 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Microphone Speaker Separation by Spatial Regions
Mar 13, 2023
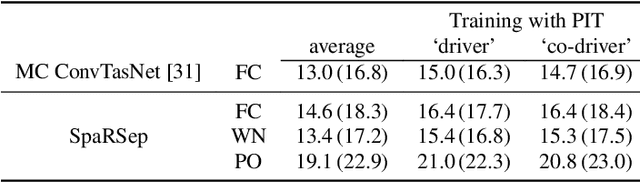
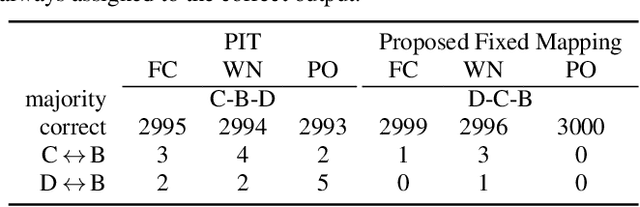

We consider the task of region-based source separation of reverberant multi-microphone recordings. We assume pre-defined spatial regions with a single active source per region. The objective is to estimate the signals from the individual spatial regions as captured by a reference microphone while retaining a correspondence between signals and spatial regions. We propose a data-driven approach using a modified version of a state-of-the-art network, where different layers model spatial and spectro-temporal information. The network is trained to enforce a fixed mapping of regions to network outputs. Using speech from LibriMix, we construct a data set specifically designed to contain the region information. Additionally, we train the network with permutation invariant training. We show that both training methods result in a fixed mapping of regions to network outputs, achieve comparable performance, and that the networks exploit spatial information. The proposed network outperforms a baseline network by 1.5 dB in scale-invariant signal-to-distortion ratio.
Measuring Multi-Source Redundancy in Factor Graphs
Mar 13, 2023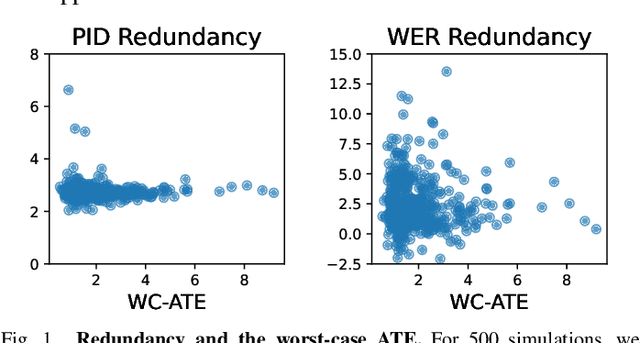
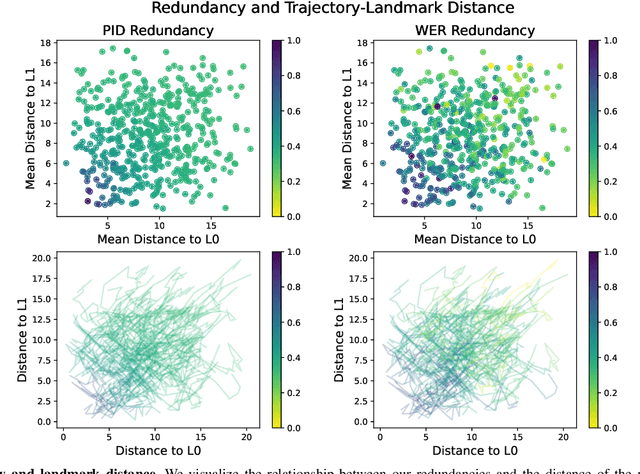
Factor graphs are a ubiquitous tool for multi-source inference in robotics and multi-sensor networks. They allow for heterogeneous measurements from many sources to be concurrently represented as factors in the state posterior distribution, so that inference can be conducted via sparse graphical methods. Adding measurements from many sources can supply robustness to state estimation, as seen in distributed pose graph optimization. However, adding excessive measurements to a factor graph can also quickly degrade their performance as more cycles are added to the graph. In both situations, the relevant quality is the redundancy of information. Drawing on recent work in information theory on partial information decomposition (PID), we articulate two potential definitions of redundancy in factor graphs, both within a common axiomatic framework for redundancy in factor graphs. This is the first application of PID to factor graphs, and only one of a few presenting quantitative measures of redundancy for them.
