 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hypertext Entity Extraction in Webpage
Mar 04, 2024
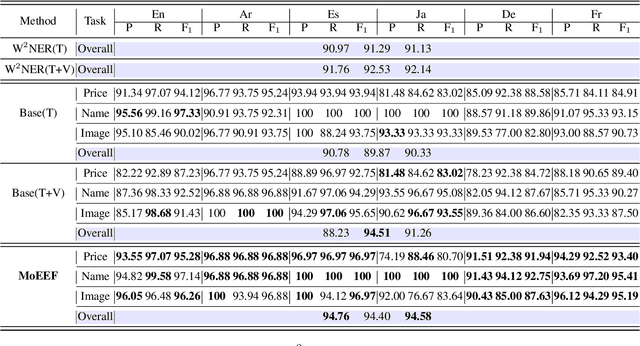
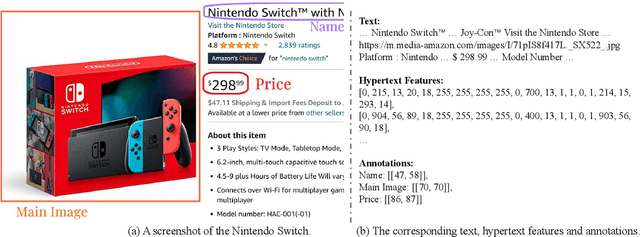

Webpage entity extraction is a fundamental natural language processing task in both research and applications. Nowadays, the majority of webpage entity extraction models are trained on structured datasets which strive to retain textual content and its structure information. However, existing datasets all overlook the rich hypertext features (e.g., font color, font size) which show their effectiveness in previous works. To this end, we first collect a \textbf{H}ypertext \textbf{E}ntity \textbf{E}xtraction \textbf{D}ataset (\textit{HEED}) from the e-commerce domains, scraping both the text and the corresponding explicit hypertext features with high-quality manual entity annotations. Furthermore, we present the \textbf{Mo}E-based \textbf{E}ntity \textbf{E}xtraction \textbf{F}ramework (\textit{MoEEF}), which efficiently integrates multiple features to enhance model performance by Mixture of Experts and outperforms strong baselines, including the state-of-the-art small-scale models and GPT-3.5-turbo. Moreover, the effectiveness of hypertext features in \textit{HEED} and several model components in \textit{MoEEF} are analyzed.
FENICE: Factuality Evaluation of summarization based on Natural language Inference and Claim Extraction
Mar 04, 2024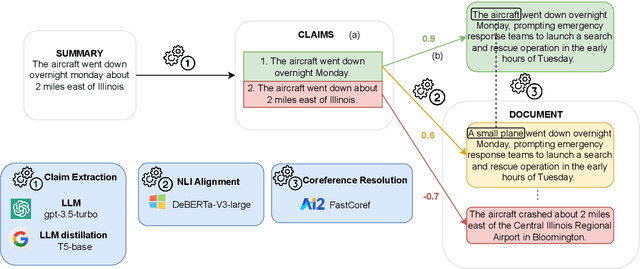
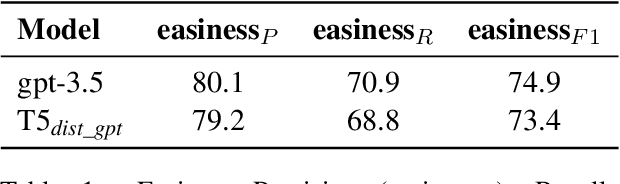
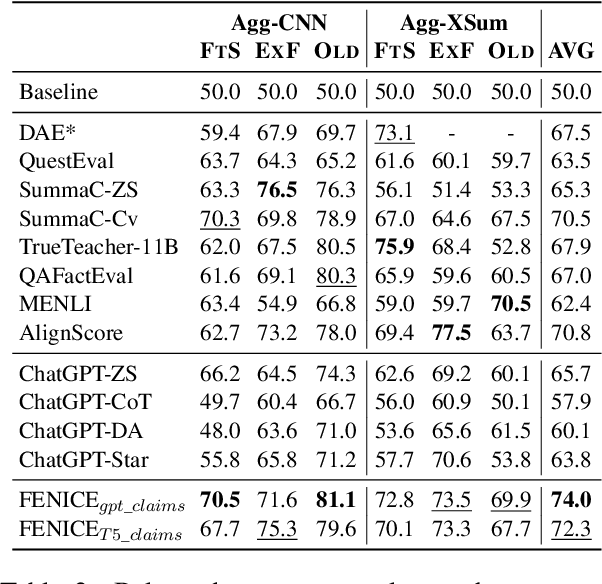

Recent advancements in text summarization, particularly with the advent of Large Language Models (LLMs), have shown remarkable performance. However, a notable challenge persists as a substantial number of automatically-generated summaries exhibit factual inconsistencies, such as hallucinations. In response to this issue, various approaches for the evaluation of consistency for summarization have emerged. Yet, these newly-introduced metrics face several limitations, including lack of interpretability, focus on short document summaries (e.g., news articles), and computational impracticality, especially for LLM-based metrics. To address these shortcomings, we propose Factuality Evaluation of summarization based on Natural language Inference and Claim Extraction (FENICE), a more interpretable and efficient factuality-oriented metric. FENICE leverages an NLI-based alignment between information in the source document and a set of atomic facts, referred to as claims, extracted from the summary. Our metric sets a new state of the art on AGGREFACT, the de-facto benchmark for factuality evaluation. Moreover, we extend our evaluation to a more challenging setting by conducting a human annotation process of long-form summarization.
