 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIPIF: Hierarchical Planning and Information Folding for Long-Horizon LLM Agent Learning
Jun 09, 2026While Large Language Models (LLMs) have demonstrated strong capabilities as autonomous agents across a wide range of tasks, their performance often degrades in multi-turn long-horizon agentic tasks. Existing methods have made progress through fine-grained credit assignment to alleviate long-horizon sparse rewards and hierarchical reinforcement learning to decompose tasks and reduce long-term dependency. However, these methods still do not directly address long-context interference, in which continuously growing histories weaken the agent's ability to track the global task state and impair subsequent reasoning and decision-making. Inspired by the way humans handle complex tasks through subgoal decomposition and completed progress summarization, we propose Hierarchical Planning and Information Folding (HIPIF) for long-horizon LLM agent learning. HIPIF trains the agent end-to-end to organize long-horizon execution around explicit subgoals while folding completed subgoal histories to reduce long-context interference. Furthermore, to stabilize subgoal-based planning and execution, HIPIF combines hierarchical reflection and subgoal-oriented process rewards to guide subgoal generation, transition, and execution, without relying on costly auxiliary models or task-specific expert trajectories. Extensive experiments on three publicly available agentic benchmarks demonstrate the validity of our method.
Predictable Scaling Laws of Optimal Hyperparameters for LLM Continued Pre-training
Jun 04, 2026The efficacy of continued pre-training for Large Language Models (LLMs) hinges upon hyperparameter configurations, such as learning rate and batch size. However, current practices often rely on heuristics or grid searches, leading to training instability and excessive costs. In this work, we first empirically discover that optimal hyperparameters follow stable and predictable scaling laws throughout the continued pre-training process. Leveraging these insights, we propose a novel framework to establish quantitative relationships between compute budget and optimal hyperparameters for a given checkpoint. Our approach has two stages: (1) \textit{Empirical Law Discovery}, where we train small-scale proxy models to derive functions mapping compute budget to optimal hyperparameters via standard loss-compute scaling laws; and (2) \textit{State-Aware Hyperparameter Prediction}, where we evaluate an initial checkpoint's validation loss and use the inverse scaling law to estimate its \textit{equivalent pre-training compute} -- the compute needed to achieve the same loss from scratch. Combining this with the planned compute budget, we predict optimal hyperparameters for the target run. Empirical results demonstrate that our method reduces the hyperparameter search overhead by up to 90\% while achieving comparable or superior performance relative to baselines. This model-agnostic framework generalizes across architectures, providing a principled and efficient methodology for diverse continued pre-training scenarios starting from any given point.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
FRAMES: Boosting LLMs with A Four-Quadrant Multi-Stage Pretraining Strategy
Feb 08, 2025



Large language models (LLMs) have significantly advanced human language understanding and generation, with pretraining data quality and organization being crucial to their performance. Multi-stage pretraining is a promising approach, but existing methods often lack quantitative criteria for data partitioning and instead rely on intuitive heuristics. In this paper, we propose the novel Four-quadRAnt Multi-stage prEtraining Strategy (FRAMES), guided by the established principle of organizing the pretraining process into four stages to achieve significant loss reductions four times. This principle is grounded in two key findings: first, training on high Perplexity (PPL) data followed by low PPL data, and second, training on low PPL difference (PD) data followed by high PD data, both causing the loss to drop significantly twice and performance enhancements. By partitioning data into four quadrants and strategically organizing them, FRAMES achieves a remarkable 16.8% average improvement over random sampling across MMLU and CMMLU, effectively boosting LLM performance.
Dual Instruction Tuning with Large Language Models for Mathematical Reasoning
Mar 27, 2024



Recent advancements highlight the success of instruction tuning with large language models (LLMs) utilizing Chain-of-Thought (CoT) data for mathematical reasoning tasks. Despite the fine-tuned LLMs, challenges persist, such as incorrect, missing, and redundant steps in CoT generation leading to inaccuracies in answer predictions. To alleviate this problem, we propose a dual instruction tuning strategy to meticulously model mathematical reasoning from both forward and reverse directions. This involves introducing the Intermediate Reasoning State Prediction task (forward reasoning) and the Instruction Reconstruction task (reverse reasoning) to enhance the LLMs' understanding and execution of instructions. Training instances for these tasks are constructed based on existing mathematical instruction tuning datasets. Subsequently, LLMs undergo multi-task fine-tuning using both existing mathematical instructions and the newly created data. Comprehensive experiments validate the effectiveness and domain generalization of the dual instruction tuning strategy across various mathematical reasoning tasks.