Learning Spatial-Temporal Implicit Neural Representations for Event-Guided Video Super-Resolution
Mar 29, 2023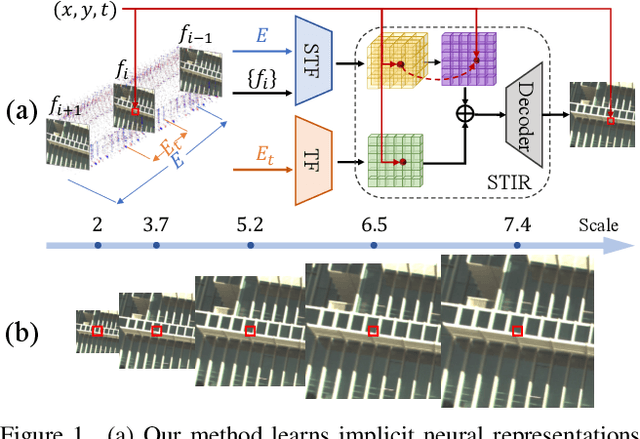
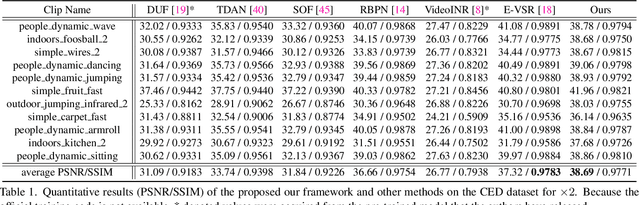
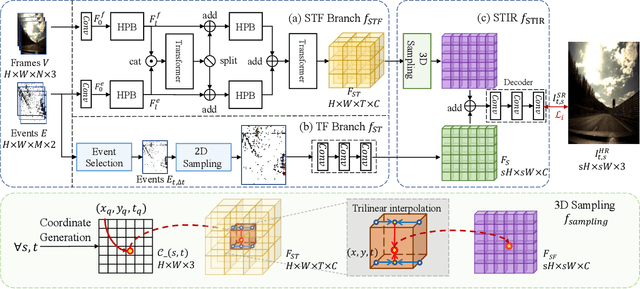
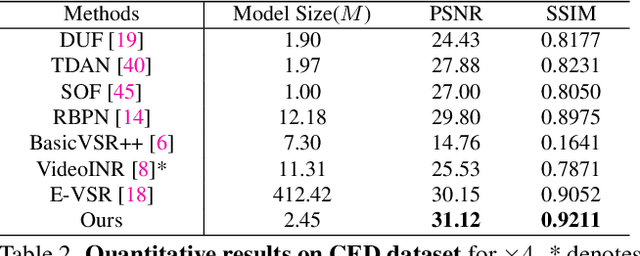
Event cameras sense the intensity changes asynchronously and produce event streams with high dynamic range and low latency. This has inspired research endeavors utilizing events to guide the challenging video superresolution (VSR) task. In this paper, we make the first attempt to address a novel problem of achieving VSR at random scales by taking advantages of the high temporal resolution property of events. This is hampered by the difficulties of representing the spatial-temporal information of events when guiding VSR. To this end, we propose a novel framework that incorporates the spatial-temporal interpolation of events to VSR in a unified framework. Our key idea is to learn implicit neural representations from queried spatial-temporal coordinates and features from both RGB frames and events. Our method contains three parts. Specifically, the Spatial-Temporal Fusion (STF) module first learns the 3D features from events and RGB frames. Then, the Temporal Filter (TF) module unlocks more explicit motion information from the events near the queried timestamp and generates the 2D features. Lastly, the SpatialTemporal Implicit Representation (STIR) module recovers the SR frame in arbitrary resolutions from the outputs of these two modules. In addition, we collect a real-world dataset with spatially aligned events and RGB frames. Extensive experiments show that our method significantly surpasses the prior-arts and achieves VSR with random scales, e.g., 6.5. Code and dataset are available at https: //vlis2022.github.io/cvpr23/egvsr.
