 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multimodal Dataset Distillation for Image-Text Retrieval
Aug 15, 2023
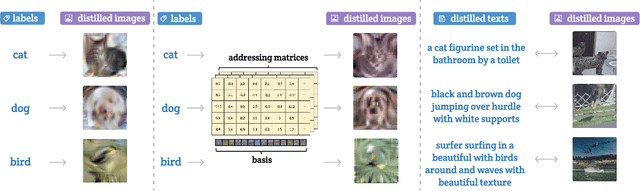
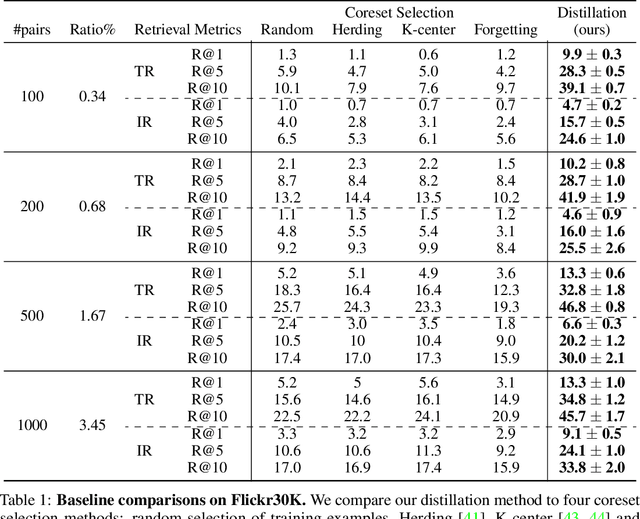
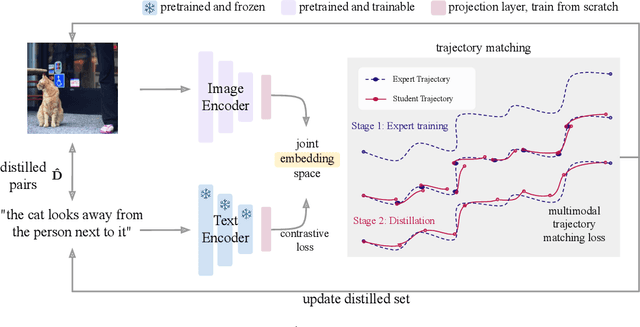
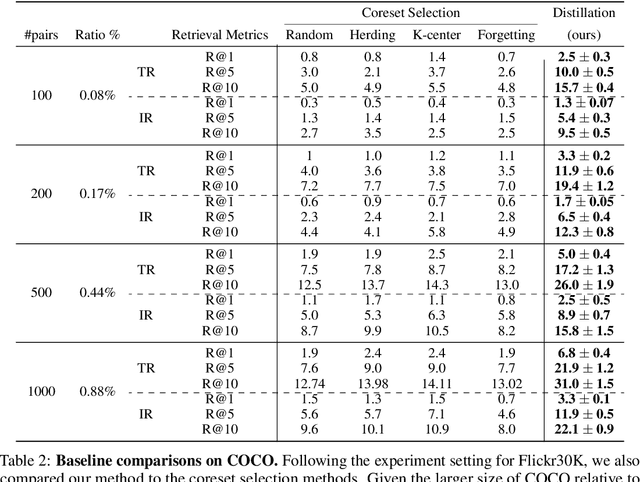
Dataset distillation methods offer the promise of reducing a large-scale dataset down to a significantly smaller set of (potentially synthetic) training examples, which preserve sufficient information for training a new model from scratch. So far dataset distillation methods have been developed for image classification. However, with the rise in capabilities of vision-language models, and especially given the scale of datasets necessary to train these models, the time is ripe to expand dataset distillation methods beyond image classification. In this work, we take the first steps towards this goal by expanding on the idea of trajectory matching to create a distillation method for vision-language datasets. The key challenge is that vision-language datasets do not have a set of discrete classes. To overcome this, our proposed multimodal dataset distillation method jointly distill the images and their corresponding language descriptions in a contrastive formulation. Since there are no existing baselines, we compare our approach to three coreset selection methods (strategic subsampling of the training dataset), which we adapt to the vision-language setting. We demonstrate significant improvements on the challenging Flickr30K and COCO retrieval benchmark: the best coreset selection method which selects 1000 image-text pairs for training is able to achieve only 5.6% image-to-text retrieval accuracy (recall@1); in contrast, our dataset distillation approach almost doubles that with just 100 (an order of magnitude fewer) training pairs.
