 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robotic Ultrasound Imaging: State-of-the-Art and Future Perspectives
Jul 08, 2023
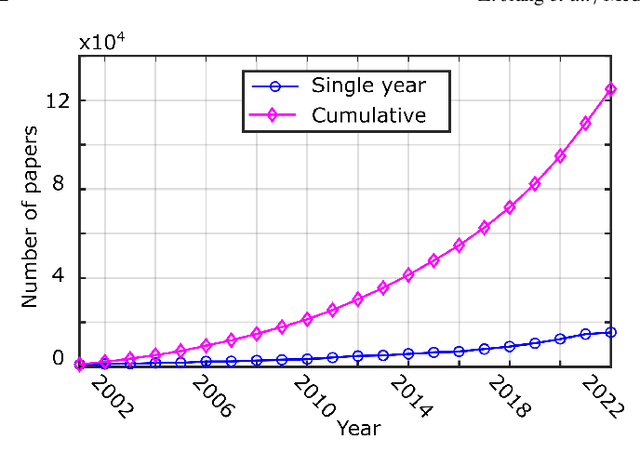
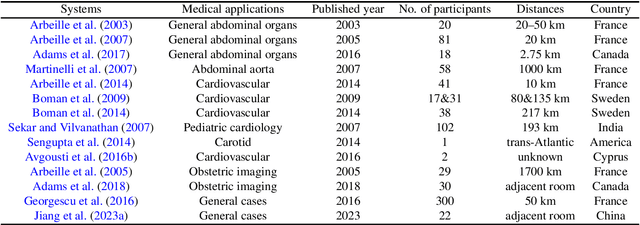
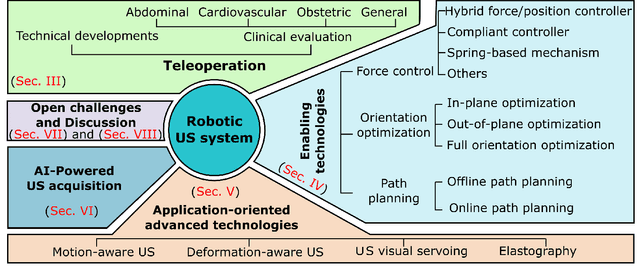
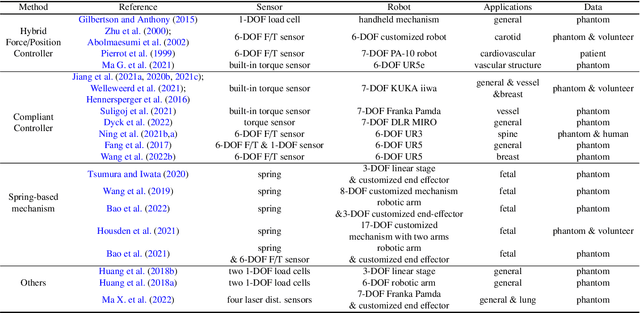
Ultrasound (US) is one of the most widely used modalities for clinical intervention and diagnosis due to the merits of providing non-invasive, radiation-free, and real-time images. However, free-hand US examinations are highly operator-dependent. Robotic US System (RUSS) aims at overcoming this shortcoming by offering reproducibility, while also aiming at improving dexterity, and intelligent anatomy and disease-aware imaging. In addition to enhancing diagnostic outcomes, RUSS also holds the potential to provide medical interventions for populations suffering from the shortage of experienced sonographers. In this paper, we categorize RUSS as teleoperated or autonomous. Regarding teleoperated RUSS, we summarize their technical developments, and clinical evaluations, respectively. This survey then focuses on the review of recent work on autonomous robotic US imaging. We demonstrate that machine learning and artificial intelligence present the key techniques, which enable intelligent patient and process-specific, motion and deformation-aware robotic image acquisition. We also show that the research on artificial intelligence for autonomous RUSS has directed the research community toward understanding and modeling expert sonographers' semantic reasoning and action. Here, we call this process, the recovery of the "language of sonography". This side result of research on autonomous robotic US acquisitions could be considered as valuable and essential as the progress made in the robotic US examination itself. This article will provide both engineers and clinicians with a comprehensive understanding of RUSS by surveying underlying techniques.
