 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Continuous-Time Markov Chain Framework for Insertion Language Models
Jun 08, 2026Insertion Language Models (ILMs) offer several advantages over left-to-right generation and mask-based generation. However, existing formulations of insertion-based generation have largely been ad-hoc. In this paper, we derive a diffusion-style denoising objective for ILMs from first principles by formulating the noising process as a continuous-time Markov chain on the space of variable-length sequences. We show that previous formulations of ILMs can be viewed as special cases of this denoising framework. Through empirical evaluation on a synthetic planning task, we show that the proposed approach retains the benefits of insertion-based generation over left-to-right generation and masked diffusion models. In language modeling, our diffusion-based approach is competitive with left-to-right generation and masked diffusion models, while offering additional flexibility in sampling compared to existing insertion language models.
Hallucination Detection-Guided Preference Optimization for Clinical Summarization
May 27, 2026Large language models (LLMs) have shown promise on summarization tasks, but they often produce hallucinations, which are unsupported or incorrect statements that limit their reliability in specialized healthcare applications. We introduce \itermodelfull (\itermodel), an inference-time method that leverages hallucination detectors to guide iterative summary revisions toward factual corrections. Building on this, we propose \itermodel for Preference Learning (\model), which converts detector-guided refinement trajectories into preference pairs for model finetuning. Extensive experiments show that our methods substantially reduce hallucinations for Llama and Gemma models in summarizing real-world clinical notes from \MimicIV. For example, \itermodel reduces 24\% and \model reduces 48\% hallucinations in Llama-3.1-8B-Instruct. Importantly, both methods preserve summary fluency, coherence, and relevance according to human expert and LLM-Jury evaluations. Together, these results demonstrate that detection-informed refinement and preference learning offer an automated solution for improving factual faithfulness in clinical summarization.
Learned Relay Representations for Forward-Thinking Discrete Diffusion Models
May 21, 2026When Masked Diffusion Models (MDMs) generate sequences through iterative refinement, the rich internal computation over masked positions is discarded, forcing every subsequent refinement step to recompute the valuable internal information stored as model representations. To avoid a hard reset between denoising rounds, we propose Learned Relay Representations (Relay), a method that allows MDMs to be forward-thinking when denoising by explicitly learning how to propagate latent information for the benefit of future denoising steps. Relay introduces a differentiable per-token channel that passes information between forward passes and is trained via truncated backpropagation through time (BPTT). We show that this framework can be scaled to state-of-the-art Diffusion Language Models (DLMs), and is seamlessly compatible with techniques like block diffusion and KV caching. We first provide a thorough justification of the design choices in Relay on a challenging Sudoku-based planning task. We then scale Relay to Fast-dLLM v2, a state-of-the-art DLM, outperforming standard supervised finetuning on coding tasks while reducing inference latency by up to 32%. Our empirical results demonstrate that state-of-the-art DLMs can be explicitly trained to relay latent information forward across decoding steps, advancing the performance-latency Pareto frontier. We provide code for all our experiments.
PROMPT2BOX: Uncovering Entailment Structure among LLM Prompts
Mar 22, 2026To discover the weaknesses of LLMs, researchers often embed prompts into a vector space and cluster them to extract insightful patterns. However, vector embeddings primarily capture topical similarity. As a result, prompts that share a topic but differ in specificity, and consequently in difficulty, are often represented similarly, making fine-grained weakness analysis difficult. To address this limitation, we propose PROMPT2BOX, which embeds prompts into a box embedding space using a trained encoder. The encoder, trained on existing and synthesized datasets, outputs box embeddings that capture not only semantic similarity but also specificity relations between prompts (e.g., "writing an adventure story" is more specific than "writing a story"). We further develop a novel dimension reduction technique for box embeddings to facilitate dataset visualization and comparison. Our experiments demonstrate that box embeddings consistently capture prompt specificity better than vector baselines. On the downstream task of creating hierarchical clustering trees for 17 LLMs from the UltraFeedback dataset, PROMPT2BOX can identify 8.9\% more LLM weaknesses than vector baselines and achieves an approximately 33\% stronger correlation between hierarchical depth and instruction specificity.
XLM: A Python package for non-autoregressive language models
Dec 18, 2025In recent years, there has been a resurgence of interest in non-autoregressive text generation in the context of general language modeling. Unlike the well-established autoregressive language modeling paradigm, which has a plethora of standard training and inference libraries, implementations of non-autoregressive language modeling have largely been bespoke making it difficult to perform systematic comparisons of different methods. Moreover, each non-autoregressive language model typically requires it own data collation, loss, and prediction logic, making it challenging to reuse common components. In this work, we present the XLM python package, which is designed to make implementing small non-autoregressive language models faster with a secondary goal of providing a suite of small pre-trained models (through a companion xlm-models package) that can be used by the research community. The code is available at https://github.com/dhruvdcoder/xlm-core.
MiGrATe: Mixed-Policy GRPO for Adaptation at Test-Time
Aug 12, 2025



