 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SHERF: Generalizable Human NeRF from a Single Image
Mar 22, 2023
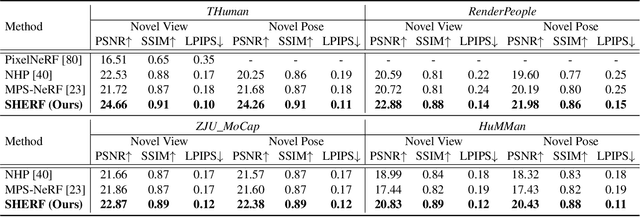
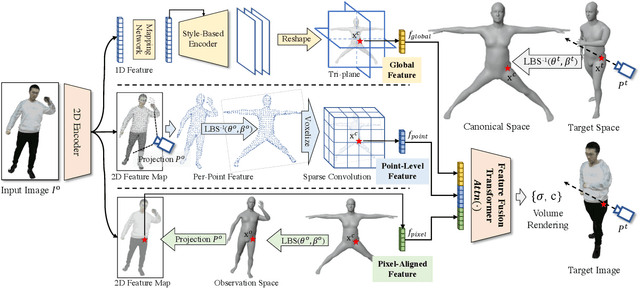
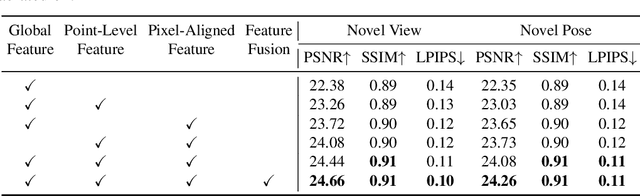

Existing Human NeRF methods for reconstructing 3D humans typically rely on multiple 2D images from multi-view cameras or monocular videos captured from fixed camera views. However, in real-world scenarios, human images are often captured from random camera angles, presenting challenges for high-quality 3D human reconstruction. In this paper, we propose SHERF, the first generalizable Human NeRF model for recovering animatable 3D humans from a single input image. SHERF extracts and encodes 3D human representations in canonical space, enabling rendering and animation from free views and poses. To achieve high-fidelity novel view and pose synthesis, the encoded 3D human representations should capture both global appearance and local fine-grained textures. To this end, we propose a bank of 3D-aware hierarchical features, including global, point-level, and pixel-aligned features, to facilitate informative encoding. Global features enhance the information extracted from the single input image and complement the information missing from the partial 2D observation. Point-level features provide strong clues of 3D human structure, while pixel-aligned features preserve more fine-grained details. To effectively integrate the 3D-aware hierarchical feature bank, we design a feature fusion transformer. Extensive experiments on THuman, RenderPeople, ZJU_MoCap, and HuMMan datasets demonstrate that SHERF achieves state-of-the-art performance, with better generalizability for novel view and pose synthesis.
