 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Model2Detector: Widening the Information Bottleneck for Out-of-Distribution Detection using a Handful of Gradient Steps
Feb 22, 2022
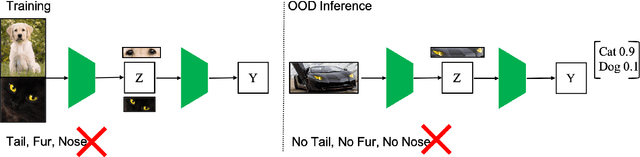
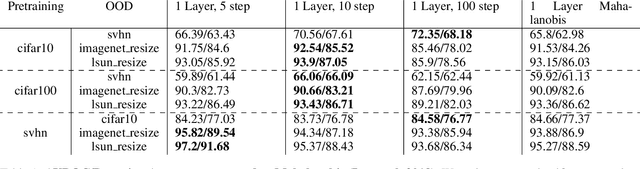
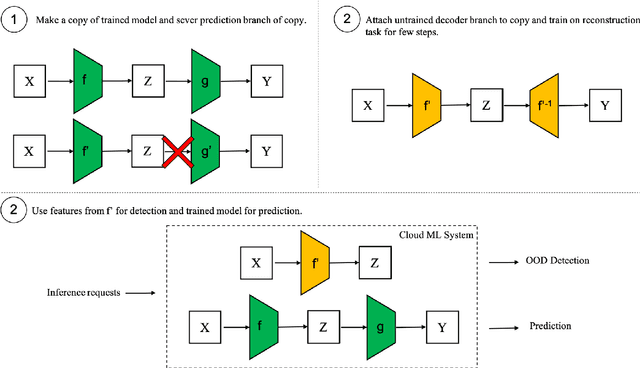
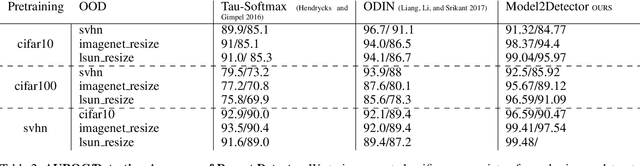
Out-of-distribution detection is an important capability that has long eluded vanilla neural networks. Deep Neural networks (DNNs) tend to generate over-confident predictions when presented with inputs that are significantly out-of-distribution (OOD). This can be dangerous when employing machine learning systems in the wild as detecting attacks can thus be difficult. Recent advances inference-time out-of-distribution detection help mitigate some of these problems. However, existing methods can be restrictive as they are often computationally expensive. Additionally, these methods require training of a downstream detector model which learns to detect OOD inputs from in-distribution ones. This, therefore, adds latency during inference. Here, we offer an information theoretic perspective on why neural networks are inherently incapable of OOD detection. We attempt to mitigate these flaws by converting a trained model into a an OOD detector using a handful of steps of gradient descent. Our work can be employed as a post-processing method whereby an inference-time ML system can convert a trained model into an OOD detector. Experimentally, we show how our method consistently outperforms the state-of-the-art in detection accuracy on popular image datasets while also reducing computational complexity.