HopPG: Self-Iterative Program Generation for Multi-Hop Question Answering over Heterogeneous Knowledge
Sep 10, 2023



The semantic parsing-based method is an important research branch for knowledge-based question answering. It usually generates executable programs lean upon the question and then conduct them to reason answers over a knowledge base. Benefit from this inherent mechanism, it has advantages in the performance and the interpretability. However, traditional semantic parsing methods usually generate a complete program before executing it, which struggles with multi-hop question answering over heterogeneous knowledge. On one hand, generating a complete multi-hop program relies on multiple heterogeneous supporting facts, and it is difficult for generators to understand these facts simultaneously. On the other hand, this way ignores the semantic information of the intermediate answers at each hop, which is beneficial for subsequent generation. To alleviate these challenges, we propose a self-iterative framework for multi-hop program generation (HopPG) over heterogeneous knowledge, which leverages the previous execution results to retrieve supporting facts and generate subsequent programs hop by hop. We evaluate our model on MMQA-T^2, and the experimental results show that HopPG outperforms existing semantic-parsing-based baselines, especially on the multi-hop questions.
UniRPG: Unified Discrete Reasoning over Table and Text as Program Generation
Oct 15, 2022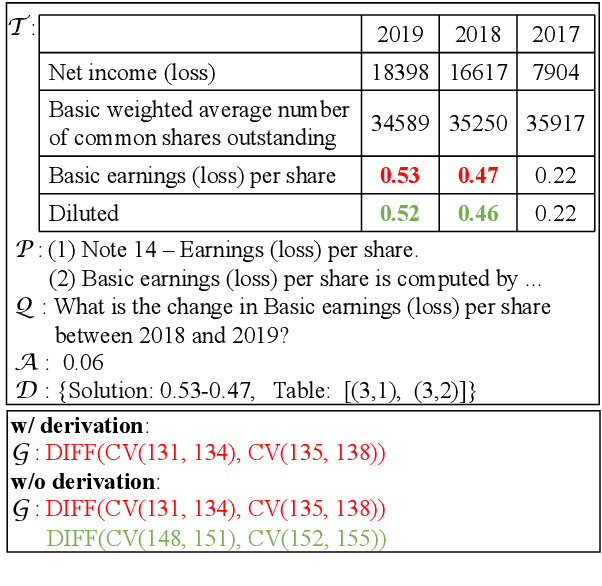
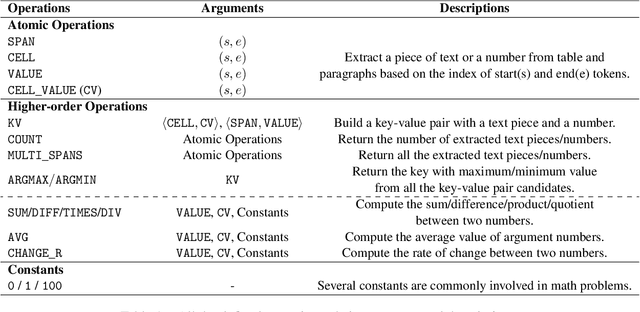
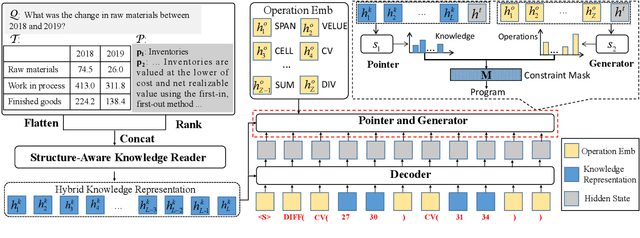
Question answering requiring discrete reasoning, e.g., arithmetic computing, comparison, and counting, over knowledge is a challenging task. In this paper, we propose UniRPG, a semantic-parsing-based approach advanced in interpretability and scalability, to perform unified discrete reasoning over heterogeneous knowledge resources, i.e., table and text, as program generation. Concretely, UniRPG consists of a neural programmer and a symbolic program executor, where a program is the composition of a set of pre-defined general atomic and higher-order operations and arguments extracted from table and text. First, the programmer parses a question into a program by generating operations and copying arguments, and then the executor derives answers from table and text based on the program. To alleviate the costly program annotation issue, we design a distant supervision approach for programmer learning, where pseudo programs are automatically constructed without annotated derivations. Extensive experiments on the TAT-QA dataset show that UniRPG achieves tremendous improvements and enhances interpretability and scalability compared with state-of-the-art methods, even without derivation annotation. Moreover, it achieves promising performance on the textual dataset DROP without derivations.
