 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Play Consistency Models for MIMO Channel Estimation
Apr 26, 2026Consistency models (CMs) learn a consistent mapping from multiple noise levels to the data endpoint and can therefore perform generative inference in one or a few steps. This property makes them attractive as learned priors for low-latency inverse problems. Multiple-input multiple-output (MIMO) channel estimation under limited pilot overhead can be formulated as a high-dimensional linear inverse problem with an explicit measurement matrix, where data consistency alone is often insufficient for stable angular-domain channel recovery. This paper applies the plug-and-play consistency model (PnP-CM) framework to pilot-aided MIMO channel estimation. The PnP-CM inference procedure enforces the pilot observation model in the data-consistency update and invokes a pretrained CM denoiser in the prior update, thereby recovering the angular-domain channel vector within a small number of outer iterations. Preliminary experiments validate the feasibility of using CMs as low-latency channel-estimation priors and show that adaptive parameter scheduling and cross-scenario robustness remain important directions for further improvement.
Wideband Near-Field Sensing in ISAC: Unified Algorithm Design and Decoupled Effect Analysis
Mar 29, 2026To advance integrated sensing and communications (ISAC) in sixth-generation (6G) extremely large-scale multiple-input multiple-output (XL-MIMO) networks, a low-complexity compressed sensing (CS)-based dictionary design is proposed for wideband near-field (WB-NF) target localization. Currently, the massive signal dimensions in the WB-NF regime impose severe computational burdens and high spatial-frequency coherence on conventional grid-based algorithms. Furthermore, a unified framework exploiting both wideband (WB) and near-field (NF) effects is lacking, and the analytical conditions for simplifying this model into decoupled approximations remain uncharacterized. To address these challenges, the proposed algorithm mathematically decouples the mutual coherence function and introduces a novel angle-distance sampling grid with customized distance adjustments, drastically reducing dictionary dimensions while ensuring low coherence. To isolate the individual WB and NF impacts, two coherence-based metrics are formulated to establish the effective boundaries of the narrowband near-field (NB-NF) and wideband far-field (WB-FF) regions, where respective multiple signal classification (MUSIC) algorithms are utilized. Simulations demonstrate that the CS-based method achieves robust performance across the entire regime, and the established boundaries provide crucial theoretical guidelines for WB and NF effect decoupling.
Joint Visible Light and Backscatter Communications for Proximity-Based Indoor Asset Tracking Enabled by Energy-Neutral Devices
Oct 31, 2025In next-generation wireless systems, providing location-based mobile computing services for energy-neutral devices has become a crucial objective for the provision of sustainable Internet of Things (IoT). Visible light positioning (VLP) has gained great research attention as a complementary method to radio frequency (RF) solutions since it can leverage ubiquitous lighting infrastructure. However, conventional VLP receivers often rely on photodetectors or cameras that are power-hungry, complex, and expensive. To address this challenge, we propose a hybrid indoor asset tracking system that integrates visible light communication (VLC) and backscatter communication (BC) within a simultaneous lightwave information and power transfer (SLIPT) framework. We design a low-complexity and energy-neutral IoT node, namely backscatter device (BD) which harvests energy from light-emitting diode (LED) access points, and then modulates and reflects ambient RF carriers to indicate its location within particular VLC cells. We present a multi-cell VLC deployment with frequency division multiplexing (FDM) method that mitigates interference among LED access points by assigning them distinct frequency pairs based on a four-color map scheduling principle. We develop a lightweight particle filter (PF) tracking algorithm at an edge RF reader, where the fusion of proximity reports and the received backscatter signal strength are employed to track the BD. Experimental results show that this approach achieves the positioning error of 0.318 m at 50th percentile and 0.634 m at 90th percentile, while avoiding the use of complex photodetectors and active RF synthesizing components at the energy-neutral IoT node. By demonstrating robust performance in multiple indoor trajectories, the proposed solution enables scalable, cost-effective, and energy-neutral indoor tracking for pervasive and edge-assisted IoT applications.
Subspace Fitting Approach for Wideband Near-Field Localization
Aug 06, 2025Two subspace fitting approaches are proposed for wideband near-field localization. Unlike in conventional far-field systems, where distance and angle can be estimated separately, spherical wave propagation in near-field systems couples these parameters. We therefore derive a frequency-domain near-field signal model for multi-target wideband systems and develop a subspace fitting-based MUSIC method that jointly estimates distance and angle. To reduce complexity, a Fresnel approximation MUSIC algorithm is further introduced to decouple the distance and angle parameters. Numerical results verify the effectiveness of both proposed approaches.
