 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Exploration for Iterative Nash Preference Optimization
May 31, 2026Preference alignment is central to improving large language models, but standard reward-based formulations can be restrictive when human preferences are cyclic, non-transitive, or otherwise not representable by a scalar reward. Nash Learning from Human Feedback (NLHF) addresses this limitation by modeling alignment as a preference game and targeting a Nash equilibrium rather than a reward maximizer. However, the learning-theoretic foundations of scalable NLHF remain limited. Existing regret guarantees rely on oracle-based methods that estimate a general preference model and solve KL-regularized minimax problems, while iterative NLHF methods directly optimize policy-level preference losses and are easier to implement but lack regret guarantees. We study online iterative NLHF under general preference models and identify exploration as the key obstacle. First, we show that standard iterative NLHF can suffer an exponential dependence on the KL-regularization parameter, revealing that implicit exploration through policy updates is insufficient for controlling regret. Second, we propose an explicitly exploratory iterative NLHF algorithm that combines SFT-based regularization with adversarial policy exploration. The resulting method retains the direct policy optimization structure of iterative NLHF, avoids explicit preference model estimation, and achieves an $O(\sqrt{T})$ regret bound without an exponential dependence on the KL-regularization parameter. We show that the regret can be improved to $O(\log(T))$ with access to a minimax oracle, clarifying the computational-statistical tradeoff in learning general preference games. Finally, we instantiate our method for LLM fine-tuning and evaluate it on \texttt{Llama-3-8B-Instruct} across multiple benchmarks, where explicit exploration yields consistent improvements over existing NLHF baselines.
Online Generalized-mean Welfare Maximization: Achieving Near-Optimal Regret from Samples
Feb 11, 2026We study online fair allocation of $T$ sequentially arriving items among $n$ agents with heterogeneous preferences, with the objective of maximizing generalized-mean welfare, defined as the $p$-mean of agents' time-averaged utilities, with $p\in (-\infty, 1)$. We first consider the i.i.d. arrival model and show that the pure greedy algorithm -- which myopically chooses the welfare-maximizing integral allocation -- achieves $\widetilde{O}(1/T)$ average regret. Importantly, in contrast to prior work, our algorithm does not require distributional knowledge and achieves the optimal regret rate using only the online samples. We then go beyond i.i.d. arrivals and investigate a nonstationary model with time-varying independent distributions. In the absence of additional data about the distributions, it is known that every online algorithm must suffer $Ω(1)$ average regret. We show that only a single historical sample from each distribution is sufficient to recover the optimal $\widetilde{O}(1/T)$ average regret rate, even in the face of arbitrary non-stationarity. Our algorithms are based on the re-solving paradigm: they assume that the remaining items will be the ones seen historically in those periods and solve the resulting welfare-maximization problem to determine the decision in every period. Finally, we also account for distribution shifts that may distort the fidelity of historical samples and show that the performance of our re-solving algorithms is robust to such shifts.
No-Regret Learning Under Adversarial Resource Constraints: A Spending Plan Is All You Need!
Jun 16, 2025We study online decision making problems under resource constraints, where both reward and cost functions are drawn from distributions that may change adversarially over time. We focus on two canonical settings: $(i)$ online resource allocation where rewards and costs are observed before action selection, and $(ii)$ online learning with resource constraints where they are observed after action selection, under full feedback or bandit feedback. It is well known that achieving sublinear regret in these settings is impossible when reward and cost distributions may change arbitrarily over time. To address this challenge, we analyze a framework in which the learner is guided by a spending plan--a sequence prescribing expected resource usage across rounds. We design general (primal-)dual methods that achieve sublinear regret with respect to baselines that follow the spending plan. Crucially, the performance of our algorithms improves when the spending plan ensures a well-balanced distribution of the budget across rounds. We additionally provide a robust variant of our methods to handle worst-case scenarios where the spending plan is highly imbalanced. To conclude, we study the regret of our algorithms when competing against benchmarks that deviate from the prescribed spending plan.
On Separation Between Best-Iterate, Random-Iterate, and Last-Iterate Convergence of Learning in Games
Mar 04, 2025Non-ergodic convergence of learning dynamics in games is widely studied recently because of its importance in both theory and practice. Recent work (Cai et al., 2024) showed that a broad class of learning dynamics, including Optimistic Multiplicative Weights Update (OMWU), can exhibit arbitrarily slow last-iterate convergence even in simple $2 \times 2$ matrix games, despite many of these dynamics being known to converge asymptotically in the last iterate. It remains unclear, however, whether these algorithms achieve fast non-ergodic convergence under weaker criteria, such as best-iterate convergence. We show that for $2\times 2$ matrix games, OMWU achieves an $O(T^{-1/6})$ best-iterate convergence rate, in stark contrast to its slow last-iterate convergence in the same class of games. Furthermore, we establish a lower bound showing that OMWU does not achieve any polynomial random-iterate convergence rate, measured by the expected duality gaps across all iterates. This result challenges the conventional wisdom that random-iterate convergence is essentially equivalent to best-iterate convergence, with the former often used as a proxy for establishing the latter. Our analysis uncovers a new connection to dynamic regret and presents a novel two-phase approach to best-iterate convergence, which could be of independent interest.