Large Language Models Can Be Used to Estimate the Ideologies of Politicians in a Zero-Shot Learning Setting
Mar 22, 2023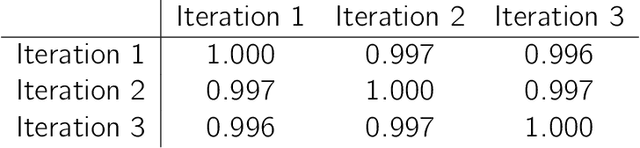
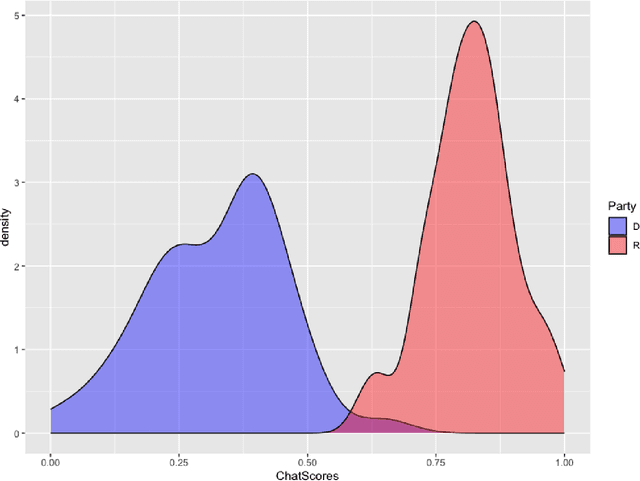
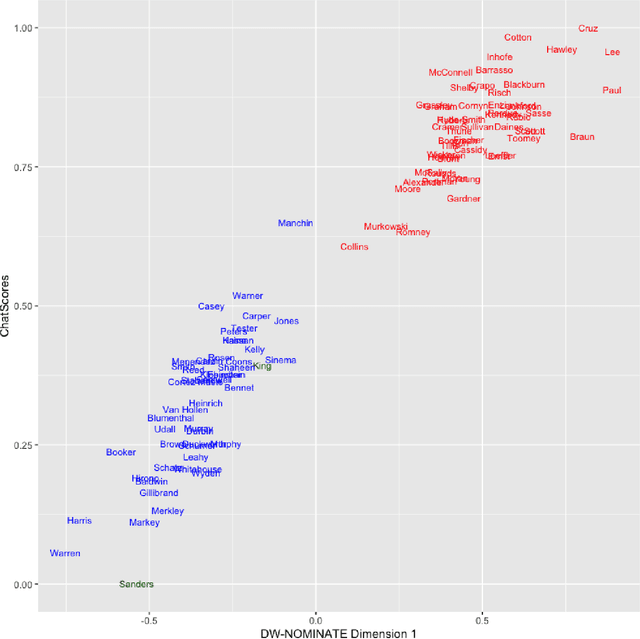
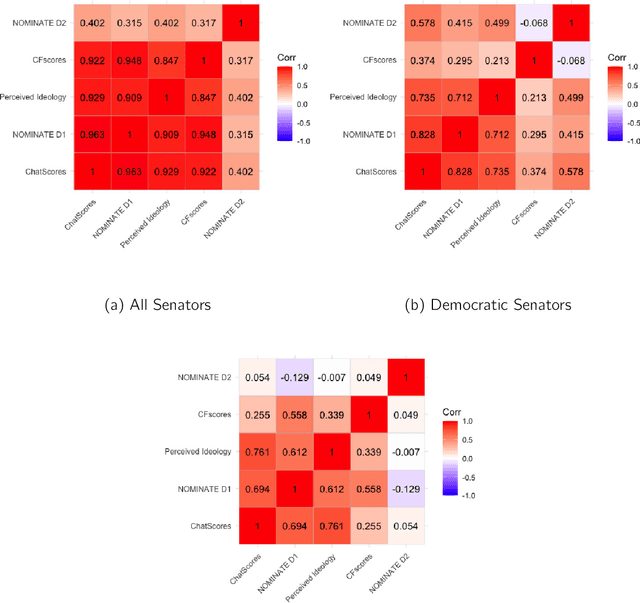
The mass aggregation of knowledge embedded in large language models (LLMs) holds the promise of new solutions to problems of observability and measurement in the social sciences. We examine the utility of one such model for a particularly difficult measurement task: measuring the latent ideology of lawmakers, which allows us to better understand functions that are core to democracy, such as how politics shape policy and how political actors represent their constituents. We scale the senators of the 116th United States Congress along the liberal-conservative spectrum by prompting ChatGPT to select the more liberal (or conservative) senator in pairwise comparisons. We show that the LLM produced stable answers across repeated iterations, did not hallucinate, and was not simply regurgitating information from a single source. This new scale strongly correlates with pre-existing liberal-conservative scales such as NOMINATE, but also differs in several important ways, such as correctly placing senators who vote against their party for far-left or far-right ideological reasons on the extreme ends. The scale also highly correlates with ideological measures based on campaign giving and political activists' perceptions of these senators. In addition to the potential for better-automated data collection and information retrieval, our results suggest LLMs are likely to open new avenues for measuring latent constructs like ideology that rely on aggregating large quantities of data from public sources.
