 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attention Mechanism Meets with Hybrid Dense Network for Hyperspectral Image Classification
Jan 04, 2022
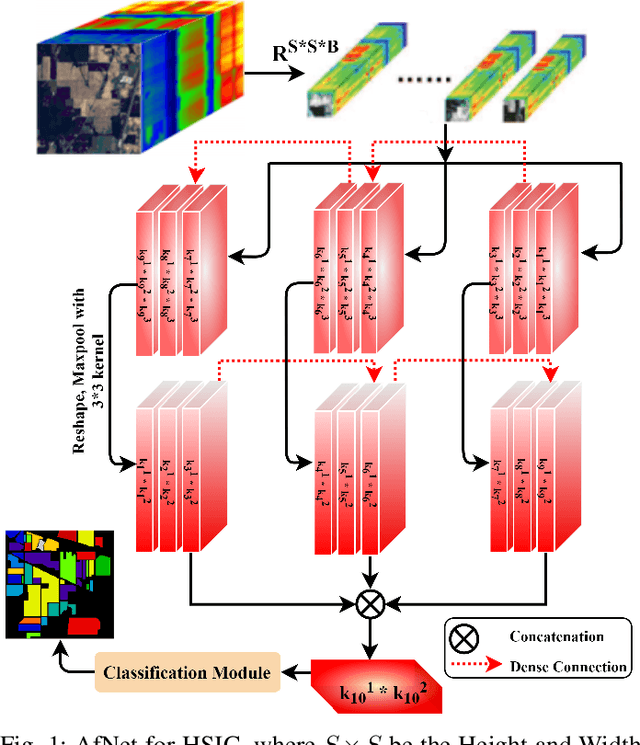
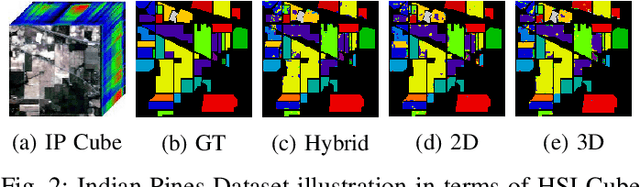
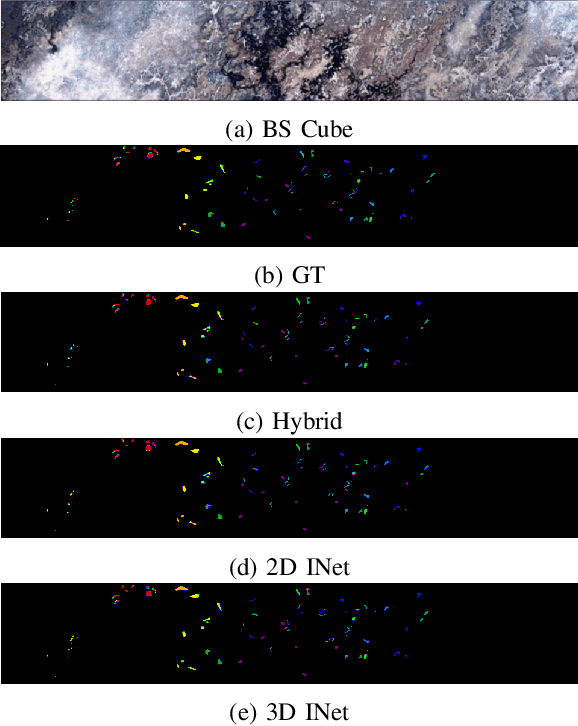
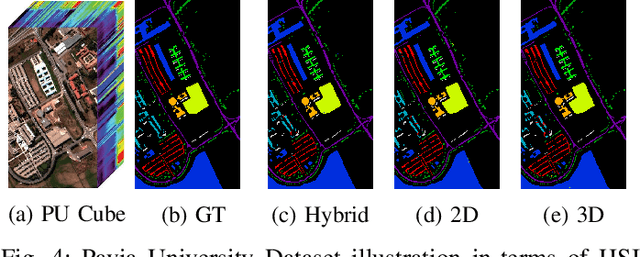
Convolutional Neural Networks (CNN) are more suitable, indeed. However, fixed kernel sizes make traditional CNN too specific, neither flexible nor conducive to feature learning, thus impacting on the classification accuracy. The convolution of different kernel size networks may overcome this problem by capturing more discriminating and relevant information. In light of this, the proposed solution aims at combining the core idea of 3D and 2D Inception net with the Attention mechanism to boost the HSIC CNN performance in a hybrid scenario. The resulting \textit{attention-fused hybrid network} (AfNet) is based on three attention-fused parallel hybrid sub-nets with different kernels in each block repeatedly using high-level features to enhance the final ground-truth maps. In short, AfNet is able to selectively filter out the discriminative features critical for classification. Several tests on HSI datasets provided competitive results for AfNet compared to state-of-the-art models. The proposed pipeline achieved, indeed, an overall accuracy of 97\% for the Indian Pines, 100\% for Botswana, 99\% for Pavia University, Pavia Center, and Salinas datasets.