On the Optimality of Dilated Entropy and Lower Bounds for Online Learning in Extensive-Form Games
Oct 30, 2024First-order methods (FOMs) are arguably the most scalable algorithms for equilibrium computation in large extensive-form games. To operationalize these methods, a distance-generating function, acting as a regularizer for the strategy space, must be chosen. The ratio between the strong convexity modulus and the diameter of the regularizer is a key parameter in the analysis of FOMs. A natural question is then: what is the optimal distance-generating function for extensive-form decision spaces? In this paper, we make a number of contributions, ultimately establishing that the weight-one dilated entropy (DilEnt) distance-generating function is optimal up to logarithmic factors. The DilEnt regularizer is notable due to its iterate-equivalence with Kernelized OMWU (KOMWU) -- the algorithm with state-of-the-art dependence on the game tree size in extensive-form games -- when used in conjunction with the online mirror descent (OMD) algorithm. However, the standard analysis for OMD is unable to establish such a result; the only current analysis is by appealing to the iterate equivalence to KOMWU. We close this gap by introducing a pair of primal-dual treeplex norms, which we contend form the natural analytic viewpoint for studying the strong convexity of DilEnt. Using these norm pairs, we recover the diameter-to-strong-convexity ratio that predicts the same performance as KOMWU. Along with a new regret lower bound for online learning in sequence-form strategy spaces, we show that this ratio is nearly optimal. Finally, we showcase our analytic techniques by refining the analysis of Clairvoyant OMD when paired with DilEnt, establishing an $\mathcal{O}(n \log |\mathcal{V}| \log T/T)$ approximation rate to coarse correlated equilibrium in $n$-player games, where $|\mathcal{V}|$ is the number of reduced normal-form strategies of the players, establishing the new state of the art.
Fast Last-Iterate Convergence of Learning in Games Requires Forgetful Algorithms
Jun 15, 2024



Self-play via online learning is one of the premier ways to solve large-scale two-player zero-sum games, both in theory and practice. Particularly popular algorithms include optimistic multiplicative weights update (OMWU) and optimistic gradient-descent-ascent (OGDA). While both algorithms enjoy $O(1/T)$ ergodic convergence to Nash equilibrium in two-player zero-sum games, OMWU offers several advantages including logarithmic dependence on the size of the payoff matrix and $\widetilde{O}(1/T)$ convergence to coarse correlated equilibria even in general-sum games. However, in terms of last-iterate convergence in two-player zero-sum games, an increasingly popular topic in this area, OGDA guarantees that the duality gap shrinks at a rate of $O(1/\sqrt{T})$, while the best existing last-iterate convergence for OMWU depends on some game-dependent constant that could be arbitrarily large. This begs the question: is this potentially slow last-iterate convergence an inherent disadvantage of OMWU, or is the current analysis too loose? Somewhat surprisingly, we show that the former is true. More generally, we prove that a broad class of algorithms that do not forget the past quickly all suffer the same issue: for any arbitrarily small $\delta>0$, there exists a $2\times 2$ matrix game such that the algorithm admits a constant duality gap even after $1/\delta$ rounds. This class of algorithms includes OMWU and other standard optimistic follow-the-regularized-leader algorithms.
Last-Iterate Convergence Properties of Regret-Matching Algorithms in Games
Nov 01, 2023Algorithms based on regret matching, specifically regret matching$^+$ (RM$^+$), and its variants are the most popular approaches for solving large-scale two-player zero-sum games in practice. Unlike algorithms such as optimistic gradient descent ascent, which have strong last-iterate and ergodic convergence properties for zero-sum games, virtually nothing is known about the last-iterate properties of regret-matching algorithms. Given the importance of last-iterate convergence for numerical optimization reasons and relevance as modeling real-word learning in games, in this paper, we study the last-iterate convergence properties of various popular variants of RM$^+$. First, we show numerically that several practical variants such as simultaneous RM$^+$, alternating RM$^+$, and simultaneous predictive RM$^+$, all lack last-iterate convergence guarantees even on a simple $3\times 3$ game. We then prove that recent variants of these algorithms based on a smoothing technique do enjoy last-iterate convergence: we prove that extragradient RM$^{+}$ and smooth Predictive RM$^+$ enjoy asymptotic last-iterate convergence (without a rate) and $1/\sqrt{t}$ best-iterate convergence. Finally, we introduce restarted variants of these algorithms, and show that they enjoy linear-rate last-iterate convergence.