Vision-based Semantic Communications for Metaverse Services: A Contest Theoretic Approach
Aug 15, 2023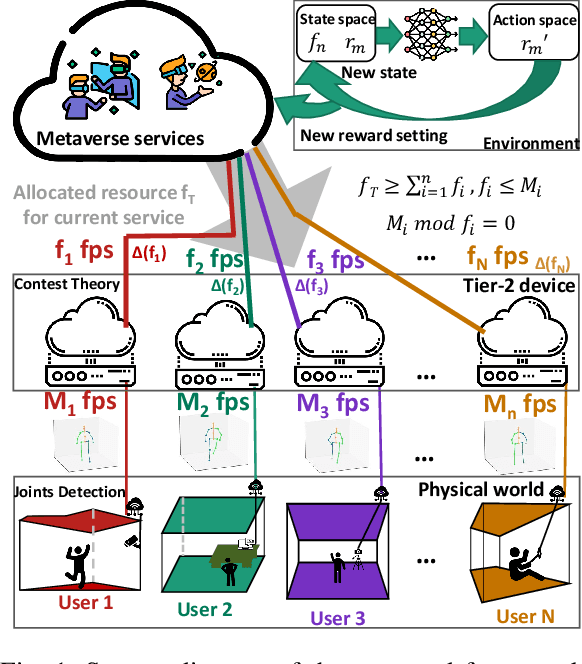
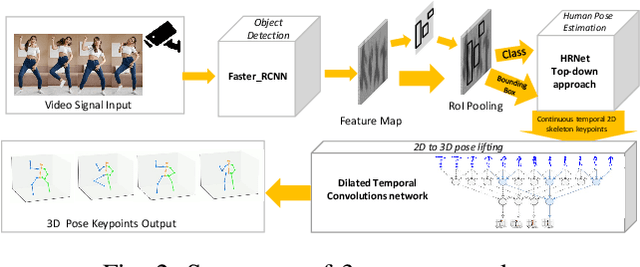
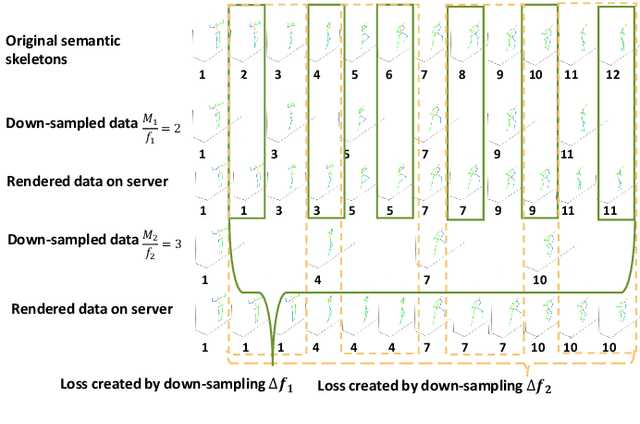
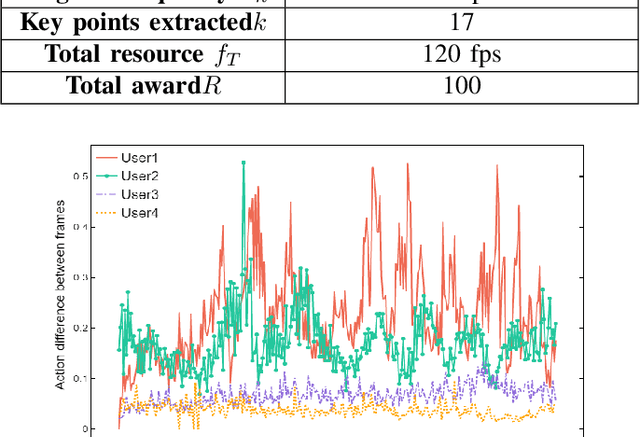
The popularity of Metaverse as an entertainment, social, and work platform has led to a great need for seamless avatar integration in the virtual world. In Metaverse, avatars must be updated and rendered to reflect users' behaviour. Achieving real-time synchronization between the virtual bilocation and the user is complex, placing high demands on the Metaverse Service Provider (MSP)'s rendering resource allocation scheme. To tackle this issue, we propose a semantic communication framework that leverages contest theory to model the interactions between users and MSPs and determine optimal resource allocation for each user. To reduce the consumption of network resources in wireless transmission, we use the semantic communication technique to reduce the amount of data to be transmitted. Under our simulation settings, the encoded semantic data only contains 51 bytes of skeleton coordinates instead of the image size of 8.243 megabytes. Moreover, we implement Deep Q-Network to optimize reward settings for maximum performance and efficient resource allocation. With the optimal reward setting, users are incentivized to select their respective suitable uploading frequency, reducing down-sampling loss due to rendering resource constraints by 66.076\% compared with the traditional average distribution method. The framework provides a novel solution to resource allocation for avatar association in VR environments, ensuring a smooth and immersive experience for all users.