Fast Benchmarking of Asynchronous Multi-Fidelity Optimization on Zero-Cost Benchmarks
Mar 04, 2024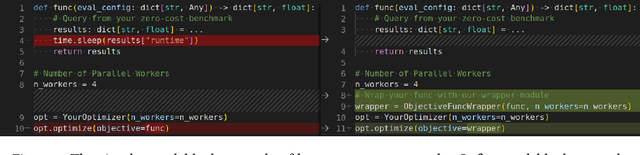

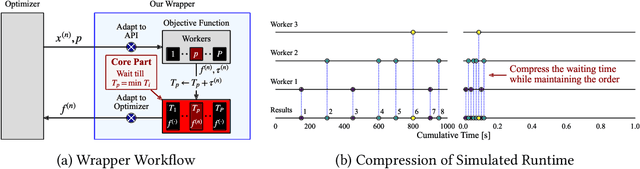

While deep learning has celebrated many successes, its results often hinge on the meticulous selection of hyperparameters (HPs). However, the time-consuming nature of deep learning training makes HP optimization (HPO) a costly endeavor, slowing down the development of efficient HPO tools. While zero-cost benchmarks, which provide performance and runtime without actual training, offer a solution for non-parallel setups, they fall short in parallel setups as each worker must communicate its queried runtime to return its evaluation in the exact order. This work addresses this challenge by introducing a user-friendly Python package that facilitates efficient parallel HPO with zero-cost benchmarks. Our approach calculates the exact return order based on the information stored in file system, eliminating the need for long waiting times and enabling much faster HPO evaluations. We first verify the correctness of our approach through extensive testing and the experiments with 6 popular HPO libraries show its applicability to diverse libraries and its ability to achieve over 1000x speedup compared to a traditional approach. Our package can be installed via pip install mfhpo-simulator.
Machine and deep learning methods for predicting 3D genome organization
Mar 04, 2024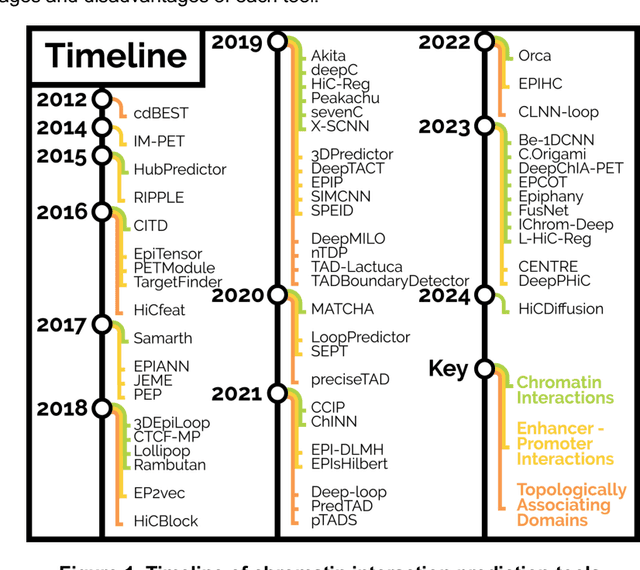
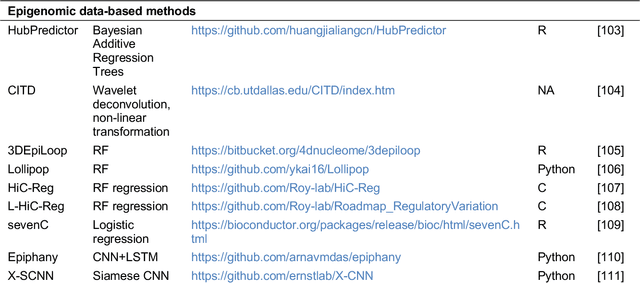

Three-Dimensional (3D) chromatin interactions, such as enhancer-promoter interactions (EPIs), loops, Topologically Associating Domains (TADs), and A/B compartments play critical roles in a wide range of cellular processes by regulating gene expression. Recent development of chromatin conformation capture technologies has enabled genome-wide profiling of various 3D structures, even with single cells. However, current catalogs of 3D structures remain incomplete and unreliable due to differences in technology, tools, and low data resolution. Machine learning methods have emerged as an alternative to obtain missing 3D interactions and/or improve resolution. Such methods frequently use genome annotation data (ChIP-seq, DNAse-seq, etc.), DNA sequencing information (k-mers, Transcription Factor Binding Site (TFBS) motifs), and other genomic properties to learn the associations between genomic features and chromatin interactions. In this review, we discuss computational tools for predicting three types of 3D interactions (EPIs, chromatin interactions, TAD boundaries) and analyze their pros and cons. We also point out obstacles of computational prediction of 3D interactions and suggest future research directions.
