 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPPA: Automated Circuit PPA Optimization via Contrastive Code-based Rule Library Learning
Apr 20, 2026Performance, power, and area (PPA) optimization is a fundamental task in RTL design, requiring a precise understanding of circuit functionality and the relationship between circuit structures and PPA metrics. Recent studies attempt to automate this process using LLMs, but neither feedback-based nor knowledge-based methods are efficient enough, as they either design without any prior knowledge or rely heavily on human-summarized optimization rules. In this paper, we propose AutoPPA, a fully automated PPA optimization framework. The key idea is to automatically generate optimization rules that enhance the search for optimal solutions. To do this, AutoPPA employs an Explore-Evaluate-Induce ($E^2I$) workflow that contrasts and abstracts rules from diverse generated code pairs rather than manually defined prior knowledge, yielding better optimization patterns. To make the abstracted rules more generalizable, AutoPPA employs an adaptive multi-step search framework that adopts the most effective rules for a given circuit. Experiments show that AutoPPA outperforms both the manual optimization and the state-of-the-art methods SymRTLO and RTLRewriter.
QiMeng-CodeV-SVA: Training Specialized LLMs for Hardware Assertion Generation via RTL-Grounded Bidirectional Data Synthesis
Mar 15, 2026SystemVerilog Assertions (SVAs) are crucial for hardware verification. Recent studies leverage general-purpose LLMs to translate natural language properties to SVAs (NL2SVA), but they perform poorly due to limited data. We propose a data synthesis framework to tackle two challenges: the scarcity of high-quality real-world SVA corpora and the lack of reliable methods to determine NL-SVA semantic equivalence. For the former, large-scale open-source RTLs are used to guide LLMs to generate real-world SVAs; for the latter, bidirectional translation serves as a data selection method. With the synthesized data, we train CodeV-SVA, a series of SVA generation models. Notably, CodeV-SVA-14B achieves 75.8% on NL2SVA-Human and 84.0% on NL2SVA-Machine in Func.@1, matching or exceeding advanced LLMs like GPT-5 and DeepSeek-R1.
LocalV: Exploiting Information Locality for IP-level Verilog Generation
Jan 31, 2026The generation of Register-Transfer Level (RTL) code is a crucial yet labor-intensive step in digital hardware design, traditionally requiring engineers to manually translate complex specifications into thousands of lines of synthesizable Hardware Description Language (HDL) code. While Large Language Models (LLMs) have shown promise in automating this process, existing approaches-including fine-tuned domain-specific models and advanced agent-based systems-struggle to scale to industrial IP-level design tasks. We identify three key challenges: (1) handling long, highly detailed documents, where critical interface constraints become buried in unrelated submodule descriptions; (2) generating long RTL code, where both syntactic and semantic correctness degrade sharply with increasing output length; and (3) navigating the complex debugging cycles required for functional verification through simulation and waveform analysis. To overcome these challenges, we propose LocalV, a multi-agent framework that leverages information locality in modular hardware design. LocalV decomposes the long-document to long-code generation problem into a set of short-document, short-code tasks, enabling scalable generation and debugging. Specifically, LocalV integrates hierarchical document partitioning, task planning, localized code generation, interface-consistent merging, and AST-guided locality-aware debugging. Experiments on RealBench, an IP-level Verilog generation benchmark, demonstrate that LocalV substantially outperforms state-of-the-art (SOTA) LLMs and agents, achieving a pass rate of 45.0% compared to 21.6%.
QiMeng-SALV: Signal-Aware Learning for Verilog Code Generation
Oct 22, 2025The remarkable progress of Large Language Models (LLMs) presents promising opportunities for Verilog code generation which is significantly important for automated circuit design. The lacking of meaningful functional rewards hinders the preference optimization based on Reinforcement Learning (RL) for producing functionally correct Verilog code. In this paper, we propose Signal-Aware Learning for Verilog code generation (QiMeng-SALV) by leveraging code segments of functionally correct output signal to optimize RL training. Considering Verilog code specifies the structural interconnection of hardware gates and wires so that different output signals are independent, the key insight of QiMeng-SALV is to extract verified signal-aware implementations in partially incorrect modules, so as to enhance the extraction of meaningful functional rewards. Roughly, we verify the functional correctness of signals in generated module by comparing with that of reference module in the training data. Then abstract syntax tree (AST) is employed to identify signal-aware code segments which can provide meaningful functional rewards from erroneous modules. Finally, we introduce signal-aware DPO which is optimized on the correct signal-level code segments, thereby preventing noise and interference from incorrect signals. The proposed QiMeng-SALV underscores the paradigm shift from conventional module-level to fine-grained signal-level optimization in Verilog code generation, addressing the issue of insufficient functional rewards. Experiments demonstrate that our method achieves state-of-the-art performance on VerilogEval and RTLLM, with a 7B parameter model matching the performance of the DeepSeek v3 671B model and significantly outperforming the leading open-source model CodeV trained on the same dataset. Our code is available at https://github.com/zy1xxx/SALV.