Model-Free Algorithm with Improved Sample Efficiency for Zero-Sum Markov Games
Aug 17, 2023The problem of two-player zero-sum Markov games has recently attracted increasing interests in theoretical studies of multi-agent reinforcement learning (RL). In particular, for finite-horizon episodic Markov decision processes (MDPs), it has been shown that model-based algorithms can find an $\epsilon$-optimal Nash Equilibrium (NE) with the sample complexity of $O(H^3SAB/\epsilon^2)$, which is optimal in the dependence of the horizon $H$ and the number of states $S$ (where $A$ and $B$ denote the number of actions of the two players, respectively). However, none of the existing model-free algorithms can achieve such an optimality. In this work, we propose a model-free stage-based Q-learning algorithm and show that it achieves the same sample complexity as the best model-based algorithm, and hence for the first time demonstrate that model-free algorithms can enjoy the same optimality in the $H$ dependence as model-based algorithms. The main improvement of the dependency on $H$ arises by leveraging the popular variance reduction technique based on the reference-advantage decomposition previously used only for single-agent RL. However, such a technique relies on a critical monotonicity property of the value function, which does not hold in Markov games due to the update of the policy via the coarse correlated equilibrium (CCE) oracle. Thus, to extend such a technique to Markov games, our algorithm features a key novel design of updating the reference value functions as the pair of optimistic and pessimistic value functions whose value difference is the smallest in the history in order to achieve the desired improvement in the sample efficiency.