Core-Periphery Principle Guided Redesign of Self-Attention in Transformers
Mar 27, 2023

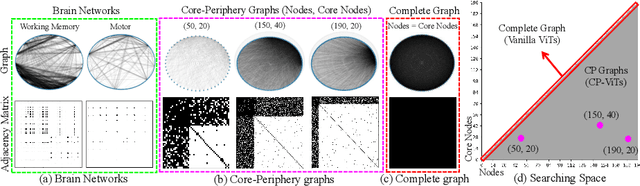

Designing more efficient, reliable, and explainable neural network architectures is critical to studies that are based on artificial intelligence (AI) techniques. Previous studies, by post-hoc analysis, have found that the best-performing ANNs surprisingly resemble biological neural networks (BNN), which indicates that ANNs and BNNs may share some common principles to achieve optimal performance in either machine learning or cognitive/behavior tasks. Inspired by this phenomenon, we proactively instill organizational principles of BNNs to guide the redesign of ANNs. We leverage the Core-Periphery (CP) organization, which is widely found in human brain networks, to guide the information communication mechanism in the self-attention of vision transformer (ViT) and name this novel framework as CP-ViT. In CP-ViT, the attention operation between nodes is defined by a sparse graph with a Core-Periphery structure (CP graph), where the core nodes are redesigned and reorganized to play an integrative role and serve as a center for other periphery nodes to exchange information. We evaluated the proposed CP-ViT on multiple public datasets, including medical image datasets (INbreast) and natural image datasets. Interestingly, by incorporating the BNN-derived principle (CP structure) into the redesign of ViT, our CP-ViT outperforms other state-of-the-art ANNs. In general, our work advances the state of the art in three aspects: 1) This work provides novel insights for brain-inspired AI: we can utilize the principles found in BNNs to guide and improve our ANN architecture design; 2) We show that there exist sweet spots of CP graphs that lead to CP-ViTs with significantly improved performance; and 3) The core nodes in CP-ViT correspond to task-related meaningful and important image patches, which can significantly enhance the interpretability of the trained deep model.
EgoViT: Pyramid Video Transformer for Egocentric Action Recognition
Mar 15, 2023
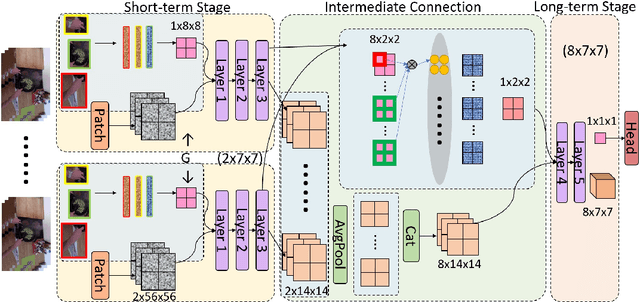


Capturing interaction of hands with objects is important to autonomously detect human actions from egocentric videos. In this work, we present a pyramid video transformer with a dynamic class token generator for egocentric action recognition. Different from previous video transformers, which use the same static embedding as the class token for diverse inputs, we propose a dynamic class token generator that produces a class token for each input video by analyzing the hand-object interaction and the related motion information. The dynamic class token can diffuse such information to the entire model by communicating with other informative tokens in the subsequent transformer layers. With the dynamic class token, dissimilarity between videos can be more prominent, which helps the model distinguish various inputs. In addition, traditional video transformers explore temporal features globally, which requires large amounts of computation. However, egocentric videos often have a large amount of background scene transition, which causes discontinuities across distant frames. In this case, blindly reducing the temporal sampling rate will risk losing crucial information. Hence, we also propose a pyramid architecture to hierarchically process the video from short-term high rate to long-term low rate. With the proposed architecture, we significantly reduce the computational cost as well as the memory requirement without sacrificing from the model performance. We perform comparisons with different baseline video transformers on the EPIC-KITCHENS-100 and EGTEA Gaze+ datasets. Both quantitative and qualitative results show that the proposed model can efficiently improve the performance for egocentric action recognition.
