 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RoR: Read-over-Read for Long Document Machine Reading Comprehension
Sep 10, 2021
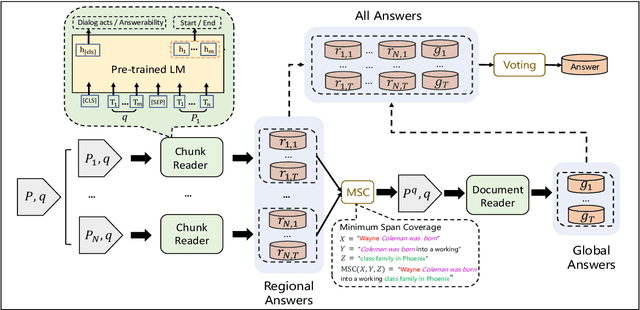
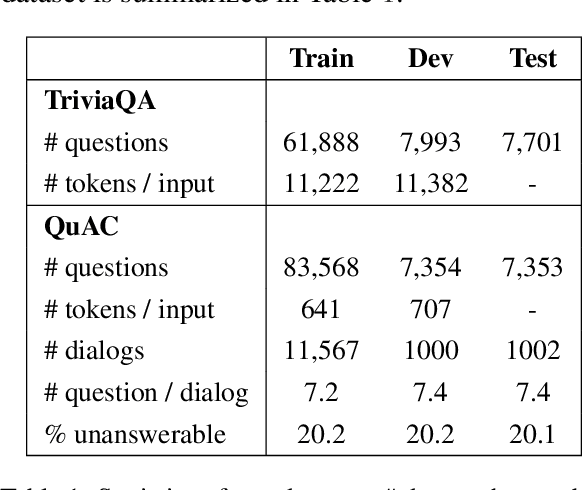
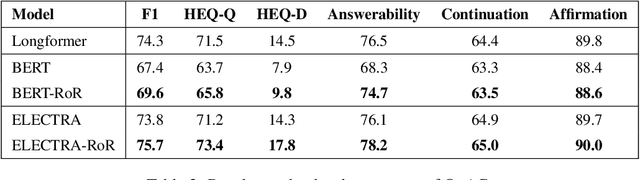
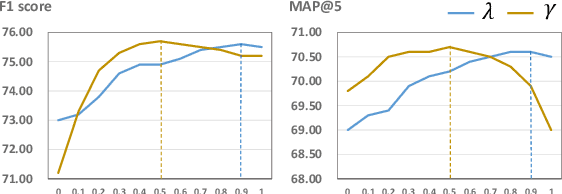
Transformer-based pre-trained models, such as BERT, have achieved remarkable results on machine reading comprehension. However, due to the constraint of encoding length (e.g., 512 WordPiece tokens), a long document is usually split into multiple chunks that are independently read. It results in the reading field being limited to individual chunks without information collaboration for long document machine reading comprehension. To address this problem, we propose RoR, a read-over-read method, which expands the reading field from chunk to document. Specifically, RoR includes a chunk reader and a document reader. The former first predicts a set of regional answers for each chunk, which are then compacted into a highly-condensed version of the original document, guaranteeing to be encoded once. The latter further predicts the global answers from this condensed document. Eventually, a voting strategy is utilized to aggregate and rerank the regional and global answers for final prediction. Extensive experiments on two benchmarks QuAC and TriviaQA demonstrate the effectiveness of RoR for long document reading. Notably, RoR ranks 1st place on the QuAC leaderboard (https://quac.ai/) at the time of submission (May 17th, 2021).