Translating Radiology Reports into Plain Language using ChatGPT and GPT-4 with Prompt Learning: Promising Results, Limitations, and Potential
Mar 29, 2023
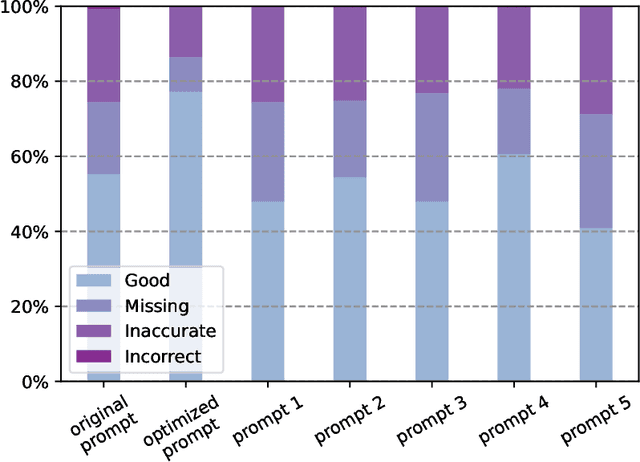


The large language model called ChatGPT has drawn extensively attention because of its human-like expression and reasoning abilities. In this study, we investigate the feasibility of using ChatGPT in experiments on using ChatGPT to translate radiology reports into plain language for patients and healthcare providers so that they are educated for improved healthcare. Radiology reports from 62 low-dose chest CT lung cancer screening scans and 76 brain MRI metastases screening scans were collected in the first half of February for this study. According to the evaluation by radiologists, ChatGPT can successfully translate radiology reports into plain language with an average score of 4.27 in the five-point system with 0.08 places of information missing and 0.07 places of misinformation. In terms of the suggestions provided by ChatGPT, they are general relevant such as keeping following-up with doctors and closely monitoring any symptoms, and for about 37% of 138 cases in total ChatGPT offers specific suggestions based on findings in the report. ChatGPT also presents some randomness in its responses with occasionally over-simplified or neglected information, which can be mitigated using a more detailed prompt. Furthermore, ChatGPT results are compared with a newly released large model GPT-4, showing that GPT-4 can significantly improve the quality of translated reports. Our results show that it is feasible to utilize large language models in clinical education, and further efforts are needed to address limitations and maximize their potential.
MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks
Mar 23, 2023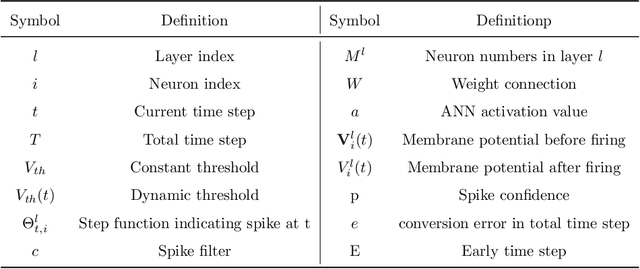
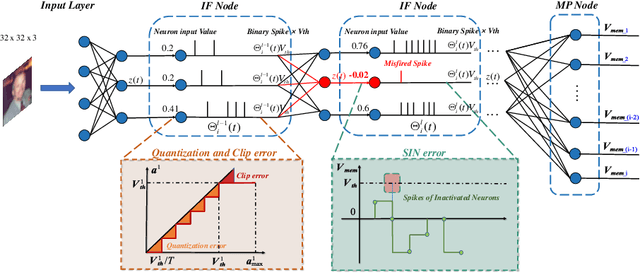
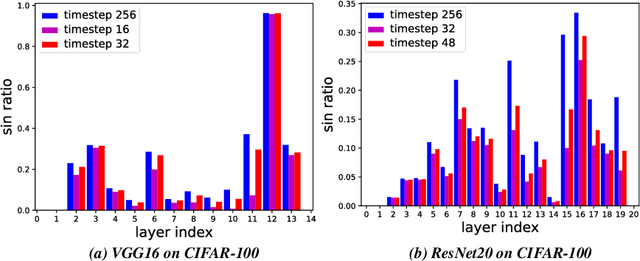
Spiking Neural Networks (SNNs) can do inference with low power consumption due to their spike sparsity. ANN-SNN conversion is an efficient way to achieve deep SNNs by converting well-trained Artificial Neural Networks (ANNs). However, the existing methods commonly use constant threshold for conversion, which prevents neurons from rapidly delivering spikes to deeper layers and causes high time delay. In addition, the same response for different inputs may result in information loss during the information transmission. Inspired by the biological model mechanism, we propose a multi-stage adaptive threshold (MSAT). Specifically, for each neuron, the dynamic threshold varies with firing history and input properties and is positively correlated with the average membrane potential and negatively correlated with the rate of depolarization. The