Limited Lookahead in Imperfect-Information Games
Feb 17, 2019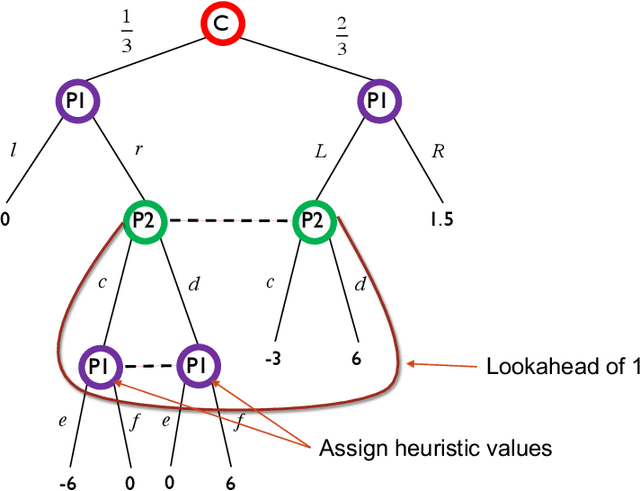
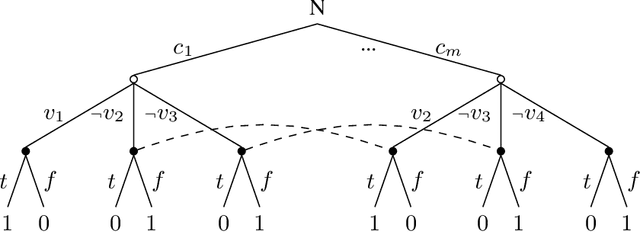
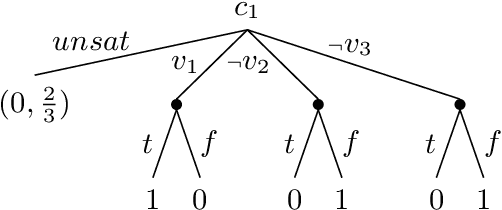
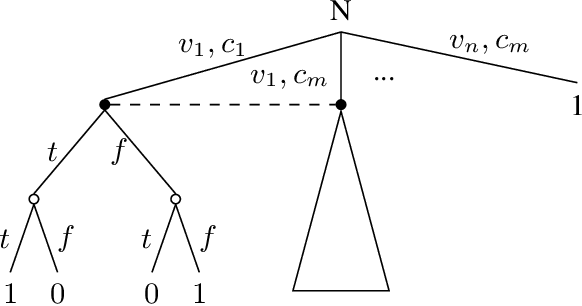
Limited lookahead has been studied for decades in complete-information games. We initiate a new direction via two simultaneous deviation points: generalization to incomplete-information games and a game-theoretic approach. We study how one should act when facing an opponent whose lookahead is limited. We study this for opponents that differ based on their lookahead depth, based on whether they, too, have incomplete information, and based on how they break ties. We characterize the hardness of finding a Nash equilibrium or an optimal commitment strategy for either player, showing that in some of these variations the problem can be solved in polynomial time while in others it is PPAD-hard or NP-hard. We proceed to design algorithms for computing optimal commitment strategies---for when the opponent breaks ties favorably, according to a fixed rule, or adversarially. We then experimentally investigate the impact of limited lookahead. The limited-lookahead player often obtains the value of the game if she knows the expected values of nodes in the game tree for some equilibrium---but we prove this is not sufficient in general. Finally, we study the impact of noise in those estimates and different lookahead depths. This uncovers an incomplete-information game lookahead pathology.