A reconfigurable multiple-format coherent-dual-band signal generator based on a single optoelectronic oscillation cavity
Aug 06, 2023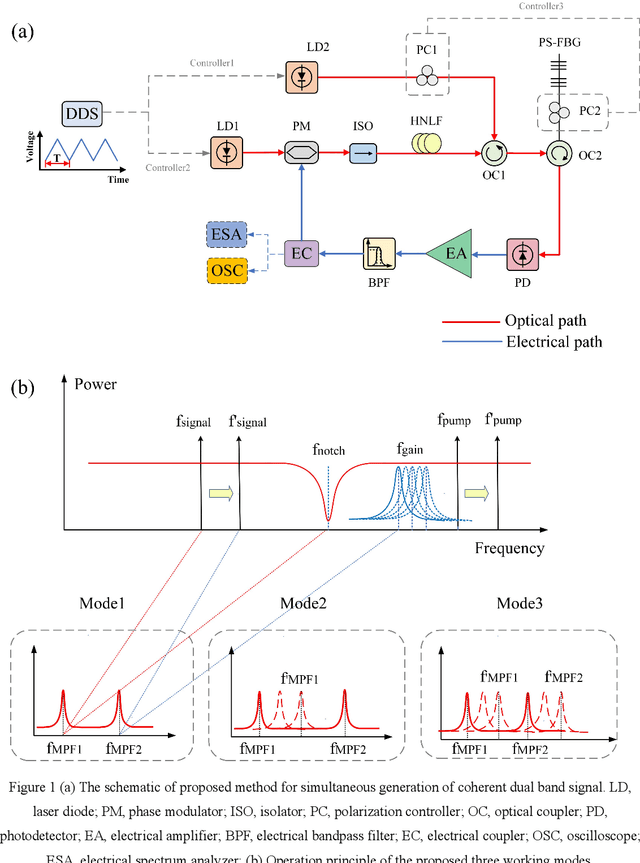
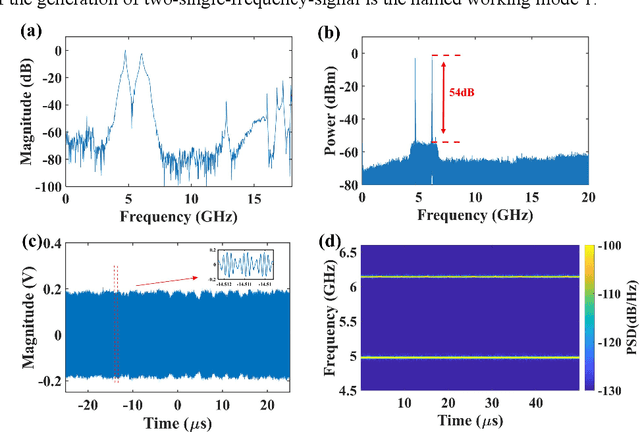
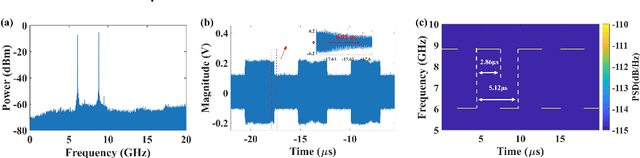
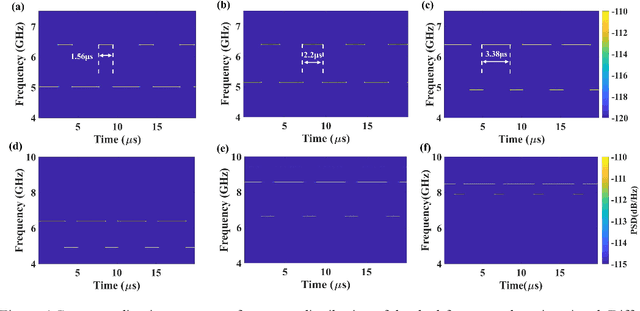
An optoelectronic oscillation method with reconfigurable multiple formats for simultaneous generation of coherent dual-band signals is proposed and experimentally demonstrated. By introducing a compatible filtering mechanism based on stimulated Brillouin scattering (SBS) effect into a typical Phase-shifted grating Bragg fiber (PS-FBG) notch filtering cavity, dual mode-selection mechanisms which have independent frequency and time tuning mechanism can be constructed. By regulating three controllers, the proposed scheme can work in different states, named mode 1, mode 2 and mode 3. At mode 1 state, a dual single-frequency hopping signals is achieved with 50 ns hopping speed and flexible central frequency and pulse duration ratio. The mode 2 state is realized by applying the Fourier domain mode-locked (FDML) technology into the proposed optoelectrical oscillator, in which dual coherent pulsed single-frequency signal and broadband signal is generated simultaneously. The adjustability of the time duration of the single-frequency signal and the bandwidth of the broadband signal are shown and discussed. The mode 3 state is a dual broadband signal generator which is realized by injecting a triangular wave into the signal laser. The detection performance of the generated broadband signals has also been evaluated by the pulse compression and the phase noise figure. The proposed method may provide a multifunctional radar system signal generator based on the simply external controllers, which can realize low-phase-noise or multifunctional detection with high resolution imaging ability, especially in a complex interference environment.
