 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Finding Similar Exercises in Retrieval Manner
Mar 15, 2023



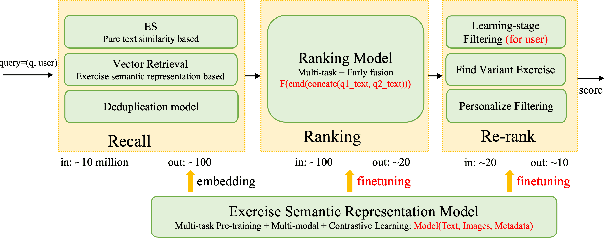
When students make a mistake in an exercise, they can consolidate it by ``similar exercises'' which have the same concepts, purposes and methods. Commonly, for a certain subject and study stage, the size of the exercise bank is in the range of millions to even tens of millions, how to find similar exercises for a given exercise becomes a crucial technical problem. Generally, we can assign a variety of explicit labels to the exercise, and then query through the labels, but the label annotation is time-consuming, laborious and costly, with limited precision and granularity, so it is not feasible. In practice, we define ``similar exercises'' as a retrieval process of finding a set of similar exercises based on recall, ranking and re-rank procedures, called the \textbf{FSE} problem (Finding similar exercises). Furthermore, comprehensive representation of the semantic information of exercises was obtained through representation learning. In addition to the reasonable architecture, we also explore what kind of tasks are more conducive to the learning of exercise semantic information from pre-training and supervised learning. It is difficult to annotate similar exercises and the annotation consistency among experts is low. Therefore this paper also provides solutions to solve the problem of low-quality annotated data. Compared with other methods, this paper has obvious advantages in both architecture rationality and algorithm precision, which now serves the daily teaching of hundreds of schools.
* 37th Conference on AAAI 2023 Artificial Intelligence for Education(AI4Edu)
DORT: Modeling Dynamic Objects in Recurrent for Multi-Camera 3D Object Detection and Tracking
Mar 29, 2023
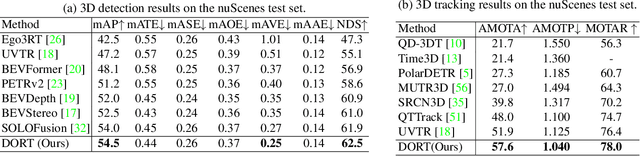
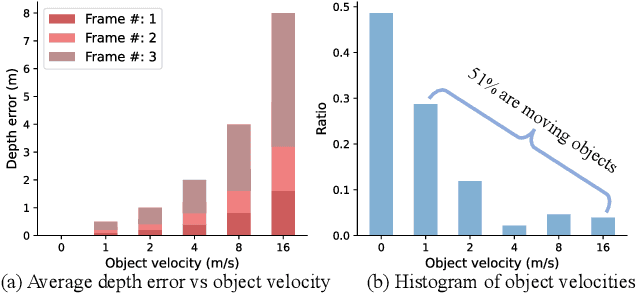
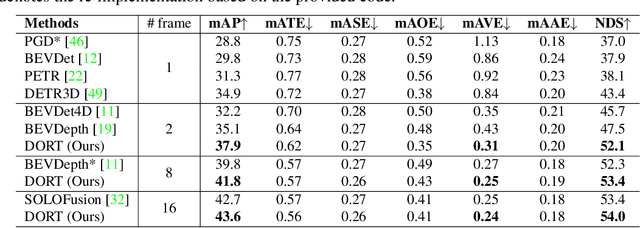
Recent multi-camera 3D object detectors usually leverage temporal information to construct multi-view stereo that alleviates the ill-posed depth estimation. However, they typically assume all the objects are static and directly aggregate features across frames. This work begins with a theoretical and empirical analysis to reveal that ignoring the motion of moving objects can result in serious localization bias. Therefore, we propose to model Dynamic Objects in RecurrenT (DORT) to tackle this problem. In contrast to previous global Bird-Eye-View (BEV) methods, DORT extracts object-wise local volumes for motion estimation that also alleviates the heavy computational burden. By iteratively refining the estimated object motion and location, the preceding features can be precisely aggregated to the current frame to mitigate the aforementioned adverse effects. The simple framework has two significant appealing properties. It is flexible and practical that can be plugged into most camera-based 3D object detectors. As there are predictions of object motion in the loop, it can easily track objects across frames according to their nearest center distances. Without bells and whistles, DORT outperforms all the previous methods on the nuScenes detection and tracking benchmarks with 62.5\% NDS and 57.6\% AMOTA, respectively. The source code will be released.