Efficient Modelling Across Time of Human Actions and Interactions
Oct 05, 2021

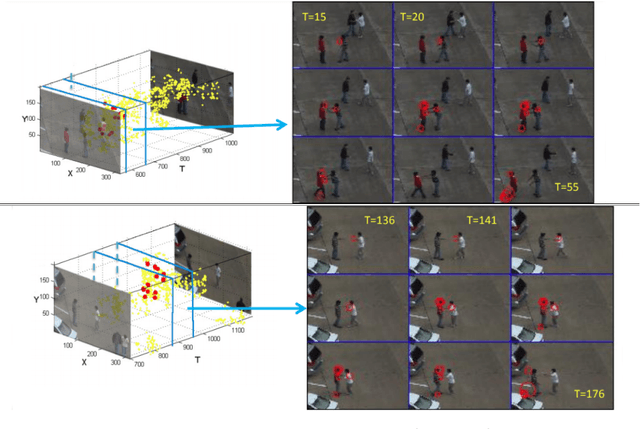
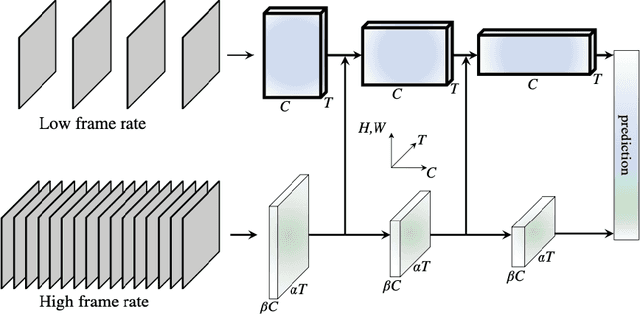
This thesis focuses on video understanding for human action and interaction recognition. We start by identifying the main challenges related to action recognition from videos and review how they have been addressed by current methods. Based on these challenges, and by focusing on the temporal aspect of actions, we argue that current fixed-sized spatio-temporal kernels in 3D convolutional neural networks (CNNs) can be improved to better deal with temporal variations in the input. Our contributions are based on the enlargement of the convolutional receptive fields through the introduction of spatio-temporal size-varying segments of videos, as well as the discovery of the local feature relevance over the entire video sequence. The resulting extracted features encapsulate information that includes the importance of local features across multiple temporal durations, as well as the entire video sequence. Subsequently, we study how we can better handle variations between classes of actions, by enhancing their feature differences over different layers of the architecture. The hierarchical extraction of features models variations of relatively similar classes the same as very dissimilar classes. Therefore, distinctions between similar classes are less likely to be modelled. The proposed approach regularises feature maps by amplifying features that correspond to the class of the video that is processed. We move away from class-agnostic networks and make early predictions based on feature amplification