VS-TransGRU: A Novel Transformer-GRU-based Framework Enhanced by Visual-Semantic Fusion for Egocentric Action Anticipation
Jul 08, 2023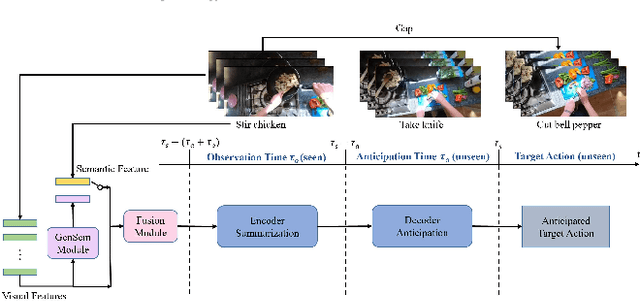
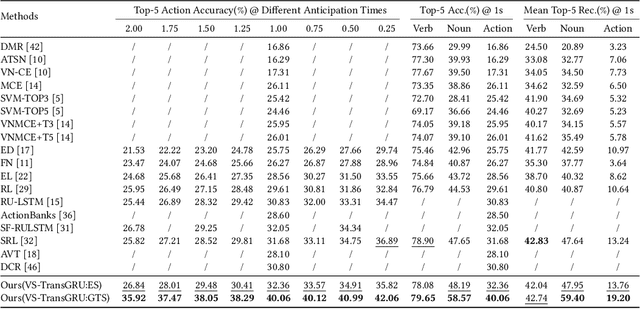

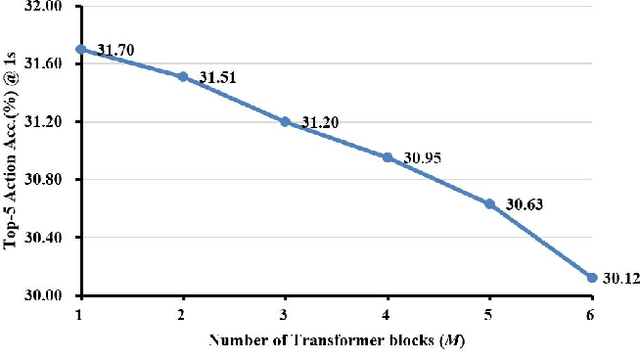
Egocentric action anticipation is a challenging task that aims to make advanced predictions of future actions from current and historical observations in the first-person view. Most existing methods focus on improving the model architecture and loss function based on the visual input and recurrent neural network to boost the anticipation performance. However, these methods, which merely consider visual information and rely on a single network architecture, gradually reach a performance plateau. In order to fully understand what has been observed and capture the dependencies between current observations and future actions well enough, we propose a novel visual-semantic fusion enhanced and Transformer GRU-based action anticipation framework in this paper. Firstly, high-level semantic information is introduced to improve the performance of action anticipation for the first time. We propose to use the semantic features generated based on the class labels or directly from the visual observations to augment the original visual features. Secondly, an effective visual-semantic fusion module is proposed to make up for the semantic gap and fully utilize the complementarity of different modalities. Thirdly, to take advantage of both the parallel and autoregressive models, we design a Transformer based encoder for long-term sequential modeling and a GRU-based decoder for flexible iteration decoding. Extensive experiments on two large-scale first-person view datasets, i.e., EPIC-Kitchens and EGTEA Gaze+, validate the effectiveness of our proposed method, which achieves new state-of-the-art performance, outperforming previous approaches by a large margin.