Self-positioning Point-based Transformer for Point Cloud Understanding
Mar 29, 2023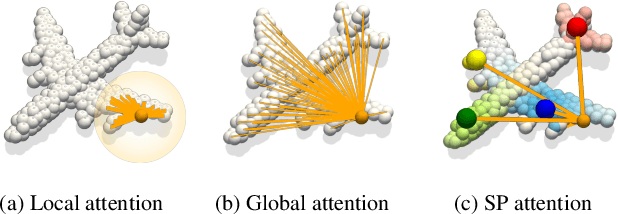
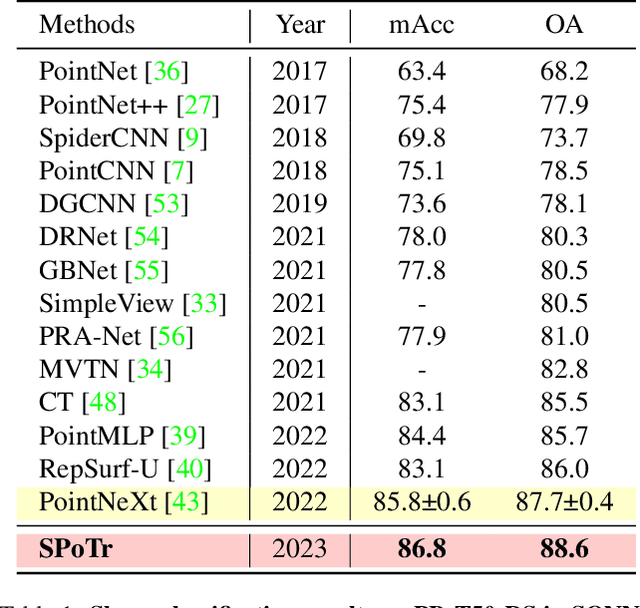
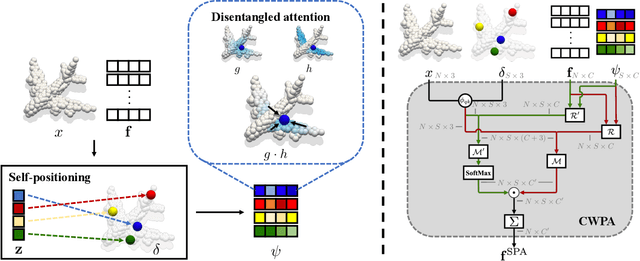
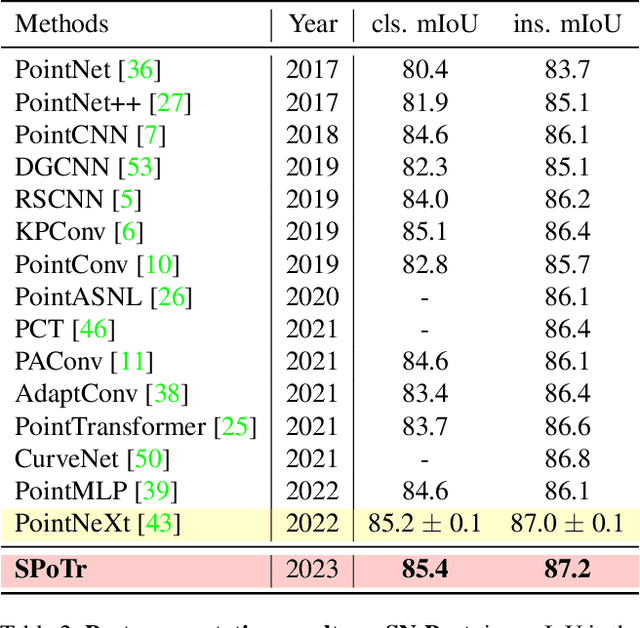
Transformers have shown superior performance on various computer vision tasks with their capabilities to capture long-range dependencies. Despite the success, it is challenging to directly apply Transformers on point clouds due to their quadratic cost in the number of points. In this paper, we present a Self-Positioning point-based Transformer (SPoTr), which is designed to capture both local and global shape contexts with reduced complexity. Specifically, this architecture consists of local self-attention and self-positioning point-based global cross-attention. The self-positioning points, adaptively located based on the input shape, consider both spatial and semantic information with disentangled attention to improve expressive power. With the self-positioning points, we propose a novel global cross-attention mechanism for point clouds, which improves the scalability of global self-attention by allowing the attention module to compute attention weights with only a small set of self-positioning points. Experiments show the effectiveness of SPoTr on three point cloud tasks such as shape classification, part segmentation, and scene segmentation. In particular, our proposed model achieves an accuracy gain of 2.6% over the previous best models on shape classification with ScanObjectNN. We also provide qualitative analyses to demonstrate the interpretability of self-positioning points. The code of SPoTr is available at https://github.com/mlvlab/SPoTr.
