 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image deblurring based on lightweight multi-information fusion network
Jan 14, 2021
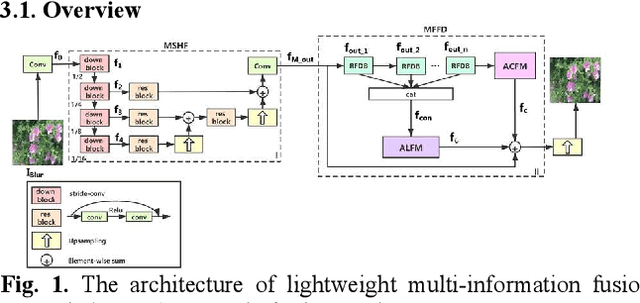
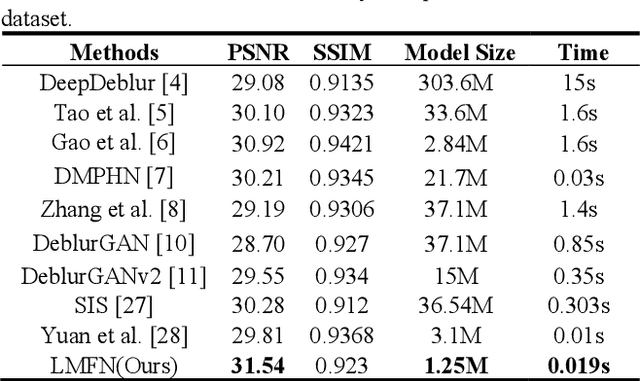
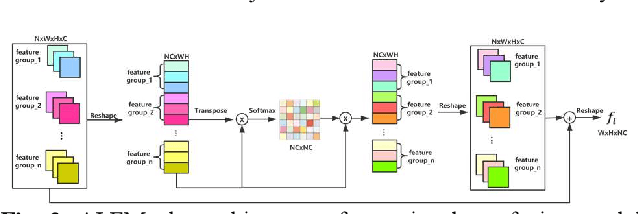

Recently, deep learning based image deblurring has been well developed. However, exploiting the detailed image features in a deep learning framework always requires a mass of parameters, which inevitably makes the network suffer from high computational burden. To solve this problem, we propose a lightweight multiinformation fusion network (LMFN) for image deblurring. The proposed LMFN is designed as an encoder-decoder architecture. In the encoding stage, the image feature is reduced to various smallscale spaces for multi-scale information extraction and fusion without a large amount of information loss. Then, a distillation network is used in the decoding stage, which allows the network benefit the most from residual learning while remaining sufficiently lightweight. Meanwhile, an information fusion strategy between distillation modules and feature channels is also carried out by attention mechanism. Through fusing different information in the proposed approach, our network can achieve state-of-the-art image deblurring result with smaller number of parameters and outperforms existing methods in model complexity.
Neural Program Synthesis with Query
May 08, 2022

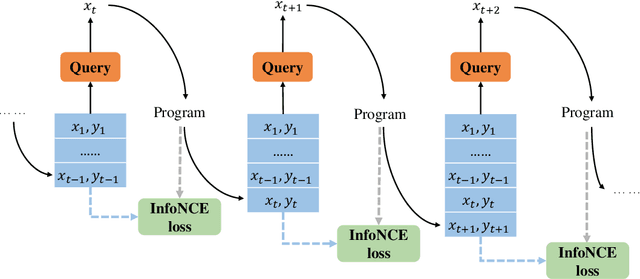

Aiming to find a program satisfying the user intent given input-output examples, program synthesis has attracted increasing interest in the area of machine learning. Despite the promising performance of existing methods, most of their success comes from the privileged information of well-designed input-output examples. However, providing such input-output examples is unrealistic because it requires the users to have the ability to describe the underlying program with a few input-output examples under the training distribution. In this work, we propose a query-based framework that trains a query neural network to generate informative input-output examples automatically and interactively from a large query space. The quality of the query depends on the amount of the mutual information between the query and the corresponding program, which can guide the optimization of the query framework. To estimate the mutual information more accurately, we introduce the functional space (F-space) which models the relevance between the input-output examples and the programs in a differentiable way. We evaluate the effectiveness and generalization of the proposed query-based framework on the Karel task and the list processing task. Experimental results show that the query-based framework can generate informative input-output examples which achieve and even outperform well-designed input-output examples.
