 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve Generative ODEs Beyond the Linear Span
Jun 07, 2026Diffusion and flow generative models sample by integrating a learned ODE, but high quality still requires many sequential model evaluations. Solver learning reduces this cost by adapting scalar coefficients, timesteps, or both, while keeping the backbone model fixed. In this work, we identify a structural bottleneck in this update family: each step remains span-limited. Since the scalar-coefficient update lies in the span of buffered velocity evaluations, it can fit only the in-span component while leaving any out-of-span residual unreachable by scalar recombination alone. We propose SpanLift, a lightweight neural solver that augments scalar-coefficient updates with a spatial residual operator. SpanLift keeps a fixed base solver as an in-span prior and learns a spatial residual operator over the state and velocity buffer. The operator is trained by endpoint teacher matching, preserves the pretrained backbone, and adds no model NFEs. Empirically, the learned correction transfers across base solvers and is predominantly out-of-span. Across pixel-space diffusion, latent flow matching, and precipitation nowcasting, SpanLift achieves state-of-the-art few-step sampling. With only 3 NFE, it improves CIFAR-10 FID from 8.16 to 5.69 and ImageNet FID from 17.37 to 11.83.
ST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Mar 26, 2025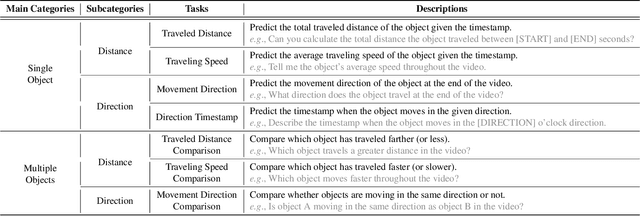

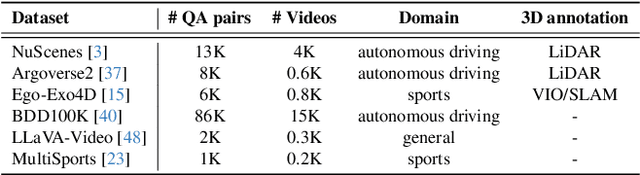
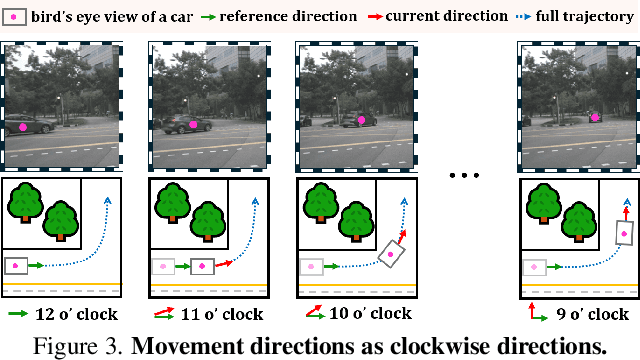
Spatio-temporal reasoning is essential in understanding real-world environments in various fields, eg, autonomous driving and sports analytics. Recent advances have improved the spatial reasoning ability of Vision-Language Models (VLMs) by introducing large-scale data, but these models still struggle to analyze kinematic elements like traveled distance and speed of moving objects. To bridge this gap, we construct a spatio-temporal reasoning dataset and benchmark involving kinematic instruction tuning, referred to as STKit and STKit-Bench. They consist of real-world videos with 3D annotations, detailing object motion dynamics: traveled distance, speed, movement direction, inter-object distance comparisons, and relative movement direction. To further scale such data construction to videos without 3D labels, we propose an automatic pipeline to generate pseudo-labels using 4D reconstruction in real-world scale. With our kinematic instruction tuning data for spatio-temporal reasoning, we present ST-VLM, a VLM enhanced for spatio-temporal reasoning, which exhibits outstanding performance on STKit-Bench. Furthermore, we show that ST-VLM generalizes robustly across diverse domains and tasks, outperforming baselines on other spatio-temporal benchmarks (eg, ActivityNet, TVQA+). Finally, by integrating learned spatio-temporal reasoning with existing abilities, ST-VLM enables complex multi-step reasoning. Project page: https://ikodoh.github.io/ST-VLM.
Constant Acceleration Flow
Nov 01, 2024