Exploring Asymmetric Tunable Blind-Spots for Self-supervised Denoising in Real-World Scenarios
Mar 29, 2023
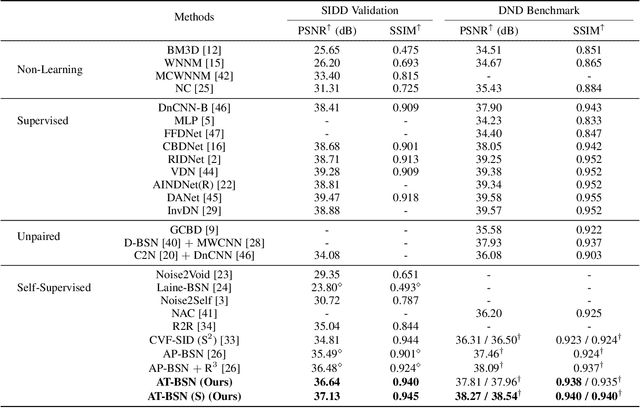
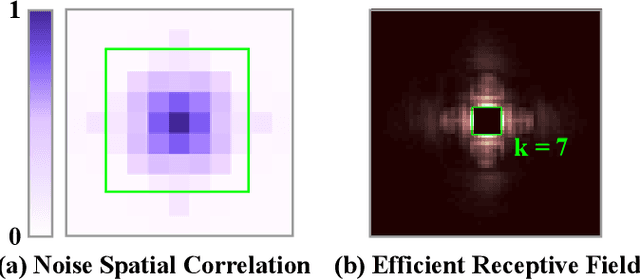
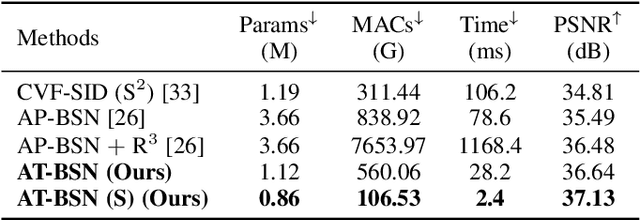
Self-supervised denoising has attracted widespread attention due to its ability to train without clean images. However, noise in real-world scenarios is often spatially correlated, which causes many self-supervised algorithms based on the pixel-wise independent noise assumption to perform poorly on real-world images. Recently, asymmetric pixel-shuffle downsampling (AP) has been proposed to disrupt the spatial correlation of noise. However, downsampling introduces aliasing effects, and the post-processing to eliminate these effects can destroy the spatial structure and high-frequency details of the image, in addition to being time-consuming. In this paper, we systematically analyze downsampling-based methods and propose an Asymmetric Tunable Blind-Spot Network (AT-BSN) to address these issues. We design a blind-spot network with a freely tunable blind-spot size, using a large blind-spot during training to suppress local spatially correlated noise while minimizing damage to the global structure, and a small blind-spot during inference to minimize information loss. Moreover, we propose blind-spot self-ensemble and distillation of non-blind-spot network to further improve performance and reduce computational complexity. Experimental results demonstrate that our method achieves state-of-the-art results while comprehensively outperforming other self-supervised methods in terms of image texture maintaining, parameter count, computation cost, and inference time.