Revisiting Long-term Time Series Forecasting: An Investigation on Linear Mapping
May 18, 2023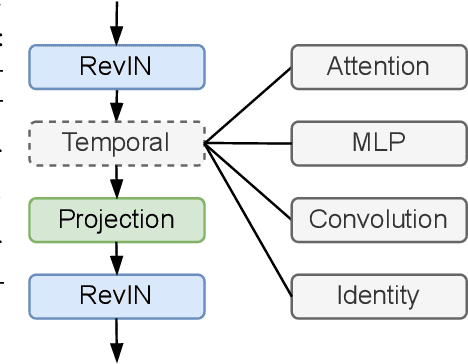
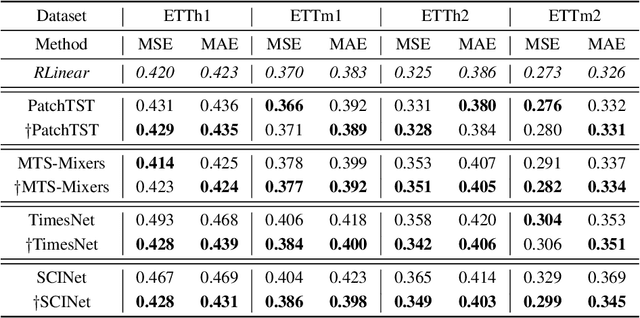
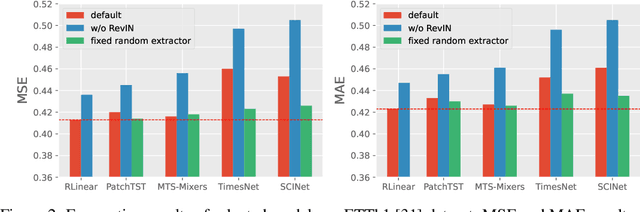

Long-term time series forecasting has gained significant attention in recent years. While there are various specialized designs for capturing temporal dependency, previous studies have demonstrated that a single linear layer can achieve competitive forecasting performance compared to other complex architectures. In this paper, we thoroughly investigate the intrinsic effectiveness of recent approaches and make three key observations: 1) linear mapping is critical to prior long-term time series forecasting efforts; 2) RevIN (reversible normalization) and CI (Channel Independent) play a vital role in improving overall forecasting performance; and 3) linear mapping can effectively capture periodic features in time series and has robustness for different periods across channels when increasing the input horizon. We provide theoretical and experimental explanations to support our findings and also discuss the limitations and future works. Our framework's code is available at \url{https://github.com/plumprc/RTSF}.
On Semidefinite Relaxations for Matrix-Weighted State-Estimation Problems in Robotics
Aug 14, 2023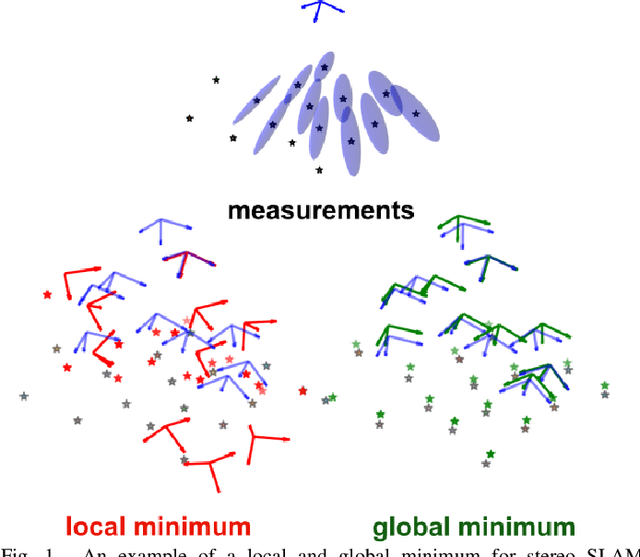
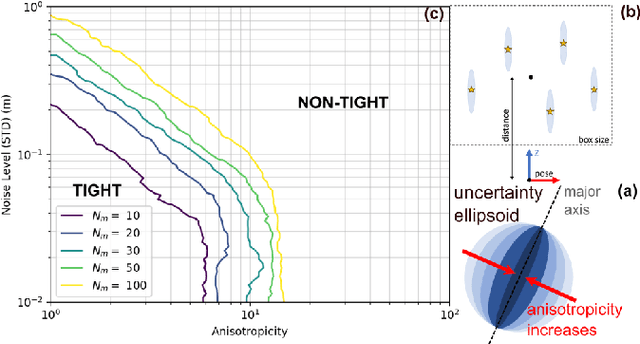
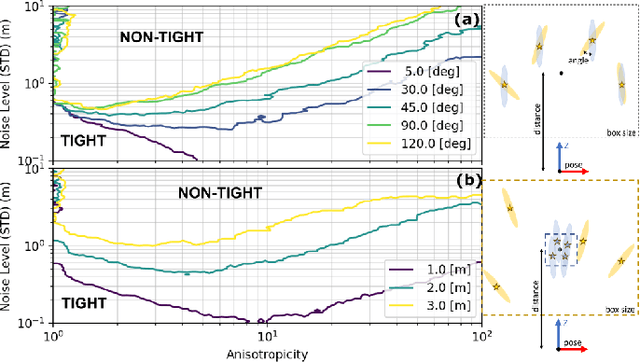