Intelligent Robotic Sonographer: Mutual Information-based Disentangled Reward Learning from Few Demonstrations
Jul 07, 2023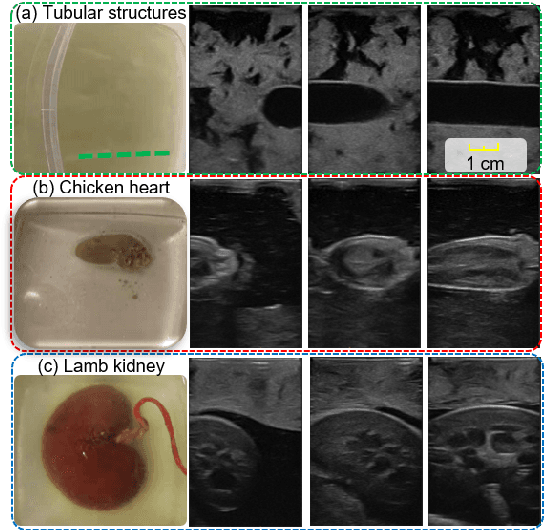
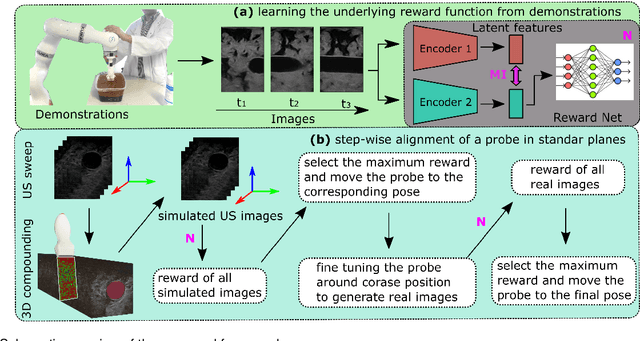
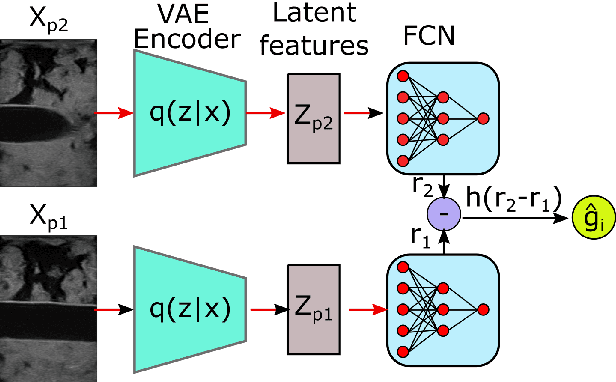
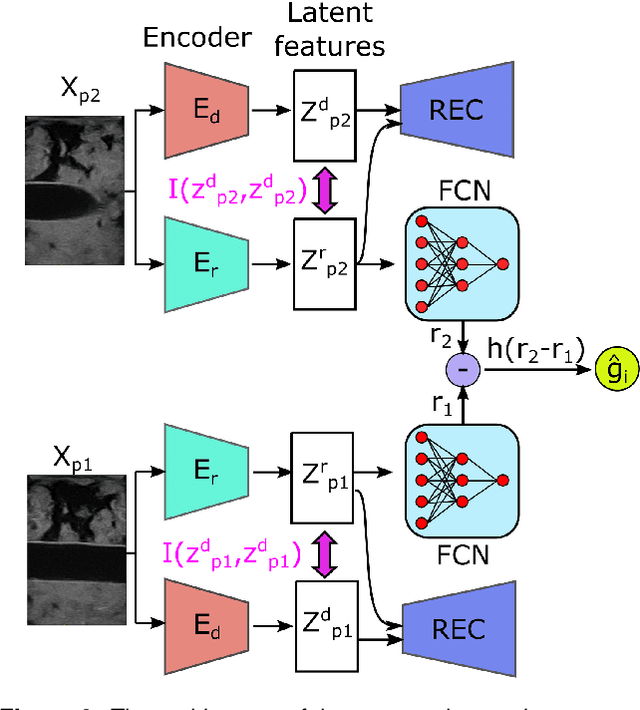
Ultrasound (US) imaging is widely used for biometric measurement and diagnosis of internal organs due to the advantages of being real-time and radiation-free. However, due to high inter-operator variability, resulting images highly depend on operators' experience. In this work, an intelligent robotic sonographer is proposed to autonomously "explore" target anatomies and navigate a US probe to a relevant 2D plane by learning from expert. The underlying high-level physiological knowledge from experts is inferred by a neural reward function, using a ranked pairwise image comparisons approach in a self-supervised fashion. This process can be referred to as understanding the "language of sonography". Considering the generalization capability to overcome inter-patient variations, mutual information is estimated by a network to explicitly extract the task-related and domain features in latent space. Besides, a Gaussian distribution-based filter is developed to automatically evaluate and take the quality of the expert's demonstrations into account. The robotic localization is carried out in coarse-to-fine mode based on the predicted reward associated to B-mode images. To demonstrate the performance of the proposed approach, representative experiments for the "line" target and "point" target are performed on vascular phantom and two ex-vivo animal organ phantoms (chicken heart and lamb kidney), respectively. The results demonstrated that the proposed advanced framework can robustly work on different kinds of known and unseen phantoms.