Partial Mobilization: Tracking Multilingual Information Flows Amongst Russian Media Outlets and Telegram
Jan 25, 2023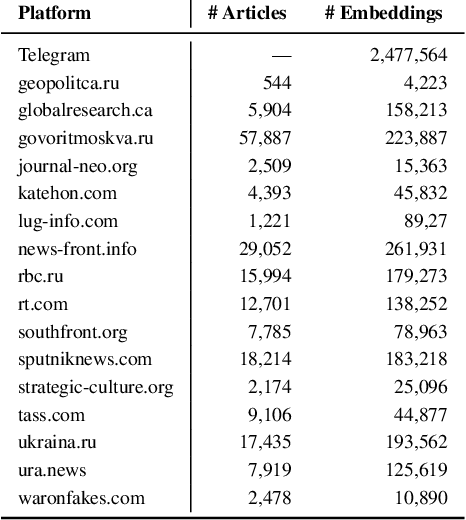
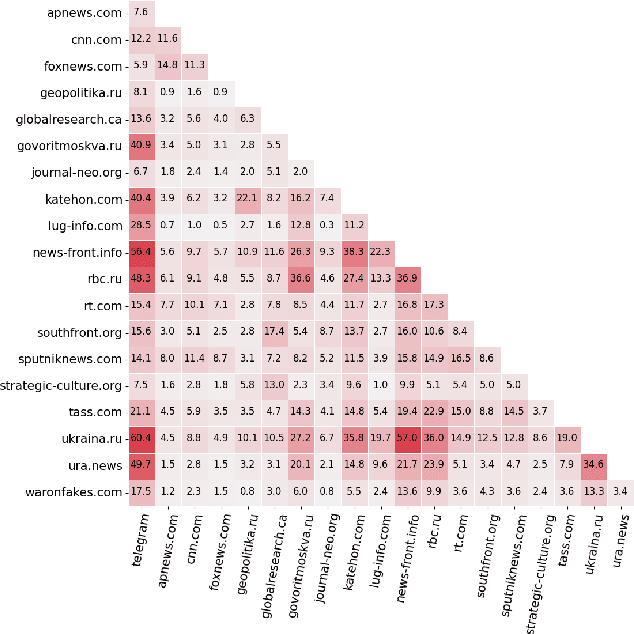
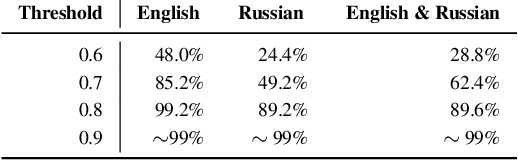

In response to disinformation and propaganda from Russian online media following the Russian invasion of Ukraine, Russian outlets including Russia Today and Sputnik News were banned throughout Europe. Many of these Russian outlets, in order to reach their audiences, began to heavily promote their content on messaging services like Telegram. In this work, to understand this phenomenon, we study how 16 Russian media outlets have interacted with and utilized 732 Telegram channels throughout 2022. To do this, we utilize a multilingual version of the foundational model MPNet to embed articles and Telegram messages in a shared embedding space and semantically compare content. Leveraging a parallelized version of DP-Means clustering, we perform paragraph-level topic/narrative extraction and time-series analysis with Hawkes Processes. With this approach, across our websites, we find between 2.3% (ura.news) and 26.7% (ukraina.ru) of their content originated/resulted from activity on Telegram. Finally, tracking the spread of individual narratives, we measure the rate at which these websites and channels disseminate content within the Russian media ecosystem.
TextIR: A Simple Framework for Text-based Editable Image Restoration
Feb 28, 2023
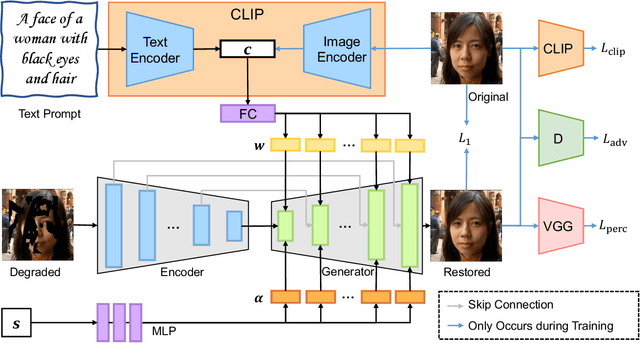
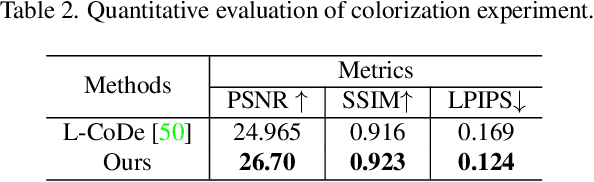

Most existing image restoration methods use neural networks to learn strong image-level priors from huge data to estimate the lost information. However, these works still struggle in cases when images have severe information deficits. Introducing external priors or using reference images to provide information also have limitations in the application domain. In contrast, text input is more readily available and provides information with higher flexibility. In this work, we design an effective framework that allows the user to control the restoration process of degraded images with text descriptions. We use the text-image feature compatibility of the CLIP to alleviate the difficulty of fusing text and image features. Our framework can be used for various image restoration tasks, including image inpainting, image super-resolution, and image colorization. Extensive experiments demonstrate the effectiveness of our method.
