 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AS-MLP: An Axial Shifted MLP Architecture for Vision
Jul 18, 2021

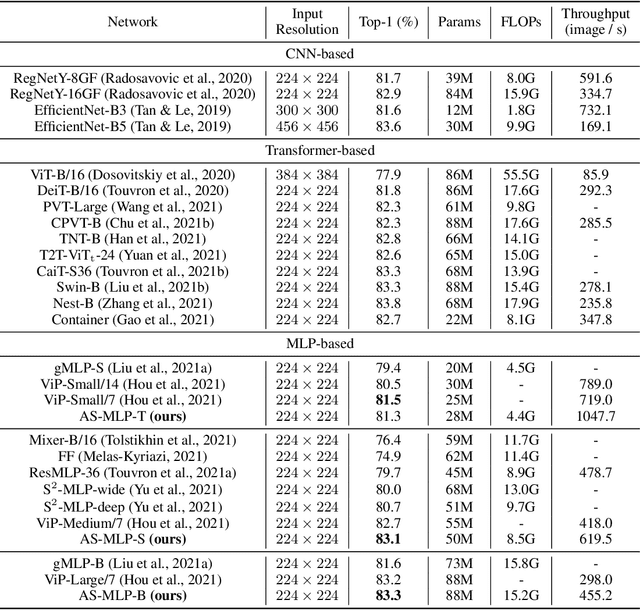
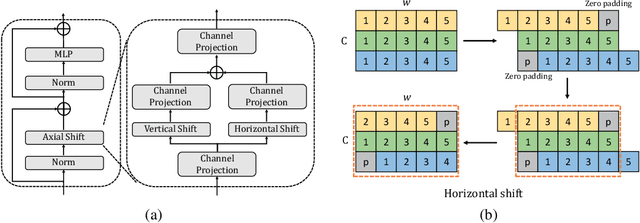
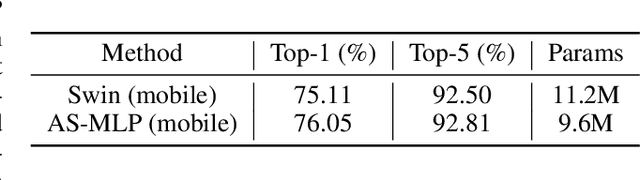
An Axial Shifted MLP architecture (AS-MLP) is proposed in this paper. Different from MLP-Mixer, where the global spatial feature is encoded for the information flow through matrix transposition and one token-mixing MLP, we pay more attention to the local features communication. By axially shifting channels of the feature map, AS-MLP is able to obtain the information flow from different axial directions, which captures the local dependencies. Such an operation enables us to utilize a pure MLP architecture to achieve the same local receptive field as CNN-like architecture. We can also design the receptive field size and dilation of blocks of AS-MLP, etc, just like designing those of convolution kernels. With the proposed AS-MLP architecture, our model obtains 83.3% Top-1 accuracy with 88M parameters and 15.2 GFLOPs on the ImageNet-1K dataset. Such a simple yet effective architecture outperforms all MLP-based architectures and achieves competitive performance compared to the transformer-based architectures (e.g., Swin Transformer) even with slightly lower FLOPs. In addition, AS-MLP is also the first MLP-based architecture to be applied to the downstream tasks (e.g., object detection and semantic segmentation). The experimental results are also impressive. Our proposed AS-MLP obtains 51.5 mAP on the COCO validation set and 49.5 MS mIoU on the ADE20K dataset, which is competitive compared to the transformer-based architectures. Code is available at https://github.com/svip-lab/AS-MLP.
Phase Retrieval using Single-Instance Deep Generative Prior
Jun 09, 2021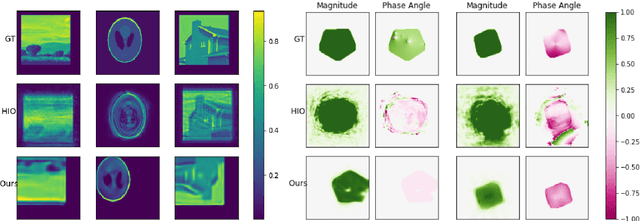
Several deep learning methods for phase retrieval exist, but most of them fail on realistic data without precise support information. We propose a novel method based on single-instance deep generative prior that works well on complex-valued crystal data.