EEGNN: Edge Enhanced Graph Neural Networks
Aug 12, 2022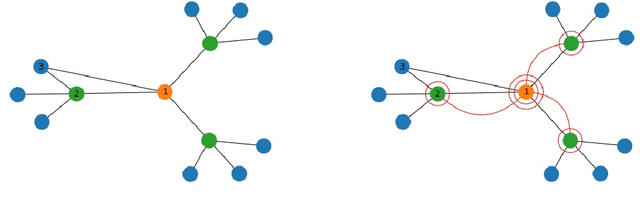
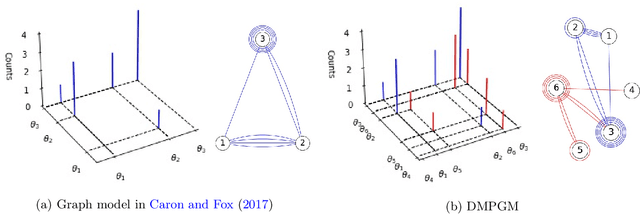
Training deep graph neural networks (GNNs) poses a challenging task, as the performance of GNNs may suffer from the number of hidden message-passing layers. The literature has focused on the proposals of over-smoothing and under-reaching to explain the performance deterioration of deep GNNs. In this paper, we propose a new explanation for such deteriorated performance phenomenon, mis-simplification, that is, mistakenly simplifying graphs by preventing self-loops and forcing edges to be unweighted. We show that such simplifying can reduce the potential of message-passing layers to capture the structural information of graphs. In view of this, we propose a new framework, edge enhanced graph neural network(EEGNN). EEGNN uses the structural information extracted from the proposed Dirichlet mixture Poisson graph model, a Bayesian nonparametric model for graphs, to improve the performance of various deep message-passing GNNs. Experiments over different datasets show that our method achieves considerable performance increase compared to baselines.
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022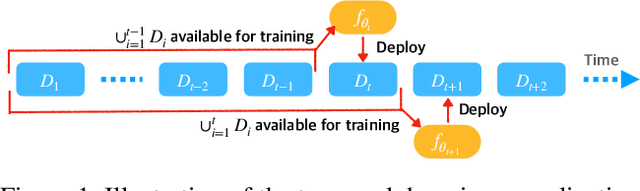
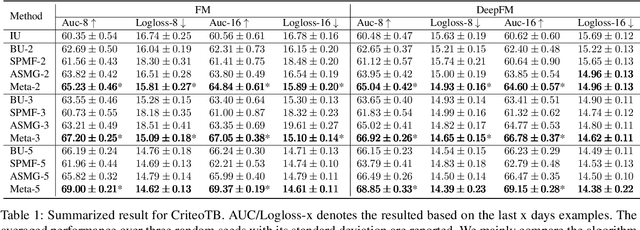
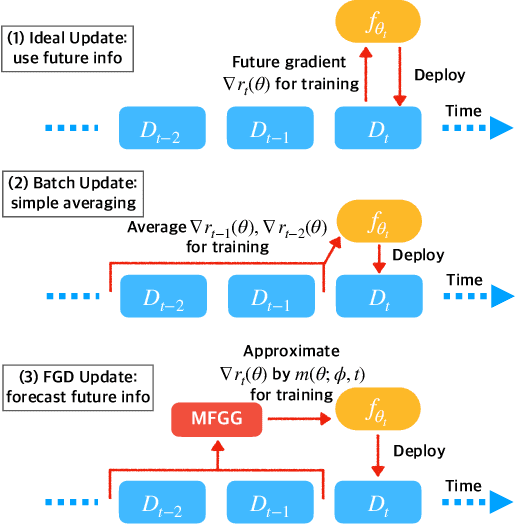
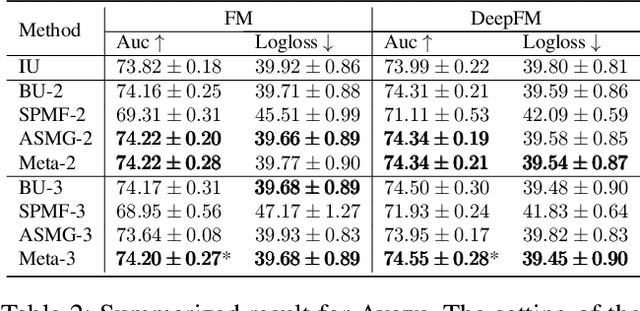
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
pFedDef: Defending Grey-Box Attacks for Personalized Federated Learning
Sep 17, 2022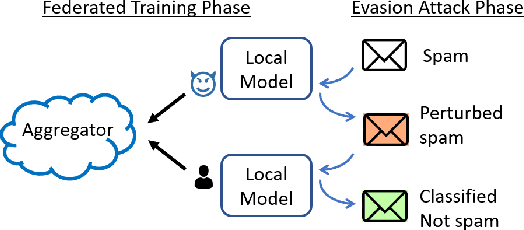
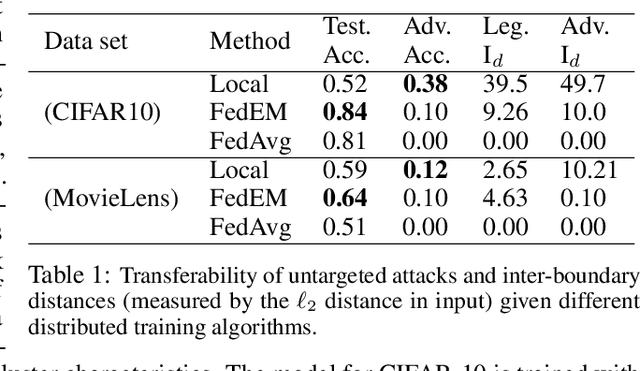
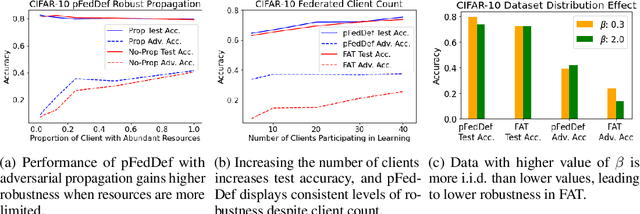