TimeMAE: Self-Supervised Representations of Time Series with Decoupled Masked Autoencoders
Mar 14, 2023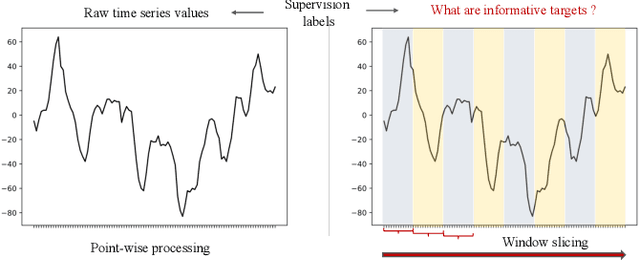

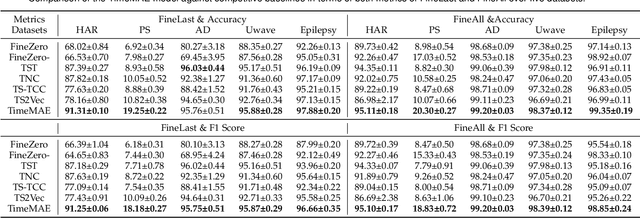
Enhancing the expressive capacity of deep learning-based time series models with self-supervised pre-training has become ever-increasingly prevalent in time series classification. Even though numerous efforts have been devoted to developing self-supervised models for time series data, we argue that the current methods are not sufficient to learn optimal time series representations due to solely unidirectional encoding over sparse point-wise input units. In this work, we propose TimeMAE, a novel self-supervised paradigm for learning transferrable time series representations based on transformer networks. The distinct characteristics of the TimeMAE lie in processing each time series into a sequence of non-overlapping sub-series via window-slicing partitioning, followed by random masking strategies over the semantic units of localized sub-series. Such a simple yet effective setting can help us achieve the goal of killing three birds with one stone, i.e., (1) learning enriched contextual representations of time series with a bidirectional encoding scheme; (2) increasing the information density of basic semantic units; (3) efficiently encoding representations of time series using transformer networks. Nevertheless, it is a non-trivial to perform reconstructing task over such a novel formulated modeling paradigm. To solve the discrepancy issue incurred by newly injected masked embeddings, we design a decoupled autoencoder architecture, which learns the representations of visible (unmasked) positions and masked ones with two different encoder modules, respectively. Furthermore, we construct two types of informative targets to accomplish the corresponding pretext tasks. One is to create a tokenizer module that assigns a codeword to each masked region, allowing the masked codeword classification (MCC) task to be completed effectively...
Balanced Filtering via Non-Disclosive Proxies
Jul 05, 2023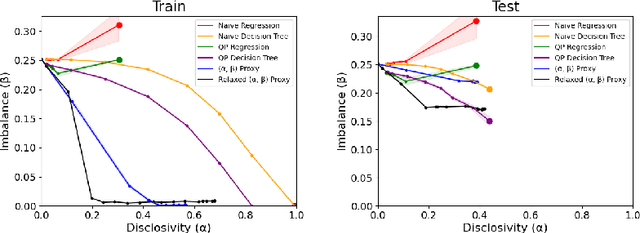
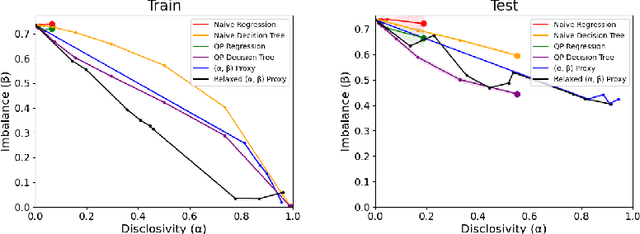
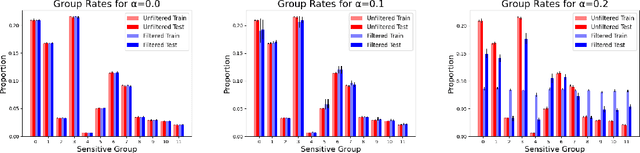
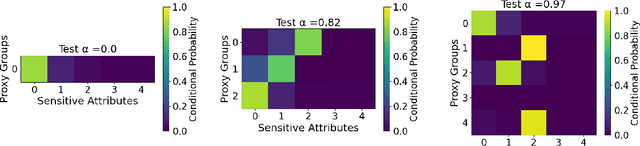
We study the problem of non-disclosively collecting a sample of data that is balanced with respect to sensitive groups when group membership is unavailable or prohibited from use at collection time. Specifically, our collection mechanism does not reveal significantly more about group membership of any individual sample than can be ascertained from base rates alone. To do this, we adopt a fairness pipeline perspective, in which a learner can use a small set of labeled data to train a proxy function that can later be used for this filtering task. We then associate the range of the proxy function with sampling probabilities; given a new candidate, we classify it using our proxy function, and then select it for our sample with probability proportional to the sampling probability corresponding to its proxy classification. Importantly, we require that the proxy classification itself not reveal significant information about the sensitive group membership of any individual sample (i.e., it should be sufficiently non-disclosive). We show that under modest algorithmic assumptions, we find such a proxy in a sample- and oracle-efficient manner. Finally, we experimentally evaluate our algorithm and analyze generalization properties.