self-adaptation to membrane potential and input allows a timely adjustment of the threshold to fire spike faster and transmit more information. Moreover, we analyze the Spikes of Inactivated Neurons error which is pervasive in early time steps and propose spike confidence accordingly as a measurement of confidence about the neurons that correctly deliver spikes. We use such spike confidence in early time steps to determine whether to elicit spike to alleviate this error. Combined with the proposed method, we examine the performance on non-trivial datasets CIFAR-10, CIFAR-100, and ImageNet. We also conduct sentiment classification and speech recognition experiments on the IDBM and Google speech commands datasets respectively. Experiments show near-lossless and lower latency ANN-SNN conversion. To the best of our knowledge, this is the first time to build a biologically inspired multi-stage adaptive threshold for converted SNN, with comparable performance to state-of-the-art methods while improving energy efficiency.
Brain Tumor classification and Segmentation using Deep Learning
Apr 16, 2023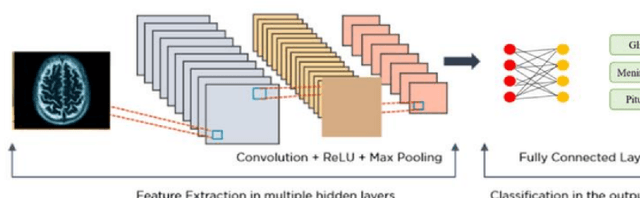
Brain tumors are a complex and potentially life-threatening medical condition that requires accurate diagnosis and timely treatment. In this paper, we present a machine learning-based system designed to assist healthcare professionals in the classification and diagnosis of brain tumors using MRI images. Our system provides a secure login, where doctors can upload or take a photo of MRI and our app can classify the model and segment the tumor, providing the doctor with a folder of each patient's history, name, and results. Our system can also add results or MRI to this folder, draw on the MRI to send it to another doctor, and save important results in a saved page in the app. Furthermore, our system can classify in less than 1 second and allow doctors to chat with a community of brain tumor doctors. To achieve these objectives, our system uses a state-of-the-art machine learning algorithm that has been trained on a large dataset of MRI images. The algorithm can accurately classify different types of brain tumors and provide doctors with detailed information on the size, location, and severity of the tumor. Additionally, our system has several features to ensure its security and privacy, including secure login and data encryption. We evaluated our system using a dataset of real-world MRI images and compared its performance to other existing systems. Our results demonstrate that our system is highly accurate, efficient, and easy to use. We believe that our system has the potential to revolutionize the field of brain tumor diagnosis and treatment and provide healthcare professionals with a powerful tool for improving patient outcomes.