OpenKI: Integrating Open Information Extraction and Knowledge Bases with Relation Inference
Apr 12, 2019
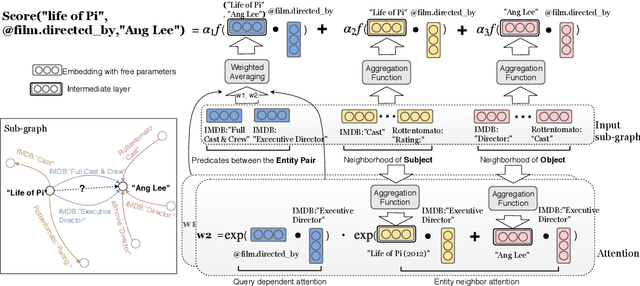
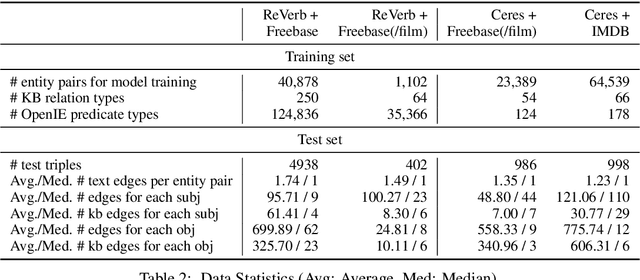
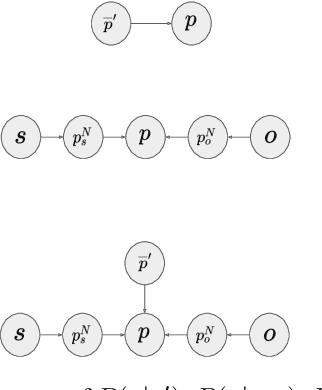
In this paper, we consider advancing web-scale knowledge extraction and alignment by integrating OpenIE extractions in the form of (subject, predicate, object) triples with Knowledge Bases (KB). Traditional techniques from universal schema and from schema mapping fall in two extremes: either they perform instance-level inference relying on embedding for (subject, object) pairs, thus cannot handle pairs absent in any existing triples; or they perform predicate-level mapping and completely ignore background evidence from individual entities, thus cannot achieve satisfying quality. We propose OpenKI to handle sparsity of OpenIE extractions by performing instance-level inference: for each entity, we encode the rich information in its neighborhood in both KB and OpenIE extractions, and leverage this information in relation inference by exploring different methods of aggregation and attention. In order to handle unseen entities, our model is designed without creating entity-specific parameters. Extensive experiments show that this method not only significantly improves state-of-the-art for conventional OpenIE extractions like ReVerb, but also boosts the performance on OpenIE from semi-structured data, where new entity pairs are abundant and data are fairly sparse.
Enhancing Visual Dialog Questioner with Entity-based Strategy Learning and Augmented Guesser
Sep 06, 2021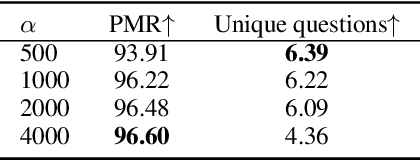
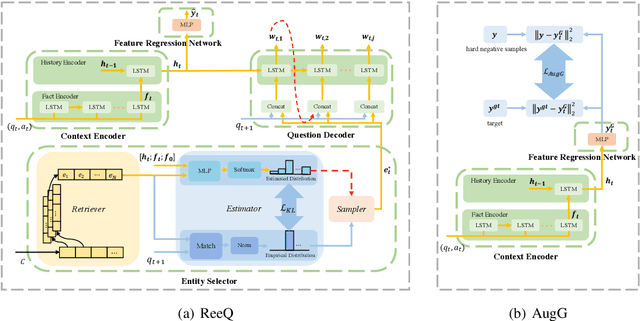
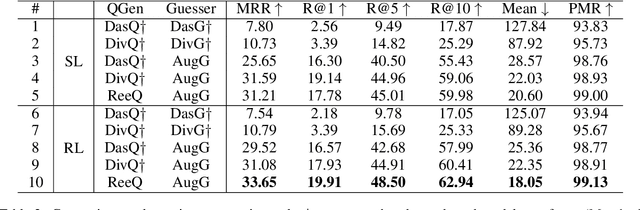