BESA: Boosting Encoder Stealing Attack with Perturbation Recovery
Jun 05, 2025To boost the encoder stealing attack under the perturbation-based defense that hinders the attack performance, we propose a boosting encoder stealing attack with perturbation recovery named BESA. It aims to overcome perturbation-based defenses. The core of BESA consists of two modules: perturbation detection and perturbation recovery, which can be combined with canonical encoder stealing attacks. The perturbation detection module utilizes the feature vectors obtained from the target encoder to infer the defense mechanism employed by the service provider. Once the defense mechanism is detected, the perturbation recovery module leverages the well-designed generative model to restore a clean feature vector from the perturbed one. Through extensive evaluations based on various datasets, we demonstrate that BESA significantly enhances the surrogate encoder accuracy of existing encoder stealing attacks by up to 24.63\% when facing state-of-the-art defenses and combinations of multiple defenses.
Context-Aware Semantic Communication for the Wireless Networks
May 29, 2025In next-generation wireless networks, supporting real-time applications such as augmented reality, autonomous driving, and immersive Metaverse services demands stringent constraints on bandwidth, latency, and reliability. Existing semantic communication (SemCom) approaches typically rely on static models, overlooking dynamic conditions and contextual cues vital for efficient transmission. To address these challenges, we propose CaSemCom, a context-aware SemCom framework that leverages a Large Language Model (LLM)-based gating mechanism and a Mixture of Experts (MoE) architecture to adaptively select and encode only high-impact semantic features across multiple data modalities. Our multimodal, multi-user case study demonstrates that CaSemCom significantly improves reconstructed image fidelity while reducing bandwidth usage, outperforming single-agent deep reinforcement learning (DRL) methods and traditional baselines in convergence speed, semantic accuracy, and retransmission overhead.
Bridging the Modality Gap: Enhancing Channel Prediction with Semantically Aligned LLMs and Knowledge Distillation
May 19, 2025Accurate channel prediction is essential in massive multiple-input multiple-output (m-MIMO) systems to improve precoding effectiveness and reduce the overhead of channel state information (CSI) feedback. However, existing methods often suffer from accumulated prediction errors and poor generalization to dynamic wireless environments. Large language models (LLMs) have demonstrated remarkable modeling and generalization capabilities in tasks such as time series prediction, making them a promising solution. Nevertheless, a significant modality gap exists between the linguistic knowledge embedded in pretrained LLMs and the intrinsic characteristics of CSI, posing substantial challenges for their direct application to channel prediction. Moreover, the large parameter size of LLMs hinders their practical deployment in real-world communication systems with stringent latency constraints. To address these challenges, we propose a novel channel prediction framework based on semantically aligned large models, referred to as CSI-ALM, which bridges the modality gap between natural language and channel information. Specifically, we design a cross-modal fusion module that aligns CSI representations . Additionally, we maximize the cosine similarity between word embeddings and CSI embeddings to construct semantic cues. To reduce complexity and enable practical implementation, we further introduce a lightweight version of the proposed approach, called CSI-ALM-Light. This variant is derived via a knowledge distillation strategy based on attention matrices. Extensive experimental results demonstrate that CSI-ALM achieves a 1 dB gain over state-of-the-art deep learning methods. Moreover, under limited training data conditions, CSI-ALM-Light, with only 0.34M parameters, attains performance comparable to CSI-ALM and significantly outperforms conventional deep learning approaches.
LAMeTA: Intent-Aware Agentic Network Optimization via a Large AI Model-Empowered Two-Stage Approach
May 18, 2025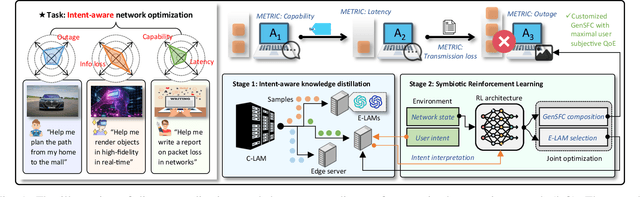
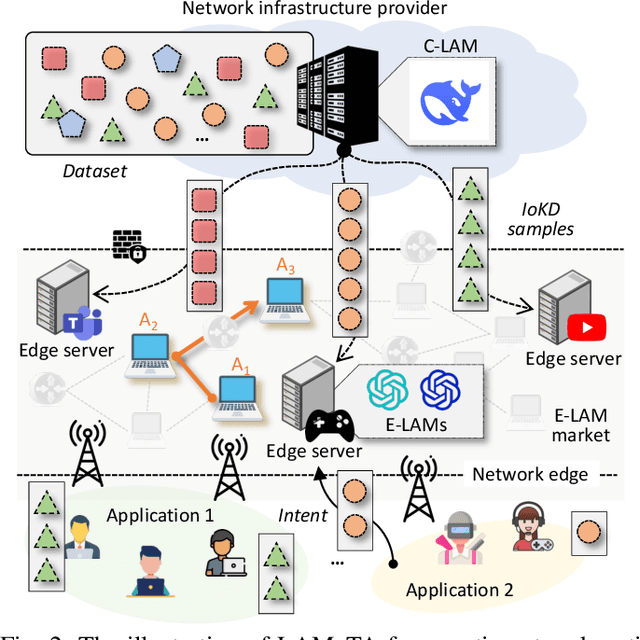
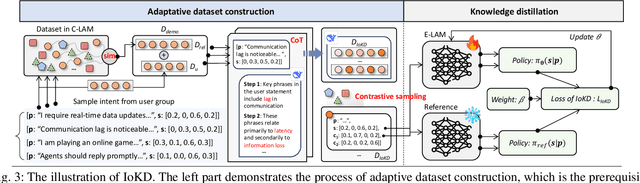
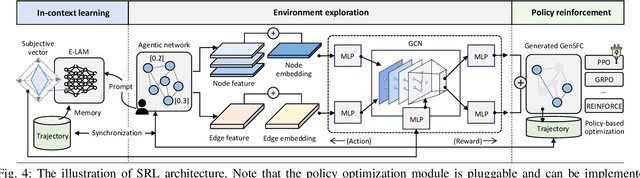