M2GNN: Metapath and Multi-interest Aggregated Graph Neural Network for Tag-based Cross-domain Recommendation
Apr 16, 2023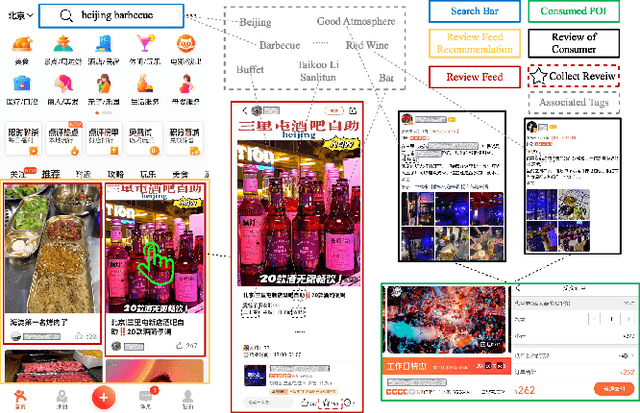
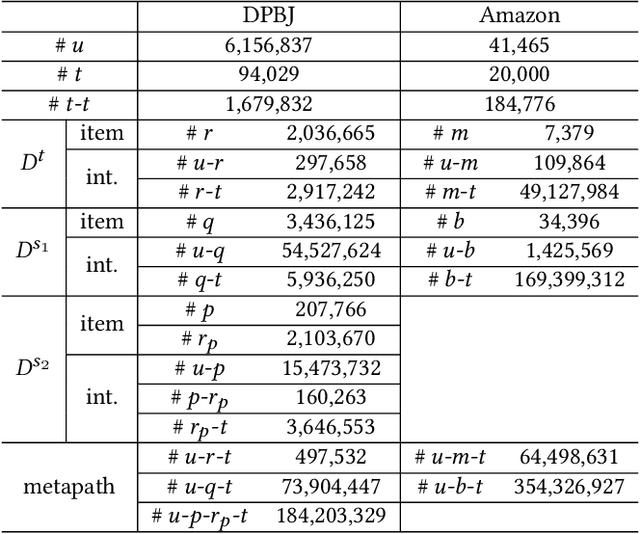
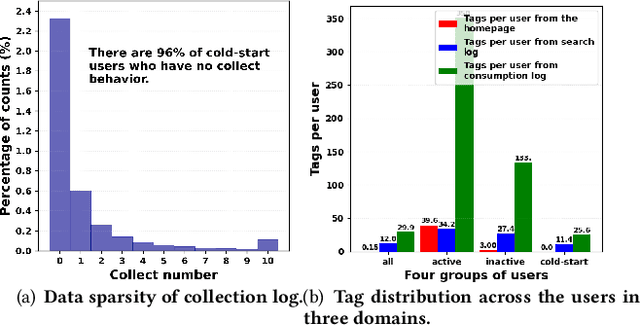
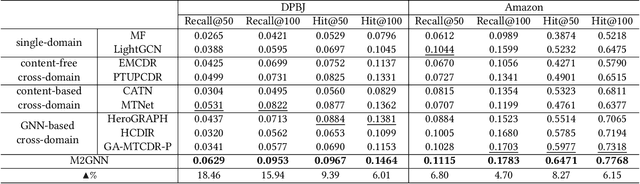
Cross-domain recommendation (CDR) is an effective way to alleviate the data sparsity problem. Content-based CDR is one of the most promising branches since most kinds of products can be described by a piece of text, especially when cold-start users or items have few interactions. However, two vital issues are still under-explored: (1) From the content modeling perspective, sufficient long-text descriptions are usually scarce in a real recommender system, more often the light-weight textual features, such as a few keywords or tags, are more accessible, which is improperly modeled by existing methods. (2) From the CDR perspective, not all inter-domain interests are helpful to infer intra-domain interests. Caused by domain-specific features, there are part of signals benefiting for recommendation in the source domain but harmful for that in the target domain. Therefore, how to distill useful interests is crucial. To tackle the above two problems, we propose a metapath and multi-interest aggregated graph neural network (M2GNN). Specifically, to model the tag-based contents, we construct a heterogeneous information network to hold the semantic relatedness between users, items, and tags in all domains. The metapath schema is predefined according to domain-specific knowledge, with one metapath for one domain. User representations are learned by GNN with a hierarchical aggregation framework, where the intra-metapath aggregation firstly filters out trivial tags and the inter-metapath aggregation further filters out useless interests. Offline experiments and online A/B tests demonstrate that M2GNN achieves significant improvements over the state-of-the-art methods and current industrial recommender system in Dianping, respectively. Further analysis shows that M2GNN offers an interpretable recommendation.
