 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocPrune:Efficient Document Question Answering via Background, Question, and Comprehension-aware Token Pruning
Apr 24, 2026Recent advances in vision-language models have demonstrated remarkable performance across diverse multi-modal tasks, including document question answering that leverages structured visual cues from text, tables, and figures. However, unlike natural images, document images contain large backgrounds and only sparse supporting evidence, leading to the inefficient consumption of substantial computational resources, especially for long documents. We observe that existing token-reduction methods for natural images and videos fall short in utilizing the structural sparsity unique to documents. To address this, we propose DocPrune, a training-free and progressive document token pruning framework designed for efficient long-document understanding. The proposed method preserves only the essential tokens for the task while removing unnecessary ones, such as background or question-irrelevant tokens. Moreover, it automatically selects the appropriate layers to initiate token pruning based on the model's level of comprehension. Our experiments on the M3DocRAG show that DocPrune improves throughput by 3.0x and 3.3x in the encoder and decoder, respectively, while boosting the F1 score by +1.0, achieving both higher accuracy and efficiency without any additional training.
MoE-GRPO: Optimizing Mixture-of-Experts via Reinforcement Learning in Vision-Language Models
Mar 26, 2026Mixture-of-Experts (MoE) has emerged as an effective approach to reduce the computational overhead of Transformer architectures by sparsely activating a subset of parameters for each token while preserving high model capacity. This paradigm has recently been extended to Vision-Language Models (VLMs), enabling scalable multi-modal understanding with reduced computational cost. However, the widely adopted deterministic top-K routing mechanism may overlook more optimal expert combinations and lead to expert overfitting. To address this limitation and improve the diversity of expert selection, we propose MoE-GRPO, a reinforcement learning (RL)-based framework for optimizing expert routing in MoE-based VLMs. Specifically, we formulate expert selection as a sequential decision-making problem and optimize it using Group Relative Policy Optimization (GRPO), allowing the model to learn adaptive expert routing policies through exploration and reward-based feedback. Furthermore, we introduce a modality-aware router guidance that enhances training stability and efficiency by discouraging the router from exploring experts that are infrequently activated for a given modality. Extensive experiments on multi-modal image and video benchmarks show that MoE-GRPO consistently outperforms standard top-K routing and its variants by promoting more diverse expert selection, thereby mitigating expert overfitting and enabling a task-level expert specialization.
ProGraph-R1: Progress-aware Reinforcement Learning for Graph Retrieval Augmented Generation
Jan 25, 2026Graph Retrieval-Augmented Generation (GraphRAG) has been successfully applied in various knowledge-intensive question answering tasks by organizing external knowledge into structured graphs of entities and relations. It enables large language models (LLMs) to perform complex reasoning beyond text-chunk retrieval. Recent works have employed reinforcement learning (RL) to train agentic GraphRAG frameworks that perform iterative interactions between LLMs and knowledge graphs. However, existing RL-based frameworks such as Graph-R1 suffer from two key limitations: (1) they primarily depend on semantic similarity for retrieval, often overlooking the underlying graph structure, and (2) they rely on sparse, outcome-level rewards, failing to capture the quality of intermediate retrieval steps and their dependencies. To address these limitations, we propose ProGraph-R1, a progress-aware agentic framework for graph-based retrieval and multi-step reasoning. ProGraph-R1 introduces a structure-aware hypergraph retrieval mechanism that jointly considers semantic relevance and graph connectivity, encouraging coherent traversal along multi-hop reasoning paths. We also design a progress-based step-wise policy optimization, which provides dense learning signals by modulating advantages according to intermediate reasoning progress within a graph, rather than relying solely on final outcomes. Experiments on multi-hop question answering benchmarks demonstrate that ProGraph-R1 consistently improves reasoning accuracy and generation quality over existing GraphRAG methods.
TabFlash: Efficient Table Understanding with Progressive Question Conditioning and Token Focusing
Nov 17, 2025Table images present unique challenges for effective and efficient understanding due to the need for question-specific focus and the presence of redundant background regions. Existing Multimodal Large Language Model (MLLM) approaches often overlook these characteristics, resulting in uninformative and redundant visual representations. To address these issues, we aim to generate visual features that are both informative and compact to improve table understanding. We first propose progressive question conditioning, which injects the question into Vision Transformer layers with gradually increasing frequency, considering each layer's capacity to handle additional information, to generate question-aware visual features. To reduce redundancy, we introduce a pruning strategy that discards background tokens, thereby improving efficiency. To mitigate information loss from pruning, we further propose token focusing, a training strategy that encourages the model to concentrate essential information in the retained tokens. By combining these approaches, we present TabFlash, an efficient and effective MLLM for table understanding. TabFlash achieves state-of-the-art performance, outperforming both open-source and proprietary MLLMs, while requiring 27% less FLOPs and 30% less memory usage compared to the second-best MLLM.
Transferable Model-agnostic Vision-Language Model Adaptation for Efficient Weak-to-Strong Generalization
Aug 13, 2025