Bidirectional Temporal Diffusion Model for Temporally Consistent Human Animation
Jul 02, 2023
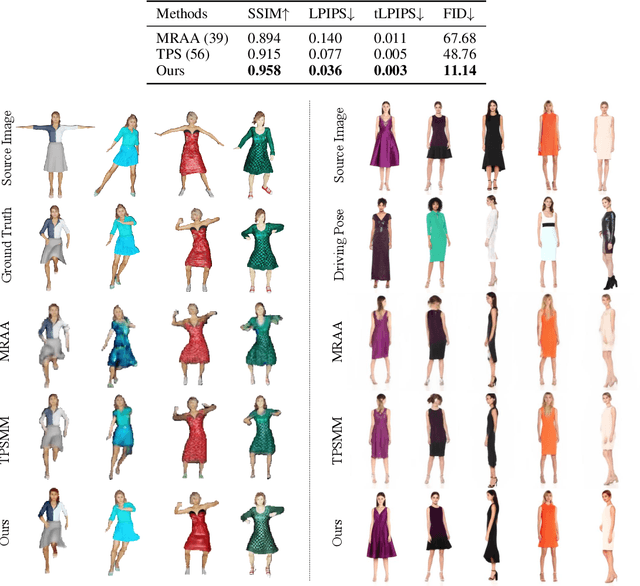
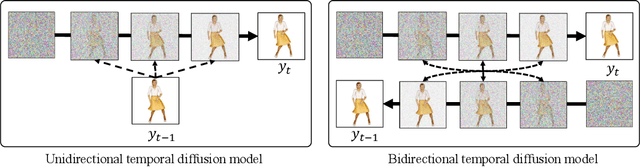
We introduce a method to generate temporally coherent human animation from a single image, a video, or a random noise. This problem has been formulated as modeling of an auto-regressive generation, i.e., to regress past frames to decode future frames. However, such unidirectional generation is highly prone to motion drifting over time, generating unrealistic human animation with significant artifacts such as appearance distortion. We claim that bidirectional temporal modeling enforces temporal coherence on a generative network by largely suppressing the motion ambiguity of human appearance. To prove our claim, we design a novel human animation framework using a denoising diffusion model: a neural network learns to generate the image of a person by denoising temporal Gaussian noises whose intermediate results are cross-conditioned bidirectionally between consecutive frames. In the experiments, our method demonstrates strong performance compared to existing unidirectional approaches with realistic temporal coherence
Reducing Uncertainties of a Chained Hydrologic-hydraulic Model to Improve Flood Forecasting Using Multi-source Earth Observation Data
Jun 14, 2023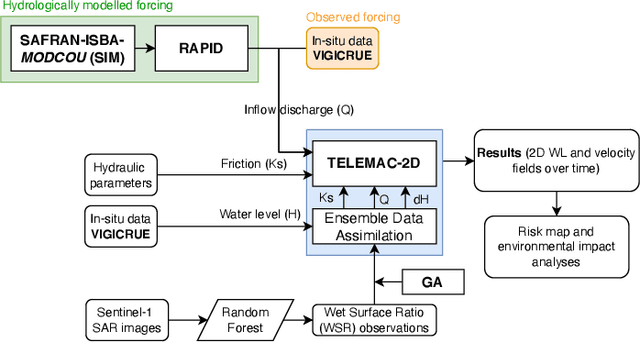
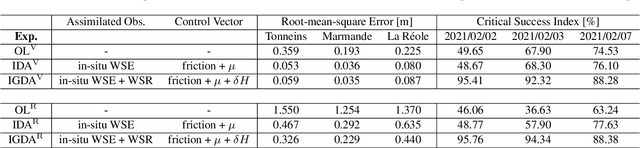
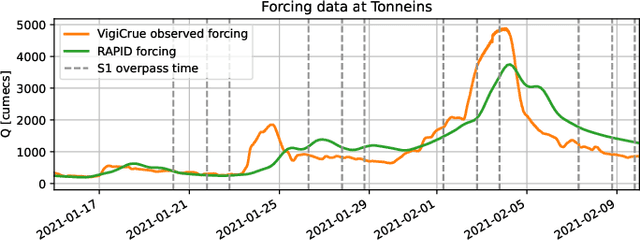
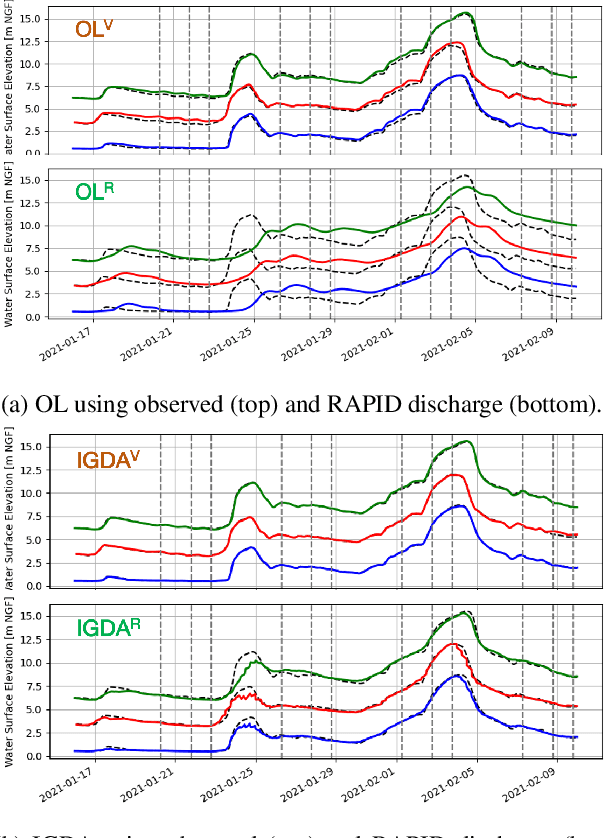
The challenges in operational flood forecasting lie in producing reliable forecasts given constrained computational resources and within processing times that are compatible with near-real-time forecasting. Flood hydrodynamic models exploit observed data from gauge networks, e.g. water surface elevation (WSE) and/or discharge that describe the forcing