 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Accelerating Transformer Inference and Training with 2:4 Activation Sparsity
Mar 20, 2025



In this paper, we demonstrate how to leverage 2:4 sparsity, a popular hardware-accelerated GPU sparsity pattern, to activations to accelerate large language model training and inference. Crucially we exploit the intrinsic sparsity found in Squared-ReLU activations to provide this acceleration with no accuracy loss. Our approach achieves up to 1.3x faster Feed Forward Network (FFNs) in both the forwards and backwards pass. This work highlights the potential for sparsity to play a key role in accelerating large language model training and inference.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
SpinQuant: LLM quantization with learned rotations
May 28, 2024



Post-training quantization (PTQ) techniques applied to weights, activations, and the KV cache greatly reduce memory usage, latency, and power consumption of Large Language Models (LLMs), but may lead to large quantization errors when outliers are present. Recent findings suggest that rotating activation or weight matrices helps remove outliers and benefits quantization. In this work, we identify a collection of applicable rotation parameterizations that lead to identical outputs in full-precision Transformer architectures, and find that some random rotations lead to much better quantization than others, with an up to 13 points difference in downstream zero-shot reasoning performance. As a result, we propose SpinQuant that optimizes (or learns) the rotation matrices with Cayley optimization on a small validation set. With 4-bit quantization of weight, activation, and KV-cache, SpinQuant narrows the accuracy gap on zero-shot reasoning tasks with full precision to merely 2.9 points on the LLaMA-2 7B model, surpassing LLM-QAT by 19.1 points and SmoothQuant by 25.0 points. SpinQuant also outperforms concurrent work QuaRot, which applies random rotations to remove outliers. In particular, for LLaMA-2 7B/LLaMA-3 8B models that are hard to quantize, SpinQuant reduces the gap to full precision by 30.2%/34.1% relative to QuaRot.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
FlexShard: Flexible Sharding for Industry-Scale Sequence Recommendation Models
Jan 08, 2023



Sequence-based deep learning recommendation models (DLRMs) are an emerging class of DLRMs showing great improvements over their prior sum-pooling based counterparts at capturing users' long term interests. These improvements come at immense system cost however, with sequence-based DLRMs requiring substantial amounts of data to be dynamically materialized and communicated by each accelerator during a single iteration. To address this rapidly growing bottleneck, we present FlexShard, a new tiered sequence embedding table sharding algorithm which operates at a per-row granularity by exploiting the insight that not every row is equal. Through precise replication of embedding rows based on their underlying probability distribution, along with the introduction of a new sharding strategy adapted to the heterogeneous, skewed performance of real-world cluster network topologies, FlexShard is able to significantly reduce communication demand while using no additional memory compared to the prior state-of-the-art. When evaluated on production-scale sequence DLRMs, FlexShard was able to reduce overall global all-to-all communication traffic by over 85%, resulting in end-to-end training communication latency improvements of almost 6x over the prior state-of-the-art approach.
RecD: Deduplication for End-to-End Deep Learning Recommendation Model Training Infrastructure
Nov 14, 2022



