 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLENDER: Blended Text Embeddings and Diffusion Residuals for Intra-Class Image Synthesis in Deep Metric Learning
Jan 28, 2026The rise of Deep Generative Models (DGM) has enabled the generation of high-quality synthetic data. When used to augment authentic data in Deep Metric Learning (DML), these synthetic samples enhance intra-class diversity and improve the performance of downstream DML tasks. We introduce BLenDeR, a diffusion sampling method designed to increase intra-class diversity for DML in a controllable way by leveraging set-theory inspired union and intersection operations on denoising residuals. The union operation encourages any attribute present across multiple prompts, while the intersection extracts the common direction through a principal component surrogate. These operations enable controlled synthesis of diverse attribute combinations within each class, addressing key limitations of existing generative approaches. Experiments on standard DML benchmarks demonstrate that BLenDeR consistently outperforms state-of-the-art baselines across multiple datasets and backbones. Specifically, BLenDeR achieves 3.7% increase in Recall@1 on CUB-200 and a 1.8% increase on Cars-196, compared to state-of-the-art baselines under standard experimental settings.
Pre-train and Search: Efficient Embedding Table Sharding with Pre-trained Neural Cost Models
May 03, 2023



Sharding a large machine learning model across multiple devices to balance the costs is important in distributed training. This is challenging because partitioning is NP-hard, and estimating the costs accurately and efficiently is difficult. In this work, we explore a "pre-train, and search" paradigm for efficient sharding. The idea is to pre-train a universal and once-for-all neural network to predict the costs of all the possible shards, which serves as an efficient sharding simulator. Built upon this pre-trained cost model, we then perform an online search to identify the best sharding plans given any specific sharding task. We instantiate this idea in deep learning recommendation models (DLRMs) and propose NeuroShard for