 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAletheia tackles FirstProof autonomously
Feb 24, 2026We report the performance of Aletheia (Feng et al., 2026b), a mathematics research agent powered by Gemini 3 Deep Think, on the inaugural FirstProof challenge. Within the allowed timeframe of the challenge, Aletheia autonomously solved 6 problems (2, 5, 7, 8, 9, 10) out of 10 according to majority expert assessments; we note that experts were not unanimous on Problem 8 (only). For full transparency, we explain our interpretation of FirstProof and disclose details about our experiments as well as our evaluation. Raw prompts and outputs are available at https://github.com/google-deepmind/superhuman/tree/main/aletheia.
Adaptive Optimization via Momentum on Variance-Normalized Gradients
Feb 10, 2026We introduce MVN-Grad (Momentum on Variance-Normalized Gradients), an Adam-style optimizer that improves stability and performance by combining two complementary ideas: variance-based normalization and momentum applied after normalization. MVN-Grad scales each coordinate by an exponential moving average of gradient uncertainty and applies momentum to the resulting normalized gradients, eliminating the cross-time coupling between stale momentum and a stochastic normalizer present in standard Adam-type updates. We prove that this decoupling yields strictly smaller one-step conditional update variance than momentum-then-normalize variance methods under standard noise assumptions, and that MVN-Grad is robust to outliers: it has a uniformly bounded response to single gradient spikes. In low-variance regimes, we further show variance normalization avoids sign-type collapse associated with second-moment scaling and can yield accelerated convergence. Across CIFAR-100 image classification and GPT-style language modeling benchmarks, MVN-Grad matches or outperforms Adam, AdaBelief, and LaProp, delivering smoother training and improved generalization with no added overhead.
Temper-Then-Tilt: Principled Unlearning for Generative Models through Tempering and Classifier Guidance
Feb 10, 2026We study machine unlearning in large generative models by framing the task as density ratio estimation to a target distribution rather than supervised fine-tuning. While classifier guidance is a standard approach for approximating this ratio and can succeed in general, we show it can fail to faithfully unlearn with finite samples when the forget set represents a sharp, concentrated data distribution. To address this, we introduce Temper-Then-Tilt Unlearning (T3-Unlearning), which freezes the base model and applies a two-step inference procedure: (i) tempering the base distribution to flatten high-confidence spikes, and (ii) tilting the tempered distribution using a lightweight classifier trained to distinguish retain from forget samples. Our theoretical analysis provides finite-sample guarantees linking the surrogate classifier's risk to unlearning error, proving that tempering is necessary to successfully unlearn for concentrated distributions. Empirical evaluations on the TOFU benchmark show that T3-Unlearning improves forget quality and generative utility over existing baselines, while training only a fraction of the parameters with a minimal runtime.
Adaptive Matrix Online Learning through Smoothing with Guarantees for Nonsmooth Nonconvex Optimization
Feb 09, 2026We study online linear optimization with matrix variables constrained by the operator norm, a setting where the geometry renders designing data-dependent and efficient adaptive algorithms challenging. The best-known adaptive regret bounds are achieved by Shampoo-like methods, but they require solving a costly quadratic projection subproblem. To address this, we extend the gradient-based prediction scheme to adaptive matrix online learning and cast algorithm design as constructing a family of smoothed potentials for the nuclear norm. We define a notion of admissibility for such smoothings and prove any admissible smoothing yields a regret bound matching the best-known guarantees of one-sided Shampoo. We instantiate this framework with two efficient methods that avoid quadratic projections. The first is an adaptive Follow-the-Perturbed-Leader (FTPL) method using Gaussian stochastic smoothing. The second is Follow-the-Augmented-Matrix-Leader (FAML), which uses a deterministic hyperbolic smoothing in an augmented matrix space. By analyzing the admissibility of these smoothings, we show both methods admit closed-form updates and match one-sided Shampoo's regret up to a constant factor, while significantly reducing computational cost. Lastly, using the online-to-nonconvex conversion, we derive two matrix-based optimizers, Pion (from FTPL) and Leon (from FAML). We prove convergence guarantees for these methods in nonsmooth nonconvex settings, a guarantee that the popular Muon optimizer lacks.