time-series at the upstream and lateral boundary conditions of the model. A chained hydrologic-hydraulic model is thus interesting to allow extended lead time forecasts and overcome the limits of forecast when using only observed gauge measurements. This research work focuses on comprehensively reducing the uncertainties in the model parameters, hydraulic state and especially the forcing data in order to improve the overall flood reanalysis and forecast performance. It aims at assimilating two main complementary EO data sources, namely in-situ WSE and SAR-derived flood extent observations.
SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks
Jul 06, 2023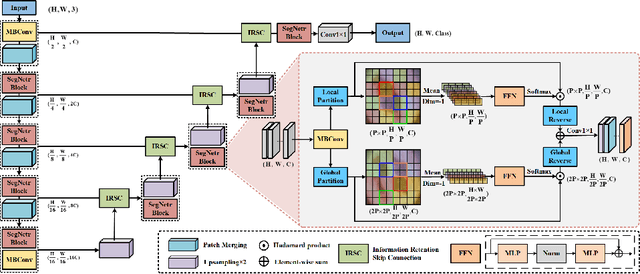
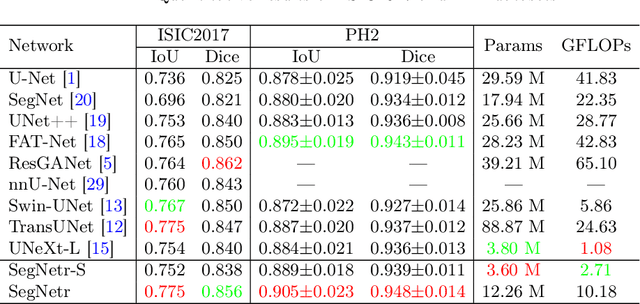
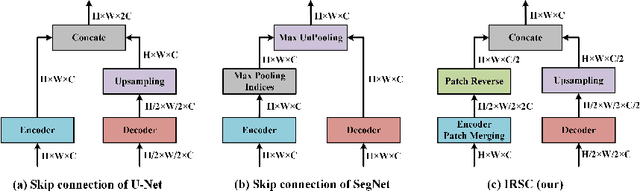
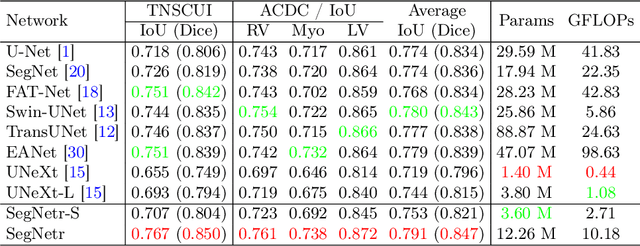
Recently, U-shaped networks have dominated the field of medical image segmentation due to their simple and easily tuned structure. However, existing U-shaped segmentation networks: 1) mostly focus on designing complex self-attention modules to compensate for the lack of long-term dependence based on convolution operation, which increases the overall number of parameters and computational complexity of the network; 2) simply fuse the features of encoder and decoder, ignoring the connection between their spatial locations. In this paper, we rethink the above problem and build a lightweight medical image segmentation network, called SegNetr. Specifically, we introduce a novel SegNetr block that can perform local-global interactions dynamically at any stage and with only linear complexity. At the same time, we design a general information retention skip connection (IRSC) to preserve the spatial location information of encoder features and achieve accurate fusion with the decoder features. We validate the effectiveness of SegNetr on