 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformalized Neural Networks for Federated Uncertainty Quantification under Dual Heterogeneity
Feb 26, 2026Federated learning (FL) faces challenges in uncertainty quantification (UQ). Without reliable UQ, FL systems risk deploying overconfident models at under-resourced agents, leading to silent local failures despite seemingly satisfactory global performance. Existing federated UQ approaches often address data heterogeneity or model heterogeneity in isolation, overlooking their joint effect on coverage reliability across agents. Conformal prediction is a widely used distribution-free UQ framework, yet its applications in heterogeneous FL settings remains underexplored. We provide FedWQ-CP, a simple yet effective approach that balances empirical coverage performance with efficiency at both global and agent levels under the dual heterogeneity. FedWQ-CP performs agent-server calibration in a single communication round. On each agent, conformity scores are computed on calibration data and a local quantile threshold is derived. Each agent then transmits only its quantile threshold and calibration sample size to the server. The server simply aggregates these thresholds through a weighted average to produce a global threshold. Experimental results on seven public datasets for both classification and regression demonstrate that FedWQ-CP empirically maintains agent-wise and global coverage while producing the smallest prediction sets or intervals.
Federated-inspired Single-cell Batch Integration in Latent Space
Jan 31, 2026Advances in single-cell RNA sequencing enable the rapid generation of massive, high-dimensional datasets, yet the accumulation of data across experiments introduces batch effects that obscure true biological signals. Existing batch correction approaches either insufficiently correct batch effects or require centralized retraining on the complete dataset, limiting their applicability in distributed and continually evolving single-cell data settings. We introduce scBatchProx, a post-hoc optimization method inspired by federated learning principles for refining cell-level embeddings produced by arbitrary upstream methods. Treating each batch as a client, scBatchProx learns batch-conditioned adapters under proximal regularization, correcting batch structure directly in latent space without requiring raw expression data or centralized optimization. The method is lightweight and deployable, optimizing batch-specific adapter parameters only. Extensive experiments show that scBatchProx consistently yields relative gains of approximately 3-8% in overall embedding quality, with batch correction and biological conservation improving in 90% and 85% of data-method pairs, respectively. We envision this work as a step toward the practical refinement of learned representations in dynamic single-cell data systems.
VideoBadminton: A Video Dataset for Badminton Action Recognition
Mar 19, 2024



In the dynamic and evolving field of computer vision, action recognition has become a key focus, especially with the advent of sophisticated methodologies like Convolutional Neural Networks (CNNs), Convolutional 3D, Transformer, and spatial-temporal feature fusion. These technologies have shown promising results on well-established benchmarks but face unique challenges in real-world applications, particularly in sports analysis, where the precise decomposition of activities and the distinction of subtly different actions are crucial. Existing datasets like UCF101, HMDB51, and Kinetics have offered a diverse range of video data for various scenarios. However, there's an increasing need for fine-grained video datasets that capture detailed categorizations and nuances within broader action categories. In this paper, we introduce the VideoBadminton dataset derived from high-quality badminton footage. Through an exhaustive evaluation of leading methodologies on this dataset, this study aims to advance the field of action recognition, particularly in badminton sports. The introduction of VideoBadminton could not only serve for badminton action recognition but also provide a dataset for recognizing fine-grained actions. The insights gained from these evaluations are expected to catalyze further research in action comprehension, especially within sports contexts.
A Survey of Lottery Ticket Hypothesis
Mar 12, 2024

The Lottery Ticket Hypothesis (LTH) states that a dense neural network model contains a highly sparse subnetwork (i.e., winning tickets) that can achieve even better performance than the original model when trained in isolation. While LTH has been proved both empirically and theoretically in many works, there still are some open issues, such as efficiency and scalability, to be addressed. Also, the lack of open-source frameworks and consensual experimental setting poses a challenge to future research on LTH. We, for the first time, examine previous research and studies on LTH from different perspectives. We also discuss issues in existing works and list potential directions for further exploration. This survey aims to provide an in-depth look at the state of LTH and develop a duly maintained platform to conduct experiments and compare with the most updated baselines.