embedding table sharding. NeuroShard pre-trains neural cost models on augmented tables to cover various sharding scenarios. Then it identifies the best column-wise and table-wise sharding plans with beam search and greedy grid search, respectively. Experiments show that NeuroShard significantly and consistently outperforms the state-of-the-art on the benchmark sharding dataset, achieving up to 23.8% improvement. When deployed in an ultra-large production DLRM with multi-terabyte embedding tables, NeuroShard achieves 11.6% improvement in embedding costs over the state-of-the-art, which translates to 6.6% end-to-end training throughput improvement. To facilitate future research of the "pre-train, and search" paradigm in ML for Systems, we open-source our code at https://github.com/daochenzha/neuroshard
DreamShard: Generalizable Embedding Table Placement for Recommender Systems
Oct 05, 2022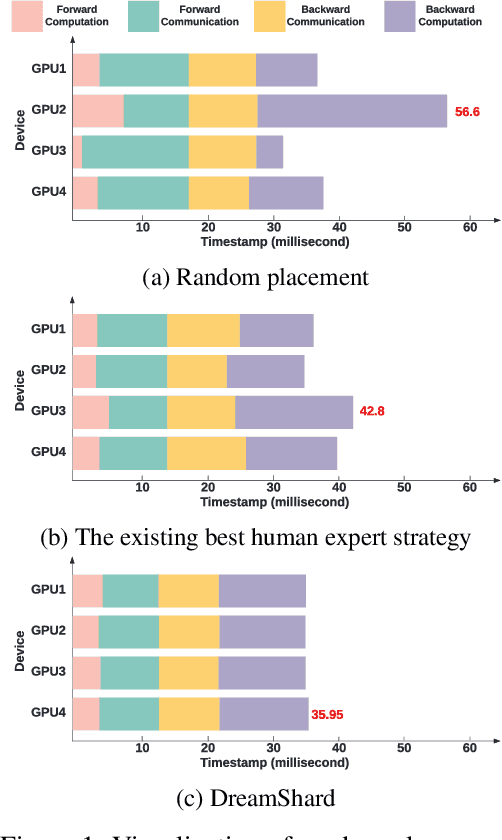
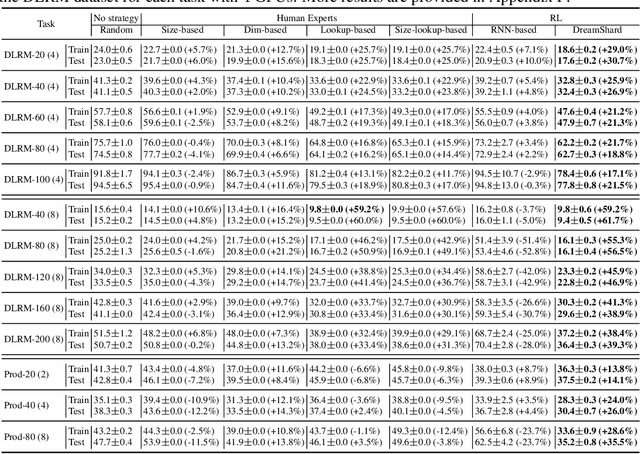
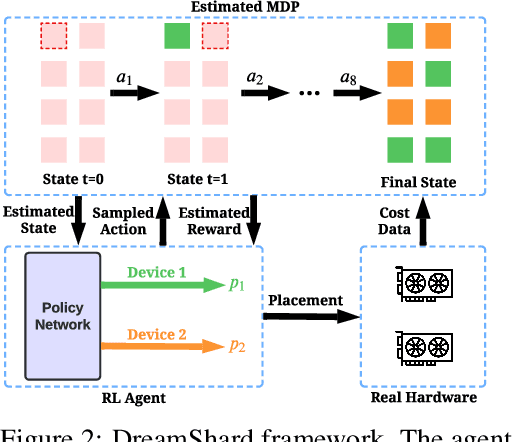
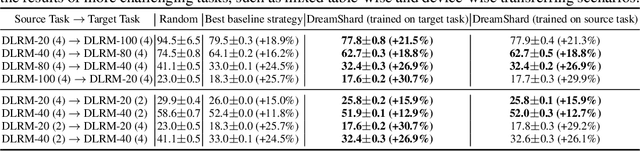
We study embedding table placement for distributed recommender systems, which aims to partition and place the tables on multiple hardware devices (e.g., GPUs) to balance the computation and communication costs. Although prior work has explored learning-based approaches for the device placement of computational graphs, embedding table placement remains to be a challenging problem because of 1) the operation fusion of embedding tables, and 2) the generalizability requirement on unseen placement tasks with different numbers of tables and/or devices. To this end, we present DreamShard, a reinforcement learning (RL) approach for embedding table placement. DreamShard achieves the reasoning of operation fusion and generalizability with 1) a cost network to directly predict the costs of the fused operation, and 2) a policy network that is efficiently trained on an estimated Markov decision process (MDP) without real GPU execution, where the states and the rewards are estimated with the cost network. Equipped with sum and max representation reductions, the two networks can directly generalize to any unseen