What Text Design Characterizes Book Genres?
Feb 26, 2024This study analyzes the relationship between non-verbal information (e.g., genres) and text design (e.g., font style, character color, etc.) through the classification of book genres using text design on book covers. Text images have both semantic information about the word itself and other information (non-semantic information or visual design), such as font style, character color, etc. When we read a word printed on some materials, we receive impressions or other information from both the word itself and the visual design. Basically, we can understand verbal information only from semantic information, i.e., the words themselves; however, we can consider that text design is helpful for understanding other additional information (i.e., non-verbal information), such as impressions, genre, etc. To investigate the effect of text design, we analyze text design using words printed on book covers and their genres in two scenarios. First, we attempted to understand the importance of visual design for determining the genre (i.e., non-verbal information) of books by analyzing the differences in the relationship between semantic information/visual design and genres. In the experiment, we found that semantic information is sufficient to determine the genre; however, text design is helpful in adding more discriminative features for book genres. Second, we investigated the effect of each text design on book genres. As a result, we found that each text design characterizes some book genres. For example, font style is useful to add more discriminative features for genres of ``Mystery, Thriller \& Suspense'' and ``Christian books \& Bibles.''
Information That Matters: Exploring Information Needs of People Affected by Algorithmic Decisions
Jan 29, 2024Explanations of AI systems rarely address the information needs of people affected by algorithmic decision-making (ADM). This gap between conveyed information and information that matters to affected stakeholders can impede understanding and adherence to regulatory frameworks such as the AI Act. To address this gap, we present the "XAI Novice Question Bank": A catalog of affected stakeholders' information needs in two ADM use cases (employment prediction and health monitoring), covering the categories data, system context, system usage, and system specifications. Information needs were gathered in an interview study where participants received explanations in response to their inquiries. Participants