VideoFlow: Exploiting Temporal Cues for Multi-frame Optical Flow Estimation
Mar 17, 2023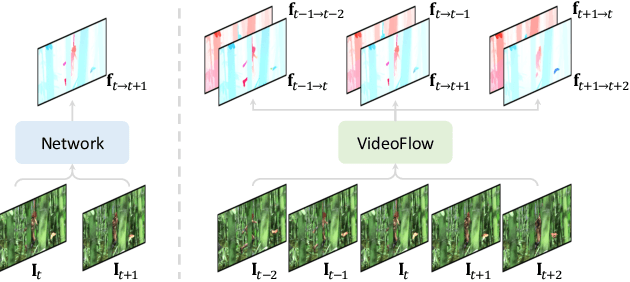
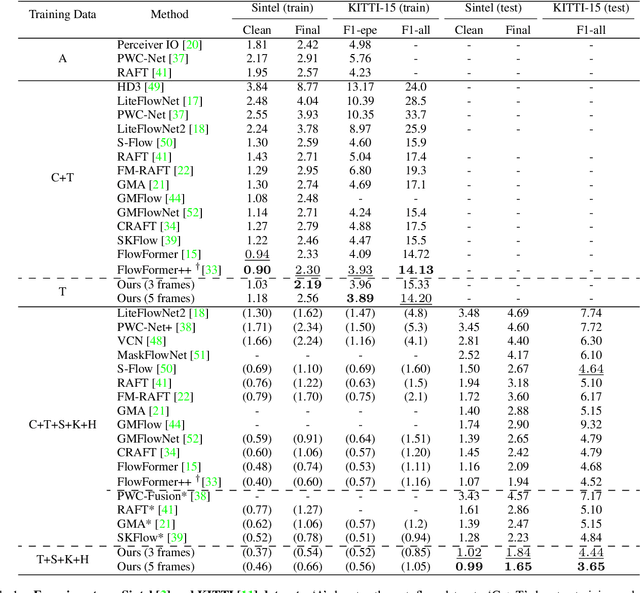
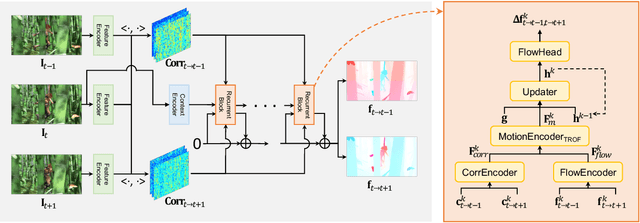
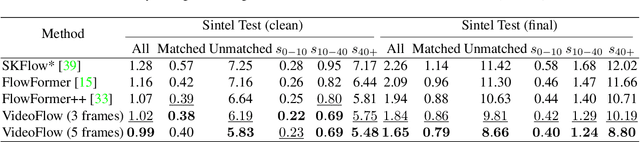
We introduce VideoFlow, a novel optical flow estimation framework for videos. In contrast to previous methods that learn to estimate optical flow from two frames, VideoFlow concurrently estimates bi-directional optical flows for multiple frames that are available in videos by sufficiently exploiting temporal cues. We first propose a TRi-frame Optical Flow (TROF) module that estimates bi-directional optical flows for the center frame in a three-frame manner. The information of the frame triplet is iteratively fused onto the center frame. To extend TROF for handling more frames, we further propose a MOtion Propagation (MOP) module that bridges multiple TROFs and propagates motion features between adjacent TROFs. With the iterative flow estimation refinement, the information fused in individual TROFs can be propagated into the whole sequence via MOP. By effectively exploiting video information, VideoFlow presents extraordinary performance, ranking 1st on all public benchmarks. On the Sintel benchmark, VideoFlow achieves 1.649 and 0.991 average end-point-error (AEPE) on the final and clean passes, a 15.1% and 7.6% error reduction from the best published results (1.943 and 1.073 from FlowFormer++). On the KITTI-2015 benchmark, VideoFlow achieves an F1-all error of 3.65%, a 19.2% error reduction from the best published result (4.52% from FlowFormer++).