QiMeng: Fully Automated Hardware and Software Design for Processor Chip
Jun 05, 2025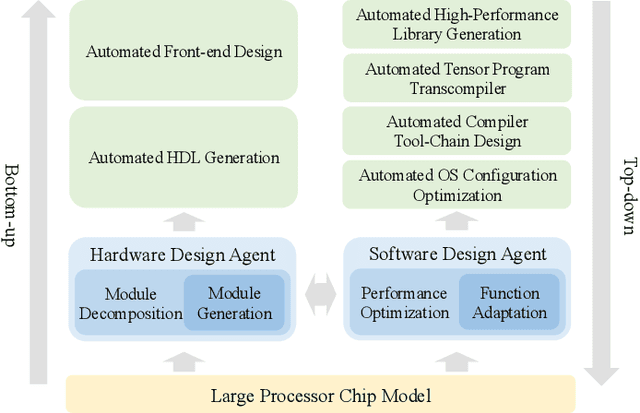
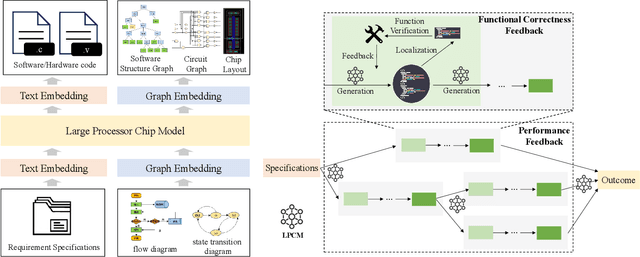
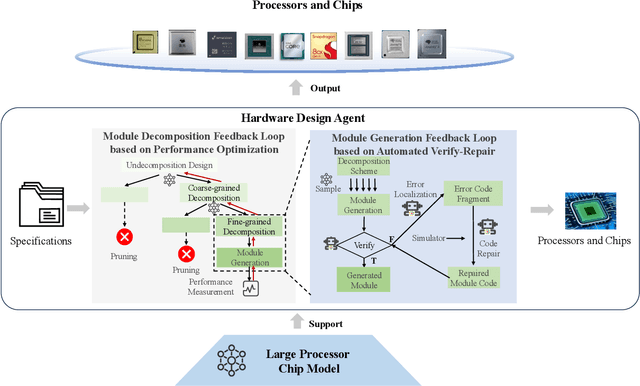
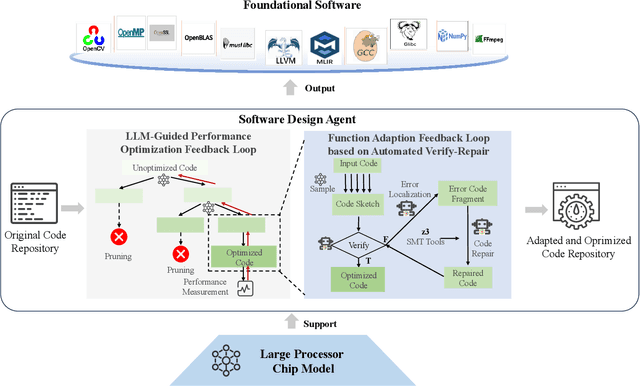
Processor chip design technology serves as a key frontier driving breakthroughs in computer science and related fields. With the rapid advancement of information technology, conventional design paradigms face three major challenges: the physical constraints of fabrication technologies, the escalating demands for design resources, and the increasing diversity of ecosystems. Automated processor chip design has emerged as a transformative solution to address these challenges. While recent breakthroughs in Artificial Intelligence (AI), particularly Large Language Models (LLMs) techniques, have opened new possibilities for fully automated processor chip design, substantial challenges remain in establishing domain-specific LLMs for processor chip design. In this paper, we propose QiMeng, a novel system for fully automated hardware and software design of processor chips. QiMeng comprises three hierarchical layers. In the bottom-layer, we construct a domain-specific Large Processor Chip Model (LPCM) that introduces novel designs in architecture, training, and inference, to address key challenges such as knowledge representation gap, data scarcity, correctness assurance, and enormous solution space. In the middle-layer, leveraging the LPCM's knowledge representation and inference capabilities, we develop the Hardware Design Agent and the Software Design Agent to automate the design of hardware and software for processor chips. Currently, several components of QiMeng have been completed and successfully applied in various top-layer applications, demonstrating significant advantages and providing a feasible solution for efficient, fully automated hardware/software design of processor chips. Future research will focus on integrating all components and performing iterative top-down and bottom-up design processes to establish a comprehensive QiMeng system.
CodeV-R1: Reasoning-Enhanced Verilog Generation
May 30, 2025Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while matching or even exceeding the performance of 671B DeepSeek-R1. We will release our model, training pipeline, and dataset to facilitate research in EDA and LLM communities.