tasks with different numbers of tables and/or devices without fine-tuning. Extensive experiments show that DreamShard substantially outperforms the existing human expert and RNN-based strategies with up to 19% speedup over the strongest baseline on large-scale synthetic tables and our production tables. The code is available at https://github.com/daochenzha/dreamshard
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022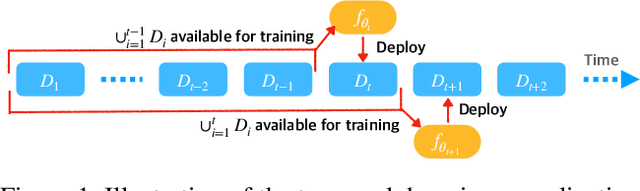
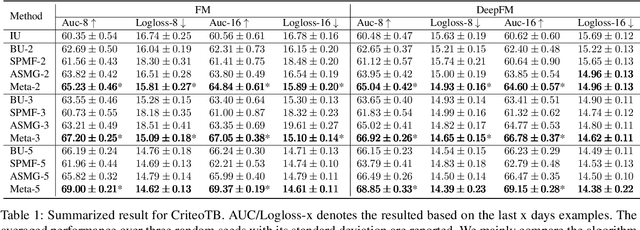
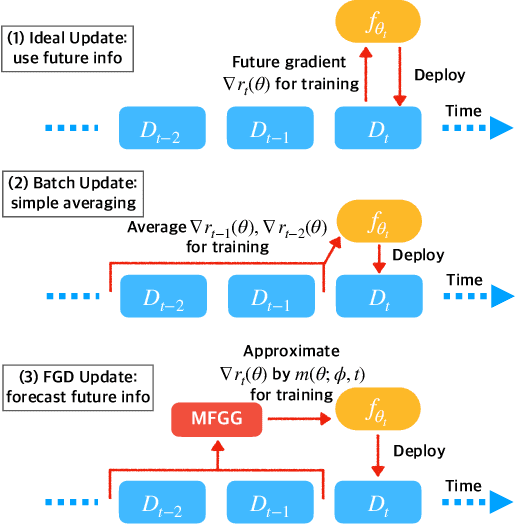
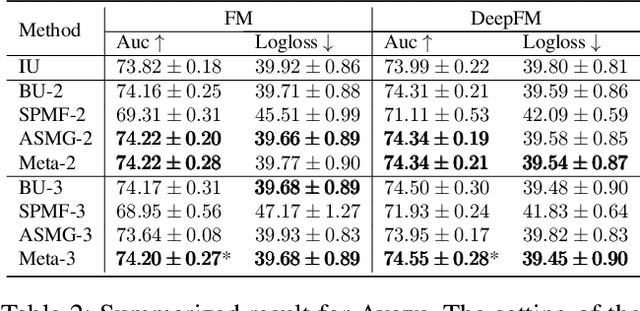
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
AutoShard: Automated Embedding Table Sharding for Recommender Systems
Aug 12, 2022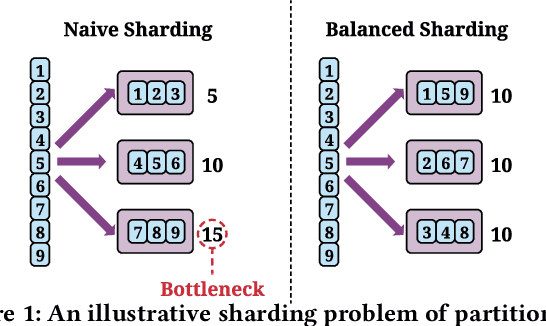
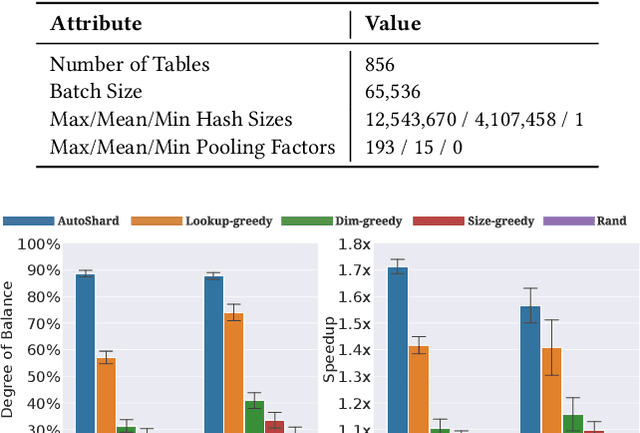

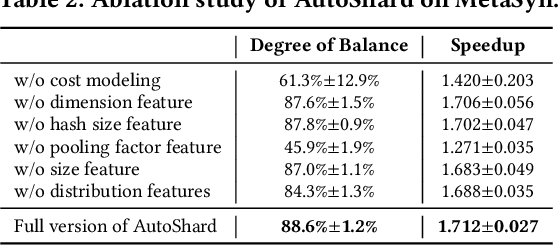
Embedding learning is an important technique in deep recommendation models to map categorical features to dense vectors. However, the embedding tables often demand an extremely large number of parameters, which become the storage and efficiency bottlenecks. Distributed training solutions have been adopted to partition the embedding tables into multiple devices. However, the embedding tables can easily lead to imbalances if not carefully partitioned. This is a significant design challenge of distributed systems named embedding table sharding, i.e., how we should partition the embedding tables to balance the costs across devices, which is a non-trivial task because 1) it is hard to efficiently and precisely measure the cost, and 2) the partition problem is known to be NP-hard. In this work, we introduce our novel practice in Meta, namely AutoShard, which uses a neural cost model to directly predict the multi-table costs and leverages deep reinforcement learning to solve the partition problem. Experimental results on an open-sourced large-scale synthetic dataset and Meta's production dataset demonstrate the superiority of AutoShard over the heuristics. Moreover, the learned policy of AutoShard can transfer to sharding tasks with various numbers of tables and different ratios of the unseen tables without any fine-tuning. Furthermore, AutoShard can efficiently shard hundreds of tables in seconds. The effectiveness, transferability, and efficiency of AutoShard make it desirable for production use. Our algorithms have been deployed in Meta production environment. A prototype is available at https://github.com/daochenzha/autoshard
