 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Faceted Interactivity Alignment in Full-Duplex Speech Models
Jun 09, 2026Full-duplex spoken dialogue models can listen and speak simultaneously, making them a promising architecture for natural conversation. However, current models are trained solely with supervised learning through token-level likelihood maximization, which does not directly optimize interaction-level behaviors, causing interactivity issues such as excessive silence and ill-timed turn-taking. Recent work has applied reinforcement learning (RL) to improve interactivity, but existing methods address only a limited set of interactive behaviors in their rewards. In this work, we propose a post-training alignment method that comprehensively improves the interactivity of full-duplex spoken dialogue models through RL. We address the four canonical axes of interactivity: pause handling, turn-taking, backchanneling, and user interruption. For each axis, we extract short audio segments from human conversation corpora and optimize the model with axis-specific reward functions. An extra LLM-based reward for response quality prevents semantic degradation. We apply our method to two open-source models, Moshi and PersonaPlex, demonstrating consistent improvements in interactivity on both offline evaluation with pre-recorded audio and real-time multi-turn dialogue evaluation.
Universal Post-Processing Networks for Joint Optimization of Modules in Task-Oriented Dialogue Systems
Feb 02, 2025



Post-processing networks (PPNs) are components that modify the outputs of arbitrary modules in task-oriented dialogue systems and are optimized using reinforcement learning (RL) to improve the overall task completion capability of the system. However, previous PPN-based approaches have been limited to handling only a subset of modules within a system, which poses a significant limitation in improving the system performance. In this study, we propose a joint optimization method for post-processing the outputs of all modules using universal post-processing networks (UniPPNs), which are language-model-based networks that can modify the outputs of arbitrary modules in a system as a sequence-transformation task. Moreover, our RL algorithm, which employs a module-level Markov decision process, enables fine-grained value and advantage estimation for each module, thereby stabilizing joint learning for post-processing the outputs of all modules. Through both simulation-based and human evaluation experiments using the MultiWOZ dataset, we demonstrated that UniPPN outperforms conventional PPNs in the task completion capability of task-oriented dialogue systems.
On the True Distribution Approximation of Minimum Bayes-Risk Decoding
Mar 31, 2024Minimum Bayes-risk (MBR) decoding has recently gained renewed attention in text generation. MBR decoding considers texts sampled from a model as pseudo-references and selects the text with the highest similarity to the others. Therefore, sampling is one of the key elements of MBR decoding, and previous studies reported that the performance varies by sampling methods. From a theoretical standpoint, this performance variation is likely tied to how closely the samples approximate the true distribution of references. However, this approximation has not been the subject of in-depth study. In this study, we propose using anomaly detection to measure the degree of approximation. We first closely examine the performance variation and then show that previous hypotheses about samples do not correlate well with the variation, but our introduced anomaly scores do. The results are the first to empirically support the link between the performance and the core assumption of MBR decoding.
JMultiWOZ: A Large-Scale Japanese Multi-Domain Task-Oriented Dialogue Dataset
Mar 26, 2024



Dialogue datasets are crucial for deep learning-based task-oriented dialogue system research. While numerous English language multi-domain task-oriented dialogue datasets have been developed and contributed to significant advancements in task-oriented dialogue systems, such a dataset does not exist in Japanese, and research in this area is limited compared to that in English. In this study, towards the advancement of research and development of task-oriented dialogue systems in Japanese, we constructed JMultiWOZ, the first Japanese language large-scale multi-domain task-oriented dialogue dataset. Using JMultiWOZ, we evaluated the dialogue state tracking and response generation capabilities of the state-of-the-art methods on the existing major English benchmark dataset MultiWOZ2.2 and the latest large language model (LLM)-based methods. Our evaluation results demonstrated that JMultiWOZ provides a benchmark that is on par with MultiWOZ2.2. In addition, through evaluation experiments of interactive dialogues with the models and human participants, we identified limitations in the task completion capabilities of LLMs in Japanese.
Team Flow at DRC2023: Building Common Ground and Text-based Turn-taking in a Travel Agent Spoken Dialogue System
Dec 21, 2023At the Dialogue Robot Competition 2023 (DRC2023), which was held to improve the capability of dialogue robots, our team developed a system that could build common ground and take more natural turns based on user utterance texts. Our system generated queries for sightseeing spot searches using the common ground and engaged in dialogue while waiting for user comprehension.
Team Flow at DRC2022: Pipeline System for Travel Destination Recommendation Task in Spoken Dialogue
Oct 18, 2022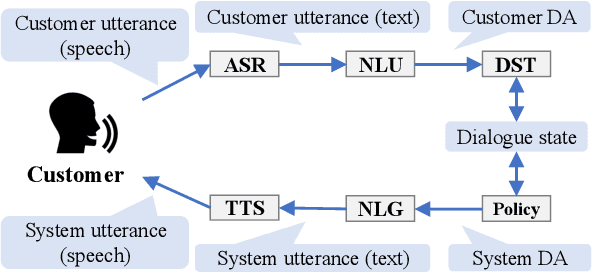