further reported their understanding and decision confidence, showing that while confidence tended to increase after receiving explanations, participants also met understanding challenges, such as being unable to tell why their understanding felt incomplete. Explanations further influenced participants' perceptions of the systems' risks and benefits, which they confirmed or changed depending on the use case. When risks were perceived as high, participants expressed particular interest in explanations about intention, such as why and to what end a system was put in place. With this work, we aim to support the inclusion of affected stakeholders into explainability by contributing an overview of information and challenges relevant to them when deciding on the adoption of ADM systems. We close by summarizing our findings in a list of six key implications that inform the design of future explanations for affected stakeholder audiences.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024
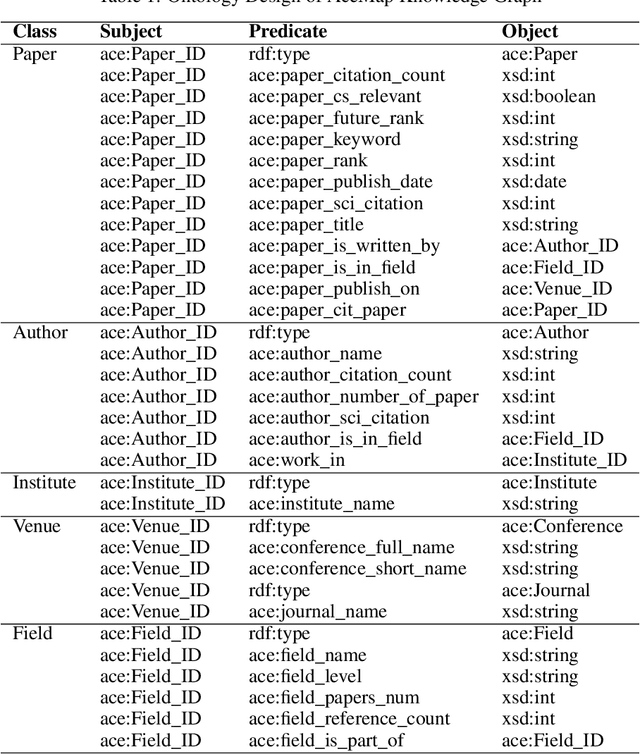
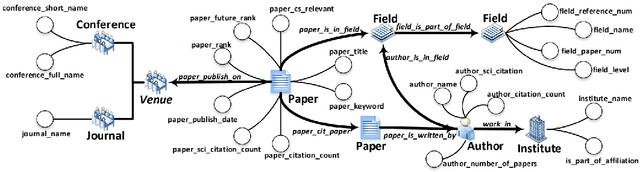
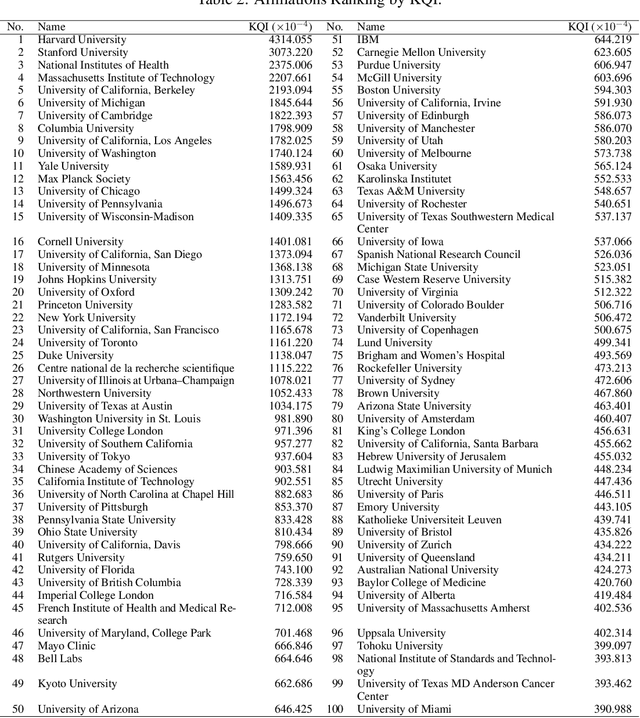
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
Multi-frequency tracking via group-sparse optimal transport
Feb 29, 2024In this work, we introduce an optimal transport framework for inferring power distributions over both spatial location and temporal frequency. Recently, it has been shown that optimal transport is a powerful tool for estimating spatial spectra that change smoothly over time. In this work, we consider the tracking of the spatio-temporal spectrum corresponding to a small number of moving broad-band signal sources. Typically, such tracking problems are addressed by treating the spatio-temporal power distribution in a frequency-by-frequency manner, allowing to use well-understood models for narrow-band signals. This however leads to decreased target resolution due to inefficient use of the available information. We propose an extension of the optimal transport framework that exploits information from several frequencies simultaneously by estimating a spatio-temporal distribution penalized by a group-sparsity regularizer. This approach finds a spatial spectrum that changes smoothly over time, and at each time instance has a small support that is similar across frequencies. To the best of the authors knowledge, this is the first formulation combining optimal transport and sparsity for solving inverse problems. As is shown on simulated and real data, our method can successfully track targets in scenarios where information from separate frequency bands alone is insufficient.