APPT : Asymmetric Parallel Point Transformer for 3D Point Cloud Understanding
Mar 31, 2023
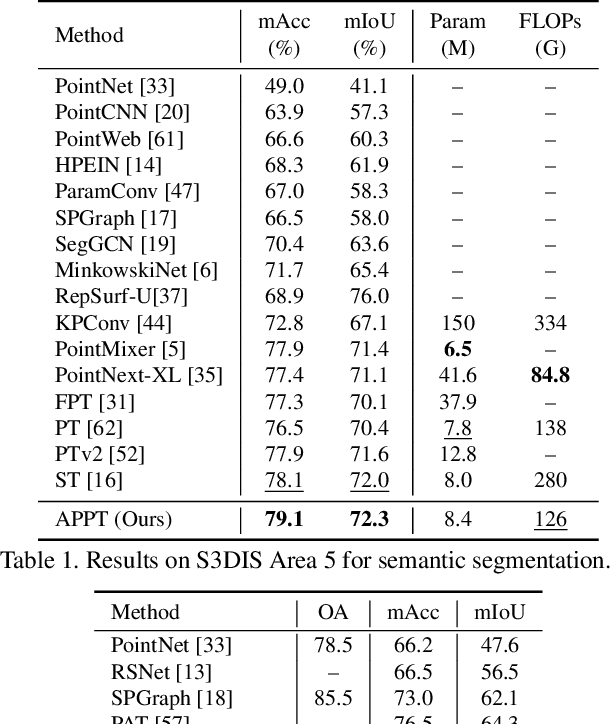
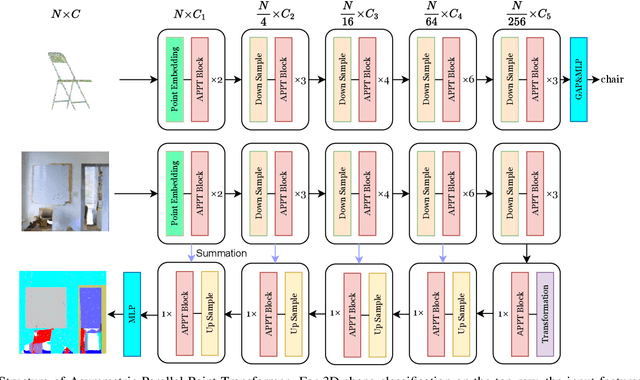
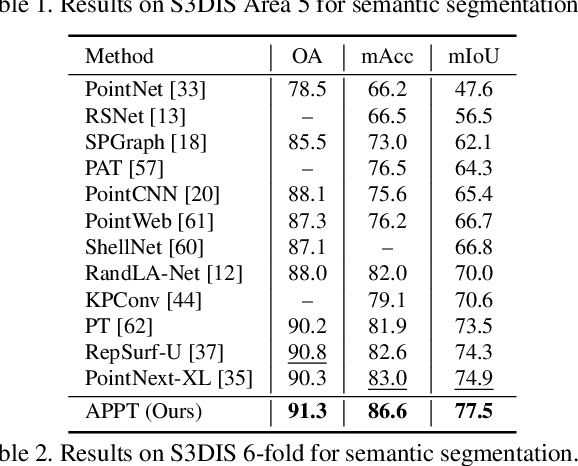
Transformer-based networks have achieved impressive performance in 3D point cloud understanding. However, most of them concentrate on aggregating local features, but neglect to directly model global dependencies, which results in a limited effective receptive field. Besides, how to effectively incorporate local and global components also remains challenging. To tackle these problems, we propose Asymmetric Parallel Point Transformer (APPT). Specifically, we introduce Global Pivot Attention to extract global features and enlarge the effective receptive field. Moreover, we design the Asymmetric Parallel structure to effectively integrate local and global information. Combined with these designs, APPT is able to capture features globally throughout the entire network while focusing on local-detailed features. Extensive experiments show that our method outperforms the priors and achieves state-of-the-art on several benchmarks for 3D point cloud understanding, such as 3D semantic segmentation on S3DIS, 3D shape classification on ModelNet40, and 3D part segmentation on ShapeNet.
