 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text": models, code, and papers
AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
Apr 04, 2024
Large language models (LLMs) have fueled many intelligent agent tasks, such as web navigation -- but most existing agents perform far from satisfying in real-world webpages due to three factors: (1) the versatility of actions on webpages, (2) HTML text exceeding model processing capacity, and (3) the complexity of decision-making due to the open-domain nature of web. In light of the challenge, we develop AutoWebGLM, a GPT-4-outperforming automated web navigation agent built upon ChatGLM3-6B. Inspired by human browsing patterns, we design an HTML simplification algorithm to represent webpages, preserving vital information succinctly. We employ a hybrid human-AI method to build web browsing data for curriculum training. Then, we bootstrap the model by reinforcement learning and rejection sampling to further facilitate webpage comprehension, browser operations, and efficient task decomposition by itself. For testing, we establish a bilingual benchmark -- AutoWebBench -- for real-world web browsing tasks. We evaluate AutoWebGLM across diverse web navigation benchmarks, revealing its improvements but also underlying challenges to tackle real environments. Related code, model, and data will be released at \url{https://github.com/THUDM/AutoWebGLM}.
Scaling Up Video Summarization Pretraining with Large Language Models
Apr 04, 2024Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
Future-Proofing Class Incremental Learning
Apr 04, 2024Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
Scaling Properties of Speech Language Models
Mar 31, 2024Speech Language Models (SLMs) aim to learn language from raw audio, without textual resources. Despite significant advances, our current models exhibit weak syntax and semantic abilities. However, if the scaling properties of neural language models hold for the speech modality, these abilities will improve as the amount of compute used for training increases. In this paper, we use models of this scaling behavior to estimate the scale at which our current methods will yield a SLM with the English proficiency of text-based Large Language Models (LLMs). We establish a strong correlation between pre-training loss and downstream syntactic and semantic performance in SLMs and LLMs, which results in predictable scaling of linguistic performance. We show that the linguistic performance of SLMs scales up to three orders of magnitude more slowly than that of text-based LLMs. Additionally, we study the benefits of synthetic data designed to boost semantic understanding and the effects of coarser speech tokenization.
On the True Distribution Approximation of Minimum Bayes-Risk Decoding
Mar 31, 2024Minimum Bayes-risk (MBR) decoding has recently gained renewed attention in text generation. MBR decoding considers texts sampled from a model as pseudo-references and selects the text with the highest similarity to the others. Therefore, sampling is one of the key elements of MBR decoding, and previous studies reported that the performance varies by sampling methods. From a theoretical standpoint, this performance variation is likely tied to how closely the samples approximate the true distribution of references. However, this approximation has not been the subject of in-depth study. In this study, we propose using anomaly detection to measure the degree of approximation. We first closely examine the performance variation and then show that previous hypotheses about samples do not correlate well with the variation, but our introduced anomaly scores do. The results are the first to empirically support the link between the performance and the core assumption of MBR decoding.
Deep Instruction Tuning for Segment Anything Model
Mar 31, 2024Segment Anything Model (SAM) exhibits powerful yet versatile capabilities on (un) conditional image segmentation tasks recently. Although SAM can support various segmentation prompts, we note that, compared to point- and box-guided segmentation, it performs much worse on text-instructed tasks. We argue that deep text instruction tuning is key to mitigate such shortcoming caused by the shallow fusion scheme in its default light-weight mask decoder. In this paper, two \emph{deep instruction tuning} (DIT) methods are proposed, one is end-to-end and the other is layer-wise. With these tuning methods, we can regard the image encoder of SAM as a stand-alone vision-language learner in contrast to building another deep fusion branch. Extensive experiments on three highly competitive benchmark datasets of referring image segmentation show that a simple end-to-end DIT improves SAM by a large margin, with layer-wise DIT further boosts the performance to state-of-the-art. Our code is anonymously released at: https://github.com/wysnzzzz/DIT.
M3D: Advancing 3D Medical Image Analysis with Multi-Modal Large Language Models
Mar 31, 2024Medical image analysis is essential to clinical diagnosis and treatment, which is increasingly supported by multi-modal large language models (MLLMs). However, previous research has primarily focused on 2D medical images, leaving 3D images under-explored, despite their richer spatial information. This paper aims to advance 3D medical image analysis with MLLMs. To this end, we present a large-scale 3D multi-modal medical dataset, M3D-Data, comprising 120K image-text pairs and 662K instruction-response pairs specifically tailored for various 3D medical tasks, such as image-text retrieval, report generation, visual question answering, positioning, and segmentation. Additionally, we propose M3D-LaMed, a versatile multi-modal large language model for 3D medical image analysis. Furthermore, we introduce a new 3D multi-modal medical benchmark, M3D-Bench, which facilitates automatic evaluation across eight tasks. Through comprehensive evaluation, our method proves to be a robust model for 3D medical image analysis, outperforming existing solutions. All code, data, and models are publicly available at: https://github.com/BAAI-DCAI/M3D.