Dynamic Graph Representation Learning for Depression Screening with Transformer
May 10, 2023Early detection of mental disorder is crucial as it enables prompt intervention and treatment, which can greatly improve outcomes for individuals suffering from debilitating mental affliction. The recent proliferation of mental health discussions on social media platforms presents research opportunities to investigate mental health and potentially detect instances of mental illness. However, existing depression detection methods are constrained due to two major limitations: (1) the reliance on feature engineering and (2) the lack of consideration for time-varying factors. Specifically, these methods require extensive feature engineering and domain knowledge, which heavily rely on the amount, quality, and type of user-generated content. Moreover, these methods ignore the important impact of time-varying factors on depression detection, such as the dynamics of linguistic patterns and interpersonal interactive behaviors over time on social media (e.g., replies, mentions, and quote-tweets). To tackle these limitations, we propose an early depression detection framework, ContrastEgo treats each user as a dynamic time-evolving attributed graph (ego-network) and leverages supervised contrastive learning to maximize the agreement of users' representations at different scales while minimizing the agreement of users' representations to differentiate between depressed and control groups. ContrastEgo embraces four modules, (1) constructing users' heterogeneous interactive graphs, (2) extracting the representations of users' interaction snapshots using graph neural networks, (3) modeling the sequences of snapshots using attention mechanism, and (4) depression detection using contrastive learning. Extensive experiments on Twitter data demonstrate that ContrastEgo significantly outperforms the state-of-the-art methods in terms of all the effectiveness metrics in various experimental settings.
Rethinking Graph Lottery Tickets: Graph Sparsity Matters
May 03, 2023



Lottery Ticket Hypothesis (LTH) claims the existence of a winning ticket (i.e., a properly pruned sub-network together with original weight initialization) that can achieve competitive performance to the original dense network. A recent work, called UGS, extended LTH to prune graph neural networks (GNNs) for effectively accelerating GNN inference. UGS simultaneously prunes the graph adjacency matrix and the model weights using the same masking mechanism, but since the roles of the graph adjacency matrix and the weight matrices are very different, we find that their sparsifications lead to different performance