Dataset and Baseline System for Multi-lingual Extraction and Normalization of Temporal and Numerical Expressions
Mar 31, 2023

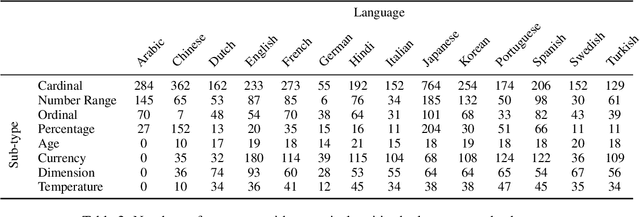
Temporal and numerical expression understanding is of great importance in many downstream Natural Language Processing (NLP) and Information Retrieval (IR) tasks. However, much previous work covers only a few sub-types and focuses only on entity extraction, which severely limits the usability of identified mentions. In order for such entities to be useful in downstream scenarios, coverage and granularity of sub-types are important; and, even more so, providing resolution into concrete values that can be manipulated. Furthermore, most previous work addresses only a handful of languages. Here we describe a multi-lingual evaluation dataset - NTX - covering diverse temporal and numerical expressions across 14 languages and covering extraction, normalization, and resolution. Along with the dataset we provide a robust rule-based system as a strong baseline for comparisons against other models to be evaluated in this dataset. Data and code are available at \url{https://aka.ms/NTX}.
Incorporating Relevance Feedback for Information-Seeking Retrieval using Few-Shot Document Re-Ranking
Oct 19, 2022
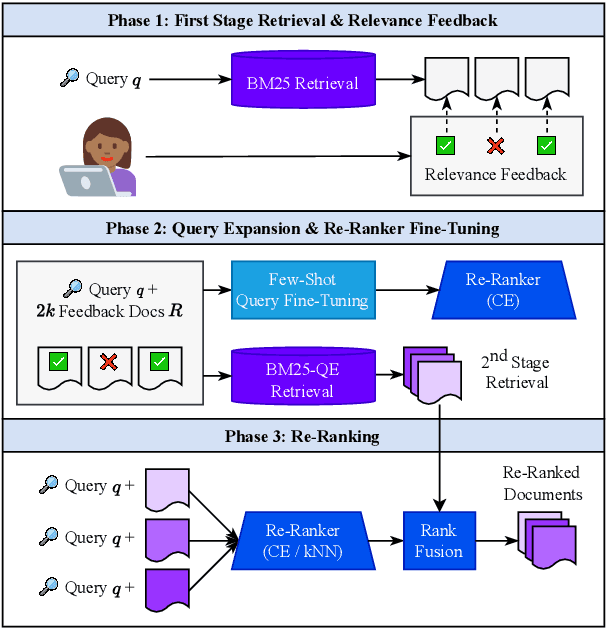
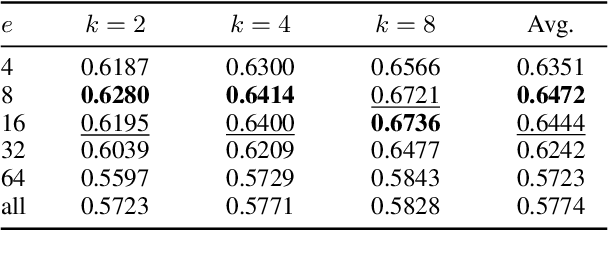
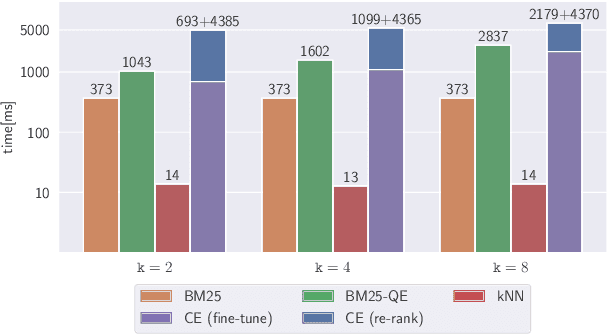
Pairing a lexical retriever with a neural re-ranking model has set state-of-the-art performance on large-scale information retrieval datasets. This pipeline covers scenarios like question answering or navigational queries, however, for information-seeking scenarios, users often provide information on whether a document is relevant to their query in form of clicks or explicit feedback. Therefore, in this work, we explore how relevance feedback can be directly integrated into neural re-ranking models by adopting few-shot and parameter-efficient learning techniques. Specifically, we introduce a kNN approach that re-ranks documents based on their similarity with the query and the documents the user considers relevant. Further, we explore Cross-Encoder models that we pre-train using meta-learning and subsequently fine-tune for each query, training only on the feedback documents. To evaluate our different integration strategies, we transform four existing information retrieval datasets into the relevance feedback scenario. Extensive experiments demonstrate that integrating relevance feedback directly in neural re-ranking models improves their performance, and fusing lexical ranking with our best performing neural re-ranker outperforms all other methods by 5.2 nDCG@20.