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Mar 18, 2024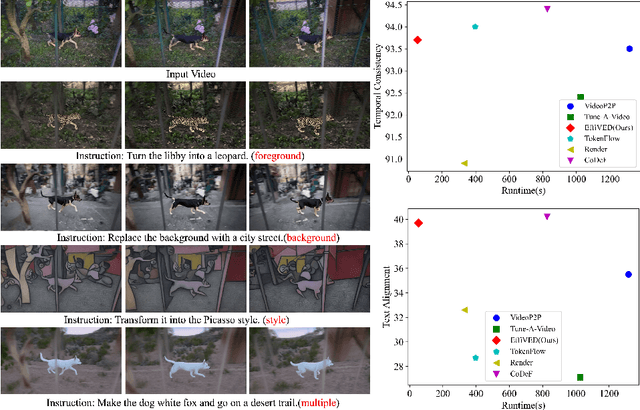
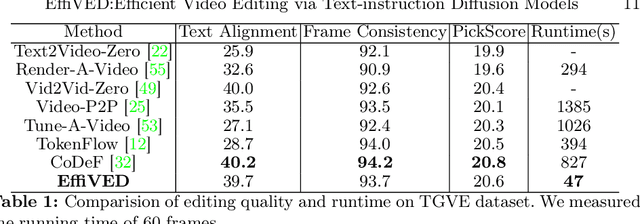
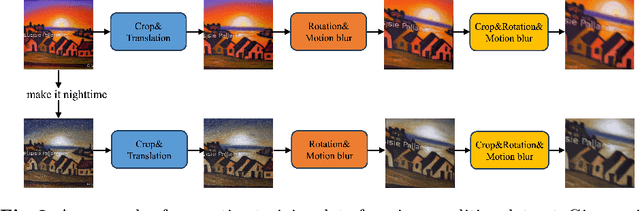
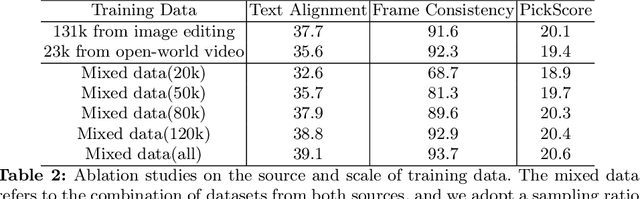
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. The datasets will be made publicly available upon publication.
Measuring Style Similarity in Diffusion Models
Apr 01, 2024Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation. Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes. Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images. Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc. We also propose a method to extract style descriptors that can be used to attribute style of a generated image to the images used in the training dataset of a text-to-image model. We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model. Code and artifacts are available at https://github.com/learn2phoenix/CSD.
BAMM: Bidirectional Autoregressive Motion Model
Apr 01, 2024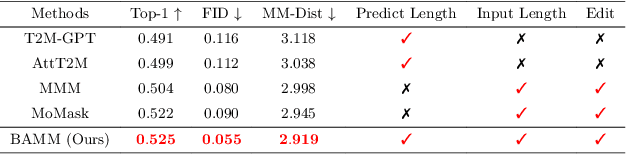
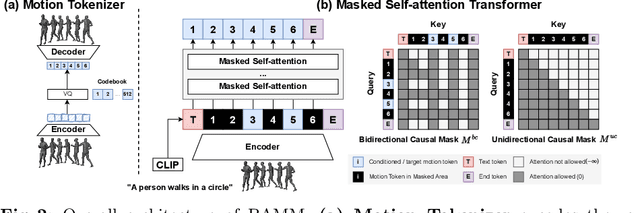
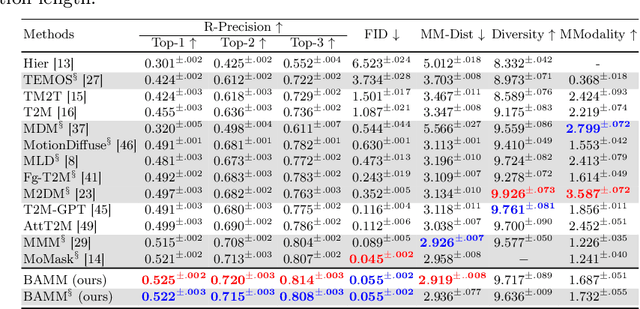
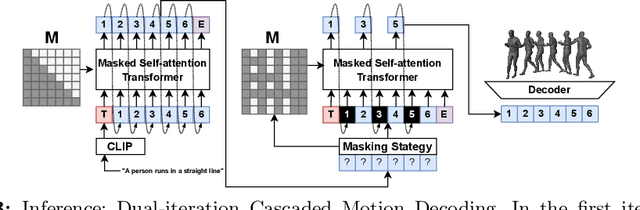
Generating human motion from text has been dominated by denoising motion models either through diffusion or generative masking process. However, these models face great limitations in usability by requiring prior knowledge of the motion length. Conversely, autoregressive motion models address this limitation by adaptively predicting motion endpoints, at the cost of degraded generation quality and editing capabilities. To address these challenges, we propose Bidirectional Autoregressive Motion Model (BAMM), a novel text-to-motion generation framework. BAMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into discrete tokens in latent space, and (2) a masked self-attention transformer that autoregressively predicts randomly masked tokens via a hybrid attention masking strategy. By unifying generative masked modeling and autoregressive modeling, BAMM captures rich and bidirectional dependencies among motion tokens, while learning the probabilistic mapping from textual inputs to motion outputs with dynamically-adjusted motion sequence length. This feature enables BAMM to simultaneously achieving high-quality motion generation with enhanced usability and built-in motion editability. Extensive experiments on HumanML3D and KIT-ML datasets demonstrate that BAMM surpasses current state-of-the-art methods in both qualitative and quantitative measures. Our project page is available at https://exitudio.github.io/BAMM-page