Personalized federated learning allows for clients in a distributed system to train a neural network tailored to their unique local data while leveraging information at other clients. However, clients' models are vulnerable to attacks during both the training and testing phases. In this paper we address the issue of adversarial clients crafting evasion attacks at test time to deceive other clients. For example, adversaries may aim to deceive spam filters and recommendation systems trained with personalized federated learning for monetary gain. The adversarial clients have varying degrees of personalization based on the method of distributed learning, leading to a "grey-box" situation. We are the first to characterize the transferability of such internal evasion attacks for different learning methods and analyze the trade-off between model accuracy and robustness depending on the degree of personalization and similarities in client data. We introduce a defense mechanism, pFedDef, that performs personalized federated adversarial training while respecting resource limitations at clients that inhibit adversarial training. Overall, pFedDef increases relative grey-box adversarial robustness by 62% compared to federated adversarial training and performs well even under limited system resources.
Robot Motion Planning as Video Prediction: A Spatio-Temporal Neural Network-based Motion Planner
Aug 24, 2022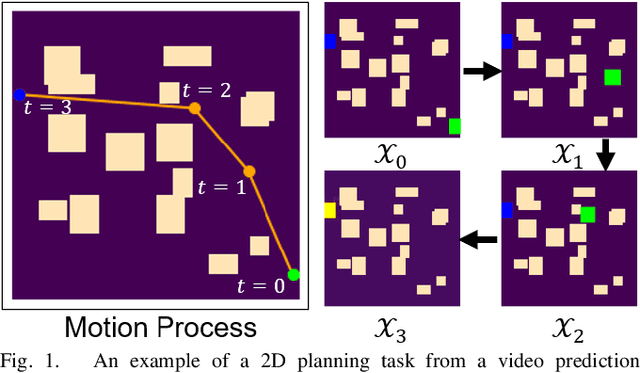
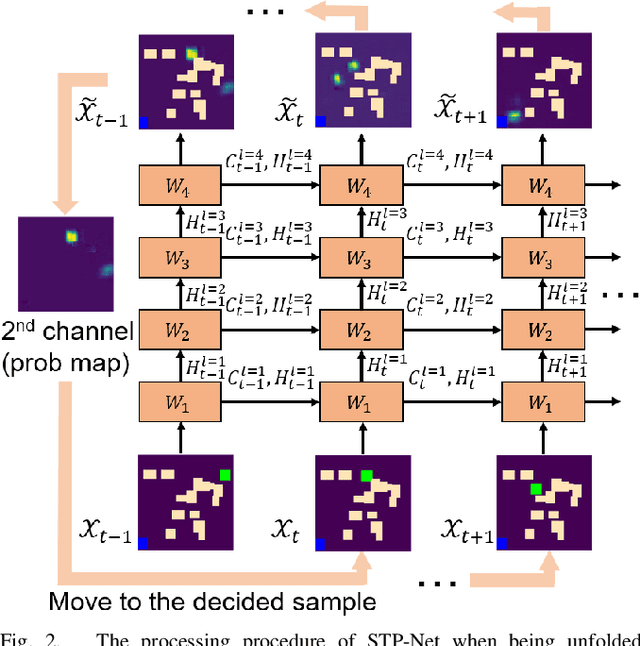
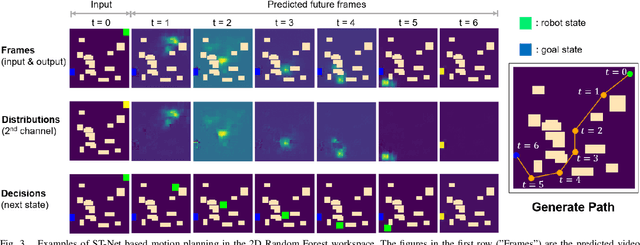
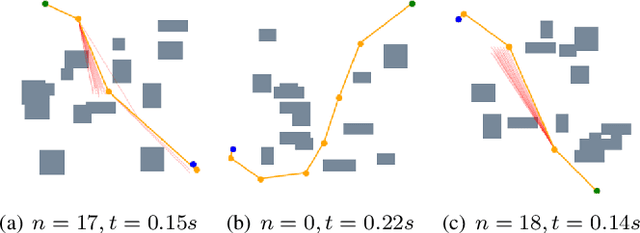
Neural network (NN)-based methods have emerged as an attractive approach for robot motion planning due to strong learning capabilities of NN models and their inherently high parallelism. Despite the current development in this direction, the efficient capture and processing of important sequential and spatial information, in a direct and simultaneous way, is still relatively under-explored. To overcome the challenge