mechanism. The proposed approaches are evaluated on several benchmark action recognition datasets and show competitive results. In terms of performance, we compete with the state-of-the-art while being more efficient in terms of GFLOPs. Finally, we present a human-understandable approach aimed at providing visual explanations for features learned over spatio-temporal networks.
Low-rank statistical finite elements for scalable model-data synthesis
Sep 10, 2021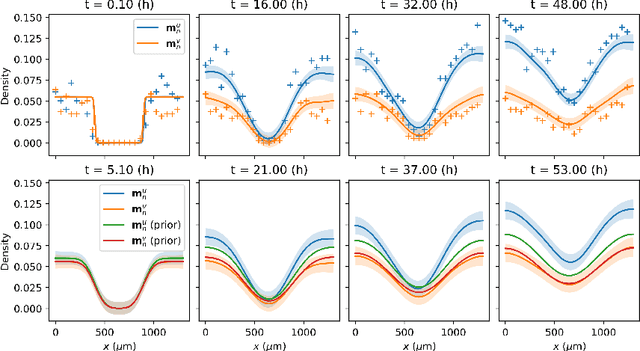
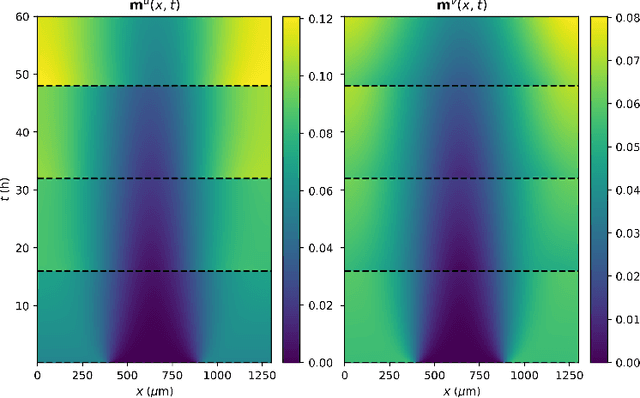
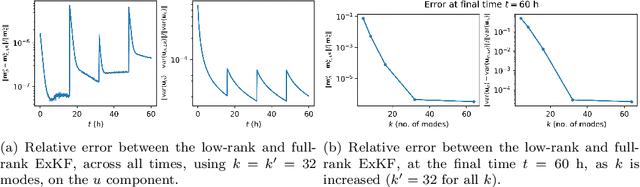
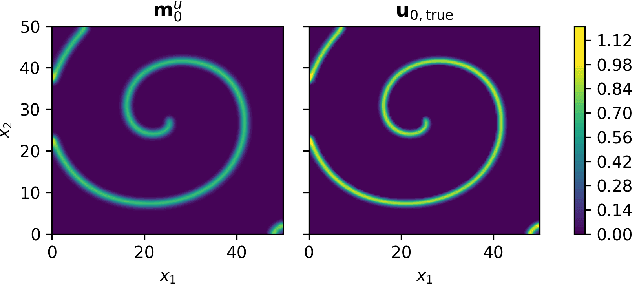
Statistical learning additions to physically derived mathematical models are gaining traction in the literature. A recent approach has been to augment the underlying physics of the governing equations with data driven Bayesian statistical methodology. Coined statFEM, the method acknowledges a priori model misspecification, by embedding stochastic forcing within the governing equations. Upon receipt of additional data, the posterior distribution of the discretised finite element solution is updated using classical Bayesian filtering techniques. The resultant posterior jointly quantifies uncertainty associated with the ubiquitous problem of model misspecification and the data intended to represent the true process of interest. Despite this appeal, computational scalability is a challenge to statFEM's application to high-dimensional problems typically experienced in physical and industrial contexts. This article overcomes this hurdle by embedding a low-rank approximation of the underlying dense covariance matrix, obtained from the leading order modes