 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Can Be a Viable Substitute for Expert Political Surveys When a Shock Disrupts Traditional Measurement Approaches
Jun 06, 2025After a disruptive event or shock, such as the Department of Government Efficiency (DOGE) federal layoffs of 2025, expert judgments are colored by knowledge of the outcome. This can make it difficult or impossible to reconstruct the pre-event perceptions needed to study the factors associated with the event. This position paper argues that large language models (LLMs), trained on vast amounts of digital media data, can be a viable substitute for expert political surveys when a shock disrupts traditional measurement. We analyze the DOGE layoffs as a specific case study for this position. We use pairwise comparison prompts with LLMs and derive ideology scores for federal executive agencies. These scores replicate pre-layoff expert measures and predict which agencies were targeted by DOGE. We also use this same approach and find that the perceptions of certain federal agencies as knowledge institutions predict which agencies were targeted by DOGE, even when controlling for ideology. This case study demonstrates that using LLMs allows us to rapidly and easily test the associated factors hypothesized behind the shock. More broadly, our case study of this recent event exemplifies how LLMs offer insights into the correlational factors of the shock when traditional measurement techniques fail. We conclude by proposing a two-part criterion for when researchers can turn to LLMs as a substitute for expert political surveys.
Evaluating how LLM annotations represent diverse views on contentious topics
Mar 29, 2025Researchers have proposed the use of generative large language models (LLMs) to label data for both research and applied settings. This literature emphasizes the improved performance of LLMs relative to other natural language models, noting that LLMs typically outperform other models on standard metrics such as accuracy, precision, recall, and F1 score. However, previous literature has also highlighted the bias embedded in language models, particularly around contentious topics such as potentially toxic content. This bias could result in labels applied by LLMs that disproportionately align with majority groups over a more diverse set of viewpoints. In this paper, we evaluate how LLMs represent diverse viewpoints on these contentious tasks. Across four annotation tasks on four datasets, we show that LLMs do not show substantial disagreement with annotators on the basis of demographics. Instead, the model, prompt, and disagreement between human annotators on the labeling task are far more predictive of LLM agreement. Our findings suggest that when using LLMs to annotate data, under-representing the views of particular groups is not a substantial concern. We conclude with a discussion of the implications for researchers and practitioners.
Concept-Guided Chain-of-Thought Prompting for Pairwise Comparison Scaling of Texts with Large Language Models
Oct 18, 2023Existing text scaling methods often require a large corpus, struggle with short texts, or require labeled data. We develop a text scaling method that leverages the pattern recognition capabilities of generative large language models (LLMs). Specifically, we propose concept-guided chain-of-thought (CGCoT), which uses prompts designed to summarize ideas and identify target parties in texts to generate concept-specific breakdowns, in many ways similar to guidance for human coder content analysis. CGCoT effectively shifts pairwise text comparisons from a reasoning problem to a pattern recognition problem. We then pairwise compare concept-specific breakdowns using an LLM. We use the results of these pairwise comparisons to estimate a scale using the Bradley-Terry model. We use this approach to scale affective speech on Twitter. Our measures correlate more strongly with human judgments than alternative approaches like Wordfish. Besides a small set of pilot data to develop the CGCoT prompts, our measures require no additional labeled data and produce binary predictions comparable to a RoBERTa-Large model fine-tuned on thousands of human-labeled tweets. We demonstrate how combining substantive knowledge with LLMs can create state-of-the-art measures of abstract concepts.
Large Language Models Can Be Used to Estimate the Ideologies of Politicians in a Zero-Shot Learning Setting
Mar 22, 2023



The mass aggregation of knowledge embedded in large language models (LLMs) holds the promise of new solutions to problems of observability and measurement in the social sciences. We examine the utility of one such model for a particularly difficult measurement task: measuring the latent ideology of lawmakers, which allows us to better understand functions that are core to democracy, such as how politics shape policy and how political actors represent their constituents. We scale the senators of the 116th United States Congress along the liberal-conservative spectrum by prompting ChatGPT to select the more liberal (or conservative) senator in pairwise comparisons. We show that the LLM produced stable answers across repeated iterations, did not hallucinate, and was not simply regurgitating information from a single source. This new scale strongly correlates with pre-existing liberal-conservative scales such as NOMINATE, but also differs in several important ways, such as correctly placing senators who vote against their party for far-left or far-right ideological reasons on the extreme ends. The scale also highly correlates with ideological measures based on campaign giving and political activists' perceptions of these senators. In addition to the potential for better-automated data collection and information retrieval, our results suggest LLMs are likely to open new avenues for measuring latent constructs like ideology that rely on aggregating large quantities of data from public sources.
