 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph-Guided Reasoning for Multi-Hop Question Answering in Large Language Models
Nov 16, 2023
Chain-of-Thought (CoT) prompting has boosted the multi-step reasoning capabilities of Large Language Models (LLMs) by generating a series of rationales before the final answer. We analyze the reasoning paths generated by CoT and find two issues in multi-step reasoning: (i) Generating rationales irrelevant to the question, (ii) Unable to compose subquestions or queries for generating/retrieving all the relevant information. To address them, we propose a graph-guided CoT prompting method, which guides the LLMs to reach the correct answer with graph representation/verification steps. Specifically, we first leverage LLMs to construct a "question/rationale graph" by using knowledge extraction prompting given the initial question and the rationales generated in the previous steps. Then, the graph verification step diagnoses the current rationale triplet by comparing it with the existing question/rationale graph to filter out irrelevant rationales and generate follow-up questions to obtain relevant information. Additionally, we generate CoT paths that exclude the extracted graph information to represent the context information missed from the graph extraction. Our graph-guided reasoning method shows superior performance compared to previous CoT prompting and the variants on multi-hop question answering benchmark datasets.
OCT2Confocal: 3D CycleGAN based Translation of Retinal OCT Images to Confocal Microscopy
Nov 26, 2023Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, each presenting unique benefits and limitations. In vivo OCT offers rapid, non-invasive imaging but can be hampered by clarity issues and motion artifacts. Ex vivo confocal microscopy provides high-resolution, cellular detailed color images but is invasive and poses ethical concerns and potential tissue damage. To bridge these modalities, we developed a 3D CycleGAN framework for unsupervised translation of in vivo OCT to ex vivo confocal microscopy images. Applied to our OCT2Confocal dataset, this framework effectively translates between 3D medical data domains, capturing vascular, textural, and cellular details with precision. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. Assessed through quantitative and qualitative metrics, the 3D CycleGAN framework demonstrates commendable image fidelity and quality, outperforming existing methods despite the constraints of limited data. This non-invasive generation of retinal confocal images has the potential to further enhance diagnostic and monitoring capabilities in ophthalmology.
An Intelligent-Detection Network for Handwritten Mathematical Expression Recognition
Nov 26, 2023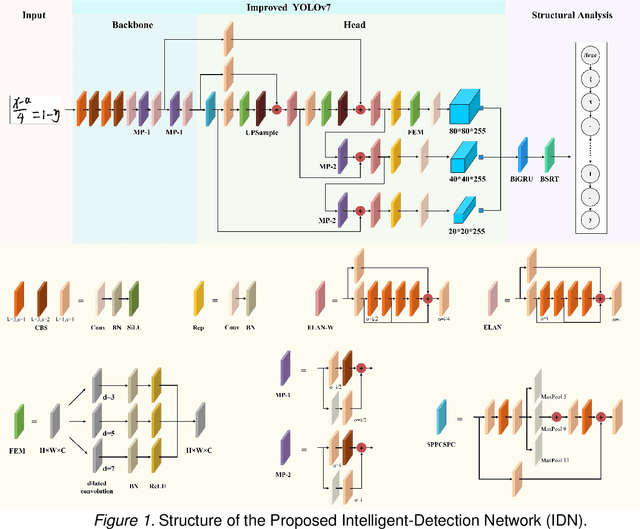

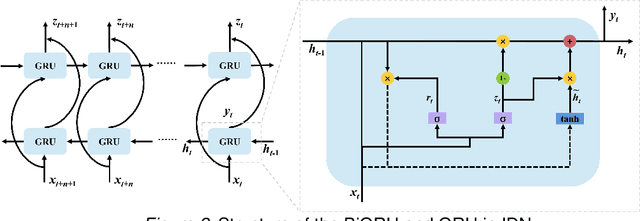
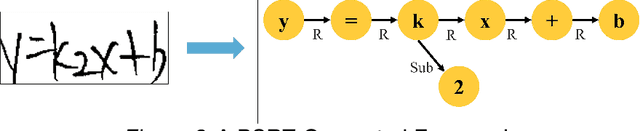
The use of artificial intelligence technology in education is growing rapidly, with increasing attention being paid to handwritten mathematical expression recognition (HMER) by researchers. However, many existing methods for HMER may fail to accurately read formulas with complex structures, as the attention results can be inaccurate due to illegible handwriting or large variations in writing styles. Our proposed Intelligent-Detection Network (IDN) for HMER differs from traditional encoder-decoder methods by utilizing object detection techniques. Specifically, we have developed an enhanced YOLOv7 network that can accurately detect both digital and symbolic objects. The detection results are then integrated into the bidirectional gated recurrent unit (BiGRU) and the baseline symbol relationship tree (BSRT) to determine the relationships between symbols and numbers. The experiments demonstrate that the proposed method outperforms those encoder-decoder networks in recognizing complex handwritten mathematical expressions. This is due to the precise detection of symbols and numbers. Our research has the potential to make valuable contributions to the field of HMER. This could be applied in various practical scenarios, such as assignment grading in schools and information entry of paper documents.