of the full-rank alternative. Demonstrated on a series of reaction-diffusion problems of increasing dimension, using experimental and simulated data, the method reconstructs the sparsely observed data-generating processes with minimal loss of information, in both posterior mean and the variance, paving the way for further integration of physical and probabilistic approaches to complex systems.
InfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019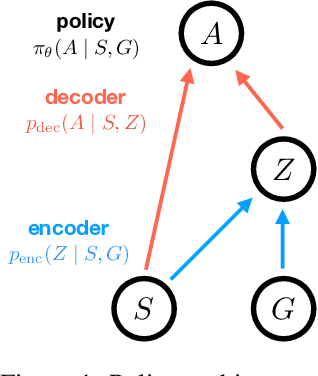



A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.
AfroMT: Pretraining Strategies and Reproducible Benchmarks for Translation of 8 African Languages
Sep 10, 2021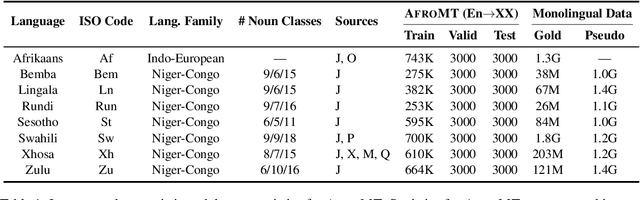
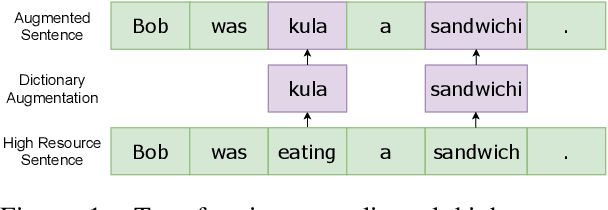
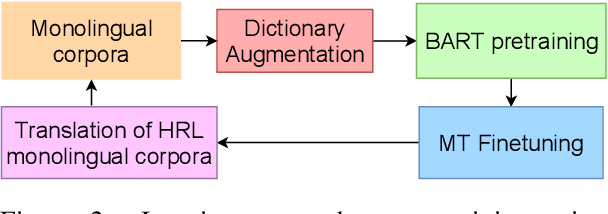
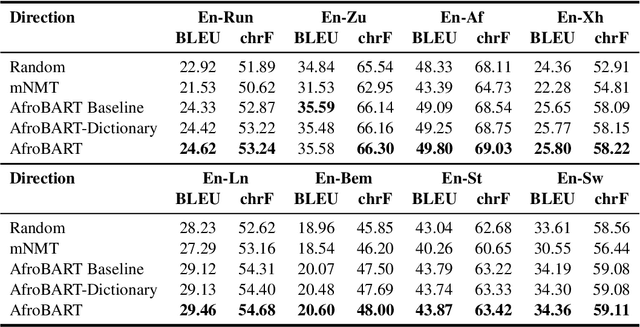
Reproducible benchmarks are crucial in driving progress of machine translation research. However, existing machine translation benchmarks have been mostly limited to high-resource or well-represented languages. Despite an increasing interest in low-resource machine translation, there are no standardized reproducible benchmarks for many African languages, many of which are used by millions of speakers but have less digitized textual data. To tackle these challenges, we propose AfroMT, a standardized, clean, and reproducible machine translation benchmark for eight widely spoken African languages. We also develop a suite of analysis tools for system diagnosis taking into account the unique properties of these languages. Furthermore, we explore the newly considered case of low-resource focused pretraining and develop two novel data augmentation-based