Vision-Language Models (VLMs) have been widely used in various visual recognition tasks due to their remarkable generalization capabilities. As these models grow in size and complexity, fine-tuning becomes costly, emphasizing the need to reuse adaptation knowledge from 'weaker' models to efficiently enhance 'stronger' ones. However, existing adaptation transfer methods exhibit limited transferability across models due to their model-specific design and high computational demands. To tackle this, we propose Transferable Model-agnostic adapter (TransMiter), a light-weight adapter that improves vision-language models 'without backpropagation'. TransMiter captures the knowledge gap between pre-trained and fine-tuned VLMs, in an 'unsupervised' manner. Once trained, this knowledge can be seamlessly transferred across different models without the need for backpropagation. Moreover, TransMiter consists of only a few layers, inducing a negligible additional inference cost. Notably, supplementing the process with a few labeled data further yields additional performance gain, often surpassing a fine-tuned stronger model, with a marginal training cost. Experimental results and analyses demonstrate that TransMiter effectively and efficiently transfers adaptation knowledge while preserving generalization abilities across VLMs of different sizes and architectures in visual recognition tasks.
EfficientViM: Efficient Vision Mamba with Hidden State Mixer based State Space Duality
Nov 22, 2024



For the deployment of neural networks in resource-constrained environments, prior works have built lightweight architectures with convolution and attention for capturing local and global dependencies, respectively. Recently, the state space model has emerged as an effective global token interaction with its favorable linear computational cost in the number of tokens. Yet, efficient vision backbones built with SSM have been explored less. In this paper, we introduce Efficient Vision Mamba (EfficientViM), a novel architecture built on hidden state mixer-based state space duality (HSM-SSD) that efficiently captures global dependencies with further reduced computational cost. In the HSM-SSD layer, we redesign the previous SSD layer to enable the channel mixing operation within hidden states. Additionally, we propose multi-stage hidden state fusion to further reinforce the representation power of hidden states, and provide the design alleviating the bottleneck caused by the memory-bound operations. As a result, the EfficientViM family achieves a new state-of-the-art speed-accuracy trade-off on ImageNet-1k, offering up to a 0.7% performance improvement over the second-best model SHViT with faster speed. Further, we observe significant improvements in throughput and accuracy compared to prior works, when scaling images or employing distillation training. Code is available at https://github.com/mlvlab/EfficientViM.
Robust Multimodal 3D Object Detection via Modality-Agnostic Decoding and Proximity-based Modality Ensemble
Jul 27, 2024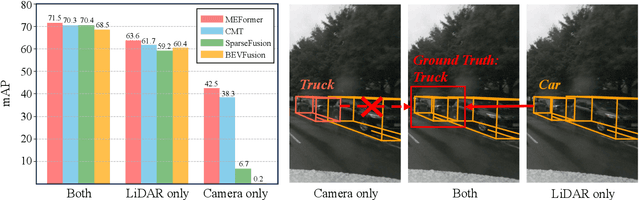