Fine-grained Appearance Transfer with Diffusion Models
Nov 27, 2023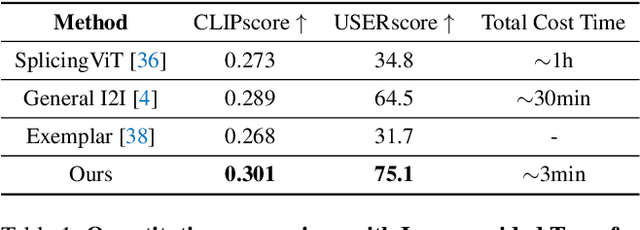

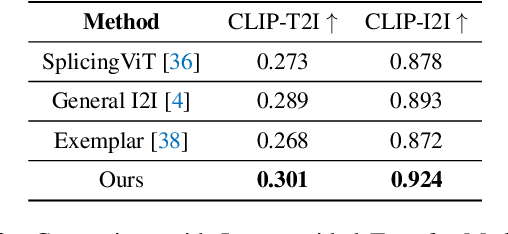
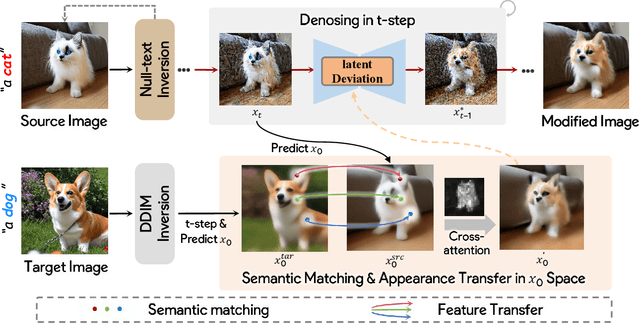
Image-to-image translation (I2I), and particularly its subfield of appearance transfer, which seeks to alter the visual appearance between images while maintaining structural coherence, presents formidable challenges. Despite significant advancements brought by diffusion models, achieving fine-grained transfer remains complex, particularly in terms of retaining detailed structural elements and ensuring information fidelity. This paper proposes an innovative framework designed to surmount these challenges by integrating various aspects of semantic matching, appearance transfer, and latent deviation. A pivotal aspect of our approach is the strategic use of the predicted $x_0$ space by diffusion models within the latent space of diffusion processes. This is identified as a crucial element for the precise and natural transfer of fine-grained details. Our framework exploits this space to accomplish semantic alignment between source and target images, facilitating mask-wise appearance transfer for improved feature acquisition. A significant advancement of our method is the seamless integration of these features into the latent space, enabling more nuanced latent deviations without necessitating extensive model retraining or fine-tuning. The effectiveness of our approach is demonstrated through extensive experiments, which showcase its ability to adeptly handle fine-grained appearance transfers across a wide range of categories and domains. We provide our code at https://github.com/babahui/Fine-grained-Appearance-Transfer
SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution
Nov 27, 2023Owe to the powerful generative priors, the pre-trained text-to-image (T2I) diffusion models have become increasingly popular in solving the real-world image super-resolution problem. However, as a consequence of the heavy quality degradation of input low-resolution (LR) images, the destruction of local structures can lead to ambiguous image semantics. As a result, the content of reproduced high-resolution image may have semantic errors, deteriorating the super-resolution performance. To address this issue, we present a semantics-aware approach to better preserve the semantic fidelity of generative real-world image super-resolution. First, we train a degradation-aware prompt extractor, which can generate accurate soft and hard semantic prompts even under strong degradation. The hard semantic prompts refer to the image tags, aiming to enhance the local perception ability of the T2I model, while the soft semantic prompts compensate for the hard ones to provide additional representation information. These semantic prompts can encourage the T2I model to generate detailed and semantically accurate results. Furthermore, during the inference process, we integrate the LR images into the initial sampling noise to mitigate the diffusion model's tendency to generate excessive random details. The experiments show that our method can reproduce more realistic image details and hold better the semantics.
Source-Free Domain Adaptation with Frozen Multimodal Foundation Model
Nov 27, 2023Source-Free Domain Adaptation (SFDA) aims to adapt a source model for a target domain, with only access to unlabeled target training data and the source model pre-trained on a supervised source domain. Relying on pseudo labeling and/or auxiliary supervision, conventional methods are inevitably error-prone. To mitigate this limitation, in this work we for the first time explore the potentials of off-the-shelf vision-language (ViL) multimodal models (e.g.,CLIP) with rich whilst heterogeneous knowledge. We find that directly applying the ViL model to the target domain in a zero-shot fashion is unsatisfactory, as it is not specialized for this particular task but largely generic. To make it task specific, we propose a novel Distilling multimodal Foundation model(DIFO)approach. Specifically, DIFO alternates between two steps during adaptation: (i) Customizing the ViL model by maximizing the mutual information with the target model in a prompt learning manner, (ii) Distilling the knowledge of this customized ViL model to the target model. For more fine-grained and reliable distillation, we further introduce two effective regularization terms, namely most-likely category encouragement and predictive consistency. Extensive experiments show that DIFO significantly outperforms the state-of-the-art alternatives. Our source code will be released.