and unlock the potentials of neural networks for motion planning tasks, in this paper, we propose STP-Net, an end-to-end learning framework that can fully extract and leverage important spatio-temporal information to form an efficient neural motion planner. By interpreting the movement of the robot as a video clip, robot motion planning is transformed to a video prediction task that can be performed by STP-Net in both spatially and temporally efficient ways. Empirical evaluations across different seen and unseen environments show that, with nearly 100% accuracy (aka, success rate), STP-Net demonstrates very promising performance with respect to both planning speed and path cost. Compared with existing NN-based motion planners, STP-Net achieves at least 5x, 2.6x and 1.8x faster speed with lower path cost on 2D Random Forest, 2D Maze and 3D Random Forest environments, respectively. Furthermore, STP-Net can quickly and simultaneously compute multiple near-optimal paths in multi-robot motion planning tasks
DevNet: Self-supervised Monocular Depth Learning via Density Volume Construction
Sep 20, 2022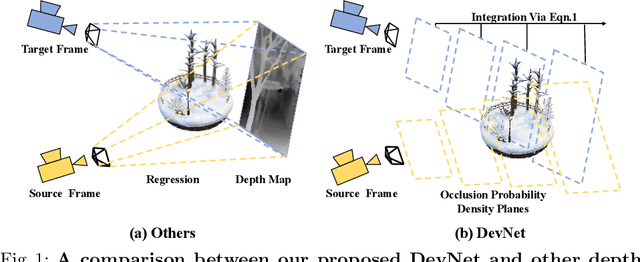
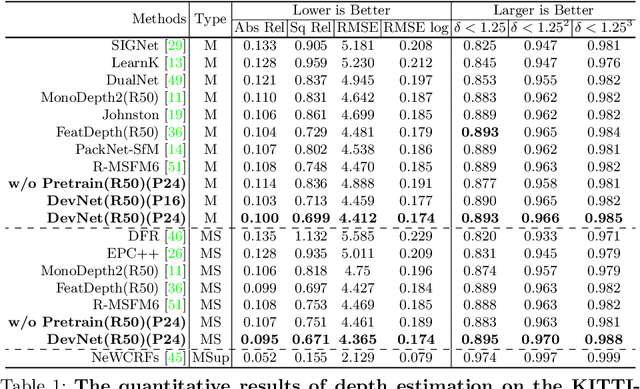
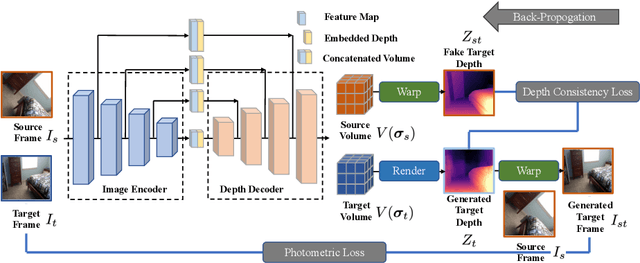

Self-supervised depth learning from monocular images normally relies on the 2D pixel-wise photometric relation between temporally adjacent image frames. However, they neither fully exploit the 3D point-wise geometric correspondences, nor effectively tackle the ambiguities in the photometric warping caused by occlusions or illumination inconsistency. To address these problems, this work proposes Density Volume Construction Network (DevNet), a novel self-supervised monocular depth learning framework, that can consider 3D spatial information, and exploit stronger geometric constraints among adjacent