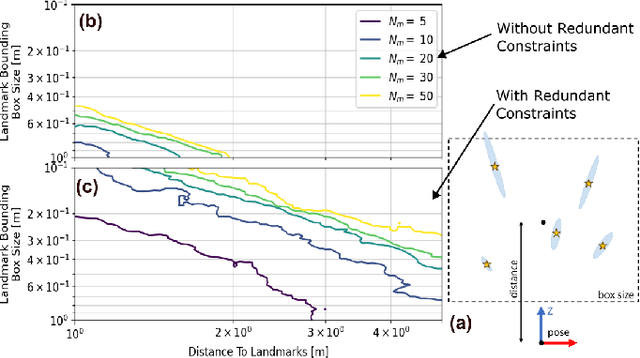
In recent years, there has been remarkable progress in the development of so-called certifiable perception methods, which leverage semidefinite, convex relaxations to find global optima of perception problems in robotics. However, many of these relaxations rely on simplifying assumptions that facilitate the problem formulation, such as an isotropic measurement noise distribution. In this paper, we explore the tightness of the semidefinite relaxations of matrix-weighted (anisotropic) state-estimation problems and reveal the limitations lurking therein: matrix-weighted factors can cause convex relaxations to lose tightness. In particular, we show that the semidefinite relaxations of localization problems with matrix weights may be tight only for low noise levels. We empirically explore the factors that contribute to this loss of tightness and demonstrate that redundant constraints can be used to regain tightness, albeit at the expense of real-time performance. As a second technical contribution of this paper, we show that the state-of-the-art relaxation of scalar-weighted SLAM cannot be used when matrix weights are considered. We provide an alternate formulation and show that its SDP relaxation is not tight (even for very low noise levels) unless specific redundant constraints are used. We demonstrate the tightness of our formulations on both simulated and real-world data.