MM-BSN: Self-Supervised Image Denoising for Real-World with Multi-Mask based on Blind-Spot Network
Apr 07, 2023

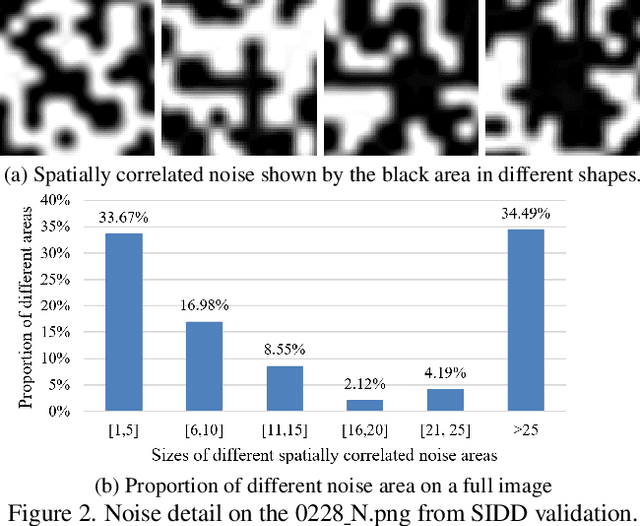
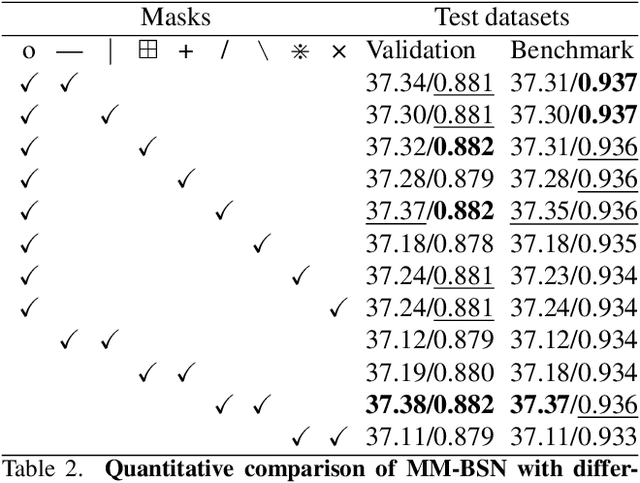
Recent advances in deep learning have been pushing image denoising techniques to a new level. In self-supervised image denoising, blind-spot network (BSN) is one of the most common methods. However, most of the existing BSN algorithms use a dot-based central mask, which is recognized as inefficient for images with large-scale spatially correlated noise. In this paper, we give the definition of large-noise and propose a multi-mask strategy using multiple convolutional kernels masked in different shapes to further break the noise spatial correlation. Furthermore, we propose a novel self-supervised image denoising method that combines the multi-mask strategy with BSN (MM-BSN). We show that different masks can cause significant performance differences, and the proposed MM-BSN can efficiently fuse the features extracted by multi-masked layers, while recovering the texture structures destroyed by multi-masking and information transmission. Our MM-BSN can be used to address the problem of large-noise denoising, which cannot be efficiently handled by other BSN methods. Extensive experiments on public real-world datasets demonstrate that the proposed MM-BSN achieves state-of-the-art performance among self-supervised and even unpaired image denoising methods for sRGB images denoising, without any labelling effort or prior knowledge. Code can be found in https://github.com/dannie125/MM-BSN.