four mainstream medical image segmentation datasets, with 59\% and 76\% fewer parameters and GFLOPs than vanilla U-Net, while achieving segmentation performance comparable to state-of-the-art methods. Notably, the components proposed in this paper can be applied to other U-shaped networks to improve their segmentation performance.
VideoGLUE: Video General Understanding Evaluation of Foundation Models
Jul 06, 2023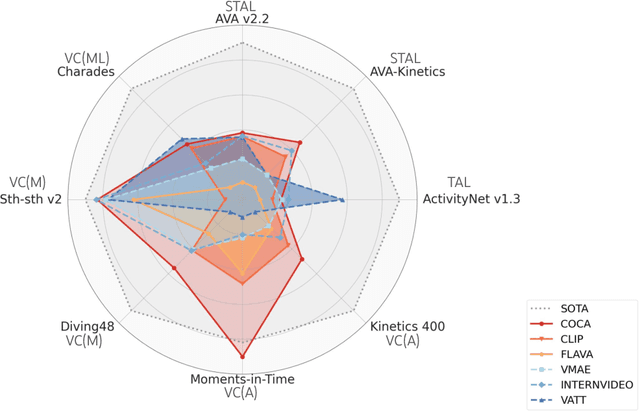


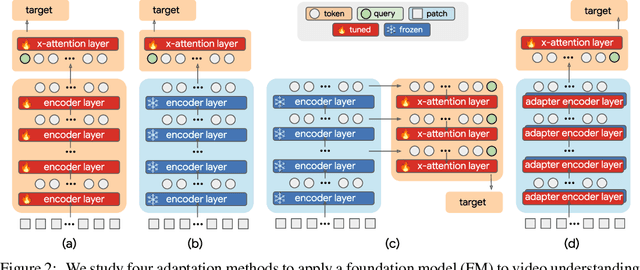
We evaluate existing foundation models video understanding capabilities using a carefully designed experiment protocol consisting of three hallmark tasks (action recognition, temporal localization, and spatiotemporal localization), eight datasets well received by the community, and four adaptation methods tailoring a foundation model (FM) for a downstream task. Moreover, we propose a scalar VideoGLUE score (VGS) to measure an FMs efficacy and efficiency when adapting to general video understanding tasks. Our main findings are as follows. First, task-specialized models significantly outperform the six FMs studied in this work, in sharp contrast to what FMs have achieved in natural language and image understanding. Second,video-native FMs, whose pretraining data contains the video modality, are generally better than image-native FMs in classifying motion-rich videos, localizing actions in time, and understanding a video of more than one action. Third, the video-native FMs can perform well on video tasks under light adaptations to downstream tasks(e.g., freezing the FM backbones), while image-native FMs win in full end-to-end finetuning. The first two observations reveal the need and tremendous opportunities to conduct research on video-focused FMs, and the last confirms that both tasks and adaptation methods matter when it comes to the evaluation of FMs.