Building a Performance Model for Deep Learning Recommendation Model Training on GPUs
Jan 19, 2022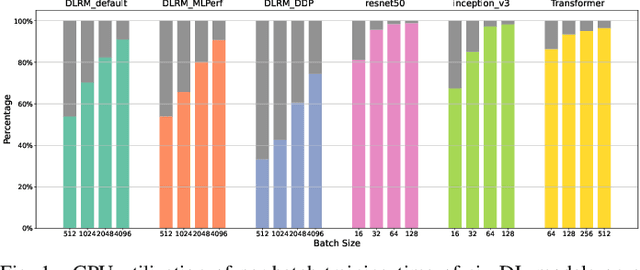
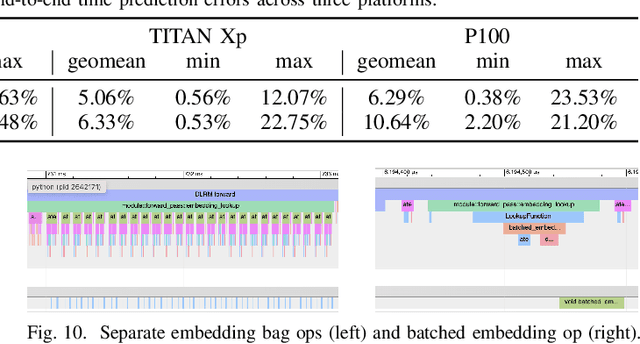

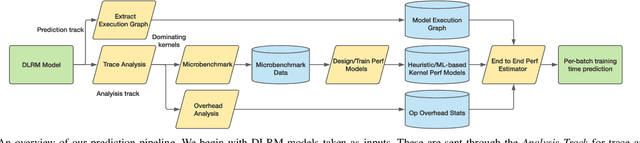
We devise a performance model for GPU training of Deep Learning Recommendation Models (DLRM), whose GPU utilization is low compared to other well-optimized CV and NLP models. We show that both the device active time (the sum of kernel runtimes) and the device idle time are important components of the overall device time. We therefore tackle them separately by (1) flexibly adopting heuristic-based and ML-based kernel performance models for operators that dominate the device active time, and (2) categorizing operator overheads into five types to determine quantitatively their contribution to the device active time. Combining these two parts, we propose a critical-path-based algorithm to predict the per-batch training time of DLRM by traversing its execution graph. We achieve less than 10% geometric mean average error (GMAE) in all kernel performance modeling, and 5.23% and 7.96% geomean errors for GPU active time and overall end-to-end per-batch training time prediction, respectively. We show that our general performance model not only achieves low prediction error on DLRM, which has highly customized configurations and is dominated by multiple factors, but also yields comparable accuracy on other compute-bound ML models targeted by most previous methods. Using this performance model and graph-level data and task dependency analyses, we show our system can provide more general model-system co-design than previous methods.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021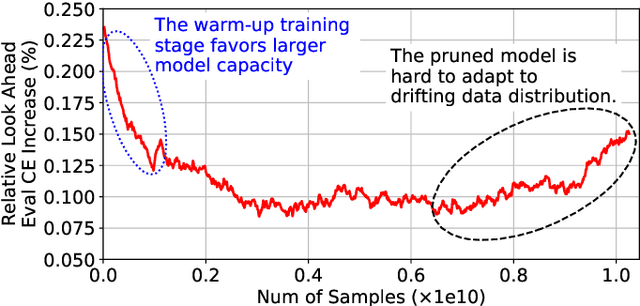

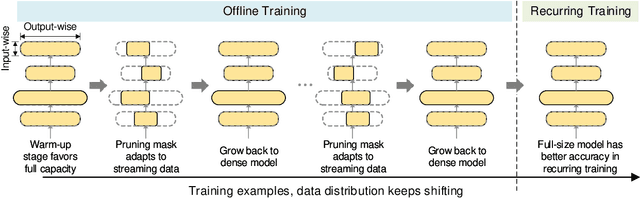

Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.