Dual Path Structural Contrastive Embeddings for Learning Novel Objects
Jan 04, 2022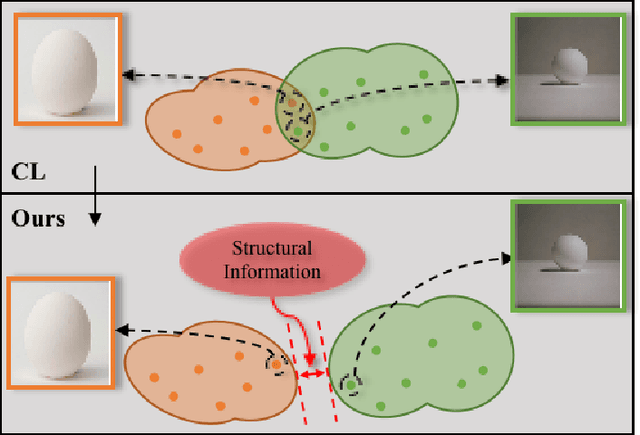
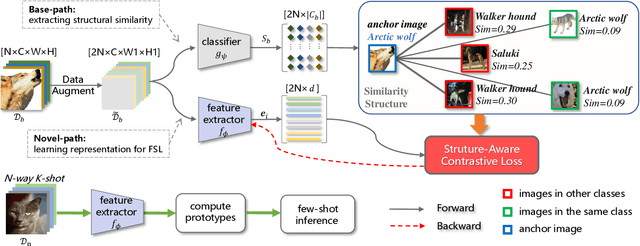
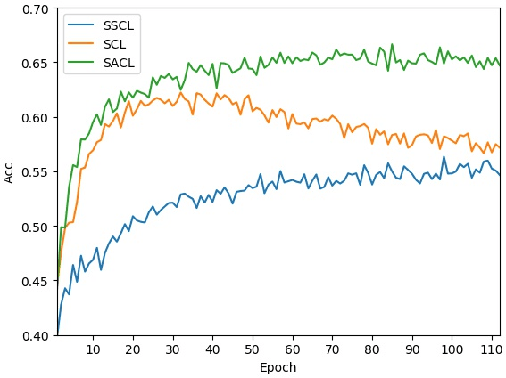

Learning novel classes from a very few labeled samples has attracted increasing attention in machine learning areas. Recent research on either meta-learning based or transfer-learning based paradigm demonstrates that gaining information on a good feature space can be an effective solution to achieve favorable performance on few-shot tasks. In this paper, we propose a simple but effective paradigm that decouples the tasks of learning feature representations and classifiers and only learns the feature embedding architecture from base classes via the typical transfer-learning training strategy. To maintain both the generalization ability across base and novel classes and discrimination ability within each class, we propose a dual path feature learning scheme that effectively combines structural similarity with contrastive feature construction. In this way, both inner-class alignment and inter-class uniformity can be well balanced, and result in improved performance. Experiments on three popular benchmarks show that when incorporated with a simple prototype based classifier, our method can still achieve promising results for both standard and generalized few-shot problems in either an inductive or transductive inference setting.
Hybrid Reflection Modulation
