 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-TTT: Efficient and Expressive Visual Representation Learning with Test-Time Training
Feb 28, 2026Learning efficient and expressive visual representation has long been the pursuit of computer vision research. While Vision Transformers (ViTs) gradually replace traditional Convolutional Neural Networks (CNNs) as more scalable vision learners, their applications are plagued by the quadratic complexity of the self-attention mechanism. To address the challenge, we introduce a new linear-time sequence modeling method Test-Time Training (TTT) into vision and propose Vision-TTT, which compresses the visual token sequence in a novel self-supervised learning manner. By incorporating bidirectional scan strategy and the Conv2d module, Vision-TTT effectively extends vanilla TTT to model 2D visual correlations with global receptive fields. Extensive experiments show that \texttt{Vittt-T/S/B} achieve 77.3%,81.2%,82.5% Top-1 accuracy on ImageNet classification and also greatly outperform their counterparts on downstream tasks. At 1280x1280 resolution, \texttt{Vittt-T} reduces FLOPs by 79.4% and runs 4.38x faster with 88.9% less memory than DeiT-T. These results demonstrate the expressiveness and efficiency of Vision-TTT as a strong candidate for the next-generation generic visual backbone.
Unsupervised Multi-Criteria Adversarial Detection in Deep Image Retrieval
Apr 09, 2023The vulnerability in the algorithm supply chain of deep learning has imposed new challenges to image retrieval systems in the downstream. Among a variety of techniques, deep hashing is gaining popularity. As it inherits the algorithmic backend from deep learning, a handful of attacks are recently proposed to disrupt normal image retrieval. Unfortunately, the defense strategies in softmax classification are not readily available to be applied in the image retrieval domain. In this paper, we propose an efficient and unsupervised scheme to identify unique adversarial behaviors in the hamming space. In particular, we design three criteria from the perspectives of hamming distance, quantization loss and denoising to defend against both untargeted and targeted attacks, which collectively limit the adversarial space. The extensive experiments on four datasets demonstrate 2-23% improvements of detection rates with minimum computational overhead for real-time image queries.
Explore Training of Deep Convolutional Neural Networks on Battery-powered Mobile Devices: Design and Application
May 26, 2020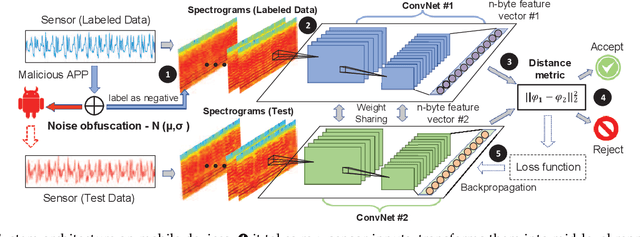
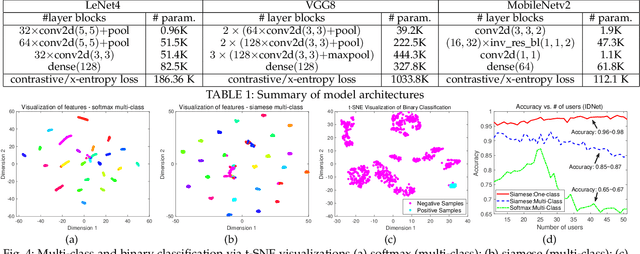
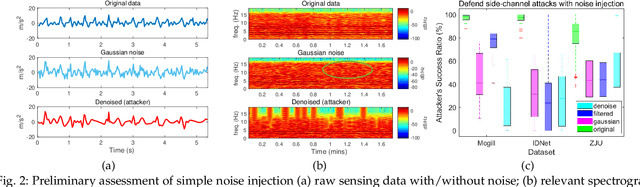
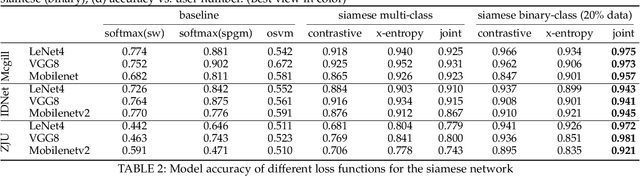
The fast-growing smart applications on mobile devices leverage pre-trained deep learning models for inference. However, the models are usually not updated thereafter. This leaves a big gap to adapt the new data distributions. In this paper, we take a step further to incorporate training deep neural networks on battery-powered mobile devices. We identify several challenges from performance and privacy that hinder effective learning in a dynamic mobile environment. We re-formulate the problem as metric learning to tackle overfitting and enlarge sample space via data paring under the memory constraints. We also make the scheme robust against side-channel attacks and run-time fluctuations. A case study based on deep behavioral authentication is conducted. The experiments demonstrate accuracy over 95% on three public datasets, a sheer 15% gain from multi-class classification with less data and robustness against brute-force and side-channel attacks with 99% and 90% success, respectively. We show the feasibility of training with mobile CPUs, where training 100 epochs takes less than 10 mins and can be boosted 3-5 times with feature transfer. Finally, we profile memory, energy and computational overhead. Our results indicate that training consumes lower energy than watching videos and slightly higher energy than playing games.