characteristics. Specifically, we find that the performance of a sparsified GNN degrades significantly when the graph sparsity goes beyond a certain extent. Therefore, we propose two techniques to improve GNN performance when the graph sparsity is high. First, UGS prunes the adjacency matrix using a loss formulation which, however, does not properly involve all elements of the adjacency matrix; in contrast, we add a new auxiliary loss head to better guide the edge pruning by involving the entire adjacency matrix. Second, by regarding unfavorable graph sparsification as adversarial data perturbations, we formulate the pruning process as a min-max optimization problem to gain the robustness of lottery tickets when the graph sparsity is high. We further investigate the question: Can the "retrainable" winning ticket of a GNN be also effective for graph transferring learning? We call it the transferable graph lottery ticket (GLT) hypothesis. Extensive experiments were conducted which demonstrate the superiority of our proposed sparsification method over UGS, and which empirically verified our transferable GLT hypothesis.
Multi-modal Transformer Path Prediction for Autonomous Vehicle
Aug 15, 2022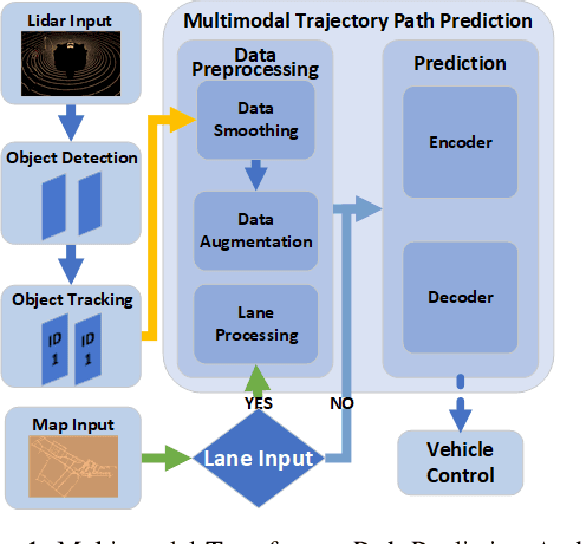
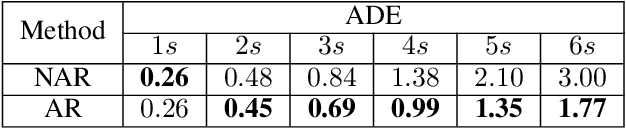
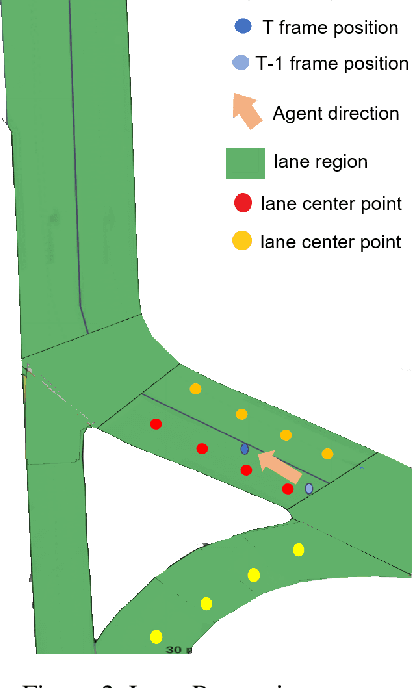
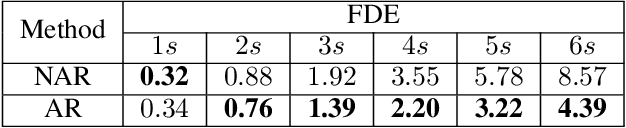
Reasoning about vehicle path prediction is an essential and challenging problem for the safe operation of autonomous driving systems. There exist many research works for path prediction. However, most of them do not use lane information and are not based on the Transformer architecture. By utilizing different types of data collected from sensors equipped on the self-driving vehicles, we propose a path prediction system named Multi-modal Transformer Path Prediction (MTPP) that aims to predict long-term future trajectory of target agents. To achieve more accurate path prediction, the Transformer architecture is adopted in our model. To better utilize the lane information, the lanes which are in opposite direction to target agent are not likely to be taken by the target agent and are consequently filtered out. In addition, consecutive lane chunks are combined to ensure the lane input to be long enough for path prediction. An extensive evaluation is conducted to show the efficacy of the proposed system using nuScene, a real-world trajectory forecasting dataset.
RFID-Based Indoor Spatial Query Evaluation with Bayesian Filtering Techniques
Apr 02, 2022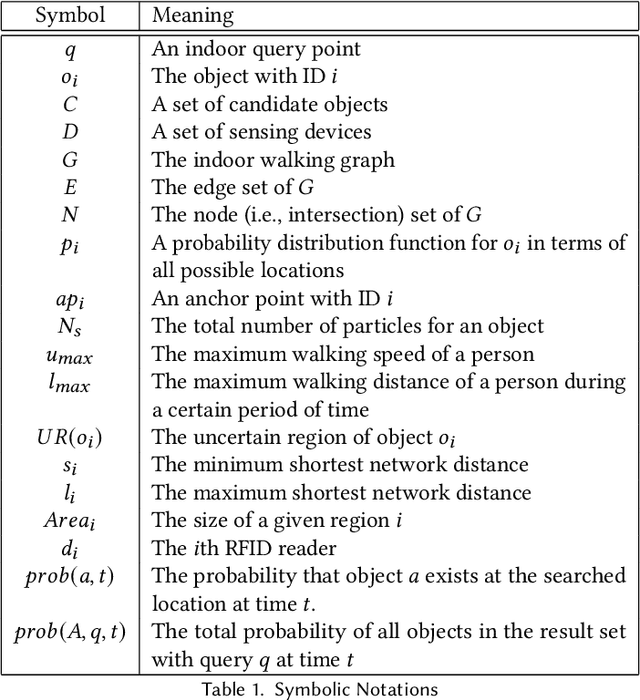
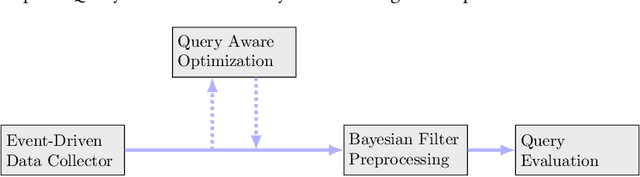
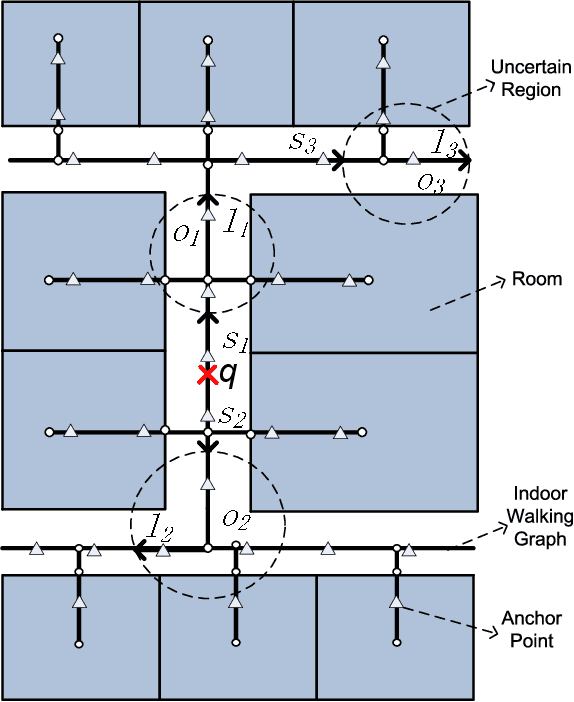
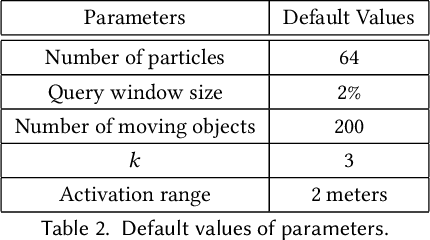