Structural Information Preserving for Graph-to-Text Generation
Feb 12, 2021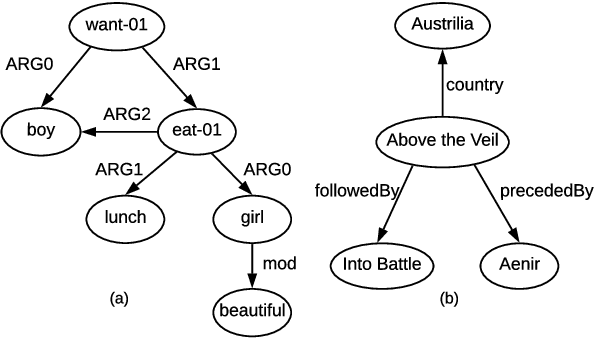
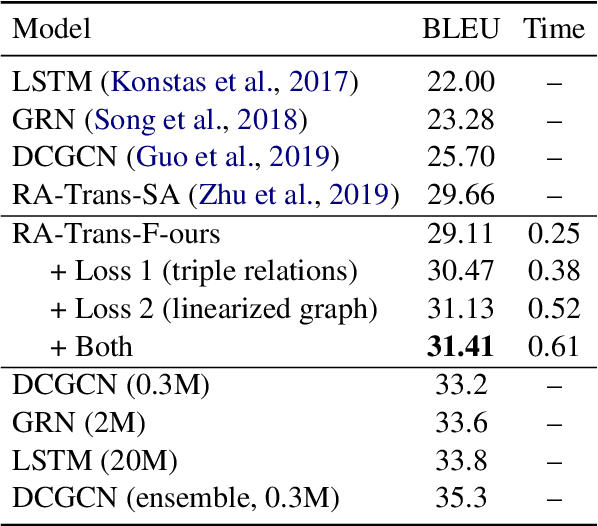
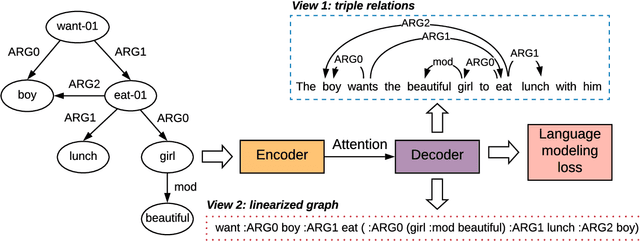

The task of graph-to-text generation aims at producing sentences that preserve the meaning of input graphs. As a crucial defect, the current state-of-the-art models may mess up or even drop the core structural information of input graphs when generating outputs. We propose to tackle this problem by leveraging richer training signals that can guide our model for preserving input information. In particular, we introduce two types of autoencoding losses, each individually focusing on different aspects (a.k.a. views) of input graphs. The losses are then back-propagated to better calibrate our model via multi-task training. Experiments on two benchmarks for graph-to-text generation show the effectiveness of our approach over a state-of-the-art baseline. Our code is available at \url{http://github.com/Soistesimmer/AMR-multiview}.