Nov 16, 2021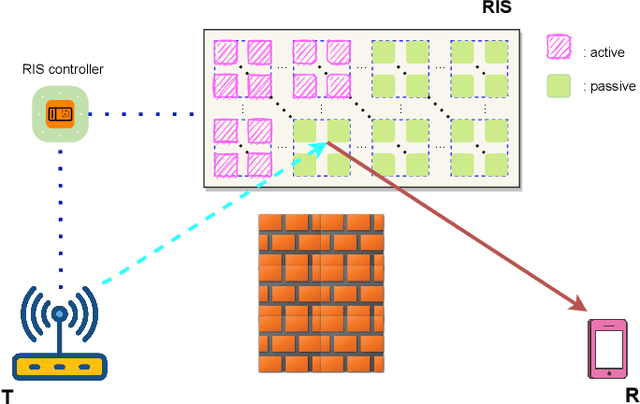
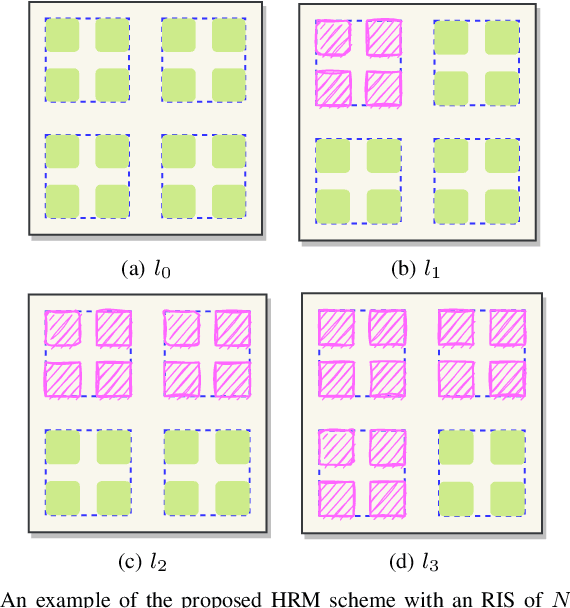
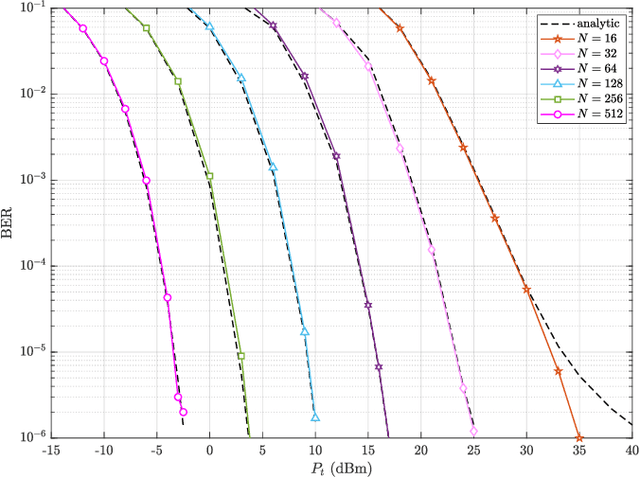
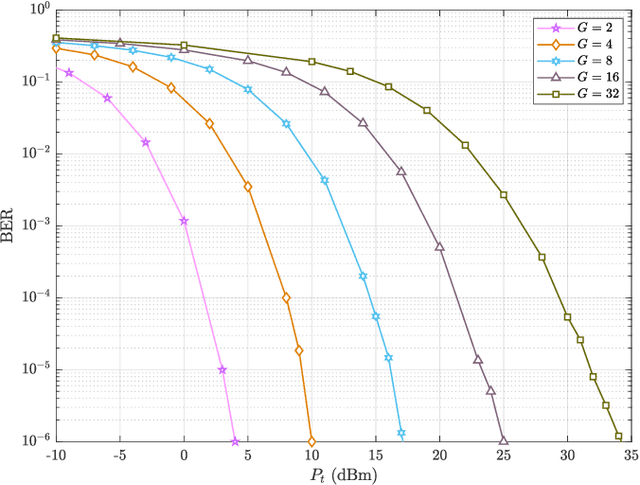
Reconfigurable intelligent surface (RIS)-empowered communication has emerged as a novel concept for customizing future wireless environments in a cost- and energy-efficient way. However, due to double path loss, existing fully passive RIS systems that purely reflect the incident signals into preferred directions attain an unsatisfactory performance improvement over the traditional wireless networks in certain conditions. To overcome this bottleneck, we propose a novel transmission scheme, named hybrid reflection modulation (HRM), exploiting both active and passive reflecting elements at the RIS and their combinations, which enables to convey information without using any radio frequency (RF) chains. In the HRM scheme, the active reflecting elements using additional power amplifiers are able to amplify and reflect the incoming signal, while the remaining passive elements can simply reflect the signals with appropriate phase shifts. Based on this novel transmission model, we obtain an upper bound for the average bit error probability (ABEP), and derive achievable rate of the system using an information theoretic approach. Moreover, comprehensive computer simulations are performed to prove the superiority of the proposed HRM scheme over existing fully passive, fully active and reflection modulation (RM) systems.