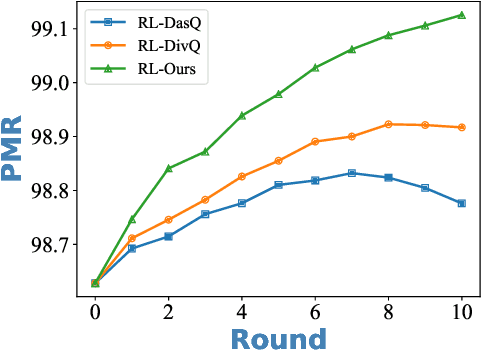
Considering the importance of building a good Visual Dialog (VD) Questioner, many researchers study the topic under a Q-Bot-A-Bot image-guessing game setting, where the Questioner needs to raise a series of questions to collect information of an undisclosed image. Despite progress has been made in Supervised Learning (SL) and Reinforcement Learning (RL), issues still exist. Firstly, previous methods do not provide explicit and effective guidance for Questioner to generate visually related and informative questions. Secondly, the effect of RL is hampered by an incompetent component, i.e., the Guesser, who makes image predictions based on the generated dialogs and assigns rewards accordingly. To enhance VD Questioner: 1) we propose a Related entity enhanced Questioner (ReeQ) that generates questions under the guidance of related entities and learns entity-based questioning strategy from human dialogs; 2) we propose an Augmented Guesser (AugG) that is strong and is optimized for the VD setting especially. Experimental results on the VisDial v1.0 dataset show that our approach achieves state-of-theart performance on both image-guessing task and question diversity. Human study further proves that our model generates more visually related, informative and coherent questions.
Can We Model News Recommendation as Sequential Recommendation?
Aug 20, 2021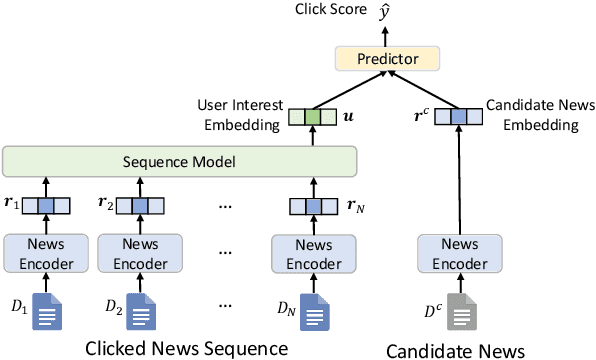
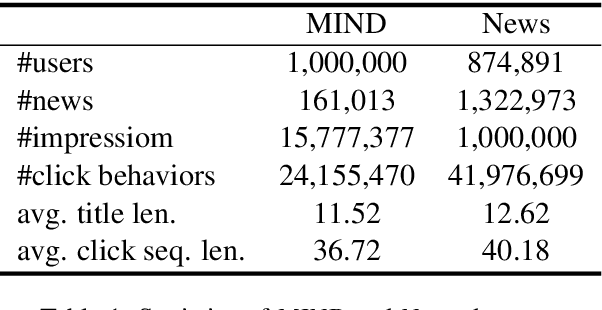
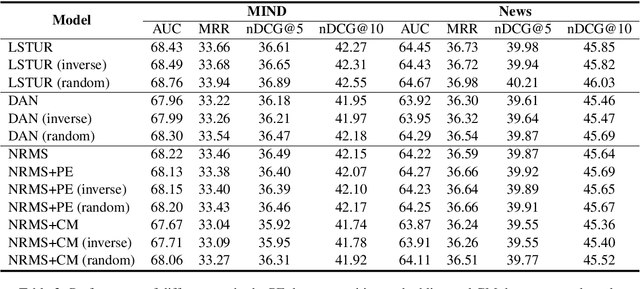
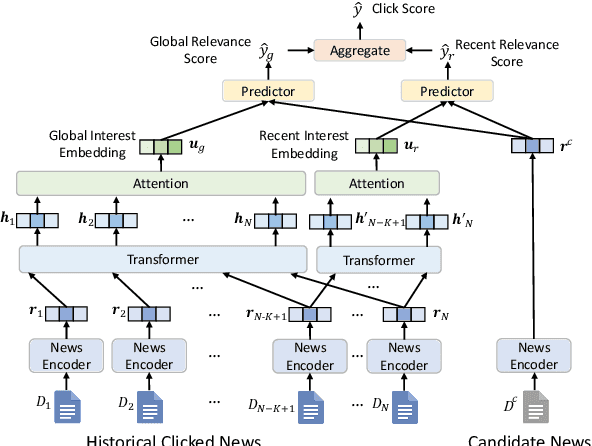