Local Sample-weighted Multiple Kernel Clustering with Consensus Discriminative Graph
Jul 05, 2022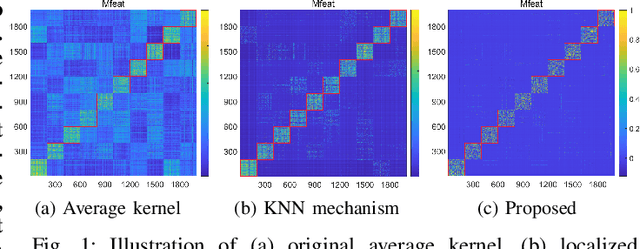
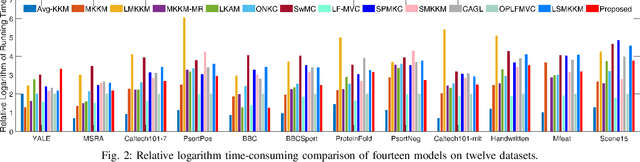
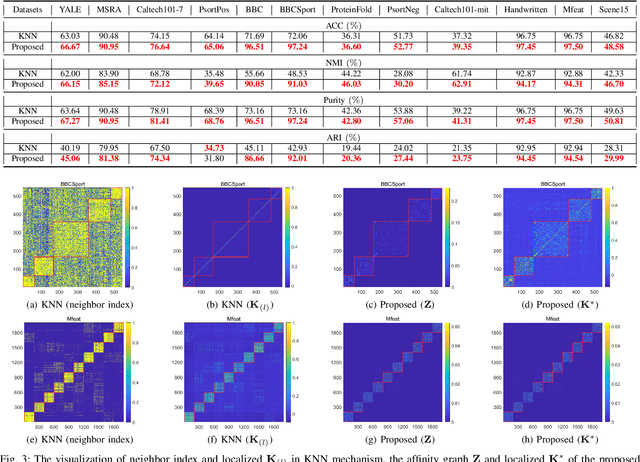
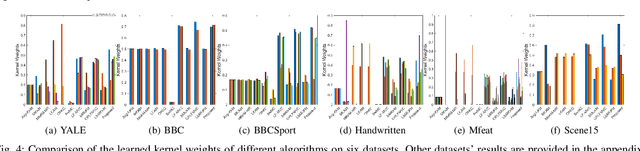
Multiple kernel clustering (MKC) is committed to achieving optimal information fusion from a set of base kernels. Constructing precise and local kernel matrices is proved to be of vital significance in applications since the unreliable distant-distance similarity estimation would degrade clustering per-formance. Although existing localized MKC algorithms exhibit improved performance compared to globally-designed competi-tors, most of them widely adopt KNN mechanism to localize kernel matrix by accounting for {\tau} -nearest neighbors. However, such a coarse manner follows an unreasonable strategy that the ranking importance of different neighbors is equal, which is impractical in applications. To alleviate such problems, this paper proposes a novel local sample-weighted multiple kernel clustering (LSWMKC) model. We first construct a consensus discriminative affinity graph in kernel space, revealing the latent local structures. Further, an optimal neighborhood kernel for the learned affinity graph is output with naturally sparse property and clear block diagonal structure. Moreover, LSWMKC im-plicitly optimizes adaptive weights on different neighbors with corresponding samples. Experimental results demonstrate that our LSWMKC possesses better local manifold representation and outperforms existing kernel or graph-based clustering algo-rithms. The source code of LSWMKC can be publicly accessed from https://github.com/liliangnudt/LSWMKC.
Machine Learning Based Cyber Attacks Targeting on Controlled Information: A Survey
Feb 16, 2021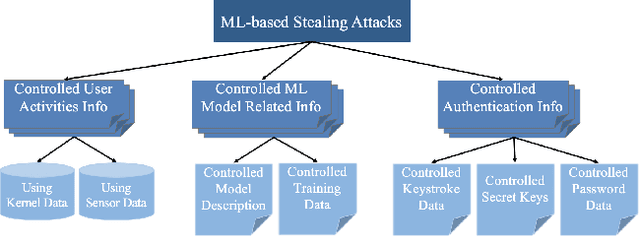

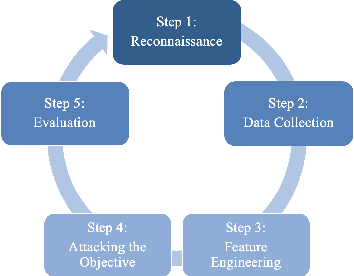
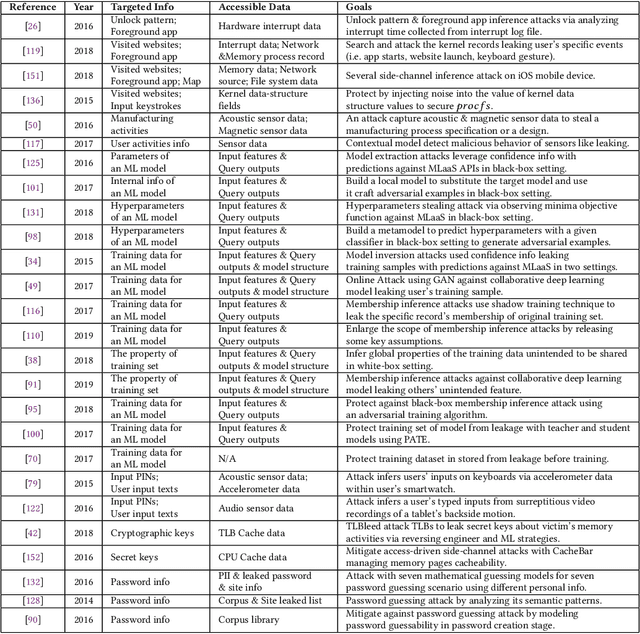