Rectified flow and reflow procedures have significantly advanced fast generation by progressively straightening ordinary differential equation (ODE) flows. They operate under the assumption that image and noise pairs, known as couplings, can be approximated by straight trajectories with constant velocity. However, we observe that modeling with constant velocity and using reflow procedures have limitations in accurately learning straight trajectories between pairs, resulting in suboptimal performance in few-step generation. To address these limitations, we introduce Constant Acceleration Flow (CAF), a novel framework based on a simple constant acceleration equation. CAF introduces acceleration as an additional learnable variable, allowing for more expressive and accurate estimation of the ODE flow. Moreover, we propose two techniques to further improve estimation accuracy: initial velocity conditioning for the acceleration model and a reflow process for the initial velocity. Our comprehensive studies on toy datasets, CIFAR-10, and ImageNet 64x64 demonstrate that CAF outperforms state-of-the-art baselines for one-step generation. We also show that CAF dramatically improves few-step coupling preservation and inversion over Rectified flow. Code is available at \href{https://github.com/mlvlab/CAF}{https://github.com/mlvlab/CAF}.
Automated Filtering of Human Feedback Data for Aligning Text-to-Image Diffusion Models
Oct 14, 2024



Fine-tuning text-to-image diffusion models with human feedback is an effective method for aligning model behavior with human intentions. However, this alignment process often suffers from slow convergence due to the large size and noise present in human feedback datasets. In this work, we propose FiFA, a novel automated data filtering algorithm designed to enhance the fine-tuning of diffusion models using human feedback datasets with direct preference optimization (DPO). Specifically, our approach selects data by solving an optimization problem to maximize three components: preference margin, text quality, and text diversity. The concept of preference margin is used to identify samples that contain high informational value to address the noisy nature of feedback dataset, which is calculated using a proxy reward model. Additionally, we incorporate text quality, assessed by large language models to prevent harmful contents, and consider text diversity through a k-nearest neighbor entropy estimator to improve generalization. Finally, we integrate all these components into an optimization process, with approximating the solution by assigning importance score to each data pair and selecting the most important ones. As a result, our method efficiently filters data automatically, without the need for manual intervention, and can be applied to any large-scale dataset. Experimental results show that FiFA significantly enhances training stability and achieves better performance, being preferred by humans 17% more, while using less than 0.5% of the full data and thus 1% of the GPU hours compared to utilizing full human feedback datasets.
Towards Unbiased Evaluation of Detecting Unanswerable Questions in EHRSQL
Apr 29, 2024



Incorporating unanswerable questions into EHR QA systems is crucial for testing the trustworthiness of a system, as providing non-existent responses can mislead doctors in their diagnoses. The EHRSQL dataset stands out as a promising benchmark because it is the only dataset that incorporates unanswerable questions in the EHR QA system alongside practical questions. However, in this work, we identify a data bias in these unanswerable questions; they can often be discerned simply by filtering with specific N-gram patterns. Such biases jeopardize the authenticity and reliability of QA system evaluations. To tackle this problem, we propose a simple debiasing method of adjusting the split between the validation and test sets to neutralize the undue influence of N-gram filtering. By experimenting on the MIMIC-III dataset, we demonstrate both the existing data bias in EHRSQL and the effectiveness of our data split strategy in mitigating this bias.
DDMI: Domain-Agnostic Latent Diffusion Models for Synthesizing High-Quality Implicit Neural Representations
Jan 23, 2024Recent studies have introduced a new class of generative models for synthesizing implicit neural representations (INRs) that capture arbitrary continuous signals in various domains. These models opened the door for domain-agnostic generative models, but they often fail to achieve high-quality generation. We observed that the existing methods generate the weights of neural networks to parameterize INRs and evaluate the network with fixed positional embeddings (PEs). Arguably, this architecture limits the expressive power of generative models and results in low-quality INR generation. To address this limitation, we propose Domain-agnostic Latent Diffusion Model for INRs (DDMI) that generates adaptive positional embeddings instead of neural networks' weights. Specifically, we develop a Discrete-to-continuous space Variational AutoEncoder (D2C-VAE), which seamlessly connects discrete data and the continuous signal functions in the shared latent space. Additionally, we introduce a novel conditioning mechanism for evaluating INRs with the hierarchically decomposed PEs to further enhance expressive power. Extensive experiments across four modalities, e.g., 2D images, 3D shapes, Neural Radiance Fields, and videos, with seven benchmark datasets, demonstrate the versatility of DDMI and its superior performance compared to the existing INR generative models.
Advancing Bayesian Optimization via Learning Correlated Latent Space
Nov 20, 2023