Nowadays, Generative AI (GenAI) reshapes numerous domains by enabling machines to create content across modalities. As GenAI evolves into autonomous agents capable of reasoning, collaboration, and interaction, they are increasingly deployed on network infrastructures to serve humans automatically. This emerging paradigm, known as the agentic network, presents new optimization challenges due to the demand to incorporate subjective intents of human users expressed in natural language. Traditional generic Deep Reinforcement Learning (DRL) struggles to capture intent semantics and adjust policies dynamically, thus leading to suboptimality. In this paper, we present LAMeTA, a Large AI Model (LAM)-empowered Two-stage Approach for intent-aware agentic network optimization. First, we propose Intent-oriented Knowledge Distillation (IoKD), which efficiently distills intent-understanding capabilities from resource-intensive LAMs to lightweight edge LAMs (E-LAMs) to serve end users. Second, we develop Symbiotic Reinforcement Learning (SRL), integrating E-LAMs with a policy-based DRL framework. In SRL, E-LAMs translate natural language user intents into structured preference vectors that guide both state representation and reward design. The DRL, in turn, optimizes the generative service function chain composition and E-LAM selection based on real-time network conditions, thus optimizing the subjective Quality-of-Experience (QoE). Extensive experiments conducted in an agentic network with 81 agents demonstrate that IoKD reduces mean squared error in intent prediction by up to 22.5%, while SRL outperforms conventional generic DRL by up to 23.5% in maximizing intent-aware QoE.
Decentralization of Generative AI via Mixture of Experts for Wireless Networks: A Comprehensive Survey
Apr 28, 2025



Mixture of Experts (MoE) has emerged as a promising paradigm for scaling model capacity while preserving computational efficiency, particularly in large-scale machine learning architectures such as large language models (LLMs). Recent advances in MoE have facilitated its adoption in wireless networks to address the increasing complexity and heterogeneity of modern communication systems. This paper presents a comprehensive survey of the MoE framework in wireless networks, highlighting its potential in optimizing resource efficiency, improving scalability, and enhancing adaptability across diverse network tasks. We first introduce the fundamental concepts of MoE, including various gating mechanisms and the integration with generative AI (GenAI) and reinforcement learning (RL). Subsequently, we discuss the extensive applications of MoE across critical wireless communication scenarios, such as vehicular networks, unmanned aerial vehicles (UAVs), satellite communications, heterogeneous networks, integrated sensing and communication (ISAC), and mobile edge networks. Furthermore, key applications in channel prediction, physical layer signal processing, radio resource management, network optimization, and security are thoroughly examined. Additionally, we present a detailed overview of open-source datasets that are widely used in MoE-based models to support diverse machine learning tasks. Finally, this survey identifies crucial future research directions for MoE, emphasizing the importance of advanced training techniques, resource-aware gating strategies, and deeper integration with emerging 6G technologies.
Wireless Hallucination in Generative AI-enabled Communications: Concepts, Issues, and Solutions
Mar 08, 2025



Generative AI (GenAI) is driving the intelligence of wireless communications. Due to data limitations, random generation, and dynamic environments, GenAI may generate channel information or optimization strategies that violate physical laws or deviate from actual real-world requirements. We refer to this phenomenon as wireless hallucination, which results in invalid channel information, spectrum wastage, and low communication reliability but remains underexplored. To address this gap, this article provides a comprehensive concept of wireless hallucinations in GenAI-driven communications, focusing on hallucination mitigation. Specifically, we first introduce the fundamental, analyze its causes based on the GenAI workflow, and propose mitigation solutions at the data, model, and post-generation levels. Then, we systematically examines representative hallucination scenarios in GenAI-enabled communications and their corresponding solutions. Finally, we propose a novel integrated mitigation solution for GenAI-based channel estimation. At the data level, we establish a channel estimation hallucination dataset and employ generative adversarial networks (GANs)-based data augmentation. Additionally, we incorporate attention mechanisms and large language models (LLMs) to enhance both training and inference performance. Experimental results demonstrate that the proposed hybrid solutions reduce the normalized mean square error (NMSE) by 0.19, effectively reducing wireless hallucinations.