Stealing attack against controlled information, along with the increasing number of information leakage incidents, has become an emerging cyber security threat in recent years. Due to the booming development and deployment of advanced analytics solutions, novel stealing attacks utilize machine learning (ML) algorithms to achieve high success rate and cause a lot of damage. Detecting and defending against such attacks is challenging and urgent so that governments, organizations, and individuals should attach great importance to the ML-based stealing attacks. This survey presents the recent advances in this new type of attack and corresponding countermeasures. The ML-based stealing attack is reviewed in perspectives of three categories of targeted controlled information, including controlled user activities, controlled ML model-related information, and controlled authentication information. Recent publications are summarized to generalize an overarching attack methodology and to derive the limitations and future directions of ML-based stealing attacks. Furthermore, countermeasures are proposed towards developing effective protections from three aspects -- detection, disruption, and isolation.
PixelGame: Infrared small target segmentation as a Nash equilibrium
May 26, 2022
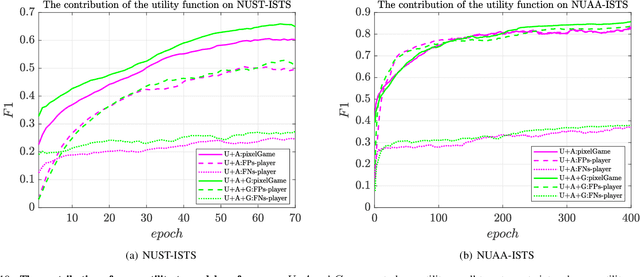


A key challenge of infrared small target segmentation (ISTS) is to balance false negative pixels (FNs) and false positive pixels (FPs). Traditional methods combine FNs and FPs into a single objective by weighted sum, and the optimization process is decided by one actor. Minimizing FNs and FPs with the same strategy leads to antagonistic decisions. To address this problem, we propose a competitive game framework (pixelGame) from a novel perspective for ISTS. In pixelGame, FNs and FPs are controlled by different player whose goal is to minimize their own utility function. FNs-player and FPs-player are designed with different strategies: One is to minimize FNs and the other is to minimize FPs. The utility function drives the evolution of the two participants in competition. We consider the Nash equilibrium of pixelGame as the optimal solution. In addition, we propose maximum information modulation (MIM) to highlight the tar-get information. MIM effectively focuses on the salient region including small targets. Extensive experiments on two standard public datasets prove the effectiveness of our method. Compared with other state-of-the-art methods, our method achieves better performance in terms of F1-measure (F1) and the intersection of union (IoU).