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
Aug 14, 2023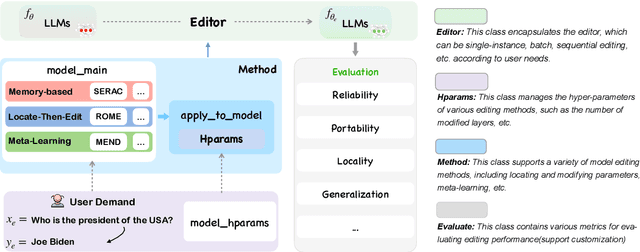
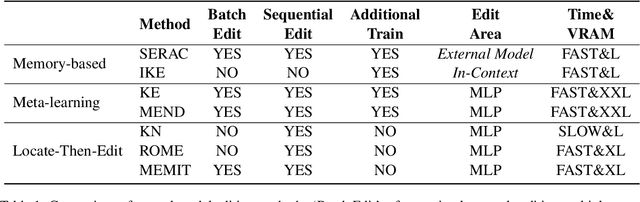

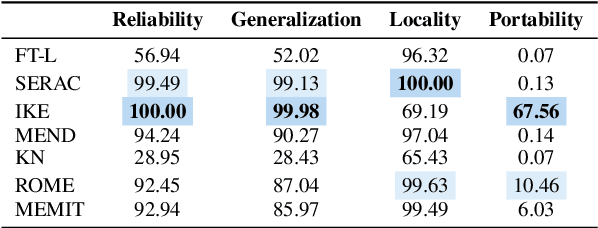
Large Language Models (LLMs) usually suffer from knowledge cutoff or fallacy issues, which means they are unaware of unseen events or generate text with incorrect facts owing to the outdated/noisy data. To this end, many knowledge editing approaches for LLMs have emerged -- aiming to subtly inject/edit updated knowledge or adjust undesired behavior while minimizing the impact on unrelated inputs. Nevertheless, due to significant differences among various knowledge editing methods and the variations in task setups, there is no standard implementation framework available for the community, which hinders practitioners to apply knowledge editing to applications. To address these issues, we propose EasyEdit, an easy-to-use knowledge editing framework for LLMs. It supports various cutting-edge knowledge editing approaches and can be readily apply to many well-known LLMs such as T5, GPT-J, LlaMA, etc. Empirically, we report the knowledge editing results on LlaMA-2 with EasyEdit, demonstrating that knowledge editing surpasses traditional fine-tuning in terms of reliability and generalization. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit, along with Google Colab tutorials and comprehensive documentation for beginners to get started. Besides, we present an online system for real-time knowledge editing, and a demo video at http://knowlm.zjukg.cn/easyedit.mp4.
Non-Myopic Sensor Control for Target Search and Track Using a Sample-Based GOSPA Implementation
Aug 14, 2023This paper is concerned with sensor management for target search and track using the generalised optimal subpattern assignment (GOSPA) metric. Utilising the GOSPA metric to predict future system performance is computationally challenging, because of the need to account for uncertainties within the scenario, notably the number of targets, the locations of targets, and the measurements generated by the targets subsequent to performing sensing actions. In this paper, efficient sample-based techniques are developed to calculate the predicted mean square GOSPA metric. These techniques allow for missed detections and false alarms, and thereby enable the metric to be exploited in scenarios more complex than those previously considered. Furthermore, the GOSPA methodology is extended to perform non-myopic (i.e. multi-step) sensor management via the development of a Bellman-type recursion that optimises a conditional GOSPA-based metric. Simulations for scenarios with missed detections, false alarms, and planning horizons of up to three time steps demonstrate the approach, in particular showing that optimal plans align with an intuitive understanding of how taking into account the opportunity to make future observations should influence the current action. It is concluded that the GOSPA-based, non-myopic search and track algorithm offers a powerful mechanism for sensor management.