CodeV: Empowering LLMs for Verilog Generation through Multi-Level Summarization
Jul 16, 2024The increasing complexity and high costs associated with modern processor design have led to a surge in demand for processor design automation. Instruction-tuned large language models (LLMs) have demonstrated remarkable performance in automatically generating code for general-purpose programming languages like Python. However, these methods fail on hardware description languages (HDLs) like Verilog due to the scarcity of high-quality instruction tuning data, as even advanced LLMs like GPT-3.5 exhibit limited performance on Verilog generation. Regarding this issue, we observe that (1) Verilog code collected from the real world has higher quality than those generated by LLMs. (2) LLMs like GPT-3.5 excel in summarizing Verilog code rather than generating it. Based on these observations, this paper introduces CodeV, a series of open-source instruction-tuned Verilog generation LLMs. Instead of generating descriptions first and then getting the corresponding code from advanced LLMs, we prompt the LLM with Verilog code and let the LLM generate the corresponding natural language description by multi-level summarization. Experimental results show that CodeV relatively surpasses the previous open-source SOTA by 14.4% (BetterV in VerilogEval) and 11.3% (RTLCoder in RTLLM) respectively, and also relatively outperforms previous commercial SOTA GPT-4 by 22.1% in VerilogEval.
TensorTEE: Unifying Heterogeneous TEE Granularity for Efficient Secure Collaborative Tensor Computing
Jul 12, 2024



Heterogeneous collaborative computing with NPU and CPU has received widespread attention due to its substantial performance benefits. To ensure data confidentiality and integrity during computing, Trusted Execution Environments (TEE) is considered a promising solution because of its comparatively lower overhead. However, existing heterogeneous TEE designs are inefficient for collaborative computing due to fine and different memory granularities between CPU and NPU. 1) The cacheline granularity of CPU TEE intensifies memory pressure due to its extra memory access, and 2) the cacheline granularity MAC of NPU escalates the pressure on the limited memory storage. 3) Data transfer across heterogeneous enclaves relies on the transit of non-secure regions, resulting in cumbersome re-encryption and scheduling. To address these issues, we propose TensorTEE, a unified tensor-granularity heterogeneous TEE for efficient secure collaborative tensor computing. First, we virtually support tensor granularity in CPU TEE to eliminate the off-chip metadata access by detecting and maintaining tensor structures on-chip. Second, we propose tensor-granularity MAC management with predictive execution to avoid computational stalls while eliminating off-chip MAC storage and access. Moreover, based on the unified granularity, we enable direct data transfer without re-encryption and scheduling dilemmas. Our evaluation is built on enhanced Gem5 and a cycle-accurate NPU simulator. The results show that TensorTEE improves the performance of Large Language Model (LLM) training workloads by 4.0x compared to existing work and incurs only 2.1% overhead compared to non-secure training, offering a practical security assurance for LLM training.
Pushing the Limits of Machine Design: Automated CPU Design with AI
Jun 27, 2023



Design activity -- constructing an artifact description satisfying given goals and constraints -- distinguishes humanity from other animals and traditional machines, and endowing machines with design abilities at the human level or beyond has been a long-term pursuit. Though machines have already demonstrated their abilities in designing new materials, proteins, and computer programs with advanced artificial intelligence (AI) techniques, the search space for designing such objects is relatively small, and thus, "Can machines design like humans?" remains an open question. To explore the boundary of machine design, here we present a new AI approach to automatically design a central processing unit (CPU), the brain of a computer, and one of the world's most intricate devices humanity have ever designed. This approach generates the circuit logic, which is represented by a graph structure called Binary Speculation Diagram (BSD), of the CPU design from only external input-output observations instead of formal program code. During the generation of BSD, Monte Carlo-based expansion and the distance of Boolean functions are used to guarantee accuracy and efficiency, respectively. By efficiently exploring a search space of unprecedented size 10^{10^{540}}, which is the largest one of all machine-designed objects to our best knowledge, and thus pushing the limits of machine design, our approach generates an industrial-scale RISC-V CPU within only 5 hours. The taped-out CPU successfully runs the Linux operating system and performs comparably against the human-designed Intel 80486SX CPU. In addition to learning the world's first CPU only from input-output observations, which may reform the semiconductor industry by significantly reducing the design cycle, our approach even autonomously discovers human knowledge of the von Neumann architecture.
ANPL: Compiling Natural Programs with Interactive Decomposition
May 29, 2023



The advents of Large Language Models (LLMs) have shown promise in augmenting programming using natural interactions. However, while LLMs are proficient in compiling common usage patterns into a programming language, e.g., Python, it remains a challenge how to edit and debug an LLM-generated program. We introduce ANPL, a programming system that allows users to decompose user-specific tasks. In an ANPL program, a user can directly manipulate sketch, which specifies the data flow of the generated program. The user annotates the modules, or hole with natural language descriptions offloading the expensive task of generating functionalities to the LLM. Given an ANPL program, the ANPL compiler generates a cohesive Python program that implements the functionalities in hole, while respecting the dataflows specified in sketch. We deploy ANPL on the Abstraction and Reasoning Corpus (ARC), a set of unique tasks that are challenging for state-of-the-art AI systems, showing it outperforms baseline programming systems that (a) without the ability to decompose tasks interactively and (b) without the guarantee that the modules can be correctly composed together. We obtain a dataset consisting of 300/400 ARC tasks that were successfully decomposed and grounded in Python, providing valuable insights into how humans decompose programmatic tasks. See the dataset at https://iprc-dip.github.io/DARC.