Statistical Learning from Attribution Sets
Feb 06, 2026We address the problem of training conversion prediction models in advertising domains under privacy constraints, where direct links between ad clicks and conversions are unavailable. Motivated by privacy-preserving browser APIs and the deprecation of third-party cookies, we study a setting where the learner observes a sequence of clicks and a sequence of conversions, but can only link a conversion to a set of candidate clicks (an attribution set) rather than a unique source. We formalize this as learning from attribution sets generated by an oblivious adversary equipped with a prior distribution over the candidates. Despite the lack of explicit labels, we construct an unbiased estimator of the population loss from these coarse signals via a novel approach. Leveraging this estimator, we show that Empirical Risk Minimization achieves generalization guarantees that scale with the informativeness of the prior and is also robust against estimation errors in the prior, despite complex dependencies among attribution sets. Simple empirical evaluations on standard datasets suggest our unbiased approach significantly outperforms common industry heuristics, particularly in regimes where attribution sets are large or overlapping.
Online Learning-guided Learning Rate Adaptation via Gradient Alignment
Jun 10, 2025



The performance of an optimizer on large-scale deep learning models depends critically on fine-tuning the learning rate, often requiring an extensive grid search over base learning rates, schedules, and other hyperparameters. In this paper, we propose a principled framework called GALA (Gradient Alignment-based Learning rate Adaptation), which dynamically adjusts the learning rate by tracking the alignment between consecutive gradients and using a local curvature estimate. Guided by the convergence analysis, we formulate the problem of selecting the learning rate as a one-dimensional online learning problem. When paired with an online learning algorithm such as Follow-the-Regularized-Leader, our method produces a flexible, adaptive learning rate schedule that tends to increase when consecutive gradients are aligned and decrease otherwise. We establish a data-adaptive convergence rate for normalized SGD equipped with GALA in the smooth, nonconvex setting. Empirically, common optimizers such as SGD and Adam, when augmented with GALA, demonstrate robust performance across a wide range of initial learning rates and perform competitively without the need for tuning.
Machine Unlearning under Overparameterization
May 28, 2025Machine unlearning algorithms aim to remove the influence of specific training samples, ideally recovering the model that would have resulted from training on the remaining data alone. We study unlearning in the overparameterized setting, where many models interpolate the data, and defining the unlearning solution as any loss minimizer over the retained set$\unicode{x2013}$as in prior work in the underparameterized setting$\unicode{x2013}$is inadequate, since the original model may already interpolate the retained data and satisfy this condition. In this regime, loss gradients vanish, rendering prior methods based on gradient perturbations ineffective, motivating both new unlearning definitions and algorithms. For this setting, we define the unlearning solution as the minimum-complexity interpolator over the retained data and propose a new algorithmic framework that only requires access to model gradients on the retained set at the original solution. We minimize a regularized objective over perturbations constrained to be orthogonal to these model gradients, a first-order relaxation of the interpolation condition. For different model classes, we provide exact and approximate unlearning guarantees, and we demonstrate that an implementation of our framework outperforms existing baselines across various unlearning experiments.