OpenGCD: Assisting Open World Recognition with Generalized Category Discovery
Aug 14, 2023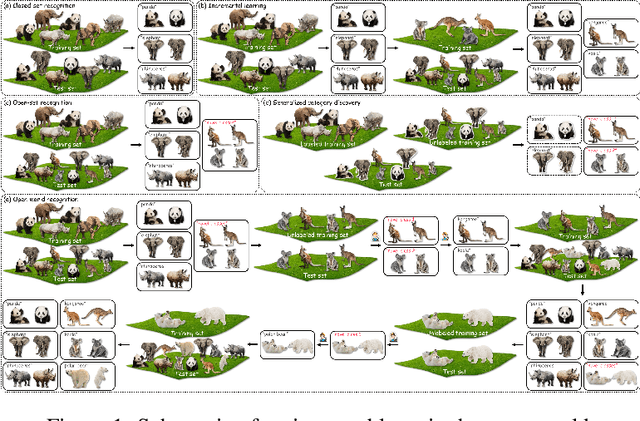
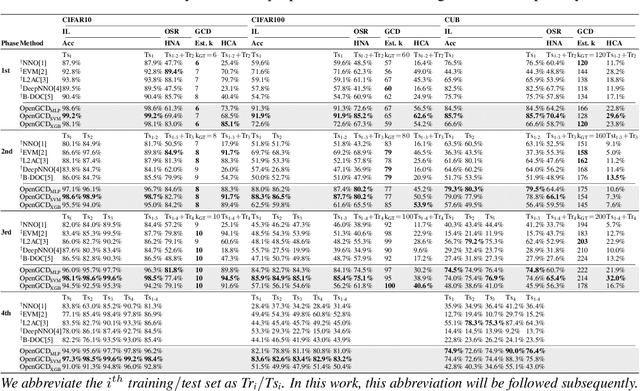
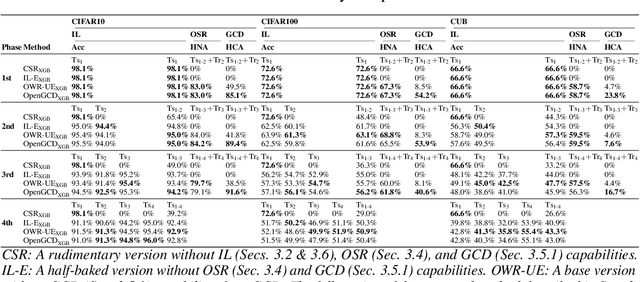
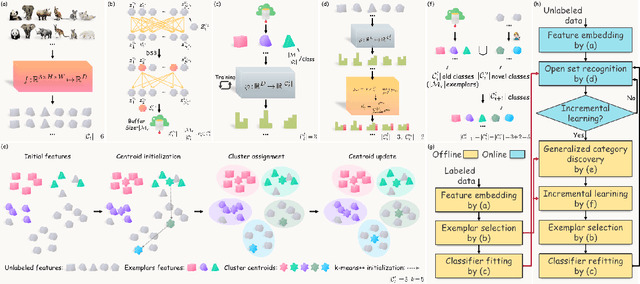
A desirable open world recognition (OWR) system requires performing three tasks: (1) Open set recognition (OSR), i.e., classifying the known (classes seen during training) and rejecting the unknown (unseen$/$novel classes) online; (2) Grouping and labeling these unknown as novel known classes; (3) Incremental learning (IL), i.e., continual learning these novel classes and retaining the memory of old classes. Ideally, all of these steps should be automated. However, existing methods mostly assume that the second task is completely done manually. To bridge this gap, we propose OpenGCD that combines three key ideas to solve the above problems sequentially: (a) We score the origin of instances (unknown or specifically known) based on the uncertainty of the classifier's prediction; (b) For the first time, we introduce generalized category discovery (GCD) techniques in OWR to assist humans in grouping unlabeled data; (c) For the smooth execution of IL and GCD, we retain an equal number of informative exemplars for each class with diversity as the goal. Moreover, we present a new performance evaluation metric for GCD called harmonic clustering accuracy. Experiments on two standard classification benchmarks and a challenging dataset demonstrate that OpenGCD not only offers excellent compatibility but also substantially outperforms other baselines. Code: https://github.com/Fulin-Gao/OpenGCD.
A Robust and Rapidly Deployable Waypoint Navigation Architecture for Long-Duration Operations in GPS-Denied Environments
Aug 10, 2023For long-duration operations in GPS-denied environments, accurate and repeatable waypoint navigation is an essential capability. While simultaneous localization and mapping (SLAM) works well for single-session operations, repeated, multi-session operations require robots to navigate to the same spot(s) accurately and precisely each and every time. Localization and navigation errors can build up from one session to the next if they are not accounted for. Localization using a global reference map works well, but there are no publicly available packages for quickly building maps and navigating with them. We propose a new architecture using a combination of two publicly available packages with a newly released package to create a fully functional multi-session navigation system for ground vehicles. The system takes just a few hours from the beginning of the first manual scan to perform autonomous waypoint navigation.