Can Vision-Language Models Think from a First-Person Perspective?
Nov 27, 2023Vision-language models (VLMs) have recently shown promising results in traditional downstream tasks. Evaluation studies have emerged to assess their abilities, with the majority focusing on the third-person perspective, and only a few addressing specific tasks from the first-person perspective. However, the capability of VLMs to "think" from a first-person perspective, a crucial attribute for advancing autonomous agents and robotics, remains largely unexplored. To bridge this research gap, we introduce EgoThink, a novel visual question-answering benchmark that encompasses six core capabilities with twelve detailed dimensions. The benchmark is constructed using selected clips from egocentric videos, with manually annotated question-answer pairs containing first-person information. To comprehensively assess VLMs, we evaluate eighteen popular VLMs on EgoThink. Moreover, given the open-ended format of the answers, we use GPT-4 as the automatic judge to compute single-answer grading. Experimental results indicate that although GPT-4V leads in numerous dimensions, all evaluated VLMs still possess considerable potential for improvement in first-person perspective tasks. Meanwhile, enlarging the number of trainable parameters has the most significant impact on model performance on EgoThink. In conclusion, EgoThink serves as a valuable addition to existing evaluation benchmarks for VLMs, providing an indispensable resource for future research in the realm of embodied artificial intelligence and robotics.
UFDA: Universal Federated Domain Adaptation with Practical Assumptions
Nov 27, 2023Conventional Federated Domain Adaptation (FDA) approaches usually demand an abundance of assumptions, such as label set consistency, which makes them significantly less feasible for real-world situations and introduces security hazards. In this work, we propose a more practical scenario named Universal Federated Domain Adaptation (UFDA). It only requires the black-box model and the label set information of each source domain, while the label sets of different source domains could be inconsistent and the target-domain label set is totally blind. This relaxes the assumptions made by FDA, which are often challenging to meet in real-world cases and diminish model security. To address the UFDA scenario, we propose a corresponding framework called Hot-Learning with Contrastive Label Disambiguation (HCLD), which tackles UFDA's domain shifts and category gaps problem by using one-hot outputs from the black-box models of various source domains. Moreover, to better distinguish the shared and unknown classes, we further present a cluster-level strategy named Mutual-Voting Decision (MVD) to extract robust consensus knowledge across peer classes from both source and target domains. The extensive experiments on three benchmarks demonstrate that our HCLD achieves comparable performance for our UFDA scenario with much fewer assumptions, compared to the previous methodologies with many additional assumptions.
Optimization of Image Processing Algorithms for Character Recognition in Cultural Typewritten Documents
Nov 27, 2023Linked Data is used in various fields as a new way of structuring and connecting data. Cultural heritage institutions have been using linked data to improve archival descriptions and facilitate the discovery of information. Most archival records have digital representations of physical artifacts in the form of scanned images that are non-machine-readable. Optical Character Recognition (OCR) recognizes text in images and translates it into machine-encoded text. This paper evaluates the impact of image processing methods and parameter tuning in OCR applied to typewritten cultural heritage documents. The approach uses a multi-objective problem formulation to minimize Levenshtein edit distance and maximize the number of words correctly identified with a non-dominated sorting genetic algorithm (NSGA-II) to tune the methods' parameters. Evaluation results show that parameterization by digital representation typology benefits the performance of image pre-processing algorithms in OCR. Furthermore, our findings suggest that employing image pre-processing algorithms in OCR might be more suitable for typologies where the text recognition task without pre-processing does not produce good results. In particular, Adaptive Thresholding, Bilateral Filter, and Opening are the best-performing algorithms for the theatre plays' covers, letters, and overall dataset, respectively, and should be applied before OCR to improve its performance.
* 25 pages, 4 figures
Leveraging Out-of-Domain Data for Domain-Specific Prompt Tuning in Multi-Modal Fake News Detection
Nov 27, 2023The spread of fake news using out-of-context images has become widespread and is a challenging task in this era of information overload. Since annotating huge amounts of such data requires significant time of domain experts, it is imperative to develop methods which can work in limited annotated data scenarios. In this work, we explore whether out-of-domain data can help to improve out-of-context misinformation detection (termed here as multi-modal fake news detection) of a desired domain, eg. politics, healthcare, etc. Towards this goal, we propose a novel framework termed DPOD (Domain-specific Prompt-tuning using Out-of-Domain data). First, to compute generalizable features, we modify the Vision-Language Model, CLIP to extract features that helps to align the representations of the images and corresponding text captions of both the in-domain and out-of-domain data in a label-aware manner. Further, we propose a domain-specific prompt learning technique which leverages the training samples of all the available domains based on the the extent they can be useful to the desired domain. Extensive experiments on a large-scale benchmark dataset, namely NewsClippings demonstrate that the proposed framework achieves state of-the-art performance, significantly surpassing the existing approaches for this challenging task.