camera frustums. Instead of directly regressing the pixel value from a single image, our DevNet divides the camera frustum into multiple parallel planes and predicts the pointwise occlusion probability density on each plane. The final depth map is generated by integrating the density along corresponding rays. During the training process, novel regularization strategies and loss functions are introduced to mitigate photometric ambiguities and overfitting. Without obviously enlarging model parameters size or running time, DevNet outperforms several representative baselines on both the KITTI-2015 outdoor dataset and NYU-V2 indoor dataset. In particular, the root-mean-square-deviation is reduced by around 4% with DevNet on both KITTI-2015 and NYU-V2 in the task of depth estimation. Code is available at https://github.com/gitkaichenzhou/DevNet.
DeepVol: Volatility Forecasting from High-Frequency Data with Dilated Causal Convolutions
Sep 23, 2022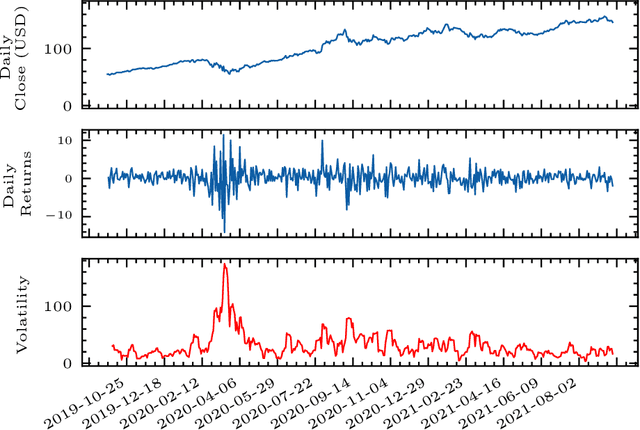
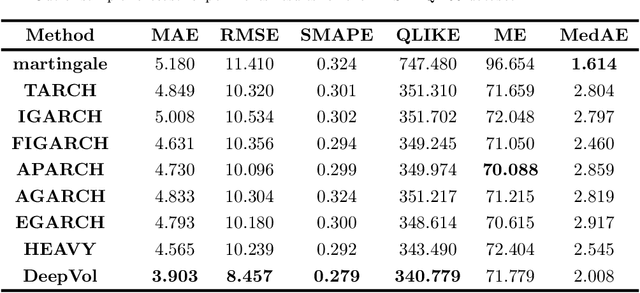
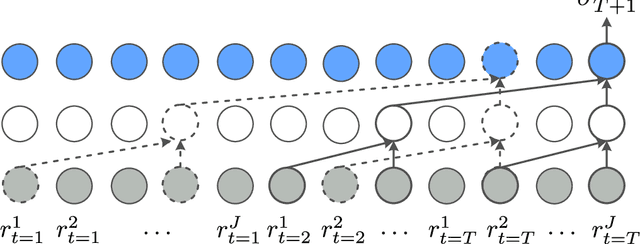
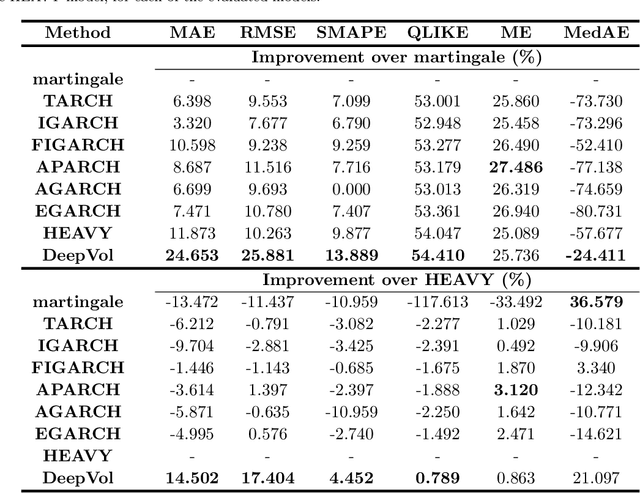
Volatility forecasts play a central role among equity risk measures. Besides traditional statistical models, modern forecasting techniques, based on machine learning, can readily be employed when treating volatility as a univariate, daily time-series. However, econometric studies have shown that increasing the number of daily observations with high-frequency intraday data helps to improve predictions. In this work, we propose DeepVol, a model based on Dilated Causal Convolutions to forecast day-ahead volatility by using high-frequency data. We show that the dilated convolutional filters are ideally suited to extract relevant information from intraday financial data, thereby naturally mimicking (via a data-driven