Regret Matching+: (In)Stability and Fast Convergence in Games
May 24, 2023Regret Matching+ (RM+) and its variants are important algorithms for solving large-scale games. However, a theoretical understanding of their success in practice is still a mystery. Moreover, recent advances on fast convergence in games are limited to no-regret algorithms such as online mirror descent, which satisfy stability. In this paper, we first give counterexamples showing that RM+ and its predictive version can be unstable, which might cause other players to suffer large regret. We then provide two fixes: restarting and chopping off the positive orthant that RM+ works in. We show that these fixes are sufficient to get $O(T^{1/4})$ individual regret and $O(1)$ social regret in normal-form games via RM+ with predictions. We also apply our stabilizing techniques to clairvoyant updates in the uncoupled learning setting for RM+ and prove desirable results akin to recent works for Clairvoyant online mirror descent. Our experiments show the advantages of our algorithms over vanilla RM+-based algorithms in matrix and extensive-form games.
Online Bidding in Repeated Non-Truthful Auctions under Budget and ROI Constraints
Feb 02, 2023Online advertising platforms typically use auction mechanisms to allocate ad placements. Advertisers participate in a series of repeated auctions, and must select bids that will maximize their overall rewards while adhering to certain constraints. We focus on the scenario in which the advertiser has budget and return-on-investment (ROI) constraints. We investigate the problem of budget- and ROI-constrained bidding in repeated non-truthful auctions, such as first-price auctions, and present a best-of-both-worlds framework with no-regret guarantees under both stochastic and adversarial inputs. By utilizing the notion of interval regret, we demonstrate that our framework does not require knowledge of specific parameters of the problem which could be difficult to determine in practice. Our proof techniques can be applied to both the adversarial and stochastic cases with minimal modifications, thereby providing a unified perspective on the two problems. In the adversarial setting, we also show that it is possible to loosen the traditional requirement of having a strictly feasible solution to the offline optimization problem at each round.
Optimal Efficiency-Envy Trade-Off via Optimal Transport
Sep 25, 2022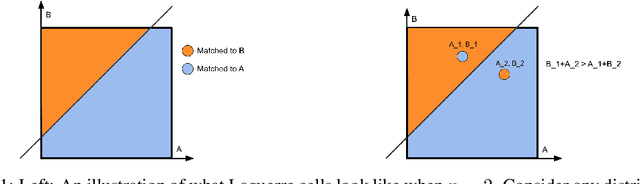
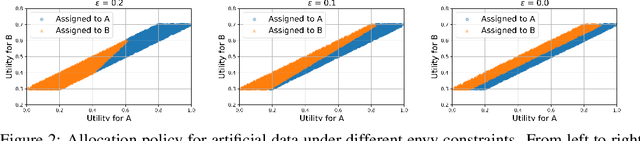
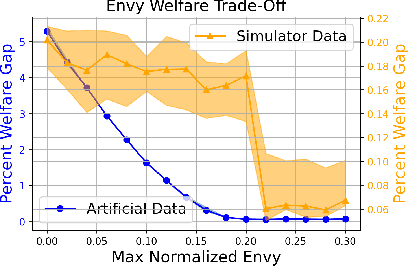
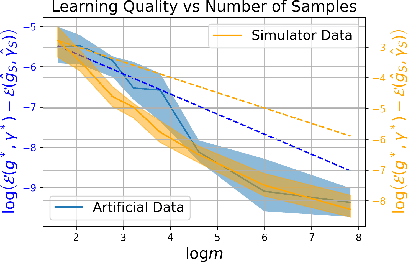
We consider the problem of allocating a distribution of items to $n$ recipients where each recipient has to be allocated a fixed, prespecified fraction of all items, while ensuring that each recipient does not experience too much envy. We show that this problem can be formulated as a variant of the semi-discrete optimal transport (OT) problem, whose solution structure in this case has a concise representation and a simple geometric interpretation. Unlike existing literature that treats envy-freeness as a hard constraint, our formulation allows us to \emph{optimally} trade off efficiency and envy continuously. Additionally, we study the statistical properties of the space of our OT based allocation policies by showing a polynomial bound on the number of samples needed to approximate the optimal solution from samples. Our approach is suitable for large-scale fair allocation problems such as the blood donation matching problem, and we show numerically that it performs well on a prior realistic data simulator.