Adaptive Dense-to-Sparse Paradigm for Pruning Online Recommendation System with Non-Stationary Data
Oct 21, 2020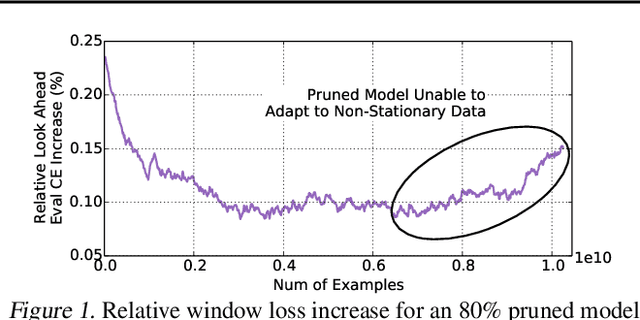
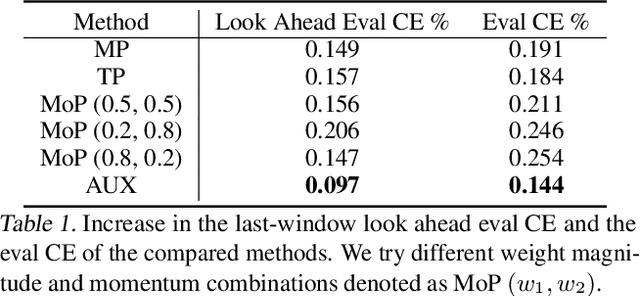
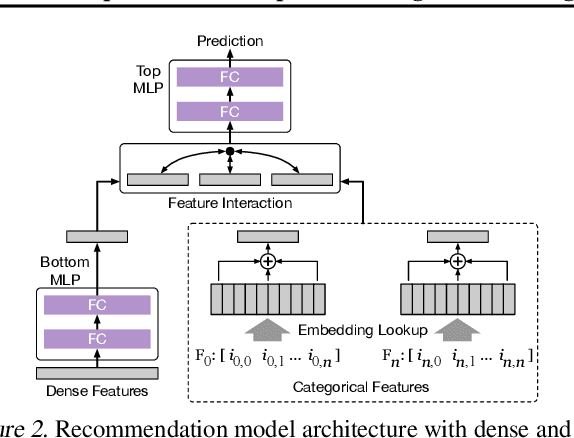
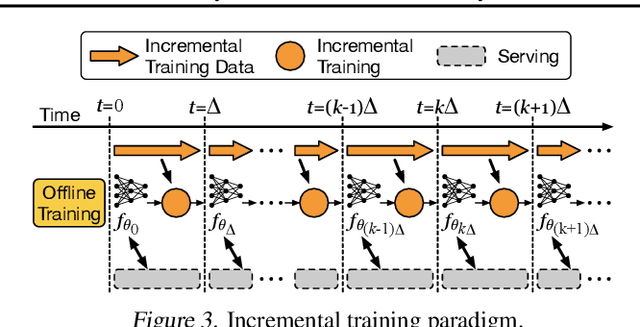
Large scale deep learning provides a tremendous opportunity to improve the quality of content recommendation systems by employing both wider and deeper models, but this comes at great infrastructural cost and carbon footprint in modern data centers. Pruning is an effective technique that reduces both memory and compute demand for model inference. However, pruning for online recommendation systems is challenging due to the continuous data distribution shift (a.k.a non-stationary data). Although incremental training on the full model is able to adapt to the non-stationary data, directly applying it on the pruned model leads to accuracy loss. This is because the sparsity pattern after pruning requires adjustment to learn new patterns. To the best of our knowledge, this is the first work to provide in-depth analysis and discussion of applying pruning to online recommendation systems with non-stationary data distribution. Overall, this work makes the following contributions: 1) We present an adaptive dense to sparse paradigm equipped with a novel pruning algorithm for pruning a large scale recommendation system with non-stationary data distribution; 2) We design the pruning algorithm to automatically learn the sparsity across layers to avoid repeating hand-tuning, which is critical for pruning the heterogeneous architectures of recommendation systems trained with non-stationary data.
