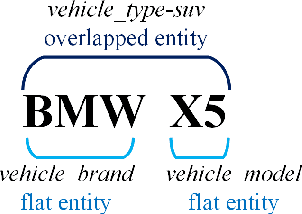
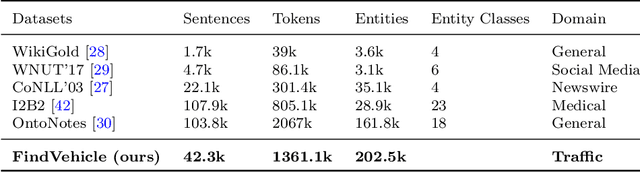
Natural language (NL) based vehicle retrieval is a task aiming to retrieve a vehicle that is most consistent with a given NL query from among all candidate vehicles. Because NL query can be easily obtained, such a task has a promising prospect in building an interactive intelligent traffic system (ITS). Current solutions mainly focus on extracting both text and image features and mapping them to the same latent space to compare the similarity. However, existing methods usually use dependency analysis or semantic role-labelling techniques to find keywords related to vehicle attributes. These techniques may require a lot of pre-processing and post-processing work, and also suffer from extracting the wrong keyword when the NL query is complex. To tackle these problems and simplify, we borrow the idea from named entity recognition (NER) and construct FindVehicle, a NER dataset in the traffic domain. It has 42.3k labelled NL descriptions of vehicle tracks, containing information such as the location, orientation, type and colour of the vehicle. FindVehicle also adopts both overlapping entities and fine-grained entities to meet further requirements. To verify its effectiveness, we propose a baseline NL-based vehicle retrieval model called VehicleFinder. Our experiment shows that by using text encoders pre-trained by FindVehicle, VehicleFinder achieves 87.7\% precision and 89.4\% recall when retrieving a target vehicle by text command on our homemade dataset based on UA-DETRAC. The time cost of VehicleFinder is 279.35 ms on one ARM v8.2 CPU and 93.72 ms on one RTX A4000 GPU, which is much faster than the Transformer-based system. The dataset is open-source via the link https://github.com/GuanRunwei/FindVehicle, and the implementation can be found via the link https://github.com/GuanRunwei/VehicleFinder-CTIM.