Deep Image Matting with Flexible Guidance Input
Oct 21, 2021
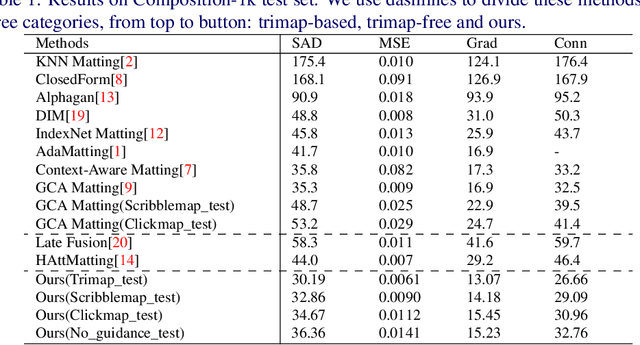
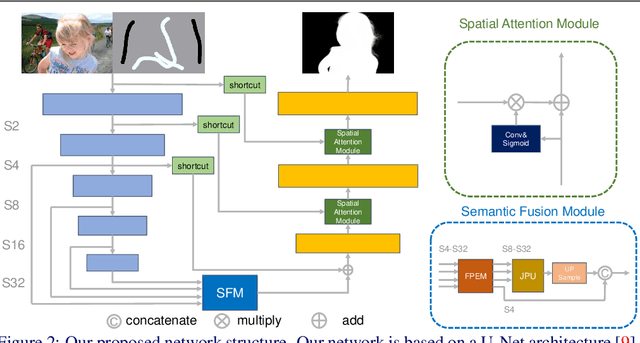

Image matting is an important computer vision problem. Many existing matting methods require a hand-made trimap to provide auxiliary information, which is very expensive and limits the real world usage. Recently, some trimap-free methods have been proposed, which completely get rid of any user input. However, their performance lag far behind trimap-based methods due to the lack of guidance information. In this paper, we propose a matting method that use Flexible Guidance Input as user hint, which means our method can use trimap, scribblemap or clickmap as guidance information or even work without any guidance input. To achieve this, we propose Progressive Trimap Deformation(PTD) scheme that gradually shrink the area of the foreground and background of the trimap with the training step increases and finally become a scribblemap. To make our network robust to any user scribble and click, we randomly sample points on foreground and background and perform curve fitting. Moreover, we propose Semantic Fusion Module(SFM) which utilize the Feature Pyramid Enhancement Module(FPEM) and Joint Pyramid Upsampling(JPU) in matting task for the first time. The experiments show that our method can achieve state-of-the-art results comparing with existing trimap-based and trimap-free methods.
Hierarchical Heterogeneous Graph Representation Learning for Short Text Classification
Oct 30, 2021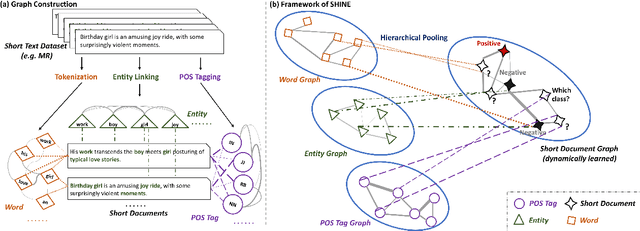
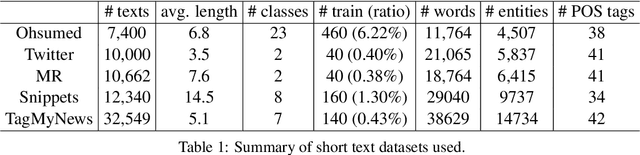
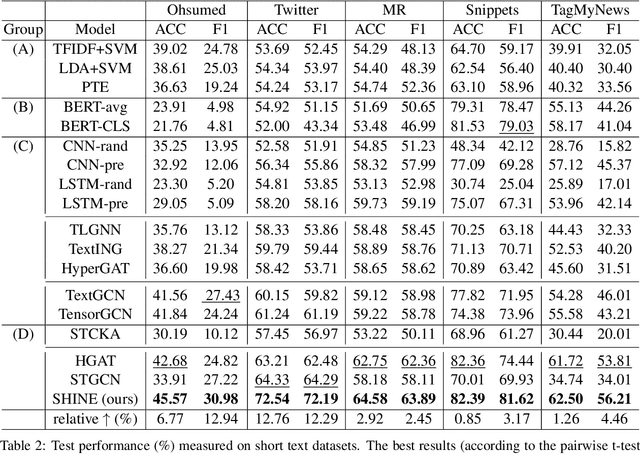
Short text classification is a fundamental task in natural language processing. It is hard due to the lack of context information and labeled data in practice. In this paper, we propose a new method called SHINE, which is based on graph neural network (GNN), for short text classification. First, we model the short text dataset as a hierarchical heterogeneous graph consisting of word-level component graphs which introduce more semantic and syntactic information. Then, we dynamically learn a short document graph that facilitates effective label propagation among similar short texts. Thus, compared with existing GNN-based methods, SHINE can better exploit interactions between nodes of the same types and capture similarities between short texts. Extensive experiments on various benchmark short text datasets show that SHINE consistently outperforms state-of-the-art methods, especially with fewer labels.