OPERA:Operation-Pivoted Discrete Reasoning over Text
May 04, 2022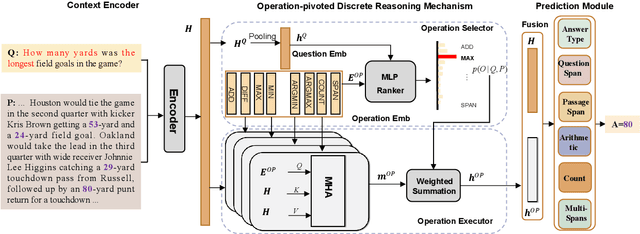

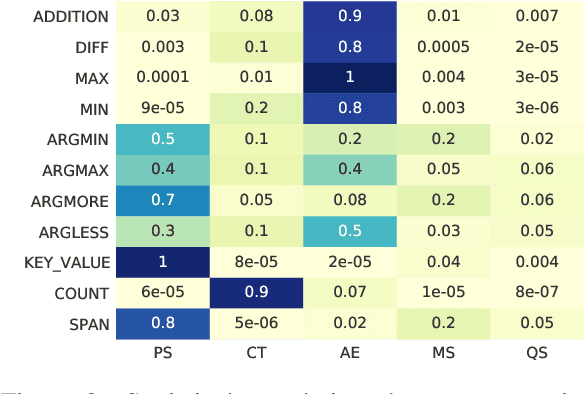

Machine reading comprehension (MRC) that requires discrete reasoning involving symbolic operations, e.g., addition, sorting, and counting, is a challenging task. According to this nature, semantic parsing-based methods predict interpretable but complex logical forms. However, logical form generation is nontrivial and even a little perturbation in a logical form will lead to wrong answers. To alleviate this issue, multi-predictor -based methods are proposed to directly predict different types of answers and achieve improvements. However, they ignore the utilization of symbolic operations and encounter a lack of reasoning ability and interpretability. To inherit the advantages of these two types of methods, we propose OPERA, an operation-pivoted discrete reasoning framework, where lightweight symbolic operations (compared with logical forms) as neural modules are utilized to facilitate the reasoning ability and interpretability. Specifically, operations are first selected and then softly executed to simulate the answer reasoning procedure. Extensive experiments on both DROP and RACENum datasets show the reasoning ability of OPERA. Moreover, further analysis verifies its interpretability.
RoR: Read-over-Read for Long Document Machine Reading Comprehension
Sep 14, 2021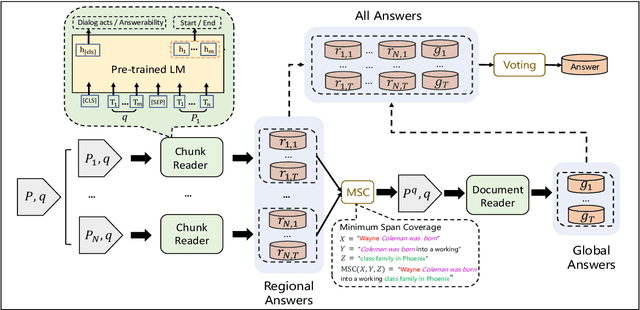
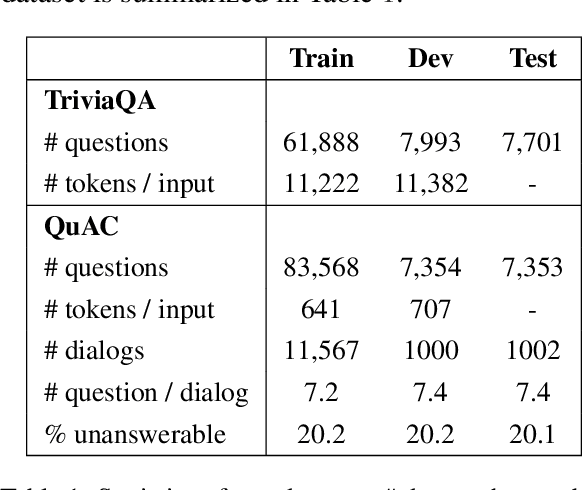
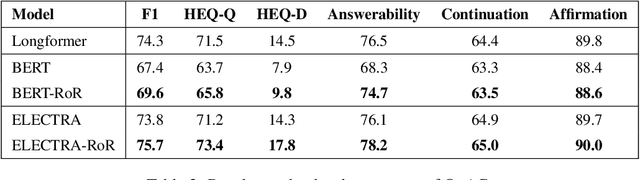
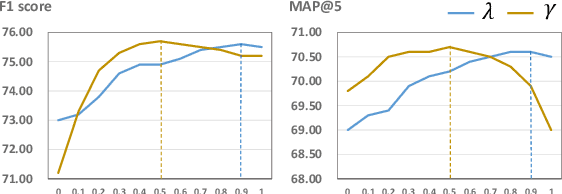
Transformer-based pre-trained models, such as BERT, have achieved remarkable results on machine reading comprehension. However, due to the constraint of encoding length (e.g., 512 WordPiece tokens), a long document is usually split into multiple chunks that are independently read. It results in the reading field being limited to individual chunks without information collaboration for long document machine reading comprehension. To address this problem, we propose RoR, a read-over-read method, which expands the