approach) the econometric models which incorporate realised measures of volatility into the forecast. This allows us to take advantage of the abundance of intraday observations, helping us to avoid the limitations of models that use daily data, such as model misspecification or manually designed handcrafted features, whose devise involves optimising the trade-off between accuracy and computational efficiency and makes models prone to lack of adaptation into changing circumstances. In our analysis, we use two years of intraday data from NASDAQ-100 to evaluate DeepVol's performance. The reported empirical results suggest that the proposed deep learning-based approach learns global features from high-frequency data, achieving more accurate predictions than traditional methodologies, yielding to more appropriate risk measures.
Rethinking The Memory Staleness Problem In Dynamics GNN
Sep 06, 2022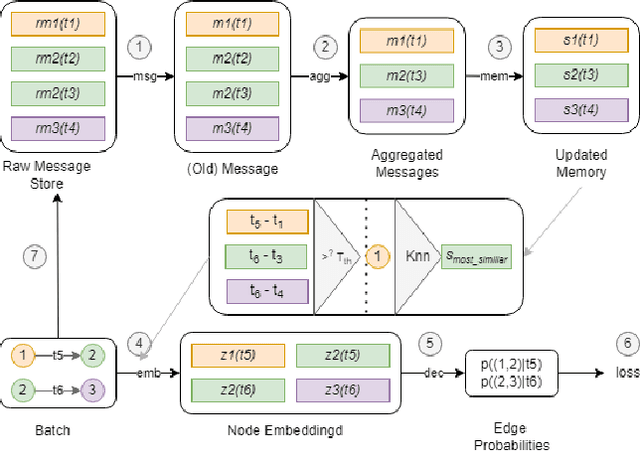
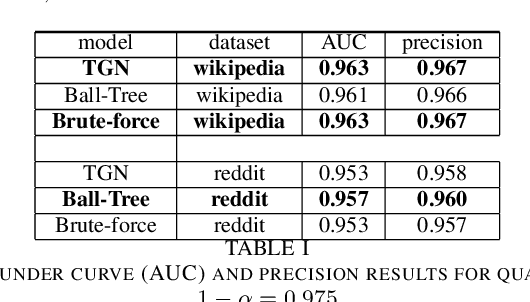
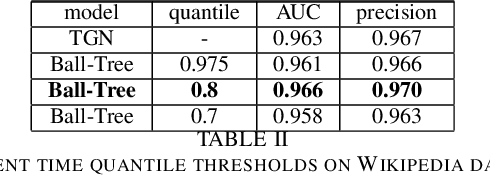
The staleness problem is a well-known problem when working with dynamic data, due to the absence of events for a long time. Since the memory of the node is updated only when the node is involved in an event, its memory becomes stale. Usually, it refers to a lack of events such as a temporal deactivation of a social account. To overcome the memory staleness problem aggregate information from the nodes neighbors memory in addition to the nodes memory. Inspired by that, we design an updated embedding module that inserts the most similar node in addition to the nodes neighbors. Our method achieved similar results to the TGN, with a slight improvement. This could indicate a potential improvement after fine-tuning our hyper-parameters, especially the time threshold, and using a learnable similarity metric.