strategies, leveraging word-level alignment information and pseudo-monolingual data for pretraining multilingual sequence-to-sequence models. We demonstrate significant improvements when pretraining on 11 languages, with gains of up to 2 BLEU points over strong baselines. We also show gains of up to 12 BLEU points over cross-lingual transfer baselines in data-constrained scenarios. All code and pretrained models will be released as further steps towards larger reproducible benchmarks for African languages.
An Upper Confidence Bound for Simultaneous Exploration and Exploitation in Heterogeneous Multi-Robot Systems
May 13, 2021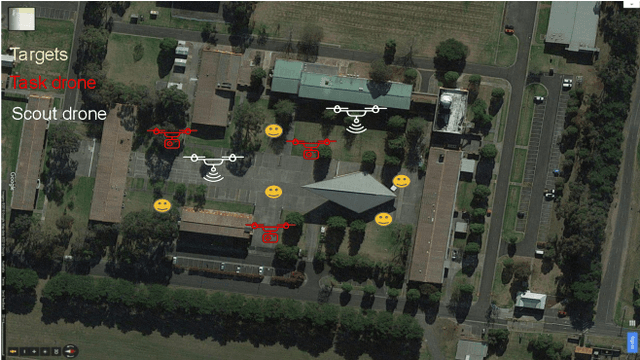
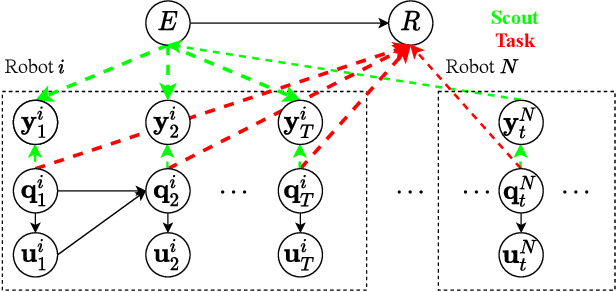
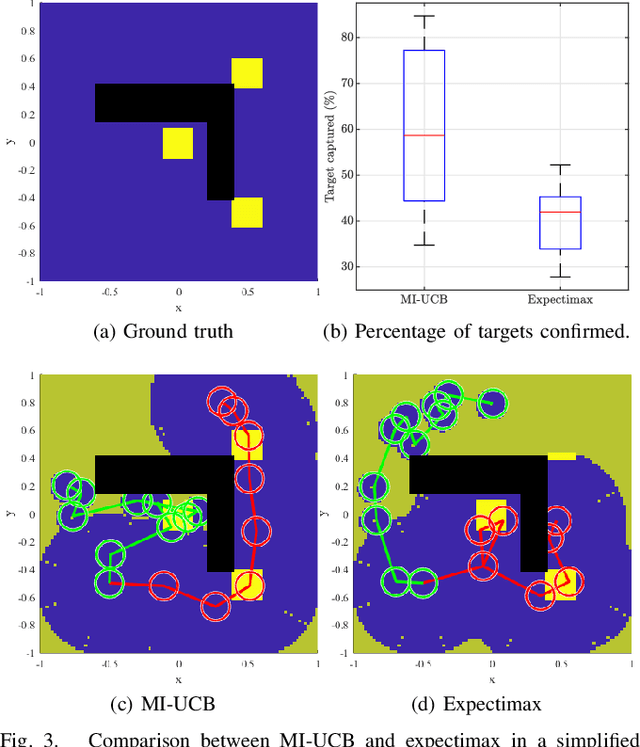
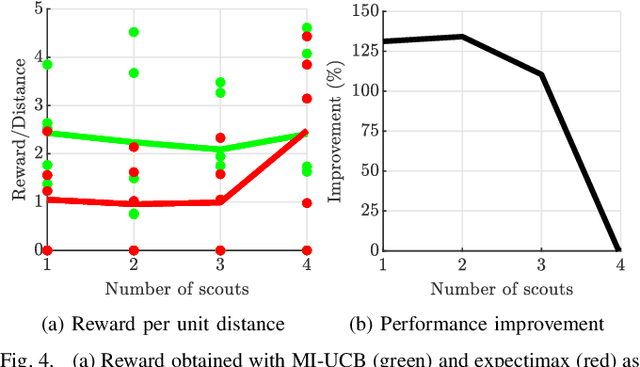
Heterogeneous multi-robot systems are advantageous for operations in unknown environments because functionally specialised robots can gather environmental information, while others perform tasks. We define this decomposition as the scout-task robot architecture and show how it avoids the need to explicitly balance exploration and exploitation~by permitting the system to do both simultaneously. The challenge is to guide exploration in a way that improves overall performance for time-limited tasks. We derive a novel upper confidence bound for simultaneous exploration and exploitation based on mutual information and present a general solution for scout-task coordination using decentralised Monte Carlo tree search. We evaluate the performance of our algorithms in a multi-drone surveillance scenario in which scout robots are equipped with low-resolution, long-range sensors and task robots capture detailed information using short-range sensors. The results address a new class of coordination problem for heterogeneous teams that has many practical applications.
