 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedIDM: Achieving Fast and Stable Convergence in Byzantine Federated Learning through Iterative Distribution Matching
Apr 16, 2026Most existing Byzantine-robust federated learning (FL) methods suffer from slow and unstable convergence. Moreover, when handling a substantial proportion of colluded malicious clients, achieving robustness typically entails compromising model utility. To address these issues, this work introduces FedIDM, which employs distribution matching to construct trustworthy condensed data for identifying and filtering abnormal clients. FedIDM consists of two main components: (1) attack-tolerant condensed data generation, and (2) robust aggregation with negative contribution-based rejection. These components exclude local updates that (1) deviate from the update direction derived from condensed data, or (2) cause a significant loss on the condensed dataset. Comprehensive evaluations on three benchmark datasets demonstrate that FedIDM achieves fast and stable convergence while maintaining acceptable model utility, under multiple state-of-the-art Byzantine attacks involving a large number of malicious clients.
SNEAKDOOR: Stealthy Backdoor Attacks against Distribution Matching-based Dataset Condensation
Mar 29, 2026Dataset condensation aims to synthesize compact yet informative datasets that retain the training efficacy of full-scale data, offering substantial gains in efficiency. Recent studies reveal that the condensation process can be vulnerable to backdoor attacks, where malicious triggers are injected into the condensation dataset, manipulating model behavior during inference. While prior approaches have made progress in balancing attack success rate and clean test accuracy, they often fall short in preserving stealthiness, especially in concealing the visual artifacts of condensed data or the perturbations introduced during inference. To address this challenge, we introduce Sneakdoor, which enhances stealthiness without compromising attack effectiveness. Sneakdoor exploits the inherent vulnerability of class decision boundaries and incorporates a generative module that constructs input-aware triggers aligned with local feature geometry, thereby minimizing detectability. This joint design enables the attack to remain imperceptible to both human inspection and statistical detection. Extensive experiments across multiple datasets demonstrate that Sneakdoor achieves a compelling balance among attack success rate, clean test accuracy, and stealthiness, substantially improving the invisibility of both the synthetic data and triggered samples while maintaining high attack efficacy. The code is available at https://github.com/XJTU-AI-Lab/SneakDoor.
UFDA: Universal Federated Domain Adaptation with Practical Assumptions
Nov 27, 2023



Conventional Federated Domain Adaptation (FDA) approaches usually demand an abundance of assumptions, such as label set consistency, which makes them significantly less feasible for real-world situations and introduces security hazards. In this work, we propose a more practical scenario named Universal Federated Domain Adaptation (UFDA). It only requires the black-box model and the label set information of each source domain, while the label sets of different source domains could be inconsistent and the target-domain label set is totally blind. This relaxes the assumptions made by FDA, which are often challenging to meet in real-world cases and diminish model security. To address the UFDA scenario, we propose a corresponding framework called Hot-Learning with Contrastive Label Disambiguation (HCLD), which tackles UFDA's domain shifts and category gaps problem by using one-hot outputs from the black-box models of various source domains. Moreover, to better distinguish the shared and unknown classes, we further present a cluster-level strategy named Mutual-Voting Decision (MVD) to extract robust consensus knowledge across peer classes from both source and target domains. The extensive experiments on three benchmarks demonstrate that our HCLD achieves comparable performance for our UFDA scenario with much fewer assumptions, compared to the previous methodologies with many additional assumptions.
Dual-Decoder Transformer For end-to-end Mandarin Chinese Speech Recognition with Pinyin and Character
Jan 26, 2022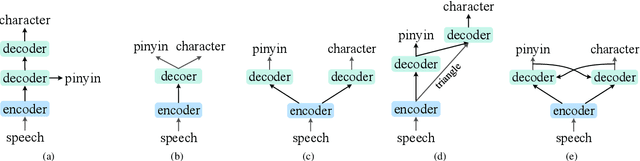
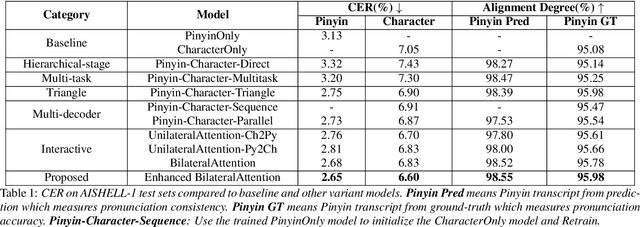
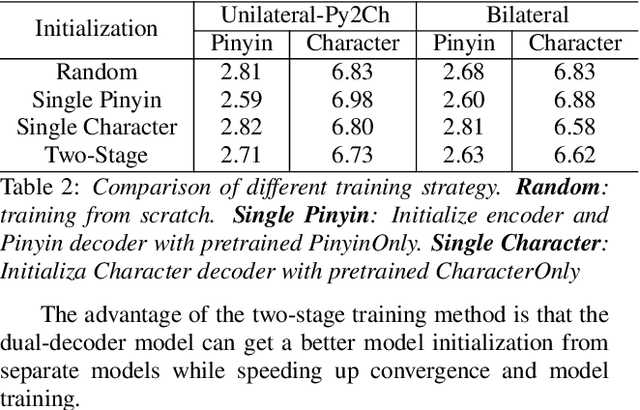
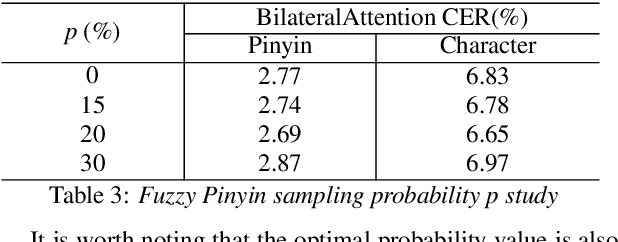
End-to-end automatic speech recognition (ASR) has achieved promising results. However, most existing end-to-end ASR methods neglect the use of specific language characteristics. For Mandarin Chinese ASR tasks, pinyin and character as writing and spelling systems respectively are mutual promotion in the Mandarin Chinese language. Based on the above intuition, we investigate types of related models that are suitable but not for joint pinyin-character ASR and propose a novel Mandarin Chinese ASR model with dual-decoder Transformer according to the characteristics of the pinyin transcripts and character transcripts. Specifically, the joint pinyin-character layer-wise linear interactive (LWLI) module and phonetic posteriorgrams adapter (PPGA) are proposed to achieve inter-layer multi-level interaction by adaptively fusing pinyin and character information. Furthermore, a two-stage training strategy is proposed to make training more stable and faster convergence. The results on the test sets of AISHELL-1 dataset show that the proposed Speech-Pinyin-Character-Interaction (SPCI) model without a language model achieves 9.85% character error rate (CER) on the test set, which is 17.71% relative reduction compared to baseline models based on Transformer.