 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Visual Dialog Questioner with Entity-based Strategy Learning and Augmented Guesser
Paper and Code
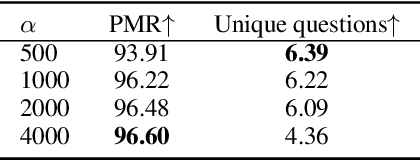
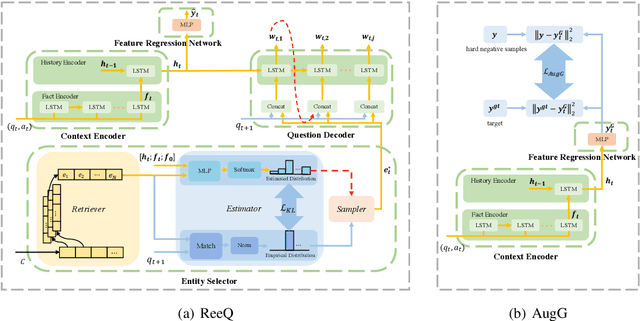
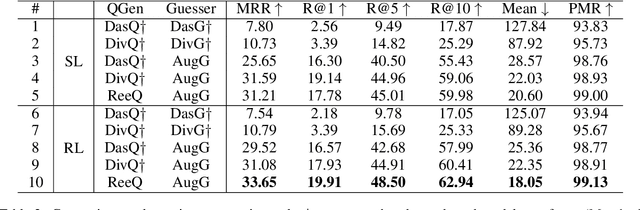
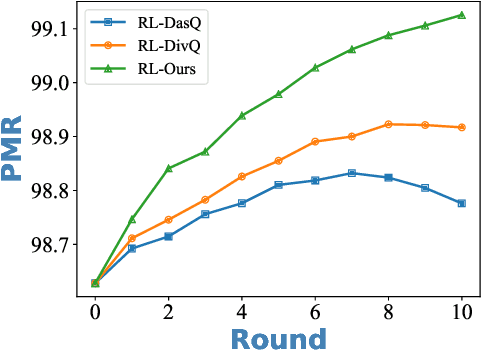
Considering the importance of building a good Visual Dialog (VD) Questioner, many researchers study the topic under a Q-Bot-A-Bot image-guessing game setting, where the Questioner needs to raise a series of questions to collect information of an undisclosed image. Despite progress has been made in Supervised Learning (SL) and Reinforcement Learning (RL), issues still exist. Firstly, previous methods do not provide explicit and effective guidance for Questioner to generate visually related and informative questions. Secondly, the effect of RL is hampered by an incompetent component, i.e., the Guesser, who makes image predictions based on the generated dialogs and assigns rewards accordingly. To enhance VD Questioner: 1) we propose a Related entity enhanced Questioner (ReeQ) that generates questions under the guidance of related entities and learns entity-based questioning strategy from human dialogs; 2) we propose an Augmented Guesser (AugG) that is strong and is optimized for the VD setting especially. Experimental results on the VisDial v1.0 dataset show that our approach achieves state-of-theart performance on both image-guessing task and question diversity. Human study further proves that our model generates more visually related, informative and coherent questions.