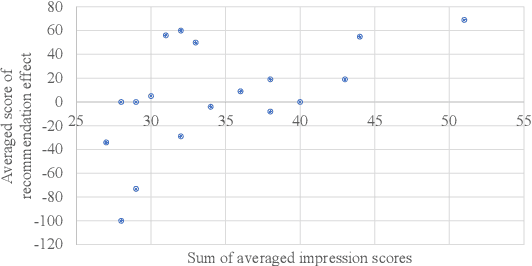

To improve the interactive capabilities of a dialogue system, e.g., to adapt to different customers, the Dialogue Robot Competition (DRC2022) was held. As one of the teams, we built a dialogue system with a pipeline structure containing four modules. The natural language understanding (NLU) and natural language generation (NLG) modules were GPT-2 based models, and the dialogue state tracking (DST) and policy modules were designed on the basis of hand-crafted rules. After the preliminary round of the competition, we found that the low variation in training examples for the NLU and failed recommendation due to the policy used were probably the main reasons for the limited performance of the system.
Adaptive Natural Language Generation for Task-oriented Dialogue via Reinforcement Learning
Sep 16, 2022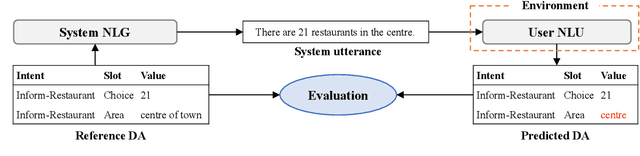
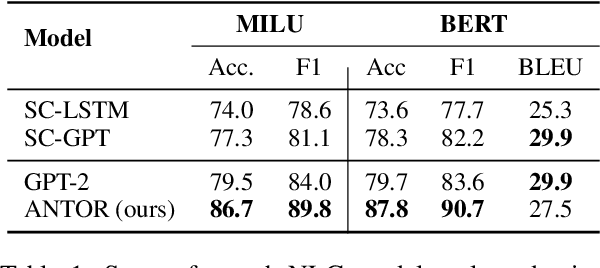
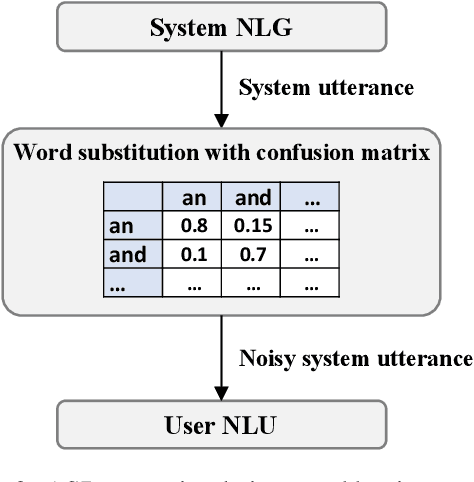
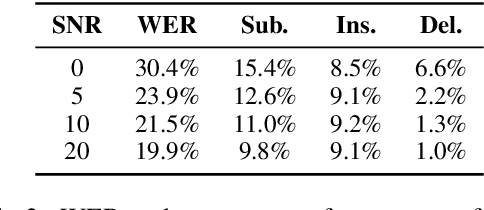
When a natural language generation (NLG) component is implemented in a real-world task-oriented dialogue system, it is necessary to generate not only natural utterances as learned on training data but also utterances adapted to the dialogue environment (e.g., noise from environmental sounds) and the user (e.g., users with low levels of understanding ability). Inspired by recent advances in reinforcement learning (RL) for language generation tasks, we propose ANTOR, a method for Adaptive Natural language generation for Task-Oriented dialogue via Reinforcement learning. In ANTOR, a natural language understanding (NLU) module, which corresponds to the user's understanding of system utterances, is incorporated into the objective function of RL. If the NLG's intentions are correctly conveyed to the NLU, which understands a system's utterances, the NLG is given a positive reward. We conducted experiments on the MultiWOZ dataset, and we confirmed that ANTOR could generate adaptive utterances against speech recognition errors and the different vocabulary levels of users.
Post-processing Networks: Method for Optimizing Pipeline Task-oriented Dialogue Systems using Reinforcement Learning
Jul 25, 2022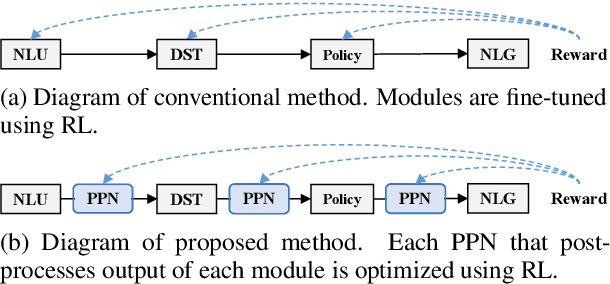

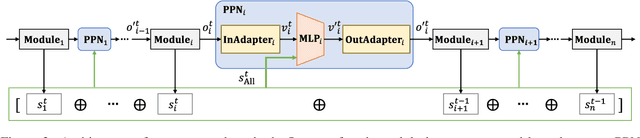
Many studies have proposed methods for optimizing the dialogue performance of an entire pipeline task-oriented dialogue system by jointly training modules in the system using reinforcement learning. However, these methods are limited in that they can only be applied to modules implemented using trainable neural-based methods. To solve this problem, we propose a method for optimizing a pipeline system composed of modules implemented with arbitrary methods for dialogue performance. With our method, neural-based components called post-processing networks (PPNs) are installed inside such a system to post-process the output of each module. All PPNs are updated to improve the overall dialogue performance of the system by using reinforcement learning, not necessitating each module to be differentiable. Through dialogue simulation and human evaluation on the MultiWOZ dataset, we show that our method can improve the dialogue performance of pipeline systems consisting of various modules.