RORA: Robust Free-Text Rationale Evaluation
Mar 01, 2024Free-text rationales play a pivotal role in explainable NLP, bridging the knowledge and reasoning gaps behind a model's decision-making. However, due to the diversity of potential reasoning paths and a corresponding lack of definitive ground truth, their evaluation remains a challenge. Existing evaluation metrics rely on the degree to which a rationale supports a target label, but we find these fall short in evaluating rationales that inadvertently leak the labels. To address this problem, we propose RORA, a Robust free-text Rationale evaluation against label leakage. RORA quantifies the new information supplied by a rationale to justify the label. This is achieved by assessing the conditional V-information \citep{hewitt-etal-2021-conditional} with a predictive family robust against leaky features that can be exploited by a small model. RORA consistently outperforms existing approaches in evaluating human-written, synthetic, or model-generated rationales, particularly demonstrating robustness against label leakage. We also show that RORA aligns well with human judgment, providing a more reliable and accurate measurement across diverse free-text rationales.
Attribute Structuring Improves LLM-Based Evaluation of Clinical Text Summaries
Mar 01, 2024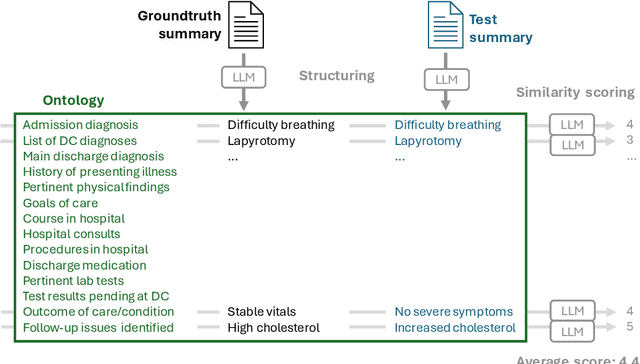
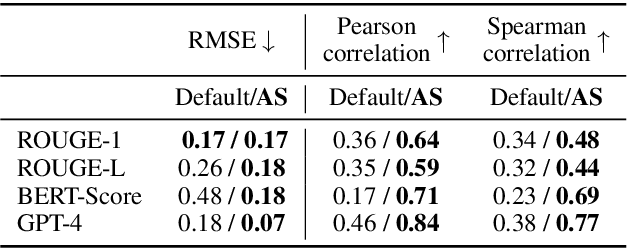
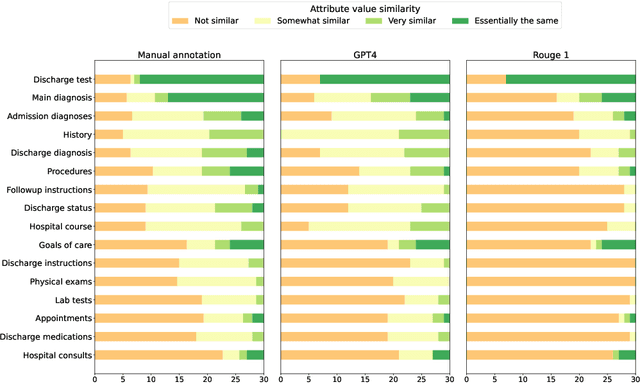
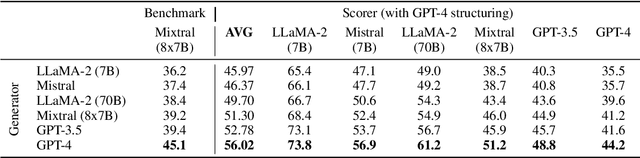
Summarizing clinical text is crucial in health decision-support and clinical research. Large language models (LLMs) have shown the potential to generate accurate clinical text summaries, but still struggle with issues regarding grounding and evaluation, especially in safety-critical domains such as health. Holistically evaluating text summaries is challenging because they may contain unsubstantiated information. Here, we explore a general mitigation framework using Attribute Structuring (AS), which structures the summary evaluation process. It decomposes the evaluation process into a grounded procedure that uses an LLM for relatively simple structuring and scoring tasks, rather than the full task of holistic summary evaluation. Experiments show that AS consistently improves the correspondence between human annotations and automated metrics in clinical text summarization. Additionally, AS yields interpretations in the form of a short text span corresponding to each output, which enables efficient human auditing, paving the way towards trustworthy evaluation of clinical information in resource-constrained scenarios. We release our code, prompts, and an open-source benchmark at https://github.com/microsoft/attribute-structuring.