News recommendation is often modeled as a sequential recommendation task, which assumes that there are rich short-term dependencies over historical clicked news. However, in news recommendation scenarios users usually have strong preferences on the temporal diversity of news information and may not tend to click similar news successively, which is very different from many sequential recommendation scenarios such as e-commerce recommendation. In this paper, we study whether news recommendation can be regarded as a standard sequential recommendation problem. Through extensive experiments on two real-world datasets, we find that modeling news recommendation as a sequential recommendation problem is suboptimal. To handle this challenge, we further propose a temporal diversity-aware news recommendation method that can promote candidate news that are diverse from recently clicked news, which can help predict future clicks more accurately. Experiments show that our approach can consistently improve various news recommendation methods.
Resilient Active Information Gathering with Mobile Robots
Sep 02, 2018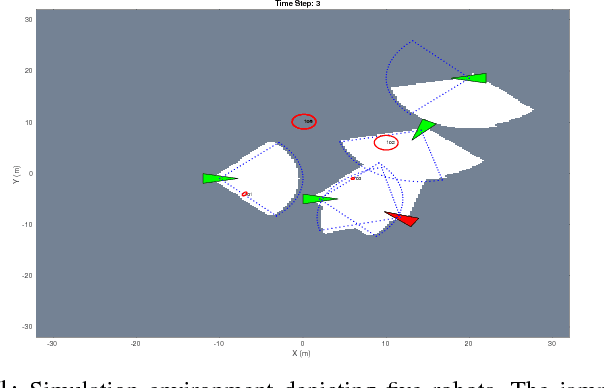
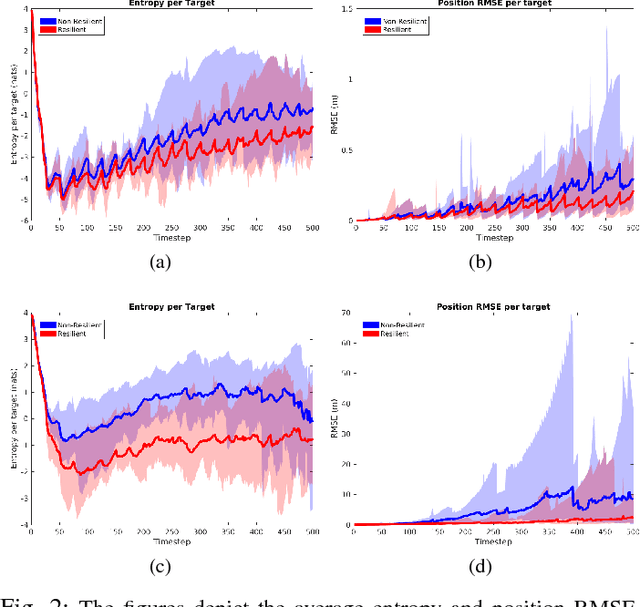

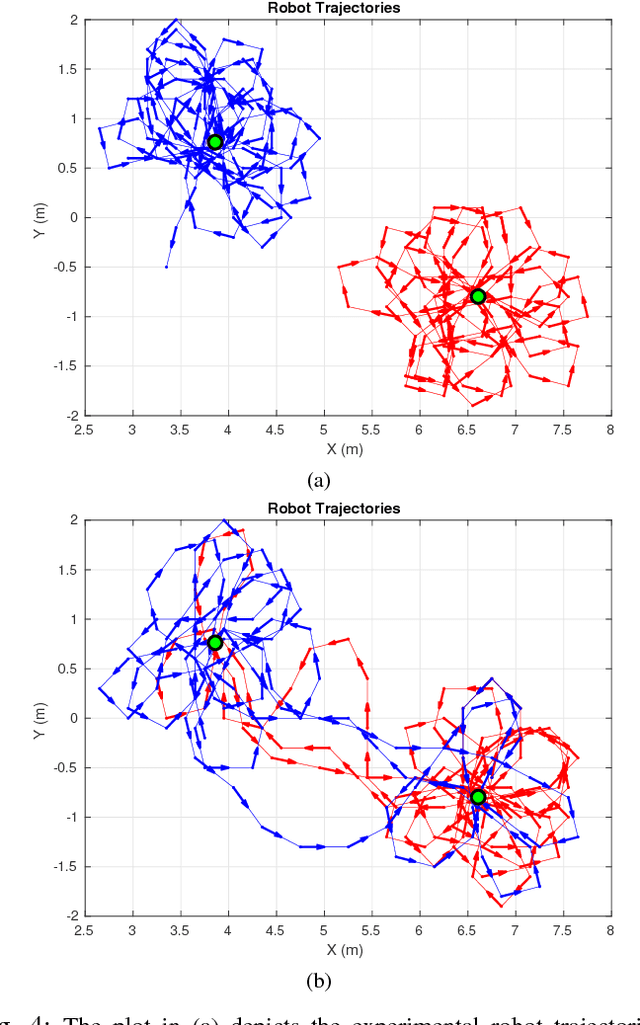
Applications of safety, security, and rescue in robotics, such as multi-robot target tracking, involve the execution of information acquisition tasks by teams of mobile robots. However, in failure-prone or adversarial environments, robots get attacked, their communication channels get jammed, and their sensors may fail, resulting in the withdrawal of robots from the collective task, and consequently the inability of the remaining active robots to coordinate with each other. As a result, traditional design paradigms become insufficient and, in contrast, resilient designs against system-wide failures and attacks become important. In general, resilient design problems are hard, and even though they often involve