 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnCAgg: Enhanced Clustering Aggregation for Robust Federated Learning against Dynamic Model Poisoning
May 21, 2026Federated learning faces increasing threats from model poisoning attacks, which harms its application to improve privacy. Existing defense methods typically rely on fixed thresholds or perform clustering with a fixed number of clusters to distinguish malicious gradients from benign ones. However, these methods are difficult to adapt to dynamic poisoning strategies of malicious clients, and often result in the loss of benign gradients due to the heterogeneity of clients' local datasets. To address these problems, we propose a novel robust aggregation method that leverages a small number of known benign clients as references, enabling accurate identification and filtering of malicious gradients while retaining as many benign gradients as possible, even when the number of malicious clients is unknown and variable. First, we introduce a density-based low-dimensional gradient clustering method, which projects gradients onto the two most divergent dimensions and applies density-based clustering to identify malicious gradients while retaining clustered benign gradients and potentially benign outliers. Second, we design an enhancing clustering low-dimensional gradient generator model, which learns to generate pseudo-gradients aligned with the boundary of the benign cluster. These pseudo-gradients act as bridges to connect sparse benign gradient outliers. Third, we introduce low-dimensional gradient re-clustering that clusters the generated pseudo-gradients together with real gradients to recover benign gradients misclassified as noise points, enabling more benign gradients to participate in aggregation. Extensive experiments on the MNIST, CIFAR-10, and MIND datasets demonstrate that our method exhibits superior fidelity and robustness under dynamic poisoning scenarios.
Knowledge Poisoning Attacks on Medical Multi-Modal Retrieval-Augmented Generation
May 11, 2026Retrieval-augmented generation (RAG) is a widely adopted paradigm for enhancing LLMs in medical applications by incorporating expert multimodal knowledge during generation. However, the underlying retrieval databases may naturally contain, or be intentionally injected with, adversarial knowledge, which can perturb model outputs and undermine system reliability. To investigate this risk, prior studies have explored knowledge poisoning attacks in medical RAG systems. Nevertheless, most of them rely on the strong assumption that adversaries possess prior knowledge of user queries, which is unrealistic in deployments and substantially limits their practical applicability. In this paper, we propose M\textsuperscript{3}Att, a knowledge-poisoning framework designed for medical multimodal RAG systems, assuming only limited distribution knowledge of the underlying database. Our core idea is to inject covert misinformation into textual data while using paired visual data as a query-agnostic trigger to promote retrieval. We first propose a unified framework that introduces imperceptible perturbations to visual inputs to manipulate retrieval probabilities. Besides, due to the prior medical knowledge in LLMs, naively poisoned medical content with explicit factual errors can be corrected during generation. Thus, we leverage the inherent ambiguity of medical diagnosis and design a covert misinformation injection strategy that degrades diagnostic accuracy while evading model self-correction. Experiments on five LLMs and datasets demonstrate that M\textsuperscript{3}Att consistently produces clinically plausible yet incorrect generations. Codes: https://github.com/ypr17/M3Att.
Explore-on-Graph: Incentivizing Autonomous Exploration of Large Language Models on Knowledge Graphs with Path-refined Reward Modeling
Feb 25, 2026The reasoning process of Large Language Models (LLMs) is often plagued by hallucinations and missing facts in question-answering tasks. A promising solution is to ground LLMs' answers in verifiable knowledge sources, such as Knowledge Graphs (KGs). Prevailing KG-enhanced methods typically constrained LLM reasoning either by enforcing rules during generation or by imitating paths from a fixed set of demonstrations. However, they naturally confined the reasoning patterns of LLMs within the scope of prior experience or fine-tuning data, limiting their generalizability to out-of-distribution graph reasoning problems. To tackle this problem, in this paper, we propose Explore-on-Graph (EoG), a novel framework that encourages LLMs to autonomously explore a more diverse reasoning space on KGs. To incentivize exploration and discovery of novel reasoning paths, we propose to introduce reinforcement learning during training, whose reward is the correctness of the reasoning paths' final answers. To enhance the efficiency and meaningfulness of the exploration, we propose to incorporate path information as additional reward signals to refine the exploration process and reduce futile efforts. Extensive experiments on five KGQA benchmark datasets demonstrate that, to the best of our knowledge, our method achieves state-of-the-art performance, outperforming not only open-source but also even closed-source LLMs.
Membox: Weaving Topic Continuity into Long-Range Memory for LLM Agents
Jan 07, 2026Human-agent dialogues often exhibit topic continuity-a stable thematic frame that evolves through temporally adjacent exchanges-yet most large language model (LLM) agent memory systems fail to preserve it. Existing designs follow a fragmentation-compensation paradigm: they first break dialogue streams into isolated utterances for storage, then attempt to restore coherence via embedding-based retrieval. This process irreversibly damages narrative and causal flow, while biasing retrieval towards lexical similarity. We introduce membox, a hierarchical memory architecture centered on a Topic Loom that continuously monitors dialogue in a sliding-window fashion, grouping consecutive same-topic turns into coherent "memory boxes" at storage time. Sealed boxes are then linked by a Trace Weaver into long-range event-timeline traces, recovering macro-topic recurrences across discontinuities. Experiments on LoCoMo demonstrate that Membox achieves up to 68% F1 improvement on temporal reasoning tasks, outperforming competitive baselines (e.g., Mem0, A-MEM). Notably, Membox attains these gains while using only a fraction of the context tokens required by existing methods, highlighting a superior balance between efficiency and effectiveness. By explicitly modeling topic continuity, Membox offers a cognitively motivated mechanism for enhancing both coherence and efficiency in LLM agents.
RedNote-Vibe: A Dataset for Capturing Temporal Dynamics of AI-Generated Text in Social Media
Sep 26, 2025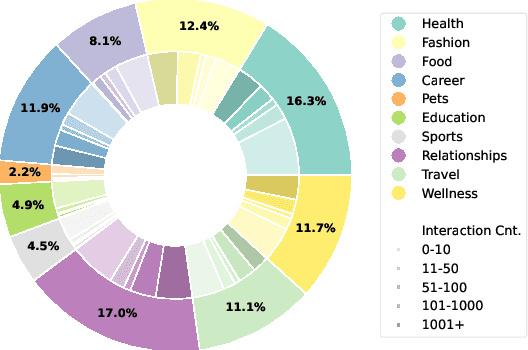
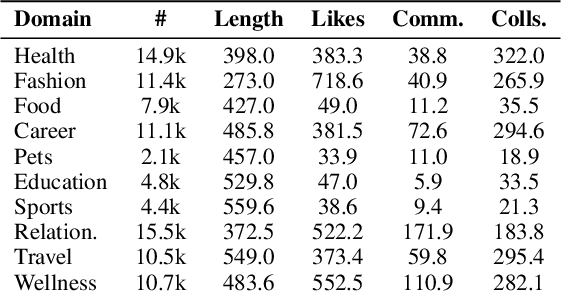