Large language models (LLMs) are increasingly being applied to black-box optimization tasks, from program synthesis to molecule design. Prior work typically leverages in-context learning to iteratively guide the model towards better solutions. Such methods, however, often struggle to balance exploration of new solution spaces with exploitation of high-reward ones. Recently, test-time training (TTT) with synthetic data has shown promise in improving solution quality. However, the need for hand-crafted training data tailored to each task limits feasibility and scalability across domains. To address this problem, we introduce MiGrATe-a method for online TTT that uses GRPO as a search algorithm to adapt LLMs at inference without requiring external training data. MiGrATe operates via a mixed-policy group construction procedure that combines on-policy sampling with two off-policy data selection techniques: greedy sampling, which selects top-performing past completions, and neighborhood sampling (NS), which generates completions structurally similar to high-reward ones. Together, these components bias the policy gradient towards exploitation of promising regions in solution space, while preserving exploration through on-policy sampling. We evaluate MiGrATe on three challenging domains-word search, molecule optimization, and hypothesis+program induction on the Abstraction and Reasoning Corpus (ARC)-and find that it consistently outperforms both inference-only and TTT baselines, demonstrating the potential of online TTT as a solution for complex search tasks without external supervision.
Identity Theft in AI Conference Peer Review
Aug 06, 2025We discuss newly uncovered cases of identity theft in the scientific peer-review process within artificial intelligence (AI) research, with broader implications for other academic procedures. We detail how dishonest researchers exploit the peer-review system by creating fraudulent reviewer profiles to manipulate paper evaluations, leveraging weaknesses in reviewer recruitment workflows and identity verification processes. The findings highlight the critical need for stronger safeguards against identity theft in peer review and academia at large, and to this end, we also propose mitigating strategies.
OpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
Jun 14, 2025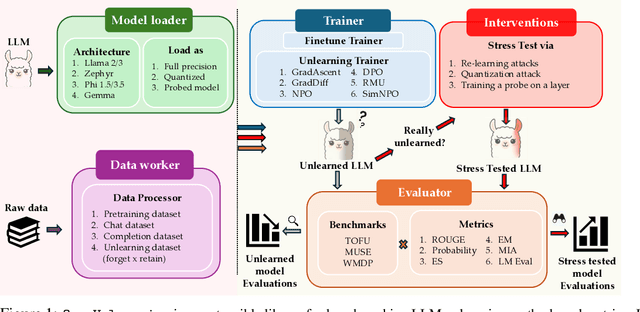



Robust unlearning is crucial for safely deploying large language models (LLMs) in environments where data privacy, model safety, and regulatory compliance must be ensured. Yet the task is inherently challenging, partly due to difficulties in reliably measuring whether unlearning has truly occurred. Moreover, fragmentation in current methodologies and inconsistent evaluation metrics hinder comparative analysis and reproducibility. To unify and accelerate research efforts, we introduce OpenUnlearning, a standardized and extensible framework designed explicitly for benchmarking both LLM unlearning methods and metrics. OpenUnlearning integrates 9 unlearning algorithms and 16 diverse evaluations across 3 leading benchmarks (TOFU, MUSE, and WMDP) and also enables analyses of forgetting behaviors across 450+ checkpoints we publicly release. Leveraging OpenUnlearning, we propose a novel meta-evaluation benchmark focused specifically on assessing the faithfulness and robustness of evaluation metrics themselves. We also benchmark diverse unlearning methods and provide a comparative analysis against an extensive evaluation suite. Overall, we establish a clear, community-driven pathway toward rigorous development in LLM unlearning research.
Insertion Language Models: Sequence Generation with Arbitrary-Position Insertions
May 09, 2025



Autoregressive models (ARMs), which predict subsequent tokens one-by-one ``from left to right,'' have achieved significant success across a wide range of sequence generation tasks. However, they struggle to accurately represent sequences that require satisfying sophisticated constraints or whose sequential dependencies are better addressed by out-of-order generation. Masked Diffusion Models (MDMs) address some of these limitations, but the process of unmasking multiple tokens simultaneously in MDMs can introduce incoherences, and MDMs cannot handle arbitrary infilling constraints when the number of tokens to be filled in is not known in advance. In this work, we introduce Insertion Language Models (ILMs), which learn to insert tokens at arbitrary positions in a sequence -- that is, they select jointly both the position and the vocabulary element to be inserted. By inserting tokens one at a time, ILMs can represent strong dependencies between tokens, and their ability to generate sequences in arbitrary order allows them to accurately model sequences where token dependencies do not follow a left-to-right sequential structure. To train ILMs, we propose a tailored network parameterization and use a simple denoising objective. Our empirical evaluation demonstrates that ILMs outperform both ARMs and MDMs on common planning tasks. Furthermore, we show that ILMs outperform MDMs and perform on par with ARMs in an unconditional text generation task while offering greater flexibility than MDMs in arbitrary-length text infilling.
Memory Augmented Cross-encoders for Controllable Personalized Search
Nov 05, 2024



Personalized search represents a problem where retrieval models condition on historical user interaction data in order to improve retrieval results. However, personalization is commonly perceived as opaque and not amenable to control by users. Further, personalization necessarily limits the space of items that users are exposed to. Therefore, prior work notes a tension between personalization and users' ability for discovering novel items. While discovery of novel items in personalization setups may be resolved through search result diversification, these approaches do little to allow user control over personalization. Therefore, in this paper, we introduce an approach for controllable personalized search. Our model, CtrlCE presents a novel cross-encoder model augmented with an editable memory constructed from users historical items. Our proposed memory augmentation allows cross-encoder models to condition on large amounts of historical user data and supports interaction from users permitting control over personalization. Further, controllable personalization for search must account for queries which don't require personalization, and in turn user control. For this, we introduce a calibrated mixing model which determines when personalization is necessary. This allows system designers using CtrlCE to only obtain user input for control when necessary. In multiple datasets of personalized search, we show CtrlCE to result in effective personalization as well as fulfill various key goals for controllable personalized search.