Dictionary-Assisted Supervised Contrastive Learning
Oct 27, 2022



Text analysis in the social sciences often involves using specialized dictionaries to reason with abstract concepts, such as perceptions about the economy or abuse on social media. These dictionaries allow researchers to impart domain knowledge and note subtle usages of words relating to a concept(s) of interest. We introduce the dictionary-assisted supervised contrastive learning (DASCL) objective, allowing researchers to leverage specialized dictionaries when fine-tuning pretrained language models. The text is first keyword simplified: a common, fixed token replaces any word in the corpus that appears in the dictionary(ies) relevant to the concept of interest. During fine-tuning, a supervised contrastive objective draws closer the embeddings of the original and keyword-simplified texts of the same class while pushing further apart the embeddings of different classes. The keyword-simplified texts of the same class are more textually similar than their original text counterparts, which additionally draws the embeddings of the same class closer together. Combining DASCL and cross-entropy improves classification performance metrics in few-shot learning settings and social science applications compared to using cross-entropy alone and alternative contrastive and data augmentation methods.
MARMOT: A Deep Learning Framework for Constructing Multimodal Representations for Vision-and-Language Tasks
Sep 23, 2021
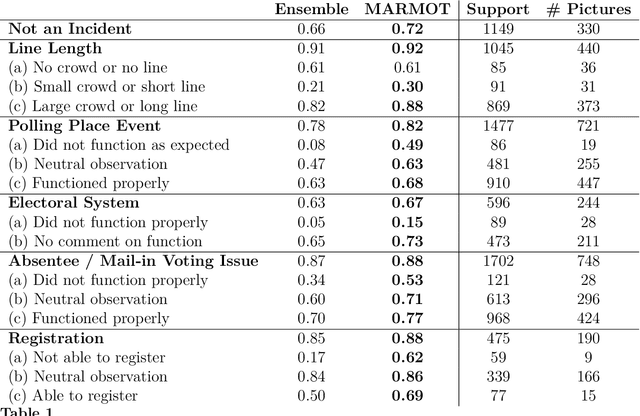
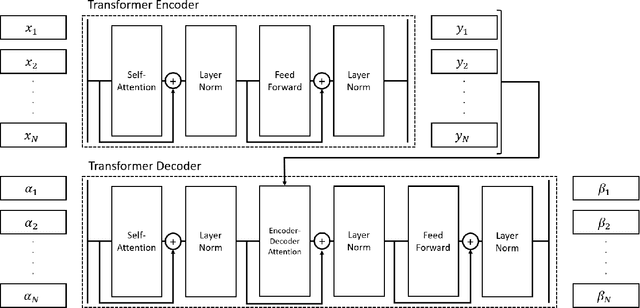
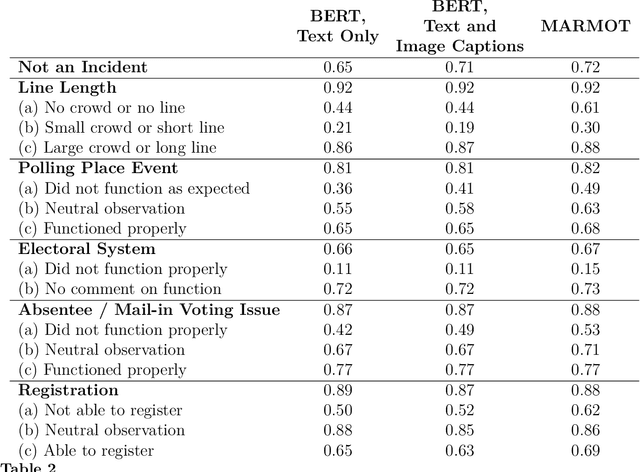
Political activity on social media presents a data-rich window into political behavior, but the vast amount of data means that almost all content analyses of social media require a data labeling step. However, most automated machine classification methods ignore the multimodality of posted content, focusing either on text or images. State-of-the-art vision-and-language models are unusable for most political science research: they require all observations to have both image and text and require computationally expensive pretraining. This paper proposes a novel vision-and-language framework called multimodal representations using modality translation (MARMOT). MARMOT presents two methodological contributions: it can construct representations for observations missing image or text, and it replaces the computationally expensive pretraining with modality translation. MARMOT outperforms an ensemble text-only classifier in 19 of 20 categories in multilabel classifications of tweets reporting election incidents during the 2016 U.S. general election. Moreover, MARMOT shows significant improvements over the results of benchmark multimodal models on the Hateful Memes dataset, improving the best result set by VisualBERT in terms of accuracy from 0.6473 to 0.6760 and area under the receiver operating characteristic curve (AUC) from 0.7141 to 0.7530.