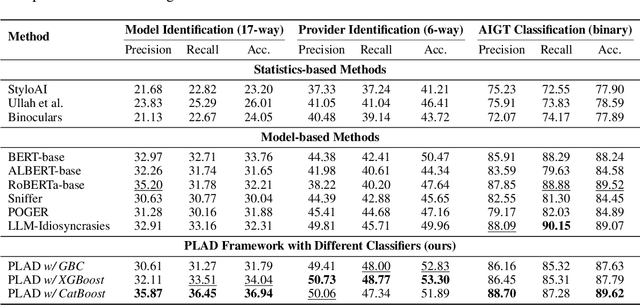
The proliferation of Large Language Models (LLMs) has led to widespread AI-Generated Text (AIGT) on social media platforms, creating unique challenges where content dynamics are driven by user engagement and evolve over time. However, existing datasets mainly depict static AIGT detection. In this work, we introduce RedNote-Vibe, the first longitudinal (5-years) dataset for social media AIGT analysis. This dataset is sourced from Xiaohongshu platform, containing user engagement metrics (e.g., likes, comments) and timestamps spanning from the pre-LLM period to July 2025, which enables research into the temporal dynamics and user interaction patterns of AIGT. Furthermore, to detect AIGT in the context of social media, we propose PsychoLinguistic AIGT Detection Framework (PLAD), an interpretable approach that leverages psycholinguistic features. Our experiments show that PLAD achieves superior detection performance and provides insights into the signatures distinguishing human and AI-generated content. More importantly, it reveals the complex relationship between these linguistic features and social media engagement. The dataset is available at https://github.com/testuser03158/RedNote-Vibe.
MrM: Black-Box Membership Inference Attacks against Multimodal RAG Systems
Jun 09, 2025



Multimodal retrieval-augmented generation (RAG) systems enhance large vision-language models by integrating cross-modal knowledge, enabling their increasing adoption across real-world multimodal tasks. These knowledge databases may contain sensitive information that requires privacy protection. However, multimodal RAG systems inherently grant external users indirect access to such data, making them potentially vulnerable to privacy attacks, particularly membership inference attacks (MIAs). % Existing MIA methods targeting RAG systems predominantly focus on the textual modality, while the visual modality remains relatively underexplored. To bridge this gap, we propose MrM, the first black-box MIA framework targeted at multimodal RAG systems. It utilizes a multi-object data perturbation framework constrained by counterfactual attacks, which can concurrently induce the RAG systems to retrieve the target data and generate information that leaks the membership information. Our method first employs an object-aware data perturbation method to constrain the perturbation to key semantics and ensure successful retrieval. Building on this, we design a counterfact-informed mask selection strategy to prioritize the most informative masked regions, aiming to eliminate the interference of model self-knowledge and amplify attack efficacy. Finally, we perform statistical membership inference by modeling query trials to extract features that reflect the reconstruction of masked semantics from response patterns. Experiments on two visual datasets and eight mainstream commercial visual-language models (e.g., GPT-4o, Gemini-2) demonstrate that MrM achieves consistently strong performance across both sample-level and set-level evaluations, and remains robust under adaptive defenses.
HeteRAG: A Heterogeneous Retrieval-augmented Generation Framework with Decoupled Knowledge Representations
Apr 12, 2025