Deep Learning under Privileged Information Using Heteroscedastic Dropout
May 29, 2018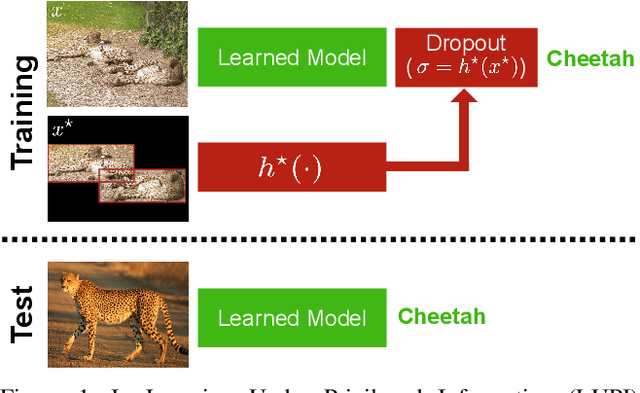
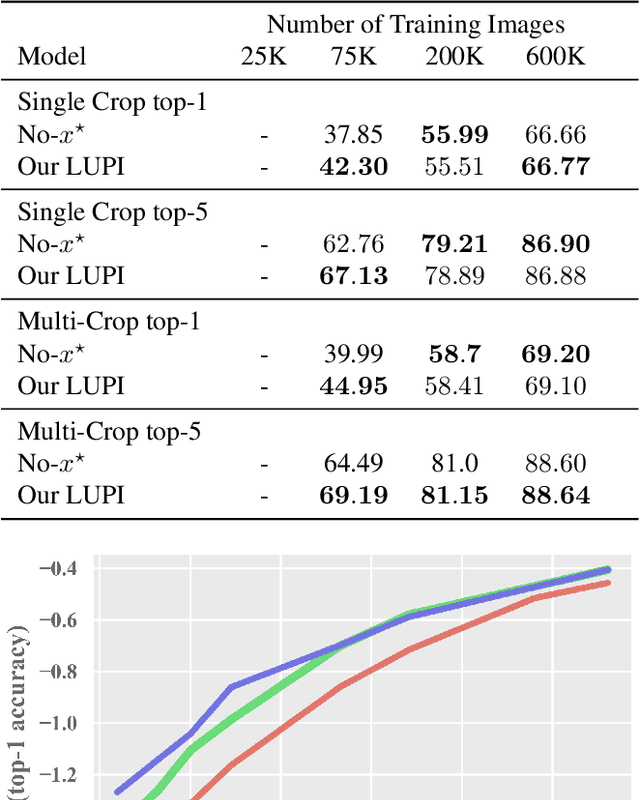
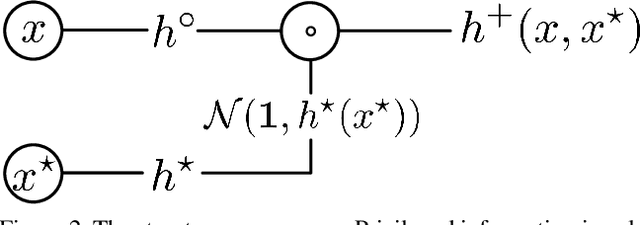
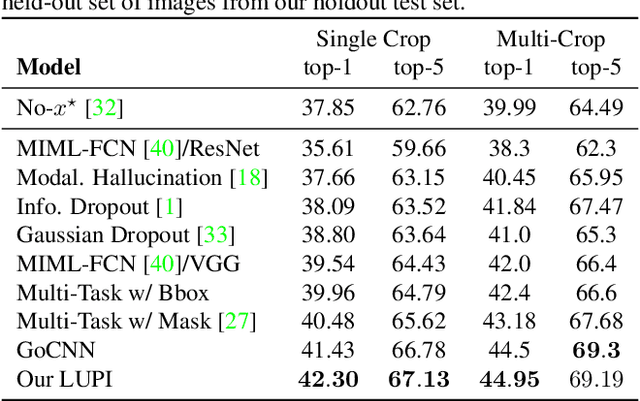
Unlike machines, humans learn through rapid, abstract model-building. The role of a teacher is not simply to hammer home right or wrong answers, but rather to provide intuitive comments, comparisons, and explanations to a pupil. This is what the Learning Under Privileged Information (LUPI) paradigm endeavors to model by utilizing extra knowledge only available during training. We propose a new LUPI algorithm specifically designed for Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). We propose to use a heteroscedastic dropout (i.e. dropout with a varying variance) and make the variance of the dropout a function of privileged information. Intuitively, this corresponds to using the privileged information to control the uncertainty of the model output. We perform experiments using CNNs and RNNs for the tasks of image classification and machine translation. Our method significantly increases the sample efficiency during learning, resulting in higher accuracy with a large margin when the number of training examples is limited. We also theoretically justify the gains in sample efficiency by providing a generalization error bound decreasing with $O(\frac{1}{n})$, where $n$ is the number of training examples, in an oracle case.