PartManip: Learning Cross-Category Generalizable Part Manipulation Policy from Point Cloud Observations
Mar 29, 2023


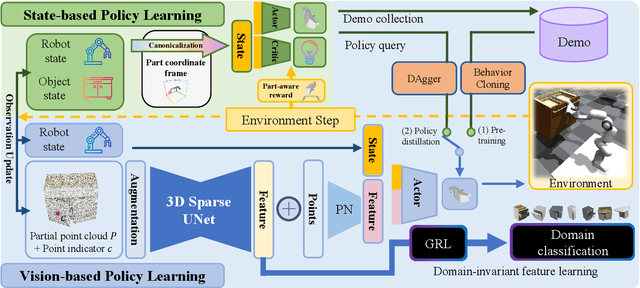
Learning a generalizable object manipulation policy is vital for an embodied agent to work in complex real-world scenes. Parts, as the shared components in different object categories, have the potential to increase the generalization ability of the manipulation policy and achieve cross-category object manipulation. In this work, we build the first large-scale, part-based cross-category object manipulation benchmark, PartManip, which is composed of 11 object categories, 494 objects, and 1432 tasks in 6 task classes. Compared to previous work, our benchmark is also more diverse and realistic, i.e., having more objects and using sparse-view point cloud as input without oracle information like part segmentation. To tackle the difficulties of vision-based policy learning, we first train a state-based expert with our proposed part-based canonicalization and part-aware rewards, and then distill the knowledge to a vision-based student. We also find an expressive backbone is essential to overcome the large diversity of different objects. For cross-category generalization, we introduce domain adversarial learning for domain-invariant feature extraction. Extensive experiments in simulation show that our learned policy can outperform other methods by a large margin, especially on unseen object categories. We also demonstrate our method can successfully manipulate novel objects in the real world.
Compressing Sign Information in DCT-based Image Coding via Deep Sign Retrieval
Sep 21, 2022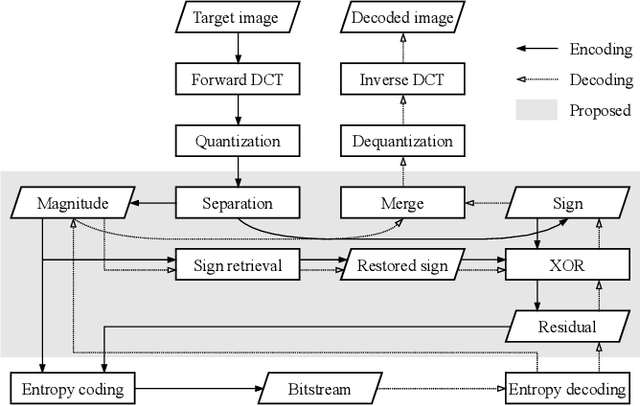

Compressing the sign information of discrete cosine transform (DCT) coefficients is an intractable problem in image coding schemes due to the equiprobable characteristics of the signs. To overcome this difficulty, we propose an efficient compression method for the sign information called "sign retrieval." This method is inspired by phase retrieval, which is a classical signal restoration problem of finding the phase information of discrete Fourier transform coefficients from their magnitudes. The sign information of all DCT coefficients is excluded from a bitstream at the encoder and is complemented at the decoder through our sign retrieval method. We show through experiments that our method outperforms previous ones in terms of the bit amount for the signs and computation cost. Our method, implemented in Python language, is available from https://github.com/ctsutake/dsr.