Retrieval-augmented generation (RAG) methods can enhance the performance of LLMs by incorporating retrieved knowledge chunks into the generation process. In general, the retrieval and generation steps usually have different requirements for these knowledge chunks. The retrieval step benefits from comprehensive information to improve retrieval accuracy, whereas excessively long chunks may introduce redundant contextual information, thereby diminishing both the effectiveness and efficiency of the generation process. However, existing RAG methods typically employ identical representations of knowledge chunks for both retrieval and generation, resulting in suboptimal performance. In this paper, we propose a heterogeneous RAG framework (\myname) that decouples the representations of knowledge chunks for retrieval and generation, thereby enhancing the LLMs in both effectiveness and efficiency. Specifically, we utilize short chunks to represent knowledge to adapt the generation step and utilize the corresponding chunk with its contextual information from multi-granular views to enhance retrieval accuracy. We further introduce an adaptive prompt tuning method for the retrieval model to adapt the heterogeneous retrieval augmented generation process. Extensive experiments demonstrate that \myname achieves significant improvements compared to baselines.
pFedGPA: Diffusion-based Generative Parameter Aggregation for Personalized Federated Learning
Sep 09, 2024



Federated Learning (FL) offers a decentralized approach to model training, where data remains local and only model parameters are shared between the clients and the central server. Traditional methods, such as Federated Averaging (FedAvg), linearly aggregate these parameters which are usually trained on heterogeneous data distributions, potentially overlooking the complex, high-dimensional nature of the parameter space. This can result in degraded performance of the aggregated model. While personalized FL approaches can mitigate the heterogeneous data issue to some extent, the limitation of linear aggregation remains unresolved. To alleviate this issue, we investigate the generative approach of diffusion model and propose a novel generative parameter aggregation framework for personalized FL, \texttt{pFedGPA}. In this framework, we deploy a diffusion model on the server to integrate the diverse parameter distributions and propose a parameter inversion method to efficiently generate a set of personalized parameters for each client. This inversion method transforms the uploaded parameters into a latent code, which is then aggregated through denoising sampling to produce the final personalized parameters. By encoding the dependence of a client's model parameters on the specific data distribution using the high-capacity diffusion model, \texttt{pFedGPA} can effectively decouple the complexity of the overall distribution of all clients' model parameters from the complexity of each individual client's parameter distribution. Our experimental results consistently demonstrate the superior performance of the proposed method across multiple datasets, surpassing baseline approaches.
LICM: Effective and Efficient Long Interest Chain Modeling for News Recommendation
Aug 01, 2024



Accurately recommending personalized candidate news articles to users has always been the core challenge of news recommendation system. News recommendations often require modeling of user interests to match candidate news. Recent efforts have primarily focused on extract local subgraph information, the lack of a comprehensive global news graph extraction has hindered the ability to utilize global news information collaboratively among similar users. To overcome these limitations, we propose an effective and efficient Long Interest Chain Modeling for News Recommendation(LICM), which combines neighbor interest with long-chain interest distilled from a global news click graph based on the collaborative of similar users to enhance news recommendation. For a global news graph based on the click history of all users, long chain interest generated from it can better utilize the high-dimensional information within it, enhancing the effectiveness of collaborative recommendations. We therefore design a comprehensive selection mechanism and interest encoder to obtain long-chain interest from the global graph. Finally, we use a gated network to integrate long-chain information with neighbor information to achieve the final user representation. Experiment results on real-world datasets validate the effectiveness and efficiency of our model to improve the performance of news recommendation.
SETTP: Style Extraction and Tunable Inference via Dual-level Transferable Prompt Learning
Jul 22, 2024



Text style transfer, an important research direction in natural language processing, aims to adapt the text to various preferences but often faces challenges with limited resources. In this work, we introduce a novel method termed Style Extraction and Tunable Inference via Dual-level Transferable Prompt Learning (SETTP) for effective style transfer in low-resource scenarios. First, SETTP learns source style-level prompts containing fundamental style characteristics from high-resource style transfer. During training, the source style-level prompts are transferred through an attention module to derive a target style-level prompt for beneficial knowledge provision in low-resource style transfer. Additionally, we propose instance-level prompts obtained by clustering the target resources based on the semantic content to reduce semantic bias. We also propose an automated evaluation approach of style similarity based on alignment with human evaluations using ChatGPT-4. Our experiments across three resourceful styles show that SETTP requires only 1/20th of the data volume to achieve performance comparable to state-of-the-art methods. In tasks involving scarce data like writing style and role style, SETTP outperforms previous methods by 16.24\%.