Bayesian optimization is a powerful method for optimizing black-box functions with limited function evaluations. Recent works have shown that optimization in a latent space through deep generative models such as variational autoencoders leads to effective and efficient Bayesian optimization for structured or discrete data. However, as the optimization does not take place in the input space, it leads to an inherent gap that results in potentially suboptimal solutions. To alleviate the discrepancy, we propose Correlated latent space Bayesian Optimization (CoBO), which focuses on learning correlated latent spaces characterized by a strong correlation between the distances in the latent space and the distances within the objective function. Specifically, our method introduces Lipschitz regularization, loss weighting, and trust region recoordination to minimize the inherent gap around the promising areas. We demonstrate the effectiveness of our approach on several optimization tasks in discrete data, such as molecule design and arithmetic expression fitting, and achieve high performance within a small budget.
Explainable Product Classification for Customs
Nov 18, 2023The task of assigning internationally accepted commodity codes (aka HS codes) to traded goods is a critical function of customs offices. Like court decisions made by judges, this task follows the doctrine of precedent and can be nontrivial even for experienced officers. Together with the Korea Customs Service (KCS), we propose a first-ever explainable decision supporting model that suggests the most likely subheadings (i.e., the first six digits) of the HS code. The model also provides reasoning for its suggestion in the form of a document that is interpretable by customs officers. We evaluated the model using 5,000 cases that recently received a classification request. The results showed that the top-3 suggestions made by our model had an accuracy of 93.9\% when classifying 925 challenging subheadings. A user study with 32 customs experts further confirmed that our algorithmic suggestions accompanied by explainable reasonings, can substantially reduce the time and effort taken by customs officers for classification reviews.
Fine tuning Pre trained Models for Robustness Under Noisy Labels
Oct 24, 2023



The presence of noisy labels in a training dataset can significantly impact the performance of machine learning models. To tackle this issue, researchers have explored methods for Learning with Noisy Labels to identify clean samples and reduce the influence of noisy labels. However, constraining the influence of a certain portion of the training dataset can result in a reduction in overall generalization performance. To alleviate this, recent studies have considered the careful utilization of noisy labels by leveraging huge computational resources. Therefore, the increasing training cost necessitates a reevaluation of efficiency. In other areas of research, there has been a focus on developing fine-tuning techniques for large pre-trained models that aim to achieve both high generalization performance and efficiency. However, these methods have mainly concentrated on clean datasets, and there has been limited exploration of the noisy label scenario. In this research, our aim is to find an appropriate way to fine-tune pre-trained models for noisy labeled datasets. To achieve this goal, we investigate the characteristics of pre-trained models when they encounter noisy datasets. Through empirical analysis, we introduce a novel algorithm called TURN, which robustly and efficiently transfers the prior knowledge of pre-trained models. The algorithm consists of two main steps: (1) independently tuning the linear classifier to protect the feature extractor from being distorted by noisy labels, and (2) reducing the noisy label ratio and fine-tuning the entire model based on the noise-reduced dataset to adapt it to the target dataset. The proposed algorithm has been extensively tested and demonstrates efficient yet improved denoising performance on various benchmarks compared to previous methods.
Semantic-Aware Implicit Template Learning via Part Deformation Consistency
Aug 23, 2023



Learning implicit templates as neural fields has recently shown impressive performance in unsupervised shape correspondence. Despite the success, we observe current approaches, which solely rely on geometric information, often learn suboptimal deformation across generic object shapes, which have high structural variability. In this paper, we highlight the importance of part deformation consistency and propose a semantic-aware implicit template learning framework to enable semantically plausible deformation. By leveraging semantic prior from a self-supervised feature extractor, we suggest local conditioning with novel semantic-aware deformation code and deformation consistency regularizations regarding part deformation, global deformation, and global scaling. Our extensive experiments demonstrate the superiority of the proposed method over baselines in various tasks: keypoint transfer, part label transfer, and texture transfer. More interestingly, our framework shows a larger performance gain under more challenging settings. We also provide qualitative analyses to validate the effectiveness of semantic-aware deformation. The code is available at https://github.com/mlvlab/PDC.