objective functions that are monotone or submodular, scalable approximation algorithms for their solution have been hitherto unknown. In this paper, we provide the first algorithm, enabling the following capabilities: minimal communication, i.e., the algorithm is executed by the robots based only on minimal communication between them; system-wide resiliency, i.e., the algorithm is valid for any number of denial-of-service attacks and failures; and provable approximation performance, i.e., the algorithm ensures for all monotone (and not necessarily submodular) objective functions a solution that is finitely close to the optimal. We quantify our algorithm's approximation performance using a notion of curvature for monotone set functions. We support our theoretical analyses with simulated and real-world experiments, by considering an active information gathering scenario, namely, multi-robot target tracking.
Learning Sparse Analytic Filters for Piano Transcription
Aug 23, 2021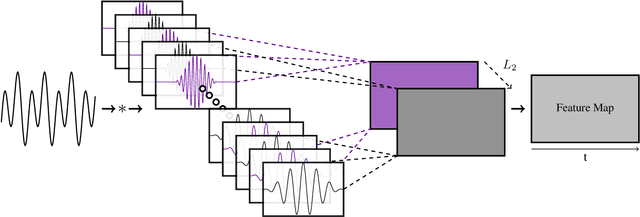
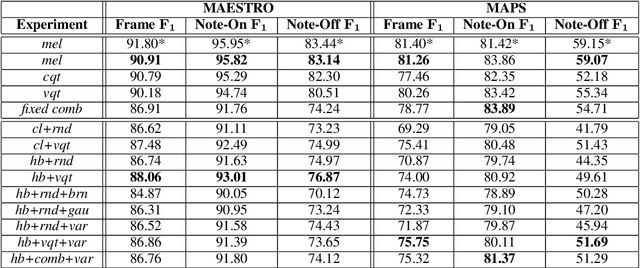
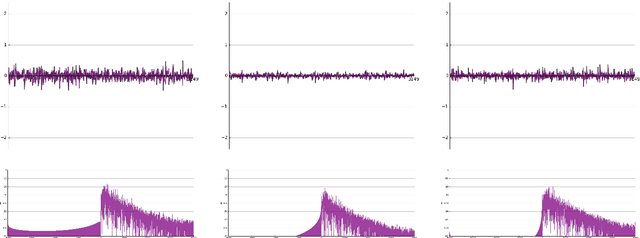
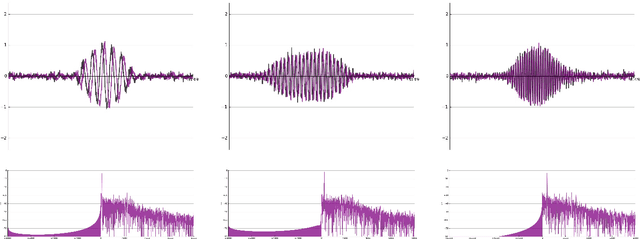
In recent years, filterbank learning has become an increasingly popular strategy for various audio-related machine learning tasks. This is partly due to its ability to discover task-specific audio characteristics which can be leveraged in downstream processing. It is also a natural extension of the nearly ubiquitous deep learning methods employed to tackle a diverse array of audio applications. In this work, several variations of a frontend filterbank learning module are investigated for piano transcription, a challenging low-level music information retrieval task. We build upon a standard piano