RetroComposer: Discovering Novel Reactions by Composing Templates for Retrosynthesis Prediction
Dec 20, 2021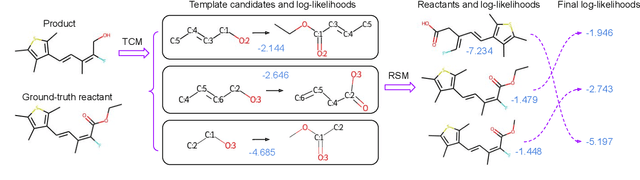
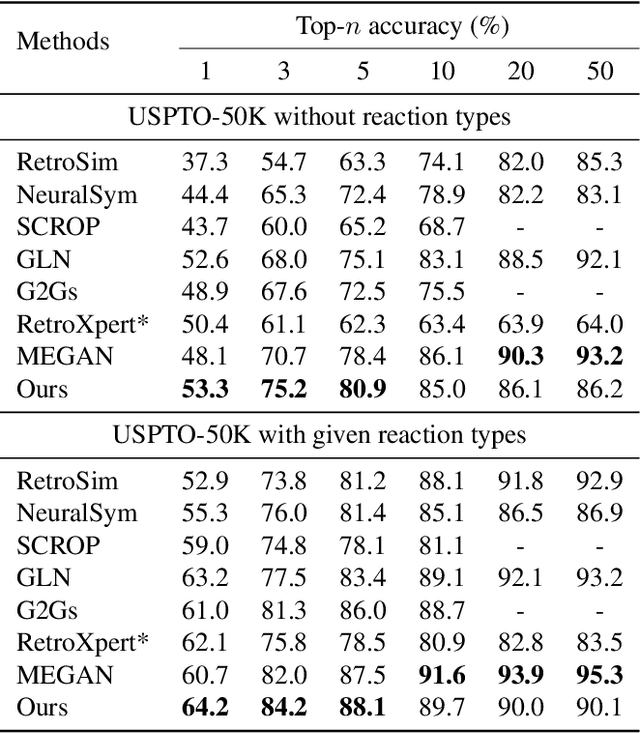
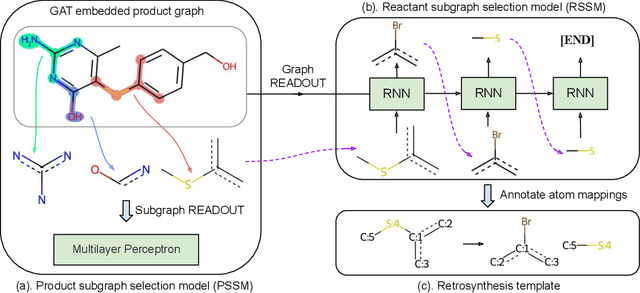
The main target of retrosynthesis is to recursively decompose desired molecules into available building blocks. Existing template-based retrosynthesis methods follow a template selection stereotype and suffer from the limited training templates, which prevents them from discovering novel reactions. To overcome the limitation, we propose an innovative retrosynthesis prediction framework that can compose novel templates beyond training templates. So far as we know, this is the first method that can find novel templates for retrosynthesis prediction. Besides, we propose an effective reactant candidates scoring model that can capture atom-level transformation information, and it helps our method outperform existing methods by a large margin. Experimental results show that our method can produce novel templates for 328 test reactions in the USPTO-50K dataset, including 21 test reactions that are not covered by the training templates.
