 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Visual Neglect: Steering via Context-Preference for MLLM Hallucination Mitigation
May 27, 2026Object hallucination remains a primary obstacle to the reliable deployment of Multimodal Large Language Models (MLLMs). Current inference-time mitigation methods mainly assume hallucinations stem from visual neglect, steering models to enhance visual reliance. In contrast, our systematic interventions on multiple MLLMs show that pushing toward more visual reliance may exacerbate hallucinations on some models, while less may mitigate hallucinations. This result suggests that attributing hallucinations solely to visual insufficiency is underdetermined. We argue that the image, as a context, simultaneously competes with the model's parametric knowledge and the textual context. For this, we propose a training-free framework, Context-Preference Activation Steering (CAS). It extracts two semantically distinct Context Preference Vectors (CPVs) via two small sets of designed conflict samples and applies them via single-pass signed residual injection at mid-early MLP layers during inference to control information reliance. Experiments show that CAS substantially mitigates object hallucinations without increasing decoding latency and preserves native text-generation quality.
Can Vision-Language Models Think from a First-Person Perspective?
Nov 27, 2023



Vision-language models (VLMs) have recently shown promising results in traditional downstream tasks. Evaluation studies have emerged to assess their abilities, with the majority focusing on the third-person perspective, and only a few addressing specific tasks from the first-person perspective. However, the capability of VLMs to "think" from a first-person perspective, a crucial attribute for advancing autonomous agents and robotics, remains largely unexplored. To bridge this research gap, we introduce EgoThink, a novel visual question-answering benchmark that encompasses six core capabilities with twelve detailed dimensions. The benchmark is constructed using selected clips from egocentric videos, with manually annotated question-answer pairs containing first-person information. To comprehensively assess VLMs, we evaluate eighteen popular VLMs on EgoThink. Moreover, given the open-ended format of the answers, we use GPT-4 as the automatic judge to compute single-answer grading. Experimental results indicate that although GPT-4V leads in numerous dimensions, all evaluated VLMs still possess considerable potential for improvement in first-person perspective tasks. Meanwhile, enlarging the number of trainable parameters has the most significant impact on model performance on EgoThink. In conclusion, EgoThink serves as a valuable addition to existing evaluation benchmarks for VLMs, providing an indispensable resource for future research in the realm of embodied artificial intelligence and robotics.
Dual-Space Attacks against Random-Walk-based Anomaly Detection
Jul 26, 2023



Random Walks-based Anomaly Detection (RWAD) is commonly used to identify anomalous patterns in various applications. An intriguing characteristic of RWAD is that the input graph can either be pre-existing or constructed from raw features. Consequently, there are two potential attack surfaces against RWAD: graph-space attacks and feature-space attacks. In this paper, we explore this vulnerability by designing practical dual-space attacks, investigating the interplay between graph-space and feature-space attacks. To this end, we conduct a thorough complexity analysis, proving that attacking RWAD is NP-hard. Then, we proceed to formulate the graph-space attack as a bi-level optimization problem and propose two strategies to solve it: alternative iteration (alterI-attack) or utilizing the closed-form solution of the random walk model (cf-attack). Finally, we utilize the results from the graph-space attacks as guidance to design more powerful feature-space attacks (i.e., graph-guided attacks). Comprehensive experiments demonstrate that our proposed attacks are effective in enabling the target nodes from RWAD with a limited attack budget. In addition, we conduct transfer attack experiments in a black-box setting, which show that our feature attack significantly decreases the anomaly scores of target nodes. Our study opens the door to studying the dual-space attack against graph anomaly detection in which the graph space relies on the feature space.
FedGEMS: Federated Learning of Larger Server Models via Selective Knowledge Fusion
Oct 21, 2021
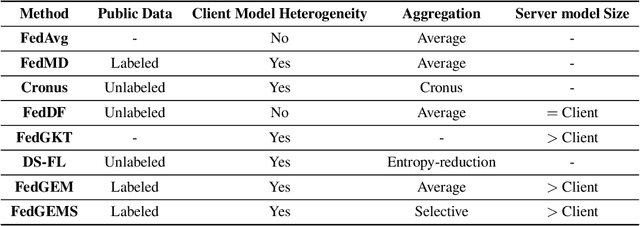
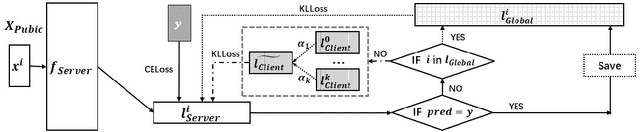
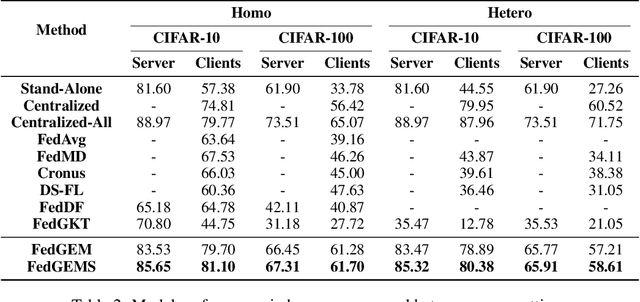
Today data is often scattered among billions of resource-constrained edge devices with security and privacy constraints. Federated Learning (FL) has emerged as a viable solution to learn a global model while keeping data private, but the model complexity of FL is impeded by the computation resources of edge nodes. In this work, we investigate a novel paradigm to take advantage of a powerful server model to break through model capacity in FL. By selectively learning from multiple teacher clients and itself, a server model develops in-depth knowledge and transfers its knowledge back to clients in return to boost their respective performance. Our proposed framework achieves superior performance on both server and client models and provides several advantages in a unified framework, including flexibility for heterogeneous client architectures, robustness to poisoning attacks, and communication efficiency between clients and server. By bridging FL effectively with larger server model training, our proposed paradigm paves ways for robust and continual knowledge accumulation from distributed and private data.