transcription model, modifying only the feature extraction stage. The filterbank module is designed such that its complex filters are unconstrained 1D convolutional kernels with long receptive fields. Additional variations employ the Hilbert transform to render the filters intrinsically analytic and apply variational dropout to promote filterbank sparsity. Transcription results are compared across all experiments, and we offer visualization and analysis of the filterbanks.
Joint Embedding of Meta-Path and Meta-Graph for Heterogeneous Information Networks
Sep 11, 2018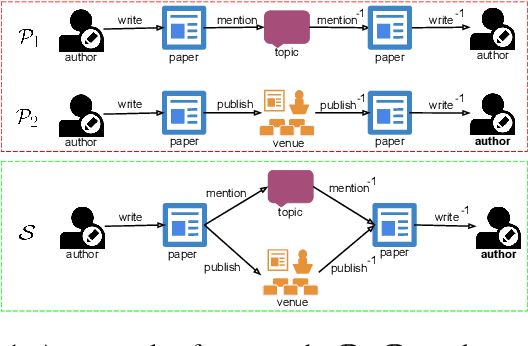
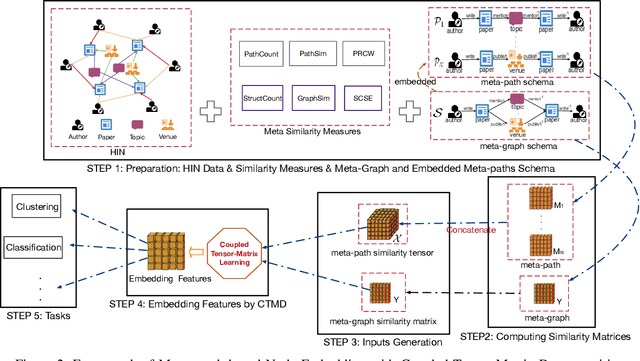

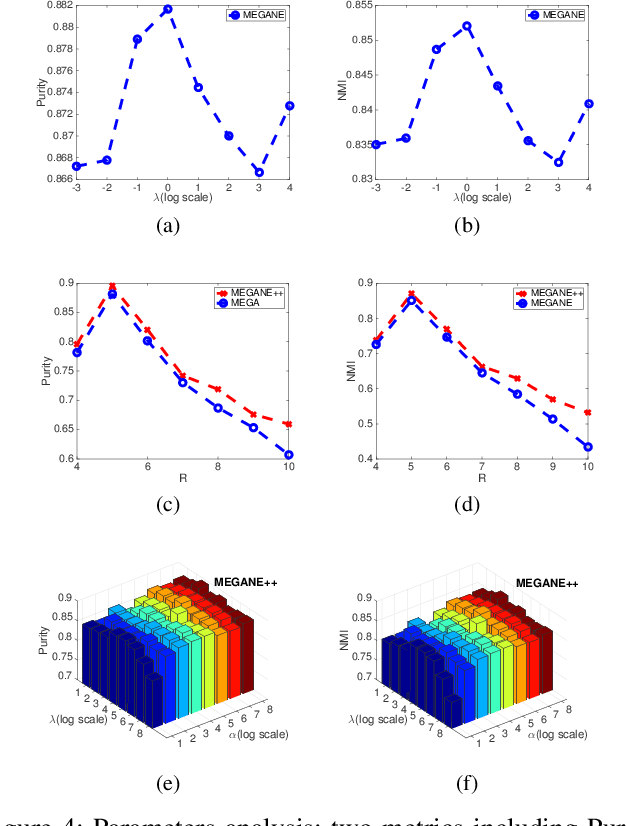
Meta-graph is currently the most powerful tool for similarity search on heterogeneous information networks,where a meta-graph is a composition of meta-paths that captures the complex structural information. However, current relevance computing based on meta-graph only considers the complex structural information, but ignores its embedded meta-paths information. To address this problem, we proposeMEta-GrAph-based network embedding models, called MEGA and MEGA++, respectively. The MEGA model uses normalized relevance or similarity measures that are derived from a meta-graph and its embedded meta-paths between nodes simultaneously, and then leverages tensor decomposition method to perform node embedding. The MEGA++ further facilitates the use of coupled tensor-matrix decomposition method to obtain a joint embedding for nodes, which simultaneously considers the hidden relations of all meta information of a meta-graph.Extensive experiments on two real datasets demonstrate thatMEGA and MEGA++ are more effective than state-of-the-art approaches.