Neural Piecewise-Constant Delay Differential Equations
Jan 04, 2022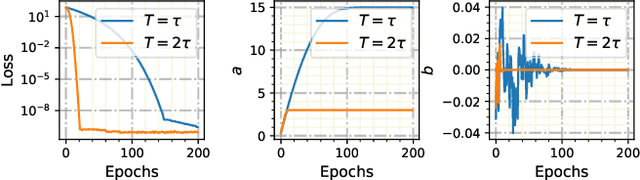
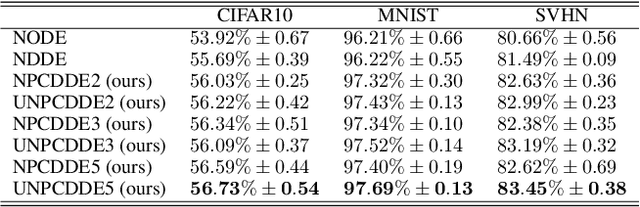
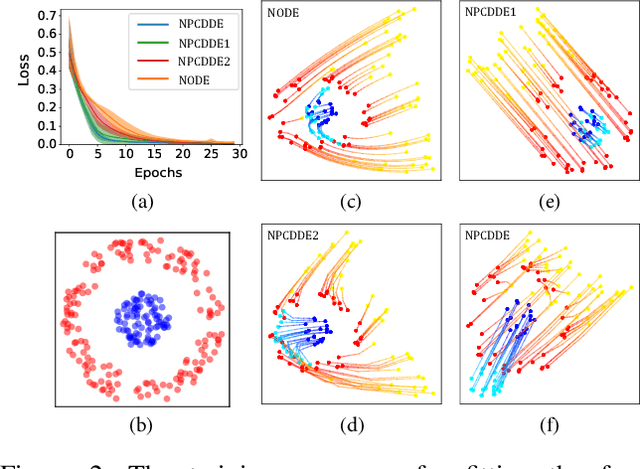
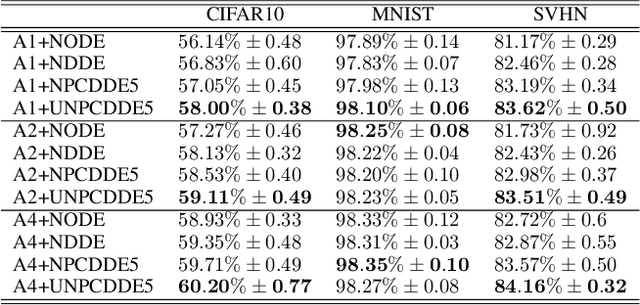
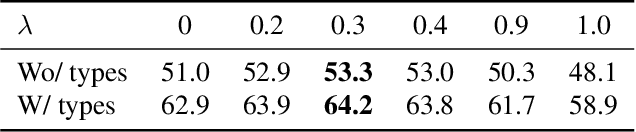
Continuous-depth neural networks, such as the Neural Ordinary Differential Equations (ODEs), have aroused a great deal of interest from the communities of machine learning and data science in recent years, which bridge the connection between deep neural networks and dynamical systems. In this article, we introduce a new sort of continuous-depth neural network, called the Neural Piecewise-Constant Delay Differential Equations (PCDDEs). Here, unlike the recently proposed framework of the Neural Delay Differential Equations (DDEs), we transform the single delay into the piecewise-constant delay(s). The Neural PCDDEs with such a transformation, on one hand, inherit the strength of universal approximating capability in Neural DDEs. On the other hand, the Neural PCDDEs, leveraging the contributions of the information from the multiple previous time steps, further promote the modeling capability without augmenting the network dimension. With such a promotion, we show that the Neural PCDDEs do outperform the several existing continuous-depth neural frameworks on the one-dimensional piecewise-constant delay population dynamics and real-world datasets, including MNIST, CIFAR10, and SVHN.
Pre-training Graph Neural Network for Cross Domain Recommendation
Nov 16, 2021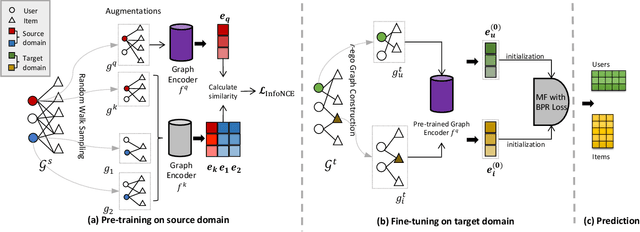
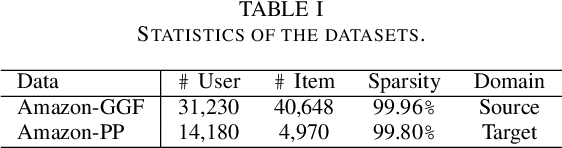
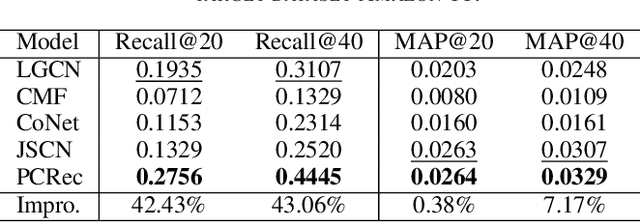
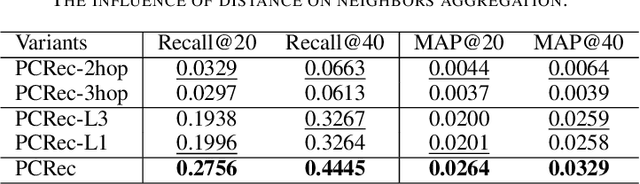
A recommender system predicts users' potential interests in items, where the core is to learn user/item embeddings. Nevertheless, it suffers from the data-sparsity issue, which the cross-domain recommendation can alleviate. However, most prior works either jointly learn the source domain and target domain models, or require side-features. However, jointly training and side features would affect the prediction on the target domain as the learned embedding is dominated by the source domain containing bias information. Inspired by the contemporary arts in pre-training from graph representation learning, we propose a pre-training and fine-tuning diagram for cross-domain recommendation. We devise a novel Pre-training Graph Neural Network for Cross-Domain Recommendation (PCRec), which adopts the contrastive self-supervised pre-training of a graph encoder. Then, we transfer the pre-trained graph encoder to initialize the node embeddings on the target domain, which benefits the fine-tuning of the single domain recommender system on the target domain. The experimental results demonstrate the superiority of PCRec. Detailed analyses verify the superiority of PCRec in transferring information while avoiding biases from source domains.