Hierarchical Prior Mining for Non-local Multi-View Stereo
Mar 17, 2023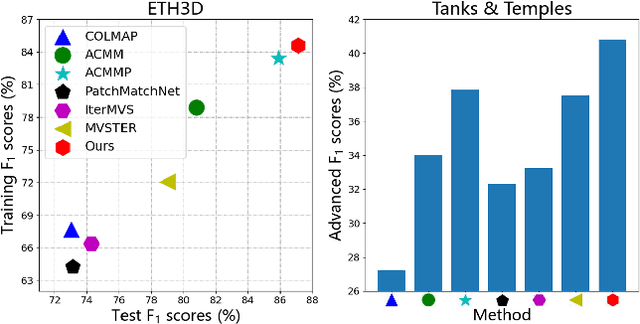
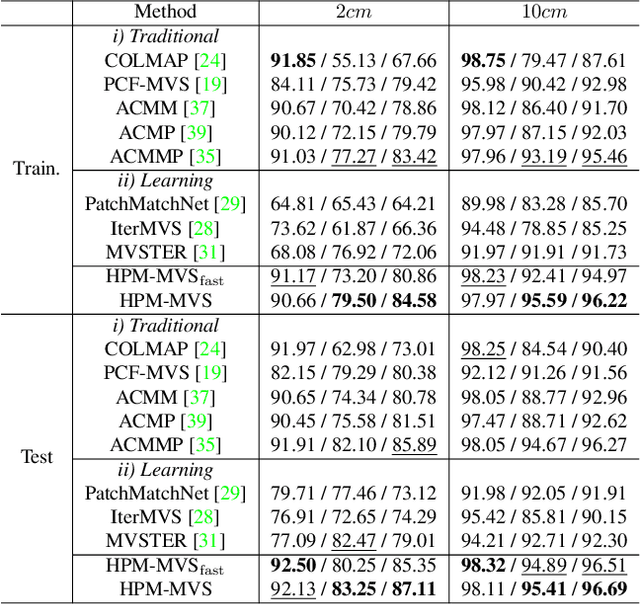
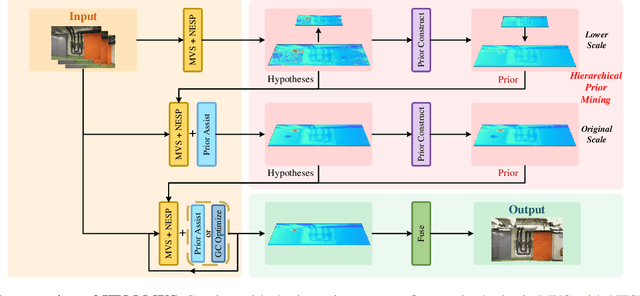
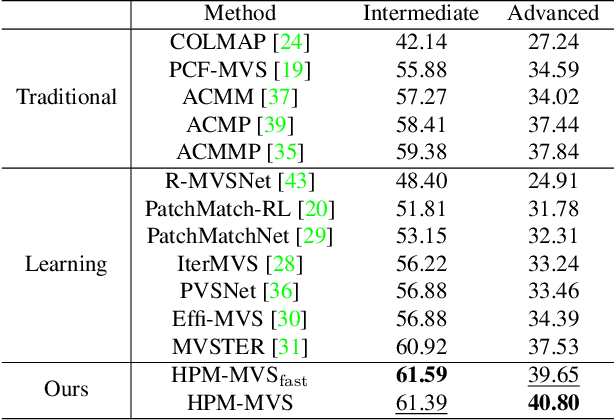
As a fundamental problem in computer vision, multi-view stereo (MVS) aims at recovering the 3D geometry of a target from a set of 2D images. Recent advances in MVS have shown that it is important to perceive non-local structured information for recovering geometry in low-textured areas. In this work, we propose a Hierarchical Prior Mining for Non-local Multi-View Stereo (HPM-MVS). The key characteristics are the following techniques that exploit non-local information to assist MVS: 1) A Non-local Extensible Sampling Pattern (NESP), which is able to adaptively change the size of sampled areas without becoming snared in locally optimal solutions. 2) A new approach to leverage non-local reliable points and construct a planar prior model based on K-Nearest Neighbor (KNN), to obtain potential hypotheses for the regions where prior construction is challenging. 3) A Hierarchical Prior Mining (HPM) framework, which is used to mine extensive non-local prior information at different scales to assist 3D model recovery, this strategy can achieve a considerable balance between the reconstruction of details and low-textured areas. Experimental results on the ETH3D and Tanks \& Temples have verified the superior performance and strong generalization capability of our method. Our code will be released.