CAN3D: Fast 3D Medical Image Segmentation via Compact Context Aggregation
Sep 22, 2021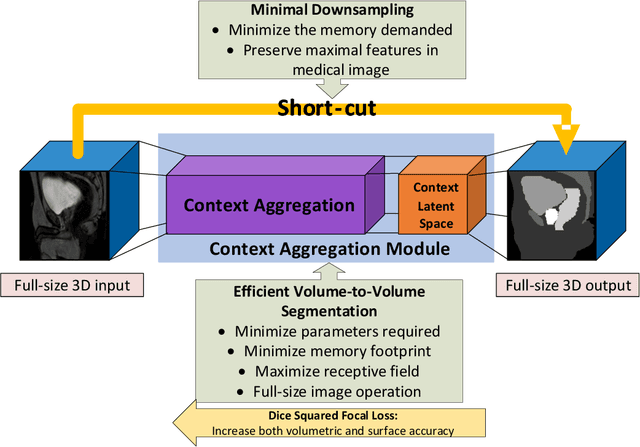

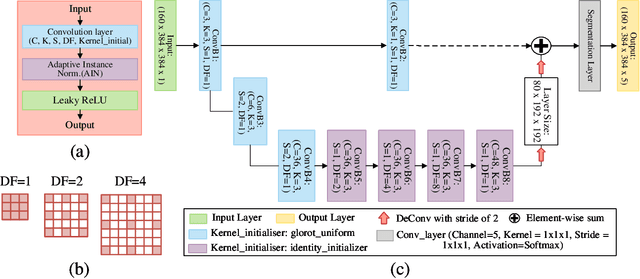
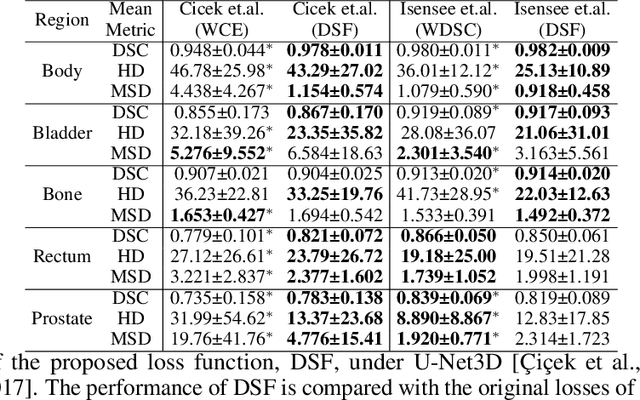
Direct automatic segmentation of objects from 3D medical imaging, such as magnetic resonance (MR) imaging, is challenging as it often involves accurately identifying a number of individual objects with complex geometries within a large volume under investigation. To address these challenges, most deep learning approaches typically enhance their learning capability by substantially increasing the complexity or the number of trainable parameters within their models. Consequently, these models generally require long inference time on standard workstations operating clinical MR systems and are restricted to high-performance computing hardware due to their large memory requirement. Further, to fit 3D dataset through these large models using limited computer memory, trade-off techniques such as patch-wise training are often used which sacrifice the fine-scale geometric information from input images which could be clinically significant for diagnostic purposes. To address these challenges, we present a compact convolutional neural network with a shallow memory footprint to efficiently reduce the number of model parameters required for state-of-art performance. This is critical for practical employment as most clinical environments only have low-end hardware with limited computing power and memory. The proposed network can maintain data integrity by directly processing large full-size 3D input volumes with no patches required and significantly reduces the computational time required for both training and inference. We also propose a novel loss function with extra shape constraint to improve the accuracy for imbalanced classes in 3D MR images.