Temporal Enhanced Training of Multi-view 3D Object Detector via Historical Object Prediction
Apr 03, 2023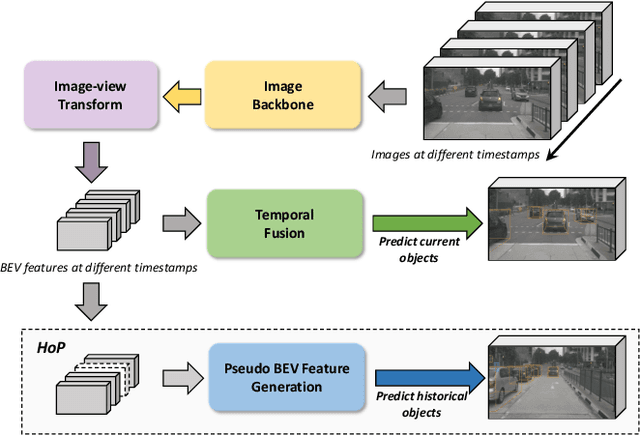
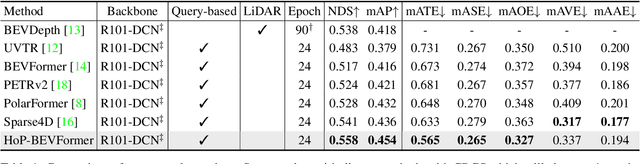
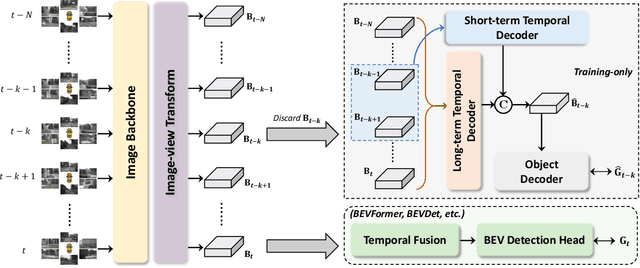
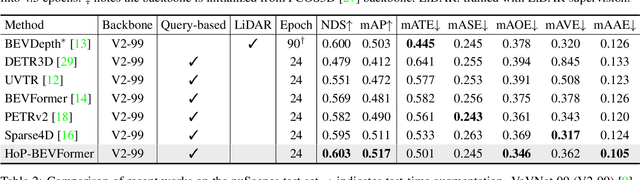
In this paper, we propose a new paradigm, named Historical Object Prediction (HoP) for multi-view 3D detection to leverage temporal information more effectively. The HoP approach is straightforward: given the current timestamp t, we generate a pseudo Bird's-Eye View (BEV) feature of timestamp t-k from its adjacent frames and utilize this feature to predict the object set at timestamp t-k. Our approach is motivated by the observation that enforcing the detector to capture both the spatial location and temporal motion of objects occurring at historical timestamps can lead to more accurate BEV feature learning. First, we elaborately design short-term and long-term temporal decoders, which can generate the pseudo BEV feature for timestamp t-k without the involvement of its corresponding camera images. Second, an additional object decoder is flexibly attached to predict the object targets using the generated pseudo BEV feature. Note that we only perform HoP during training, thus the proposed method does not introduce extra overheads during inference. As a plug-and-play approach, HoP can be easily incorporated into state-of-the-art BEV detection frameworks, including BEVFormer and BEVDet series. Furthermore, the auxiliary HoP approach is complementary to prevalent temporal modeling methods, leading to significant performance gains. Extensive experiments are conducted to evaluate the effectiveness of the proposed HoP on the nuScenes dataset. We choose the representative methods, including BEVFormer and BEVDet4D-Depth to evaluate our method. Surprisingly, HoP achieves 68.5% NDS and 62.4% mAP with ViT-L on nuScenes test, outperforming all the 3D object detectors on the leaderboard. Codes will be available at https://github.com/Sense-X/HoP.