Improved Complexity for Smooth Nonconvex Optimization: A Two-Level Online Learning Approach with Quasi-Newton Methods
Dec 03, 2024We study the problem of finding an $\epsilon$-first-order stationary point (FOSP) of a smooth function, given access only to gradient information. The best-known gradient query complexity for this task, assuming both the gradient and Hessian of the objective function are Lipschitz continuous, is ${O}(\epsilon^{-7/4})$. In this work, we propose a method with a gradient complexity of ${O}(d^{1/4}\epsilon^{-13/8})$, where $d$ is the problem dimension, leading to an improved complexity when $d = {O}(\epsilon^{-1/2})$. To achieve this result, we design an optimization algorithm that, underneath, involves solving two online learning problems. Specifically, we first reformulate the task of finding a stationary point for a nonconvex problem as minimizing the regret in an online convex optimization problem, where the loss is determined by the gradient of the objective function. Then, we introduce a novel optimistic quasi-Newton method to solve this online learning problem, with the Hessian approximation update itself framed as an online learning problem in the space of matrices. Beyond improving the complexity bound for achieving an $\epsilon$-FOSP using a gradient oracle, our result provides the first guarantee suggesting that quasi-Newton methods can potentially outperform gradient descent-type methods in nonconvex settings.
Learning Mixtures of Experts with EM
Nov 09, 2024



Mixtures of Experts (MoE) are Machine Learning models that involve partitioning the input space, with a separate "expert" model trained on each partition. Recently, MoE have become popular as components in today's large language models as a means to reduce training and inference costs. There, the partitioning function and the experts are both learnt jointly via gradient descent on the log-likelihood. In this paper we focus on studying the efficiency of the Expectation Maximization (EM) algorithm for the training of MoE models. We first rigorously analyze EM for the cases of linear or logistic experts, where we show that EM is equivalent to Mirror Descent with unit step size and a Kullback-Leibler Divergence regularizer. This perspective allows us to derive new convergence results and identify conditions for local linear convergence based on the signal-to-noise ratio (SNR). Experiments on synthetic and (small-scale) real-world data show that EM outperforms the gradient descent algorithm both in terms of convergence rate and the achieved accuracy.
Meta-Learning Adaptable Foundation Models
Oct 29, 2024


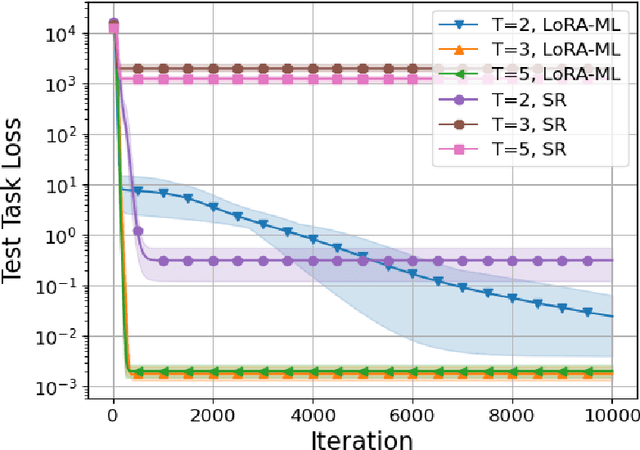
The power of foundation models (FMs) lies in their capacity to learn highly expressive representations that can be adapted to a broad spectrum of tasks. However, these pretrained models require multiple stages of fine-tuning to become effective for downstream applications. Conventionally, the model is first retrained on the aggregate of a diverse set of tasks of interest and then adapted to specific low-resource downstream tasks by utilizing a parameter-efficient fine-tuning (PEFT) scheme. While this two-phase procedure seems reasonable, the independence of the retraining and fine-tuning phases causes a major issue, as there is no guarantee the retrained model will achieve good performance post-fine-tuning. To explicitly address this issue, we introduce a meta-learning framework infused with PEFT in this intermediate retraining stage to learn a model that can be easily adapted to unseen tasks. For our theoretical results, we focus on linear models using low-rank adaptations. In this setting, we demonstrate the suboptimality of standard retraining for finding an adaptable set of parameters. Further, we prove that our method recovers the optimally adaptable parameters. We then apply these theoretical insights to retraining the RoBERTa model to predict the continuation of conversations between different personas within the ConvAI2 dataset. Empirically, we observe significant performance benefits using our proposed meta-learning scheme during retraining relative to the conventional approach.