 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttriStory: Fine-grained Attribute Realization for Visual Storytelling with Diffusion Models
May 20, 2026Visual storytelling with diffusion models has made impressive strides in maintaining character consistency across narrative scenes. However, a critical gap remains: while these methods ensure a character remains consistent across scenes, they provide no systematic method to ensure if fine-grained attributes such as color and textures of clothing, accessories are faithfully rendered in the generated images. Towards this goal, we introduce AttriStory, a benchmark enabling attribute realization in visual storytelling. We curate 200 multi-scene stories across 10 distinct artistic styles using Large Language Model. Each scene is constructed with detailed attribute specifications to enable rich visual narratives. Further, to address attribute realization, we propose a plug-and-play latent optimization module that operates during early denoising steps, when the model establishes structural and semantic content. We achieve this through AttriLoss objective designed to maximize alignment between the cross-attention maps for desired attribute-object pairs while suppressing spurious associations, guiding models to localize attributes correctly. This approach operates orthogonally to existing consistency mechanisms, integrating seamlessly with current story generation pipelines without requiring architectural modifications. Our experiments demonstrate consistent improvements on incorporating AttriLoss across all baselines. This work positions attribute realization as a distinct, complementary dimension of visual storytelling, alongside character consistency, advancing the field toward fine-grained attribute-controlled story generation. Project-page:https://manogna-s.github.io/attristory/
Segmentation Assisted Incremental Test Time Adaptation in an Open World
Aug 27, 2025



In dynamic environments, unfamiliar objects and distribution shifts are often encountered, which challenge the generalization abilities of the deployed trained models. This work addresses Incremental Test Time Adaptation of Vision Language Models, tackling scenarios where unseen classes and unseen domains continuously appear during testing. Unlike traditional Test Time Adaptation approaches, where the test stream comes only from a predefined set of classes, our framework allows models to adapt simultaneously to both covariate and label shifts, actively incorporating new classes as they emerge. Towards this goal, we establish a new benchmark for ITTA, integrating single image TTA methods for VLMs with active labeling techniques that query an oracle for samples potentially representing unseen classes during test time. We propose a segmentation assisted active labeling module, termed SegAssist, which is training free and repurposes the segmentation capabilities of VLMs to refine active sample selection, prioritizing samples likely to belong to unseen classes. Extensive experiments on several benchmark datasets demonstrate the potential of SegAssist to enhance the performance of VLMs in real world scenarios, where continuous adaptation to emerging data is essential. Project-page:https://manogna-s.github.io/segassist/
Multiple Stochastic Prompt Tuning for Practical Cross-Domain Few Shot Learning
Jun 04, 2025In this work, we propose a practical cross-domain few-shot learning (pCDFSL) task, where a large-scale pre-trained model like CLIP can be easily deployed on a target dataset. The goal is to simultaneously classify all unseen classes under extreme domain shifts, by utilizing only a few labeled samples per class. The pCDFSL paradigm is source-free and moves beyond artificially created episodic training and testing regimes followed by existing CDFSL frameworks, making it more challenging and relevant to real-world applications. Towards that goal, we propose a novel framework, termed MIST (MultIple STochastic Prompt tuning), where multiple stochastic prompts are utilized to handle significant domain and semantic shifts. Specifically, multiple prompts are learnt for each class, effectively capturing multiple peaks in the input data. Furthermore, instead of representing the weights of the multiple prompts as point-estimates, we model them as learnable Gaussian distributions with two different strategies, encouraging an efficient exploration of the prompt parameter space, which mitigate overfitting due to the few labeled training samples. Extensive experiments and comparison with the state-of-the-art methods on four CDFSL benchmarks adapted to this setting, show the effectiveness of the proposed framework.
Prompt Tuning Vision Language Models with Margin Regularizer for Few-Shot Learning under Distribution Shifts
May 21, 2025Recently, Vision-Language foundation models like CLIP and ALIGN, which are pre-trained on large-scale data have shown remarkable zero-shot generalization to diverse datasets with different classes and even domains. In this work, we take a step further and analyze whether these models can be adapted to target datasets having very different distributions and classes compared to what these models have been trained on, using only a few labeled examples from the target dataset. In such scenarios, finetuning large pretrained models is challenging due to problems of overfitting as well as loss of generalization, and has not been well explored in prior literature. Since, the pre-training data of such models are unavailable, it is difficult to comprehend the performance on various downstream datasets. First, we try to answer the question: Given a target dataset with a few labelled examples, can we estimate whether further fine-tuning can enhance the performance compared to zero-shot evaluation? by analyzing the common vision-language embedding space. Based on the analysis, we propose a novel prompt-tuning method, PromptMargin for adapting such large-scale VLMs directly on the few target samples. PromptMargin effectively tunes the text as well as visual prompts for this task, and has two main modules: 1) Firstly, we use a selective augmentation strategy to complement the few training samples in each task; 2) Additionally, to ensure robust training in the presence of unfamiliar class names, we increase the inter-class margin for improved class discrimination using a novel Multimodal Margin Regularizer. Extensive experiments and analysis across fifteen target benchmark datasets, with varying degrees of distribution shifts from natural images, shows the effectiveness of the proposed framework over the existing state-of-the-art approaches applied to this setting. github.com/debarshigit/PromptMargin.
CoVLM: Leveraging Consensus from Vision-Language Models for Semi-supervised Multi-modal Fake News Detection
Oct 06, 2024