reading field from chunk to document. Specifically, RoR includes a chunk reader and a document reader. The former first predicts a set of regional answers for each chunk, which are then compacted into a highly-condensed version of the original document, guaranteeing to be encoded once. The latter further predicts the global answers from this condensed document. Eventually, a voting strategy is utilized to aggregate and rerank the regional and global answers for final prediction. Extensive experiments on two benchmarks QuAC and TriviaQA demonstrate the effectiveness of RoR for long document reading. Notably, RoR ranks 1st place on the QuAC leaderboard (https://quac.ai/) at the time of submission (May 17th, 2021).
EviDR: Evidence-Emphasized Discrete Reasoning for Reasoning Machine Reading Comprehension
Aug 18, 2021
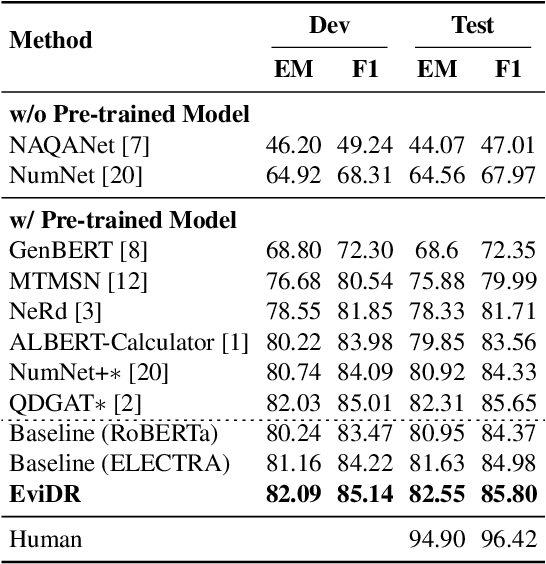
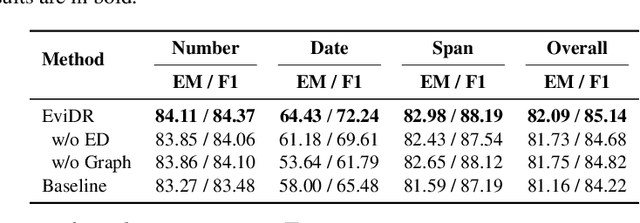

Reasoning machine reading comprehension (R-MRC) aims to answer complex questions that require discrete reasoning based on text. To support discrete reasoning, evidence, typically the concise textual fragments that describe question-related facts, including topic entities and attribute values, are crucial clues from question to answer. However, previous end-to-end methods that achieve state-of-the-art performance rarely solve the problem by paying enough emphasis on the modeling of evidence, missing the opportunity to further improve the model's reasoning ability for R-MRC. To alleviate the above issue, in this paper, we propose an evidence-emphasized discrete reasoning approach (EviDR), in which sentence and clause level evidence is first detected based on distant supervision, and then used to drive a reasoning module implemented with a relational heterogeneous graph convolutional network to derive answers. Extensive experiments are conducted on DROP (discrete reasoning over paragraphs) dataset, and the results demonstrate the effectiveness of our proposed approach. In addition, qualitative analysis verifies the capability of the proposed evidence-emphasized discrete reasoning for R-MRC.