Fast Distributed Training of Deep Neural Networks: Dynamic Communication Thresholding for Model and Data Parallelism
Oct 18, 2020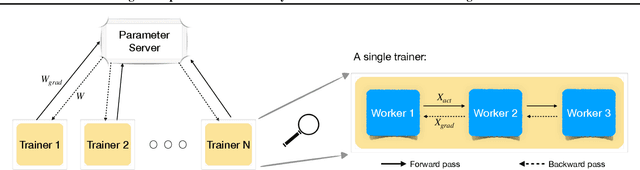
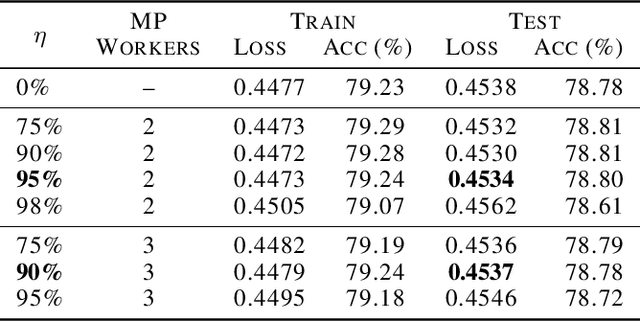
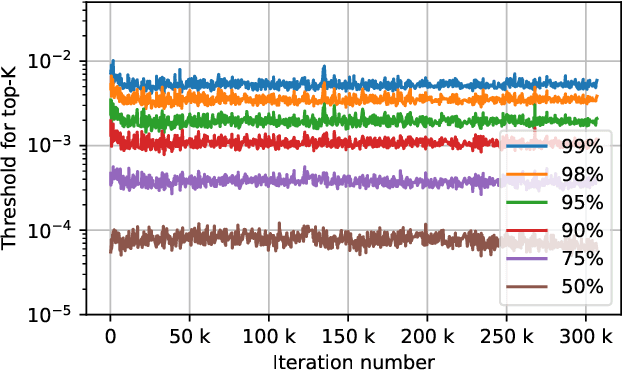
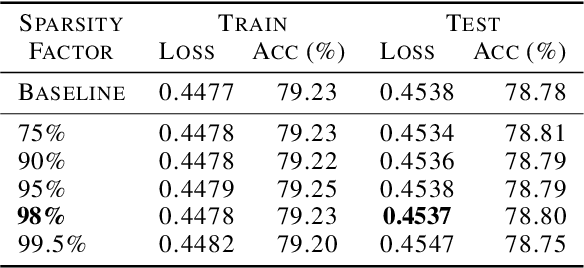
Data Parallelism (DP) and Model Parallelism (MP) are two common paradigms to enable large-scale distributed training of neural networks. Recent trends, such as the improved model performance of deeper and wider neural networks when trained with billions of data points, have prompted the use of hybrid parallelism---a paradigm that employs both DP and MP to scale further parallelization for machine learning. Hybrid training allows compute power to increase, but it runs up against the key bottleneck of communication overhead that hinders scalability. In this paper, we propose a compression framework called Dynamic Communication Thresholding (DCT) for communication-efficient hybrid training. DCT filters the entities to be communicated across the network through a simple hard-thresholding function, allowing only the most relevant information to pass through. For communication efficient DP, DCT compresses the parameter gradients sent to the parameter server during model synchronization, while compensating for the introduced errors with known techniques. For communication efficient MP, DCT incorporates a novel technique to compress the activations and gradients sent across the network during the forward and backward propagation, respectively. This is done by identifying and updating only the most relevant neurons of the neural network for each training sample in the data. Under modest assumptions, we show that the convergence of training is maintained with DCT. We evaluate DCT on natural language processing and recommender system models. DCT reduces overall communication by 20x, improving end-to-end training time on industry scale models by 37%. Moreover, we observe an improvement in the trained model performance, as the induced sparsity is possibly acting as an implicit sparsity based regularization.