Multi-modal Transformer Path Prediction for Autonomous Vehicle
Aug 15, 2022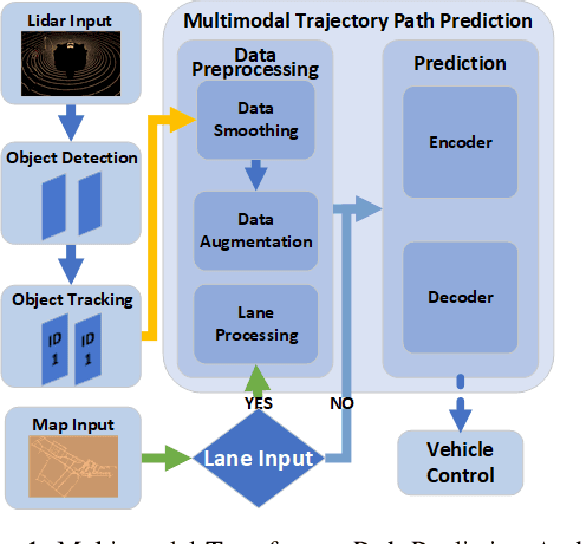
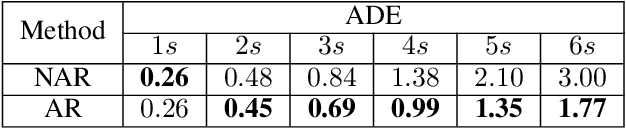
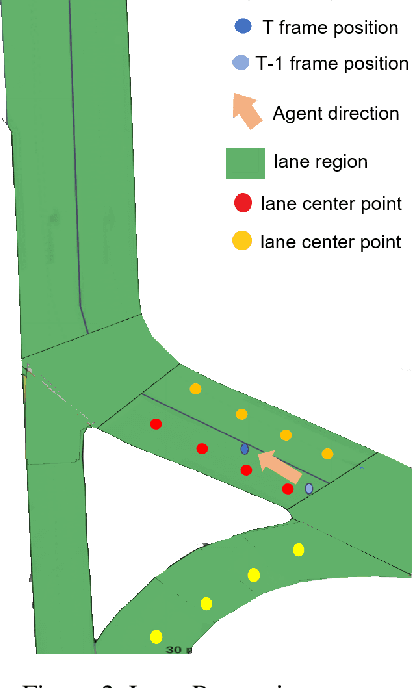
Reasoning about vehicle path prediction is an essential and challenging problem for the safe operation of autonomous driving systems. There exist many research works for path prediction. However, most of them do not use lane information and are not based on the Transformer architecture. By utilizing different types of data collected from sensors equipped on the self-driving vehicles, we propose a path prediction system named Multi-modal Transformer Path Prediction (MTPP) that aims to predict long-term future trajectory of target agents. To achieve more accurate path prediction, the Transformer architecture is adopted in our model. To better utilize the lane information, the lanes which are in opposite direction to target agent are not likely to be taken by the target agent and are consequently filtered out. In addition, consecutive lane chunks are combined to ensure the lane input to be long enough for path prediction. An extensive evaluation is conducted to show the efficacy of the proposed system using nuScene, a real-world trajectory forecasting dataset.