We present RecD (Recommendation Deduplication), a suite of end-to-end infrastructure optimizations across the Deep Learning Recommendation Model (DLRM) training pipeline. RecD addresses immense storage, preprocessing, and training overheads caused by feature duplication inherent in industry-scale DLRM training datasets. Feature duplication arises because DLRM datasets are generated from interactions. While each user session can generate multiple training samples, many features' values do not change across these samples. We demonstrate how RecD exploits this property, end-to-end, across a deployed training pipeline. RecD optimizes data generation pipelines to decrease dataset storage and preprocessing resource demands and to maximize duplication within a training batch. RecD introduces a new tensor format, InverseKeyedJaggedTensors (IKJTs), to deduplicate feature values in each batch. We show how DLRM model architectures can leverage IKJTs to drastically increase training throughput. RecD improves the training and preprocessing throughput and storage efficiency by up to 2.49x, 1.79x, and 3.71x, respectively, in an industry-scale DLRM training system.
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022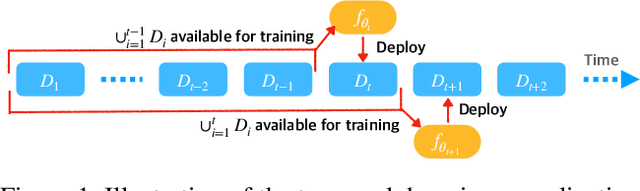
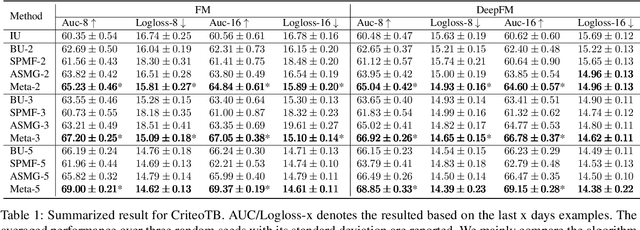
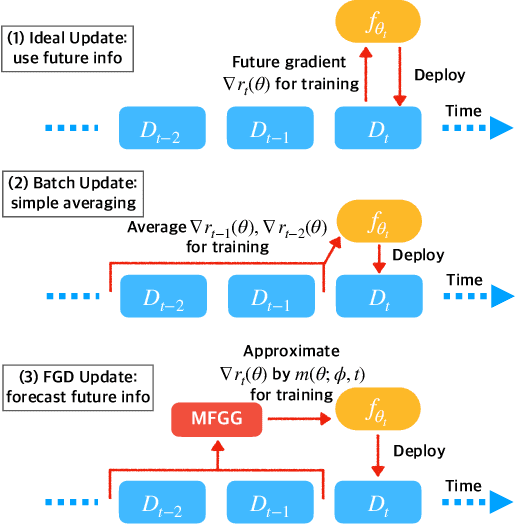
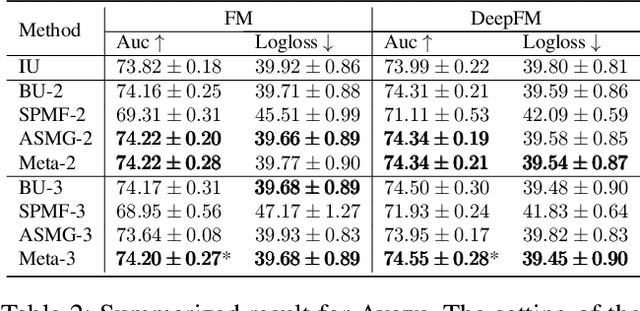
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
AutoShard: Automated Embedding Table Sharding for Recommender Systems
Aug 12, 2022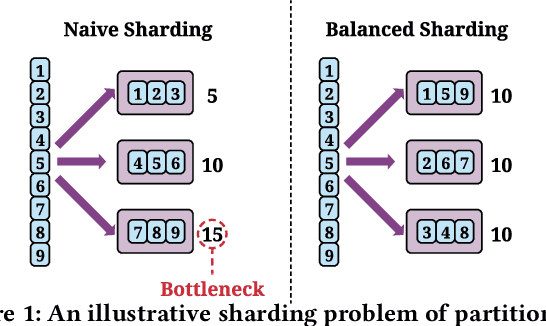
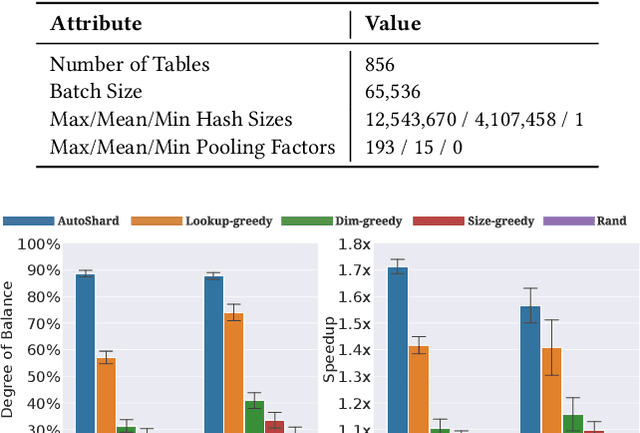

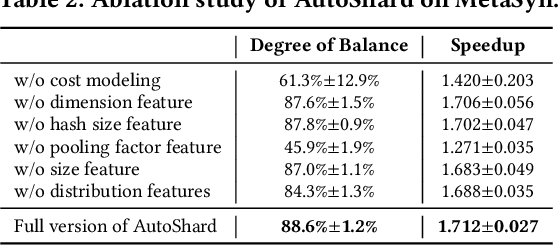
Embedding learning is an important technique in deep recommendation models to map categorical features to dense vectors. However, the embedding tables often demand an extremely large number of parameters, which become the storage and efficiency bottlenecks. Distributed training solutions have been adopted to partition the embedding tables into multiple devices. However, the embedding tables can easily lead to imbalances if not carefully partitioned. This is a significant design challenge of distributed systems named embedding table sharding, i.e., how we should partition the embedding tables to balance the costs across devices, which is a non-trivial task because 1) it is hard to efficiently and precisely measure the cost, and 2) the partition problem is known to be NP-hard. In this work, we introduce our novel practice in Meta, namely AutoShard, which uses a neural cost model to directly predict the multi-table costs and leverages deep reinforcement learning to solve the partition problem. Experimental results on an open-sourced large-scale synthetic dataset and Meta's production dataset demonstrate the superiority of AutoShard over the heuristics. Moreover, the learned policy of AutoShard can transfer to sharding tasks with various numbers of tables and different ratios of the unseen tables without any fine-tuning. Furthermore, AutoShard can efficiently shard hundreds of tables in seconds. The effectiveness, transferability, and efficiency of AutoShard make it desirable for production use. Our algorithms have been deployed in Meta production environment. A prototype is available at https://github.com/daochenzha/autoshard