People spend a significant amount of time in indoor spaces (e.g., office buildings, subway systems, etc.) in their daily lives. Therefore, it is important to develop efficient indoor spatial query algorithms for supporting various location-based applications. However, indoor spaces differ from outdoor spaces because users have to follow the indoor floor plan for their movements. In addition, positioning in indoor environments is mainly based on sensing devices (e.g., RFID readers) rather than GPS devices. Consequently, we cannot apply existing spatial query evaluation techniques devised for outdoor environments for this new challenge. Because Bayesian filtering techniques can be employed to estimate the state of a system that changes over time using a sequence of noisy measurements made on the system, in this research, we propose the Bayesian filtering-based location inference methods as the basis for evaluating indoor spatial queries with noisy RFID raw data. Furthermore, two novel models, indoor walking graph model and anchor point indexing model, are created for tracking object locations in indoor environments. Based on the inference method and tracking models, we develop innovative indoor range and k nearest neighbor (kNN) query algorithms. We validate our solution through use of both synthetic data and real-world data. Our experimental results show that the proposed algorithms can evaluate indoor spatial queries effectively and efficiently. We open-source the code, data, and floor plan at https://github.com/DataScienceLab18/IndoorToolKit.
sMGC: A Complex-Valued Graph Convolutional Network via Magnetic Laplacian for Directed Graphs
Oct 14, 2021
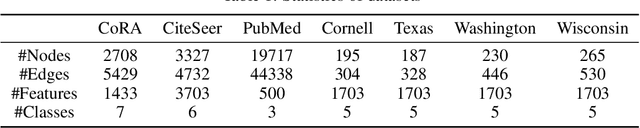
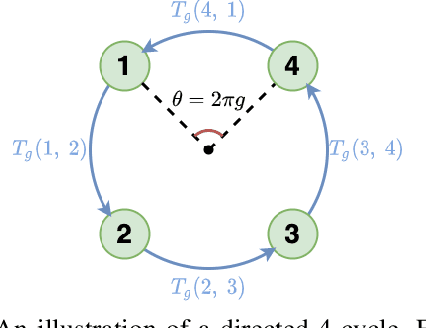
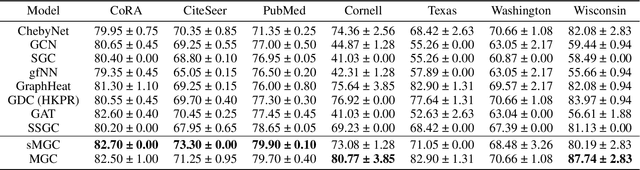
Recent advancements in Graph Neural Networks have led to state-of-the-art performance on representation learning of graphs for node classification. However, the majority of existing works process directed graphs by symmetrization, which may cause loss of directional information. In this paper, we propose the magnetic Laplacian that preserves edge directionality by encoding it into complex phase as a deformation of the combinatorial Laplacian. In addition, we design an Auto-Regressive Moving-Average (ARMA) filter that is capable of learning global features from graphs. To reduce time complexity, Taylor expansion is applied to approximate the filter. We derive complex-valued operations in graph neural network and devise a simplified Magnetic Graph Convolution network, namely sMGC. Our experiment results demonstrate that sMGC is a fast, powerful, and widely applicable GNN.