Knowledge Graphs: Opportunities and Challenges
Mar 24, 2023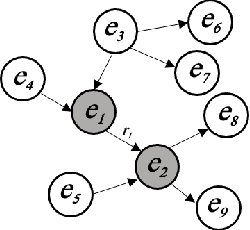
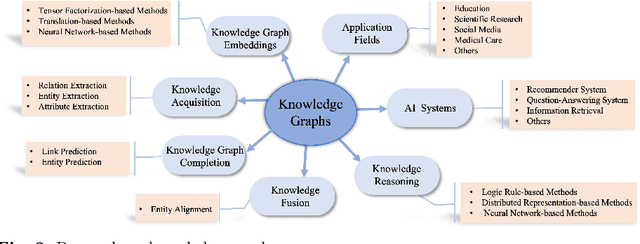
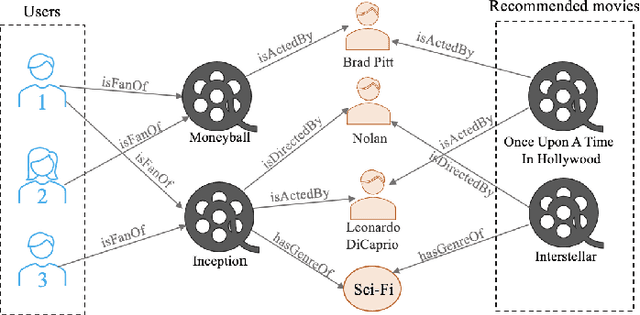
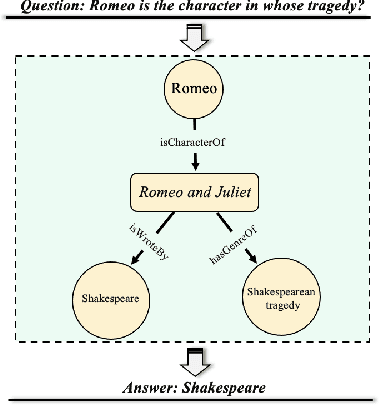
With the explosive growth of artificial intelligence (AI) and big data, it has become vitally important to organize and represent the enormous volume of knowledge appropriately. As graph data, knowledge graphs accumulate and convey knowledge of the real world. It has been well-recognized that knowledge graphs effectively represent complex information; hence, they rapidly gain the attention of academia and industry in recent years. Thus to develop a deeper understanding of knowledge graphs, this paper presents a systematic overview of this field. Specifically, we focus on the opportunities and challenges of knowledge graphs. We first review the opportunities of knowledge graphs in terms of two aspects: (1) AI systems built upon knowledge graphs; (2) potential application fields of knowledge graphs. Then, we thoroughly discuss severe technical challenges in this field, such as knowledge graph embeddings, knowledge acquisition, knowledge graph completion, knowledge fusion, and knowledge reasoning. We expect that this survey will shed new light on future research and the development of knowledge graphs.
Depression detection in social media posts using affective and social norm features
Mar 24, 2023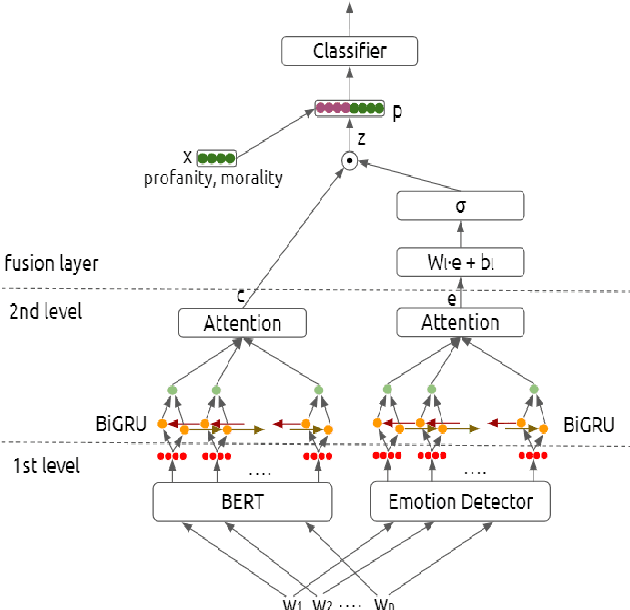


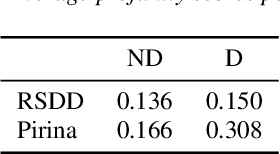
We propose a deep architecture for depression detection from social media posts. The proposed architecture builds upon BERT to extract language representations from social media posts and combines these representations using an attentive bidirectional GRU network. We incorporate affective information, by augmenting the text representations with features extracted from a pretrained emotion classifier. Motivated by psychological literature