Stability of Aggregation Graph Neural Networks
Jul 08, 2022In this paper we study the stability properties of aggregation graph neural networks (Agg-GNNs) considering perturbations of the underlying graph. An Agg-GNN is a hybrid architecture where information is defined on the nodes of a graph, but it is processed block-wise by Euclidean CNNs on the nodes after several diffusions on the graph shift operator. We derive stability bounds for the mapping operator associated to a generic Agg-GNN, and we specify conditions under which such operators can be stable to deformations. We prove that the stability bounds are defined by the properties of the filters in the first layer of the CNN that acts on each node. Additionally, we show that there is a close relationship between the number of aggregations, the filter's selectivity, and the size of the stability constants. We also conclude that in Agg-GNNs the selectivity of the mapping operators is tied to the properties of the filters only in the first layer of the CNN stage. This shows a substantial difference with respect to the stability properties of selection GNNs, where the selectivity of the filters in all layers is constrained by their stability. We provide numerical evidence corroborating the results derived, testing the behavior of Agg-GNNs in real life application scenarios considering perturbations of different magnitude.
CSI-Based Localization with CNNs Exploiting Phase Information
Jan 22, 2021
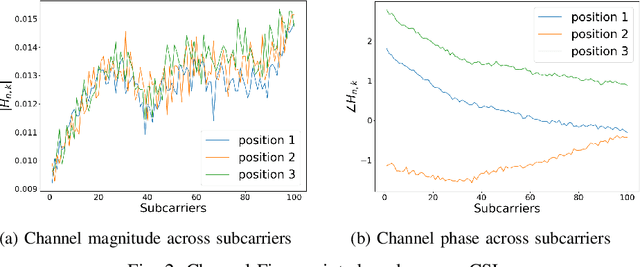
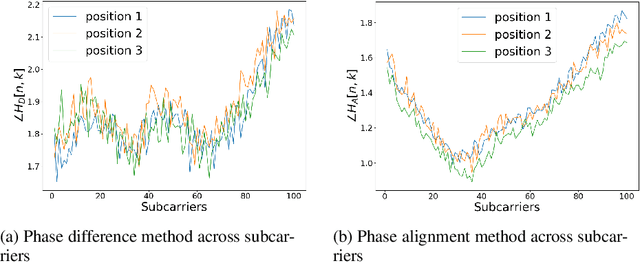
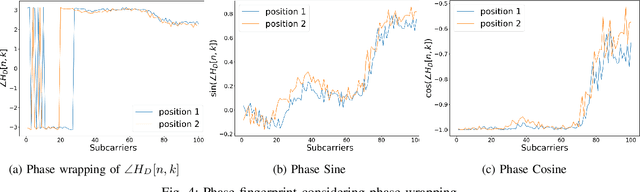
In this paper we study the use of the Channel State Information (CSI) as fingerprint inputs of a Convolutional Neural Network (CNN) for localization. We examine whether the CSI can be used as a distinct fingerprint corresponding to a single position by considering the inconsistencies with its raw phase that cause the CSI to be unreliable. We propose two methods to produce reliable fingerprints including the phase information. Furthermore, we examine the structure of the CNN and more specifically the impact of pooling on the positioning performance, and show that pooling over the subcarriers can be more beneficial than over the antennas.
Positive-Negative Equal Contrastive Loss for Semantic Segmentation
Jul 05, 2022
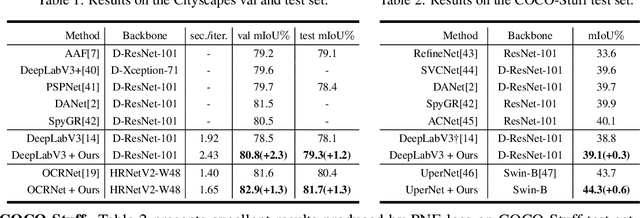
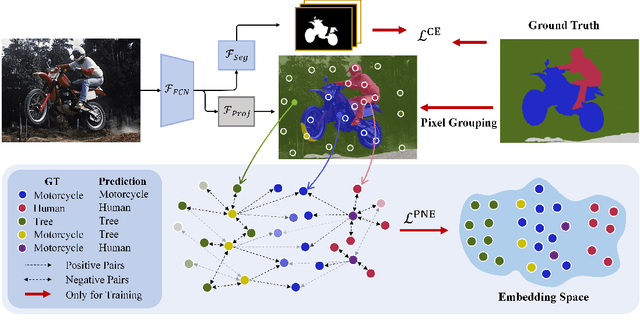
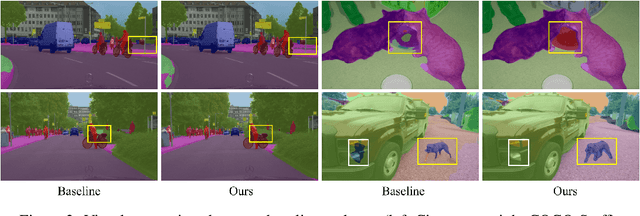