Deep Multi-attribute Graph Representation Learning on Protein Structures
Dec 22, 2020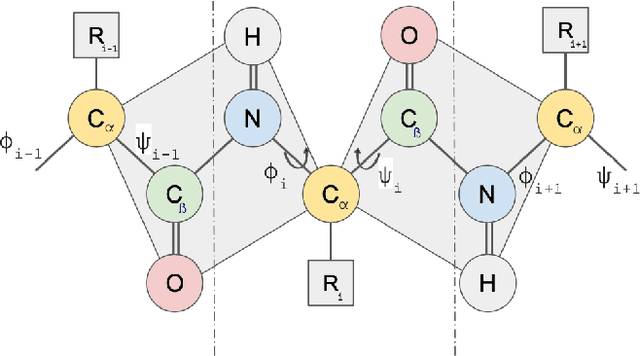
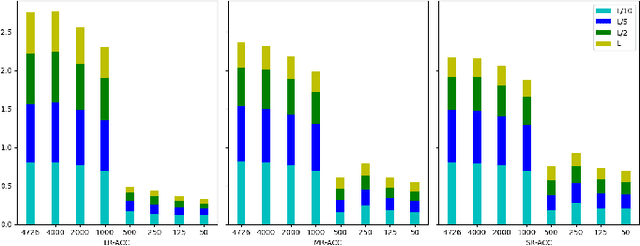
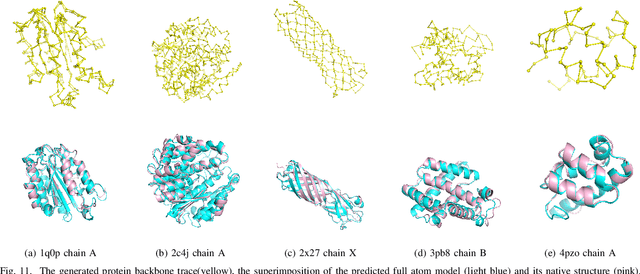
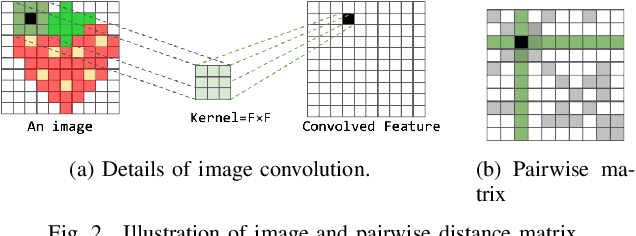
Graphs as a type of data structure have recently attracted significant attention. Representation learning of geometric graphs has achieved great success in many fields including molecular, social, and financial networks. It is natural to present proteins as graphs in which nodes represent the residues and edges represent the pairwise interactions between residues. However, 3D protein structures have rarely been studied as graphs directly. The challenges include: 1) Proteins are complex macromolecules composed of thousands of atoms making them much harder to model than micro-molecules. 2) Capturing the long-range pairwise relations for protein structure modeling remains under-explored. 3) Few studies have focused on learning the different attributes of proteins together. To address the above challenges, we propose a new graph neural network architecture to represent the proteins as 3D graphs and predict both distance geometric graph representation and dihedral geometric graph representation together. This gives a significant advantage because this network opens a new path from the sequence to structure. We conducted extensive experiments on four different datasets and demonstrated the effectiveness of the proposed method.