we propose to incorporate profanity and morality features of posts and words in our architecture using a late fusion scheme. Our analysis indicates that morality and profanity can be important features for depression detection. We apply our model for depression detection on Reddit posts on the Pirina dataset, and further consider the setting of detecting depressed users, given multiple posts per user, proposed in the Reddit RSDD dataset. The inclusion of the proposed features yields state-of-the-art results in both settings, namely 2.65% and 6.73% absolute improvement in F1 score respectively. Index Terms: Depression detection, BERT, Feature fusion, Emotion recognition, profanity, morality
BoPR: Body-aware Part Regressor for Human Shape and Pose Estimation
Mar 24, 2023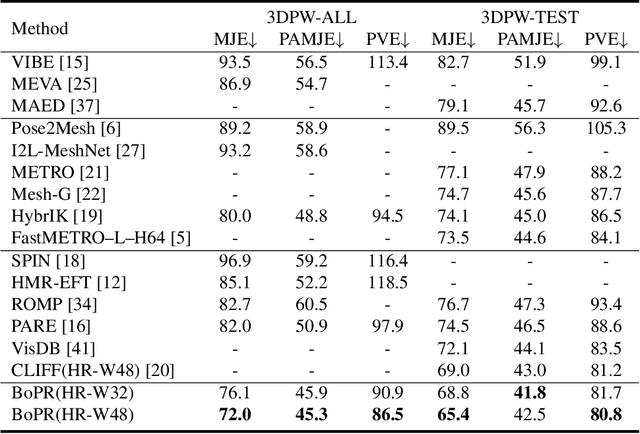
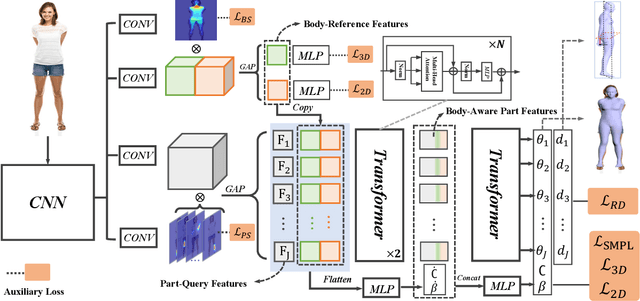
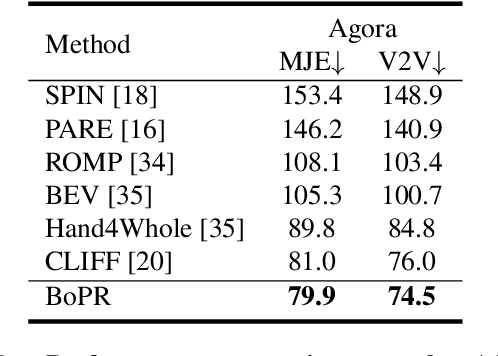
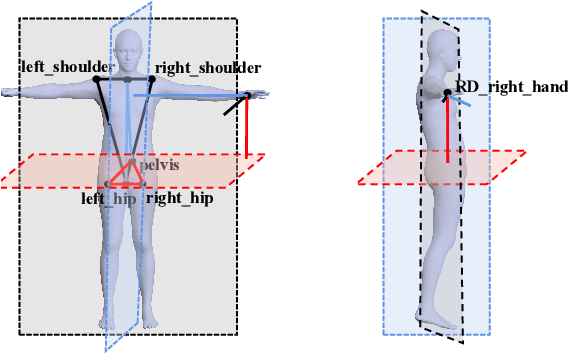
This paper presents a novel approach for estimating human body shape and pose from monocular images that effectively addresses the challenges of occlusions and depth ambiguity. Our proposed method BoPR, the Body-aware Part Regressor, first extracts features of both the body and part regions using an attention-guided mechanism. We then utilize these features to encode extra part-body dependency for per-part regression, with part features as queries and body feature as a reference. This allows our network to infer the spatial relationship of occluded parts with the body by leveraging visible parts and body reference information. Our method outperforms existing state-of-the-art methods on two benchmark datasets, and our experiments show that it significantly surpasses existing methods in terms of depth ambiguity and occlusion handling. These results provide strong evidence of the effectiveness of our approach.The code and data are available for research purposes at https://github.com/cyk990422/BoPR.