Dual Memory Aggregation Network for Event-Based Object Detection with Learnable Representation
Mar 17, 2023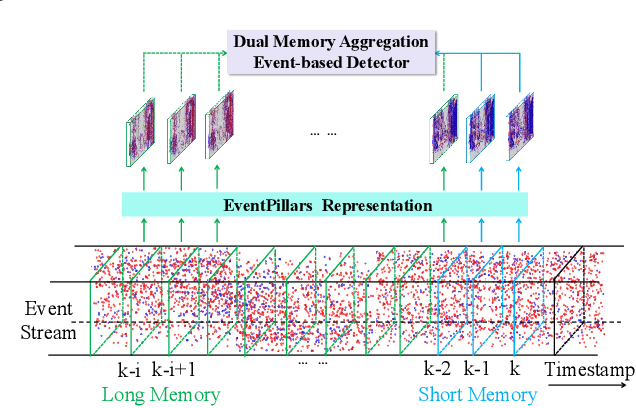

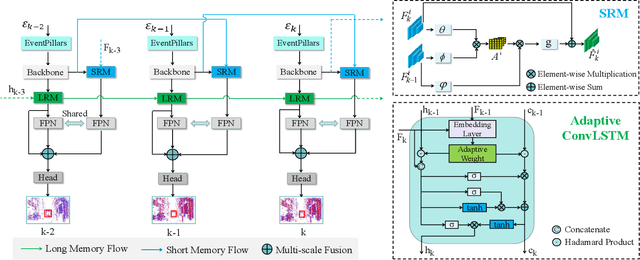
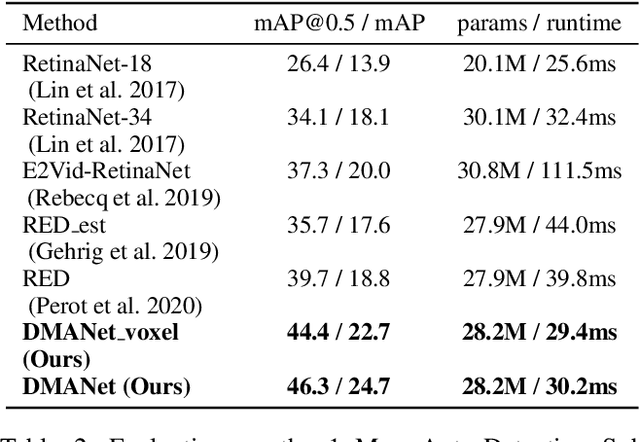
Event-based cameras are bio-inspired sensors that capture brightness change of every pixel in an asynchronous manner. Compared with frame-based sensors, event cameras have microsecond-level latency and high dynamic range, hence showing great potential for object detection under high-speed motion and poor illumination conditions. Due to sparsity and asynchronism nature with event streams, most of existing approaches resort to hand-crafted methods to convert event data into 2D grid representation. However, they are sub-optimal in aggregating information from event stream for object detection. In this work, we propose to learn an event representation optimized for event-based object detection. Specifically, event streams are divided into grids in the x-y-t coordinates for both positive and negative polarity, producing a set of pillars as 3D tensor representation. To fully exploit information with event streams to detect objects, a dual-memory aggregation network (DMANet) is proposed to leverage both long and short memory along event streams to aggregate effective information for object detection. Long memory is encoded in the hidden state of adaptive convLSTMs while short memory is modeled by computing spatial-temporal correlation between event pillars at neighboring time intervals. Extensive experiments on the recently released event-based automotive detection dataset demonstrate the effectiveness of the proposed method.