Recent advancements in 3D object detection have benefited from multi-modal information from the multi-view cameras and LiDAR sensors. However, the inherent disparities between the modalities pose substantial challenges. We observe that existing multi-modal 3D object detection methods heavily rely on the LiDAR sensor, treating the camera as an auxiliary modality for augmenting semantic details. This often leads to not only underutilization of camera data but also significant performance degradation in scenarios where LiDAR data is unavailable. Additionally, existing fusion methods overlook the detrimental impact of sensor noise induced by environmental changes, on detection performance. In this paper, we propose MEFormer to address the LiDAR over-reliance problem by harnessing critical information for 3D object detection from every available modality while concurrently safeguarding against corrupted signals during the fusion process. Specifically, we introduce Modality Agnostic Decoding (MOAD) that extracts geometric and semantic features with a shared transformer decoder regardless of input modalities and provides promising improvement with a single modality as well as multi-modality. Additionally, our Proximity-based Modality Ensemble (PME) module adaptively utilizes the strengths of each modality depending on the environment while mitigating the effects of a noisy sensor. Our MEFormer achieves state-of-the-art performance of 73.9% NDS and 71.5% mAP in the nuScenes validation set. Extensive analyses validate that our MEFormer improves robustness against challenging conditions such as sensor malfunctions or environmental changes. The source code is available at https://github.com/hanchaa/MEFormer
Multi-criteria Token Fusion with One-step-ahead Attention for Efficient Vision Transformers
Apr 01, 2024



Vision Transformer (ViT) has emerged as a prominent backbone for computer vision. For more efficient ViTs, recent works lessen the quadratic cost of the self-attention layer by pruning or fusing the redundant tokens. However, these works faced the speed-accuracy trade-off caused by the loss of information. Here, we argue that token fusion needs to consider diverse relations between tokens to minimize information loss. In this paper, we propose a Multi-criteria Token Fusion (MCTF), that gradually fuses the tokens based on multi-criteria (e.g., similarity, informativeness, and size of fused tokens). Further, we utilize the one-step-ahead attention, which is the improved approach to capture the informativeness of the tokens. By training the model equipped with MCTF using a token reduction consistency, we achieve the best speed-accuracy trade-off in the image classification (ImageNet1K). Experimental results prove that MCTF consistently surpasses the previous reduction methods with and without training. Specifically, DeiT-T and DeiT-S with MCTF reduce FLOPs by about 44% while improving the performance (+0.5%, and +0.3%) over the base model, respectively. We also demonstrate the applicability of MCTF in various Vision Transformers (e.g., T2T-ViT, LV-ViT), achieving at least 31% speedup without performance degradation. Code is available at https://github.com/mlvlab/MCTF.
vid-TLDR: Training Free Token merging for Light-weight Video Transformer
Mar 30, 2024



Video Transformers have become the prevalent solution for various video downstream tasks with superior expressive power and flexibility. However, these video transformers suffer from heavy computational costs induced by the massive number of tokens across the entire video frames, which has been the major barrier to training the model. Further, the patches irrelevant to the main contents, e.g., backgrounds, degrade the generalization performance of models. To tackle these issues, we propose training free token merging for lightweight video Transformer (vid-TLDR) that aims to enhance the efficiency of video Transformers by merging the background tokens without additional training. For vid-TLDR, we introduce a novel approach to capture the salient regions in videos only with the attention map. Further, we introduce the saliency-aware token merging strategy by dropping the background tokens and sharpening the object scores. Our experiments show that vid-TLDR significantly mitigates the computational complexity of video Transformers while achieving competitive performance compared to the base model without vid-TLDR. Code is available at https://github.com/mlvlab/vid-TLDR.
Read-only Prompt Optimization for Vision-Language Few-shot Learning
Aug 29, 2023



In recent years, prompt tuning has proven effective in adapting pre-trained vision-language models to downstream tasks. These methods aim to adapt the pre-trained models by introducing learnable prompts while keeping pre-trained weights frozen. However, learnable prompts can affect the internal representation within the self-attention module, which may negatively impact performance variance and generalization, especially in data-deficient settings. To address these issues, we propose a novel approach, Read-only Prompt Optimization (RPO). RPO leverages masked attention to prevent the internal representation shift in the pre-trained model. Further, to facilitate the optimization of RPO, the read-only prompts are initialized based on special tokens of the pre-trained model. Our extensive experiments demonstrate that RPO outperforms CLIP and CoCoOp in base-to-new generalization and domain generalization while displaying better robustness. Also, the proposed method achieves better generalization on extremely data-deficient settings, while improving parameter efficiency and computational overhead. Code is available at https://github.com/mlvlab/RPO.