PIP: Physical Interaction Prediction via Mental Imagery with Span Selection
Sep 10, 2021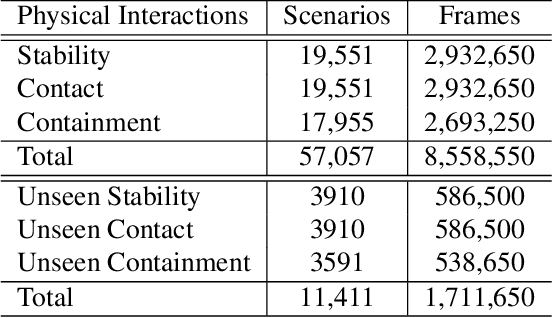

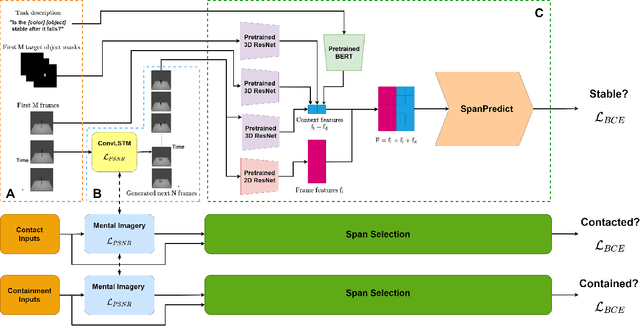

To align advanced artificial intelligence (AI) with human values and promote safe AI, it is important for AI to predict the outcome of physical interactions. Even with the ongoing debates on how humans predict the outcomes of physical interactions among objects in the real world, there are works attempting to tackle this task via cognitive-inspired AI approaches. However, there is still a lack of AI approaches that mimic the mental imagery humans use to predict physical interactions in the real world. In this work, we propose a novel PIP scheme: Physical Interaction Prediction via Mental Imagery with Span Selection. PIP utilizes a deep generative model to output future frames of physical interactions among objects before extracting crucial information for predicting physical interactions by focusing on salient frames using span selection. To evaluate our model, we propose a large-scale SPACE+ dataset of synthetic video frames, including three physical interaction events in a 3D environment. Our experiments show that PIP outperforms baselines and human performance in physical interaction prediction for both seen and unseen objects. Furthermore, PIP's span selection scheme can effectively identify the frames where physical interactions among objects occur within the generated frames, allowing for added interpretability.
Disrupting Adversarial Transferability in Deep Neural Networks
Aug 27, 2021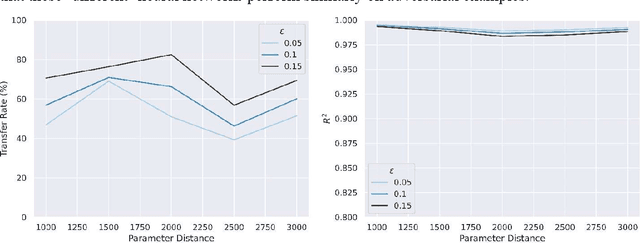
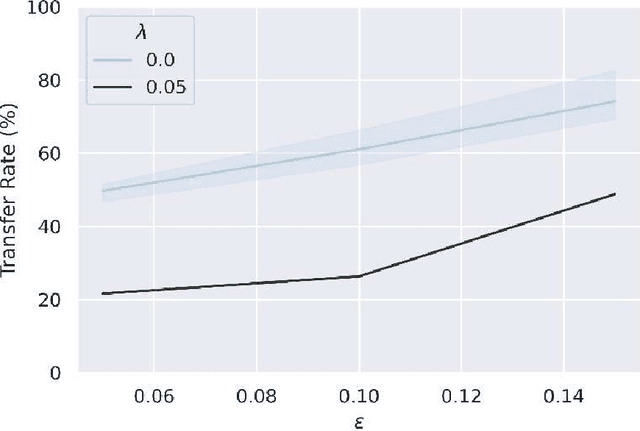
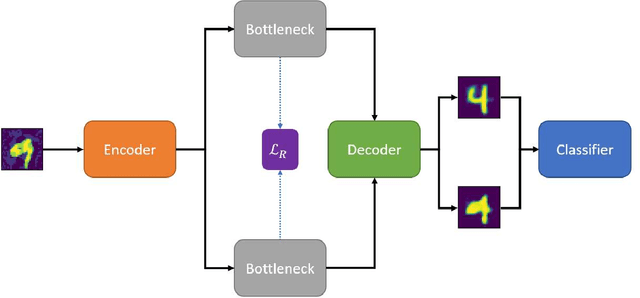
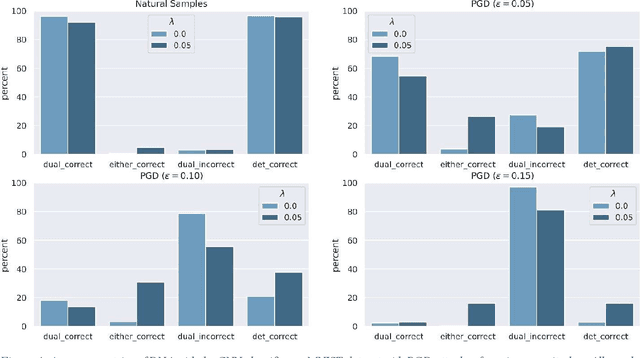
Adversarial attack transferability is a well-recognized phenomenon in deep learning. Prior work has partially explained transferability by recognizing common adversarial subspaces and correlations between decision boundaries, but we have found little explanation in the literature beyond this. In this paper, we propose that transferability