In this work, we address the real-world, challenging task of out-of-context misinformation detection, where a real image is paired with an incorrect caption for creating fake news. Existing approaches for this task assume the availability of large amounts of labeled data, which is often impractical in real-world, since it requires extensive manual intervention and domain expertise. In contrast, since obtaining a large corpus of unlabeled image-text pairs is much easier, here, we propose a semi-supervised protocol, where the model has access to a limited number of labeled image-text pairs and a large corpus of unlabeled pairs. Additionally, the occurrence of fake news being much lesser compared to the real ones, the datasets tend to be highly imbalanced, thus making the task even more challenging. Towards this goal, we propose a novel framework, Consensus from Vision-Language Models (CoVLM), which generates robust pseudo-labels for unlabeled pairs using thresholds derived from the labeled data. This approach can automatically determine the right threshold parameters of the model for selecting the confident pseudo-labels. Experimental results on benchmark datasets across challenging conditions and comparisons with state-of-the-art approaches demonstrate the effectiveness of our framework.
AggSS: An Aggregated Self-Supervised Approach for Class-Incremental Learning
Aug 08, 2024



This paper investigates the impact of self-supervised learning, specifically image rotations, on various class-incremental learning paradigms. Here, each image with a predefined rotation is considered as a new class for training. At inference, all image rotation predictions are aggregated for the final prediction, a strategy we term Aggregated Self-Supervision (AggSS). We observe a shift in the deep neural network's attention towards intrinsic object features as it learns through AggSS strategy. This learning approach significantly enhances class-incremental learning by promoting robust feature learning. AggSS serves as a plug-and-play module that can be seamlessly incorporated into any class-incremental learning framework, leveraging its powerful feature learning capabilities to enhance performance across various class-incremental learning approaches. Extensive experiments conducted on standard incremental learning datasets CIFAR-100 and ImageNet-Subset demonstrate the significant role of AggSS in improving performance within these paradigms.
TACLE: Task and Class-aware Exemplar-free Semi-supervised Class Incremental Learning
Jul 10, 2024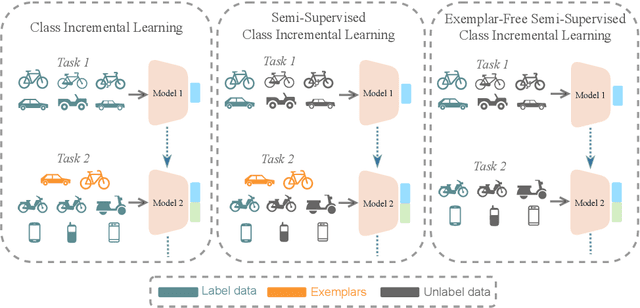
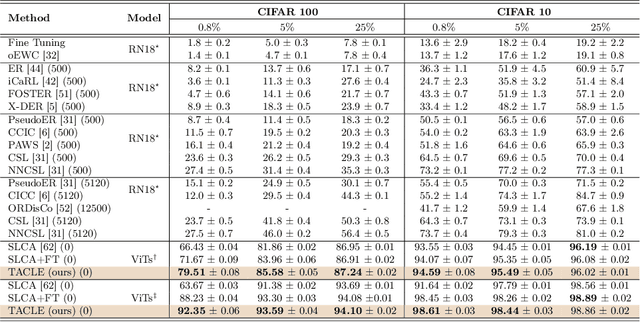
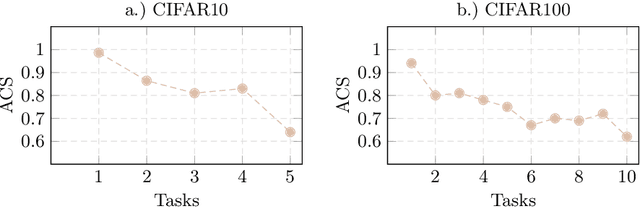
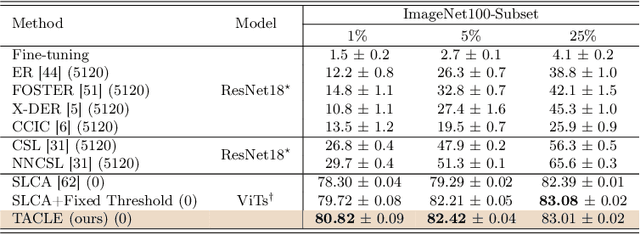
We propose a novel TACLE (TAsk and CLass-awarE) framework to address the relatively unexplored and challenging problem of exemplar-free semi-supervised class incremental learning. In this scenario, at each new task, the model has to learn new classes from both (few) labeled and unlabeled data without access to exemplars from previous classes. In addition to leveraging the capabilities of pre-trained models, TACLE proposes a novel task-adaptive threshold, thereby maximizing the utilization of the available unlabeled data as incremental learning progresses. Additionally, to enhance the performance of the under-represented classes within each task, we propose a class-aware weighted cross-entropy loss. We also exploit the unlabeled data for classifier alignment, which further enhances the model performance. Extensive experiments on benchmark datasets, namely CIFAR10, CIFAR100, and ImageNet-Subset100 demonstrate the effectiveness of the proposed TACLE framework. We further showcase its effectiveness when the unlabeled data is imbalanced and also for the extreme case of one labeled example per class.
Effectiveness of Vision Language Models for Open-world Single Image Test Time Adaptation
Jun 01, 2024