Deep Learning Based Near-OrthogonalSuperposition Code for Short Message Transmission
Nov 05, 2021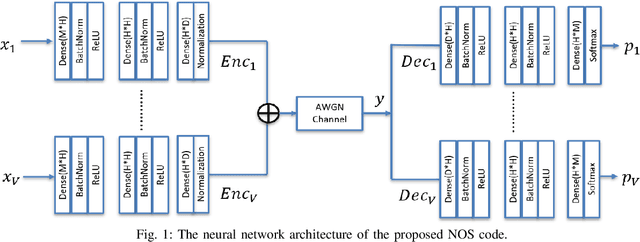
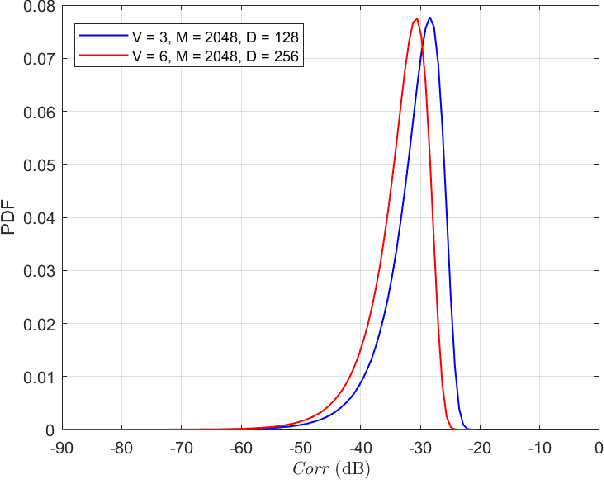
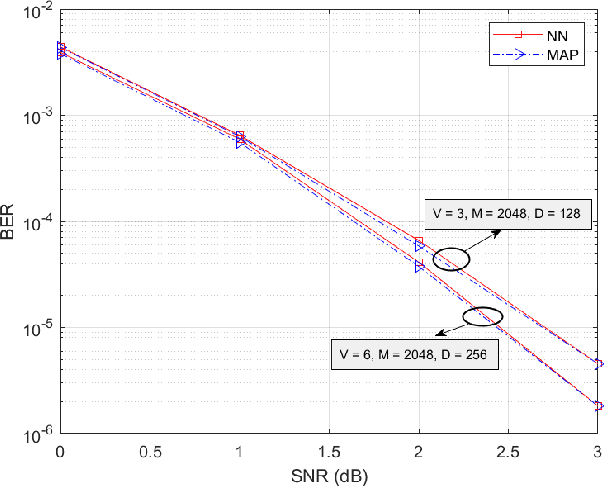
Massive machine type communication (mMTC) hasattracted new coding schemes optimized for reliable short mes-sage transmission. In this paper, a novel deep learning basednear-orthogonal superposition (NOS) coding scheme is proposedfor reliable transmission of short messages in the additive whiteGaussian noise (AWGN) channel for mMTC applications. Sim-ilar to recent hyper-dimensional modulation (HDM), the NOSencoder spreads the information bits to multiple near-orthogonalhigh dimensional vectors to be combined (superimposed) into asingle vector for transmission. The NOS decoder first estimatesthe information vectors and then performs a cyclic redundancycheck (CRC)-assistedK-best tree-search algorithm to furtherreduce the packet error rate. The proposed NOS encoder anddecoder are deep neural networks (DNNs) jointly trained asan auto-encoder and decoder pair to learn a new NOS codingscheme with near-orthogonal codewords. Simulation results showthe proposed deep learning-based NOS scheme outperformsHDM and Polar code with CRC-aided list decoding for short(32-bit) message transmission.