between seemingly different models is due to a high linear correlation between features that different deep neural networks extract. In other words, two models trained on the same task that are seemingly distant in the parameter space likely extract features in the same fashion, just with trivial shifts and rotations between the latent spaces. Furthermore, we show how applying a feature correlation loss, which decorrelates the extracted features in a latent space, can drastically reduce the transferability of adversarial attacks between models, suggesting that the models complete tasks in semantically different ways. Finally, we propose a Dual Neck Autoencoder (DNA), which leverages this feature correlation loss to create two meaningfully different encodings of input information with reduced transferability.
HeteSpaceyWalk: A Heterogeneous Spacey Random Walk for Heterogeneous Information Network Embedding
Sep 07, 2019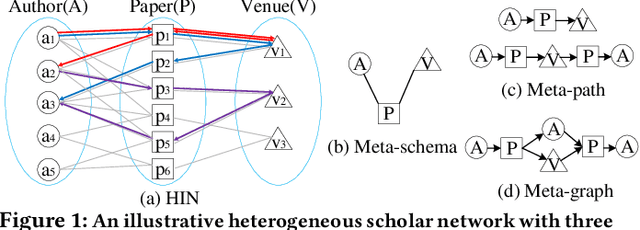
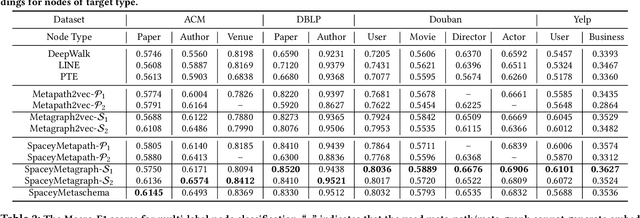
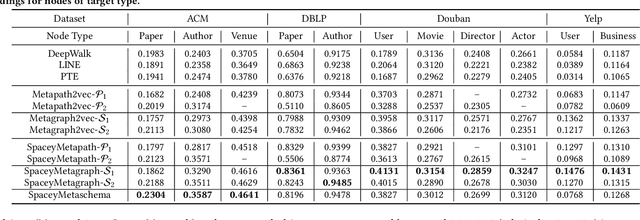
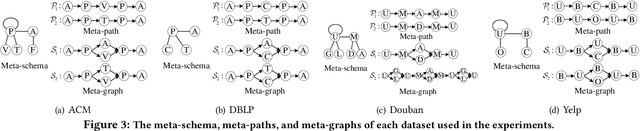
Heterogeneous information network (HIN) embedding has gained increasing interests recently. However, the current way of random-walk based HIN embedding methods have paid few attention to the higher-order Markov chain nature of meta-path guided random walks, especially to the stationarity issue. In this paper, we systematically formalize the meta-path guided random walk as a higher-order Markov chain process, and present a heterogeneous personalized spacey random walk to efficiently and effectively attain the expected stationary distribution among nodes. Then we propose a generalized scalable framework to leverage the heterogeneous personalized spacey random walk to learn embeddings for multiple types of nodes in an HIN guided by a meta-path, a meta-graph, and a meta-schema respectively. We conduct extensive experiments in several heterogeneous networks and demonstrate that our methods substantially outperform the existing state-of-the-art network embedding algorithms.