Middle-level Fusion for Lightweight RGB-D Salient Object Detection
May 06, 2021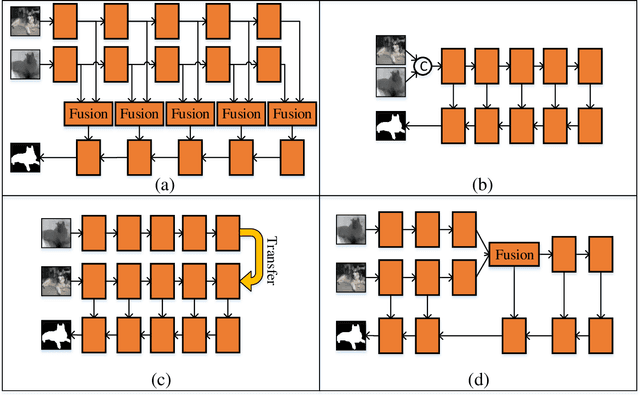
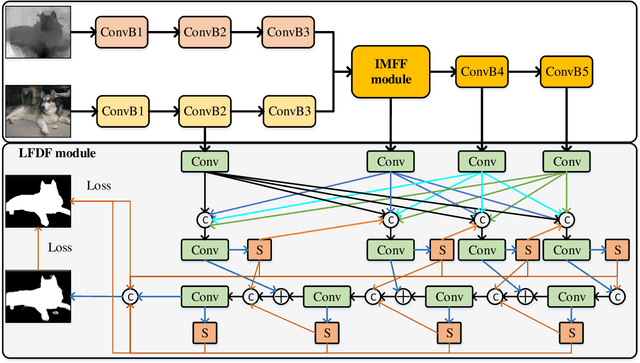
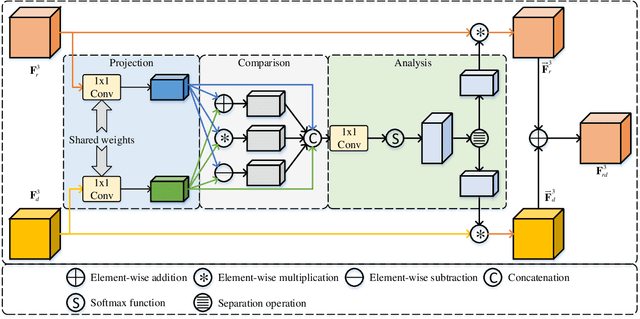

Most existing RGB-D salient object detection (SOD) models require large computational costs and memory consumption to accurately detect the salient objects. This limits the real-life applications of these RGB-D SOD models. To address this issue, a novel lightweight RGB-D SOD model is presented in this paper. Different from most existing models which usually employ the two-stream or single-stream structure, we propose to employ the middle-level fusion structure for designing lightweight RGB-D SOD model, due to the fact that the middle-level fusion structure can simultaneously exploit the modality-shared and modality-specific information as the two-stream structure and can significantly reduce the network's parameters as the single-stream structure. Based on this structure, a novel information-aware multi-modal feature fusion (IMFF) module is first designed to effectively capture the cross-modal complementary information. Then, a novel lightweight feature-level and decision-level feature fusion (LFDF) module is designed to aggregate the feature-level and the decision-level saliency information in different stages with less parameters. With IMFF and LFDF modules incorporated in the middle-level fusion structure, our proposed model has only 3.9M parameters and runs at 33 FPS. Furthermore, the experimental results on several benchmark datasets verify the effectiveness and superiority of the proposed method over some state-of-the-art methods.