On the Runtime-Efficacy Trade-off of Anomaly Detection Techniques for Real-Time Streaming Data
Oct 12, 2017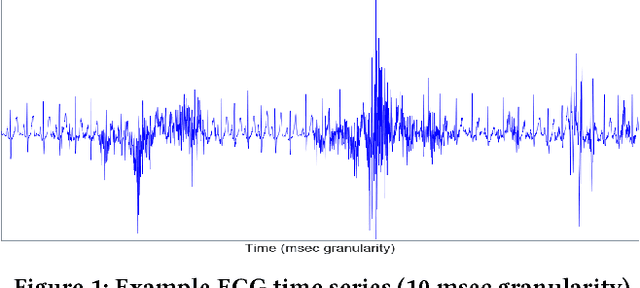
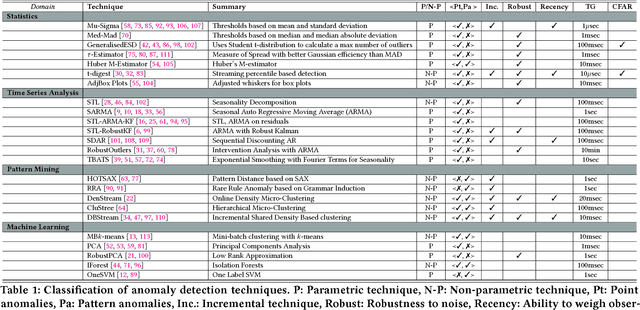
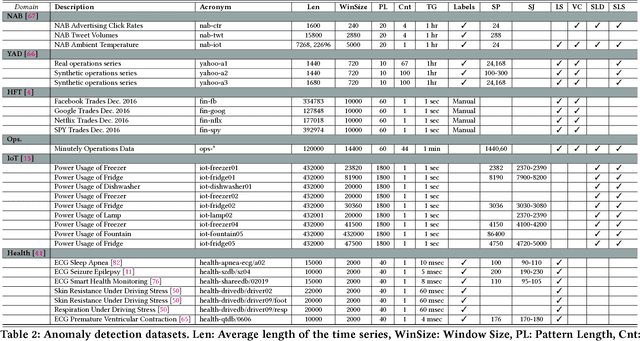
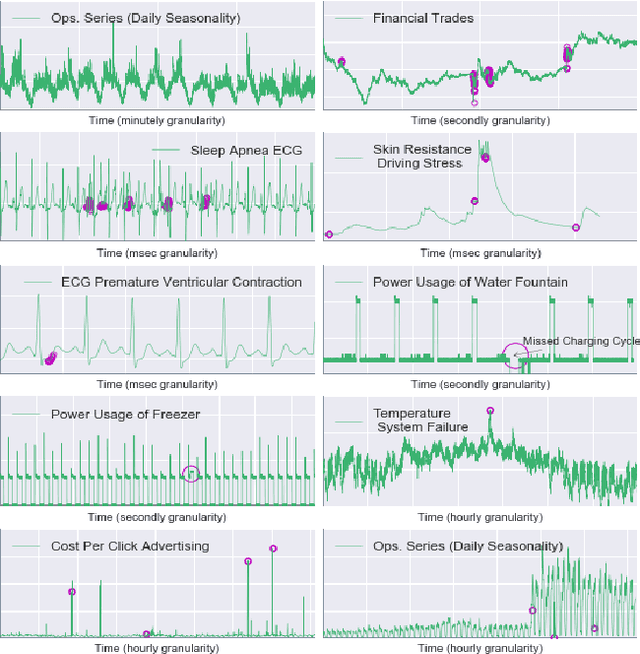
Ever growing volume and velocity of data coupled with decreasing attention span of end users underscore the critical need for real-time analytics. In this regard, anomaly detection plays a key role as an application as well as a means to verify data fidelity. Although the subject of anomaly detection has been researched for over 100 years in a multitude of disciplines such as, but not limited to, astronomy, statistics, manufacturing, econometrics, marketing, most of the existing techniques cannot be used as is on real-time data streams. Further, the lack of characterization of performance -- both with respect to real-timeliness and accuracy -- on production data sets makes model selection very challenging. To this end, we present an in-depth analysis, geared towards real-time streaming data, of anomaly detection techniques. Given the requirements with respect to real-timeliness and accuracy, the analysis presented in this paper should serve as a guide for selection of the "best" anomaly detection technique. To the best of our knowledge, this is the first characterization of anomaly detection techniques proposed in very diverse set of fields, using production data sets corresponding to a wide set of application domains.