Role Engine Implementation for a Continuous and Collaborative Multi-Robot System
Jul 06, 2023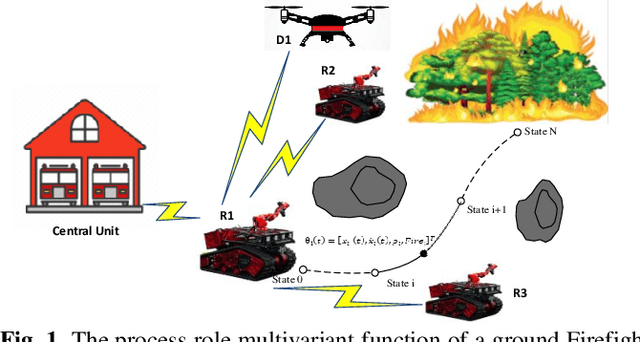
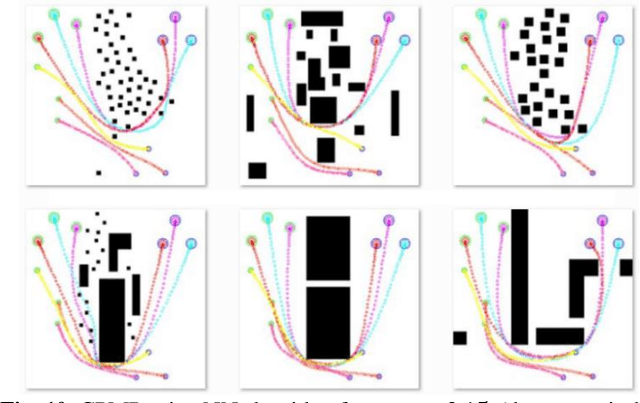
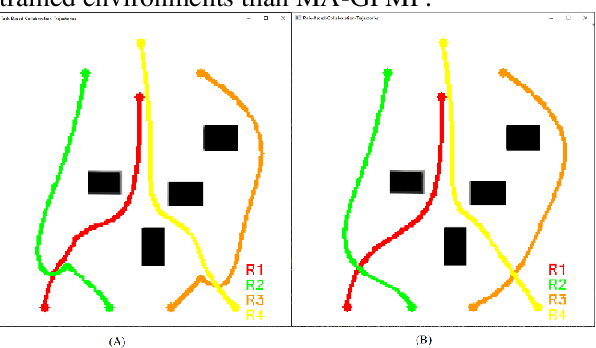
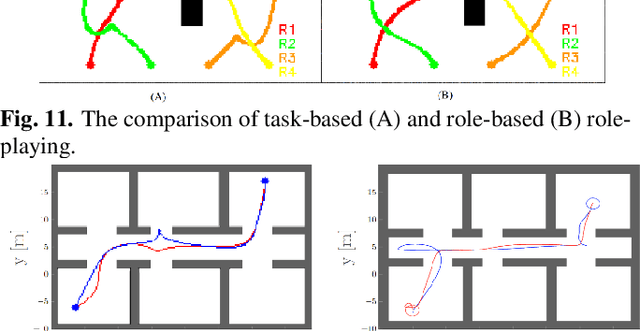
In situations involving teams of diverse robots, assigning appropriate roles to each robot and evaluating their performance is crucial. These roles define the specific characteristics of a robot within a given context. The stream actions exhibited by a robot based on its assigned role are referred to as the process role. Our research addresses the depiction of process roles using a multivariate probabilistic function. The main aim of this study is to develop a role engine for collaborative multi-robot systems and optimize the behavior of the robots. The role engine is designed to assign suitable roles to each robot, generate approximately optimal process roles, update them on time, and identify instances of robot malfunction or trigger replanning when necessary. The environment considered is dynamic, involving obstacles and other agents. The role engine operates hybrid, with central initiation and decentralized action, and assigns unlabeled roles to agents. We employ the Gaussian Process (GP) inference method to optimize process roles based on local constraints and constraints related to other agents. Furthermore, we propose an innovative approach that utilizes the environment's skeleton to address initialization and feasibility evaluation challenges. We successfully demonstrated the proposed approach's feasibility, and efficiency through simulation studies and real-world experiments involving diverse mobile robots.