We propose a novel framework to address the real-world challenging task of Single Image Test Time Adaptation in an open and dynamic environment. We leverage large scale Vision Language Models like CLIP to enable real time adaptation on a per-image basis without access to source data or ground truth labels. Since the deployed model can also encounter unseen classes in an open world, we first employ a simple and effective Out of Distribution (OOD) detection module to distinguish between weak and strong OOD samples. We propose a novel contrastive learning based objective to enhance the discriminability between weak and strong OOD samples by utilizing small, dynamically updated feature banks. Finally, we also employ a classification objective for adapting the model using the reliable weak OOD samples. The proposed framework ROSITA combines these components, enabling continuous online adaptation of Vision Language Models on a single image basis. Extensive experimentation on diverse domain adaptation benchmarks validates the effectiveness of the proposed framework. Our code can be found at the project site https://manogna-s.github.io/rosita/
Leveraging Out-of-Domain Data for Domain-Specific Prompt Tuning in Multi-Modal Fake News Detection
Nov 27, 2023The spread of fake news using out-of-context images has become widespread and is a challenging task in this era of information overload. Since annotating huge amounts of such data requires significant time of domain experts, it is imperative to develop methods which can work in limited annotated data scenarios. In this work, we explore whether out-of-domain data can help to improve out-of-context misinformation detection (termed here as multi-modal fake news detection) of a desired domain, eg. politics, healthcare, etc. Towards this goal, we propose a novel framework termed DPOD (Domain-specific Prompt-tuning using Out-of-Domain data). First, to compute generalizable features, we modify the Vision-Language Model, CLIP to extract features that helps to align the representations of the images and corresponding text captions of both the in-domain and out-of-domain data in a label-aware manner. Further, we propose a domain-specific prompt learning technique which leverages the training samples of all the available domains based on the the extent they can be useful to the desired domain. Extensive experiments on a large-scale benchmark dataset, namely NewsClippings demonstrate that the proposed framework achieves state of-the-art performance, significantly surpassing the existing approaches for this challenging task.
Robust Feature Learning and Global Variance-Driven Classifier Alignment for Long-Tail Class Incremental Learning
Nov 02, 2023



This paper introduces a two-stage framework designed to enhance long-tail class incremental learning, enabling the model to progressively learn new classes, while mitigating catastrophic forgetting in the context of long-tailed data distributions. Addressing the challenge posed by the under-representation of tail classes in long-tail class incremental learning, our approach achieves classifier alignment by leveraging global variance as an informative measure and class prototypes in the second stage. This process effectively captures class properties and eliminates the need for data balancing or additional layer tuning. Alongside traditional class incremental learning losses in the first stage, the proposed approach incorporates mixup classes to learn robust feature representations, ensuring smoother boundaries. The proposed framework can seamlessly integrate as a module with any class incremental learning method to effectively handle long-tail class incremental learning scenarios. Extensive experimentation on the CIFAR-100 and ImageNet-Subset datasets validates the approach's efficacy, showcasing its superiority over state-of-the-art techniques across various long-tail CIL settings.