Uncertainty-Aware Visual Perception for Safe Motion Planning
Sep 14, 2022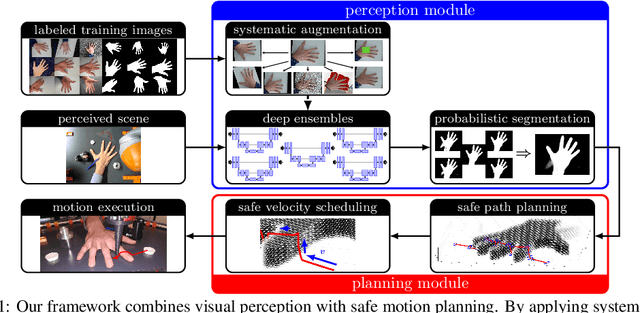
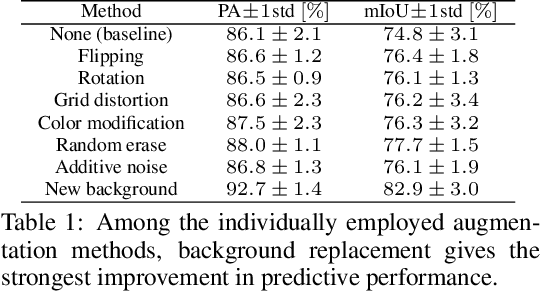
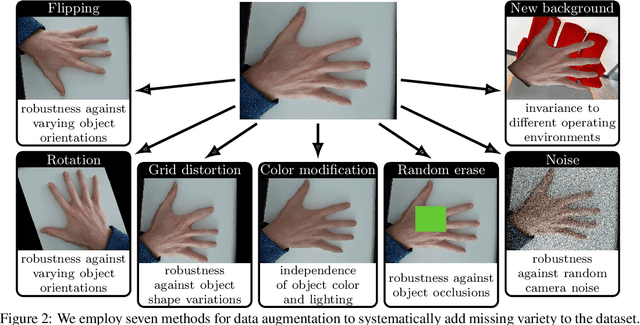
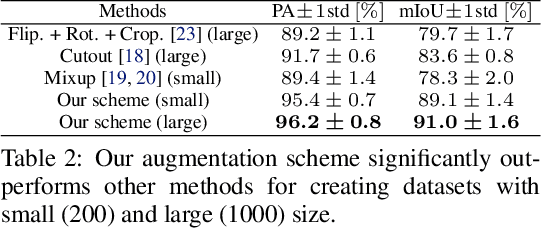
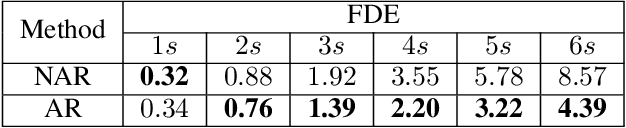
For safe operation, a robot must be able to avoid collisions in uncertain environments. Existing approaches for motion planning with uncertainties often make conservative assumptions about Gaussianity and the obstacle geometry. While visual perception can deliver a more accurate representation of the environment, its use for safe motion planning is limited by the inherent miscalibration of neural networks and the challenge of obtaining adequate datasets. In order to address these imitations, we propose to employ ensembles of deep semantic segmentation networks trained with systematically augmented datasets to ensure reliable probabilistic occupancy information. For avoiding conservatism during motion planning, we directly employ the probabilistic perception via a scenario-based path planning approach. A velocity scheduling scheme is applied to the path to ensure a safe motion despite tracking inaccuracies. We demonstrate the effectiveness of the systematic data augmentation in combination with deep ensembles and the proposed scenario-based planning approach in comparisons to state-of-the-art methods and validate our framework in an experiment involving a human hand.