The contextual information is critical for various computer vision tasks, previous works commonly design plug-and-play modules and structural losses to effectively extract and aggregate the global context. These methods utilize fine-label to optimize the model but ignore that fine-trained features are also precious training resources, which can introduce preferable distribution to hard pixels (i.e., misclassified pixels). Inspired by contrastive learning in unsupervised paradigm, we apply the contrastive loss in a supervised manner and re-design the loss function to cast off the stereotype of unsupervised learning (e.g., imbalance of positives and negatives, confusion of anchors computing). To this end, we propose Positive-Negative Equal contrastive loss (PNE loss), which increases the latent impact of positive embedding on the anchor and treats the positive as well as negative sample pairs equally. The PNE loss can be directly plugged right into existing semantic segmentation frameworks and leads to excellent performance with neglectable extra computational costs. We utilize a number of classic segmentation methods (e.g., DeepLabV3, OCRNet, UperNet) and backbone (e.g., ResNet, HRNet, Swin Transformer) to conduct comprehensive experiments and achieve state-of-the-art performance on two benchmark datasets (e.g., Cityscapes and COCO-Stuff). Our code will be publicly available soon.
Video Dialog as Conversation about Objects Living in Space-Time
Jul 08, 2022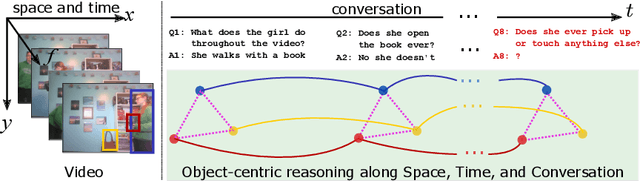

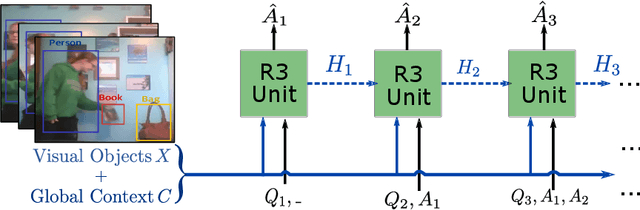
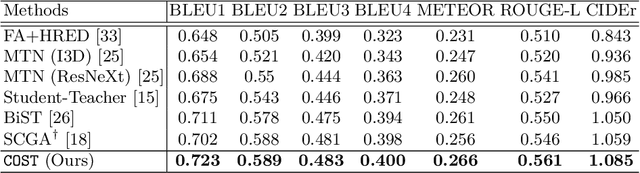
It would be a technological feat to be able to create a system that can hold a meaningful conversation with humans about what they watch. A setup toward that goal is presented as a video dialog task, where the system is asked to generate natural utterances in response to a question in an ongoing dialog. The task poses great visual, linguistic, and reasoning challenges that cannot be easily overcome without an appropriate representation scheme over video and dialog that supports high-level reasoning. To tackle these challenges we present a new object-centric framework for video dialog that supports neural reasoning dubbed COST - which stands for Conversation about Objects in Space-Time. Here dynamic space-time visual content in videos is first parsed into object trajectories. Given this video abstraction, COST maintains and tracks object-associated dialog states, which are updated upon receiving new questions. Object interactions are dynamically and conditionally inferred for each question, and these serve as the basis for relational reasoning among them. COST also maintains a history of previous answers, and this allows retrieval of relevant object-centric information to enrich the answer forming process. Language production then proceeds in a step-wise manner, taking into the context of the current utterance, the existing dialog, the current question. We evaluate COST on the DSTC7 and DSTC8 benchmarks, demonstrating its competitiveness against state-of-the-arts.