 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Task-based Performance Bounds for Accelerated MRI Image Reconstruction Methods by Use of Learned-Ideal Observers
Jan 16, 2025



Medical imaging systems are commonly assessed and optimized by the use of objective measures of image quality (IQ). The performance of the ideal observer (IO) acting on imaging measurements has long been advocated as a figure-of-merit to guide the optimization of imaging systems. For computed imaging systems, the performance of the IO acting on imaging measurements also sets an upper bound on task-performance that no image reconstruction method can transcend. As such, estimation of IO performance can provide valuable guidance when designing under-sampled data-acquisition techniques by enabling the identification of designs that will not permit the reconstruction of diagnostically inappropriate images for a specified task - no matter how advanced the reconstruction method is or how plausible the reconstructed images appear. The need for such analysis is urgent because of the substantial increase of medical device submissions on deep learning-based image reconstruction methods and the fact that they may produce clean images disguising the potential loss of diagnostic information when data is aggressively under-sampled. Recently, convolutional neural network (CNN) approximated IOs (CNN-IOs) was investigated for estimating the performance of data space IOs to establish task-based performance bounds for image reconstruction, under an X-ray computed tomographic (CT) context. In this work, the application of such data space CNN-IO analysis to multi-coil magnetic resonance imaging (MRI) systems has been explored. This study utilized stylized multi-coil sensitivity encoding (SENSE) MRI systems and deep-generated stochastic brain models to demonstrate the approach. Signal-known-statistically and background-known-statistically (SKS/BKS) binary signal detection tasks were selected to study the impact of different acceleration factors on the data space IO performance.
Report on the AAPM Grand Challenge on deep generative modeling for learning medical image statistics
May 03, 2024



The findings of the 2023 AAPM Grand Challenge on Deep Generative Modeling for Learning Medical Image Statistics are reported in this Special Report. The goal of this challenge was to promote the development of deep generative models (DGMs) for medical imaging and to emphasize the need for their domain-relevant assessment via the analysis of relevant image statistics. As part of this Grand Challenge, a training dataset was developed based on 3D anthropomorphic breast phantoms from the VICTRE virtual imaging toolbox. A two-stage evaluation procedure consisting of a preliminary check for memorization and image quality (based on the Frechet Inception distance (FID)), and a second stage evaluating the reproducibility of image statistics corresponding to domain-relevant radiomic features was developed. A summary measure was employed to rank the submissions. Additional analyses of submissions was performed to assess DGM performance specific to individual feature families, and to identify various artifacts. 58 submissions from 12 unique users were received for this Challenge. The top-ranked submission employed a conditional latent diffusion model, whereas the joint runners-up employed a generative adversarial network, followed by another network for image superresolution. We observed that the overall ranking of the top 9 submissions according to our evaluation method (i) did not match the FID-based ranking, and (ii) differed with respect to individual feature families. Another important finding from our additional analyses was that different DGMs demonstrated similar kinds of artifacts. This Grand Challenge highlighted the need for domain-specific evaluation to further DGM design as well as deployment. It also demonstrated that the specification of a DGM may differ depending on its intended use.
Translating Radiology Reports into Plain Language using ChatGPT and GPT-4 with Prompt Learning: Promising Results, Limitations, and Potential
Mar 29, 2023



The large language model called ChatGPT has drawn extensively attention because of its human-like expression and reasoning abilities. In this study, we investigate the feasibility of using ChatGPT in experiments on using ChatGPT to translate radiology reports into plain language for patients and healthcare providers so that they are educated for improved healthcare. Radiology reports from 62 low-dose chest CT lung cancer screening scans and 76 brain MRI metastases screening scans were collected in the first half of February for this study. According to the evaluation by radiologists, ChatGPT can successfully translate radiology reports into plain language with an average score of 4.27 in the five-point system with 0.08 places of information missing and 0.07 places of misinformation. In terms of the suggestions provided by ChatGPT, they are general relevant such as keeping following-up with doctors and closely monitoring any symptoms, and for about 37% of 138 cases in total ChatGPT offers specific suggestions based on findings in the report. ChatGPT also presents some randomness in its responses with occasionally over-simplified or neglected information, which can be mitigated using a more detailed prompt. Furthermore, ChatGPT results are compared with a newly released large model GPT-4, showing that GPT-4 can significantly improve the quality of translated reports. Our results show that it is feasible to utilize large language models in clinical education, and further efforts are needed to address limitations and maximize their potential.
Assessing the ability of generative adversarial networks to learn canonical medical image statistics
Apr 27, 2022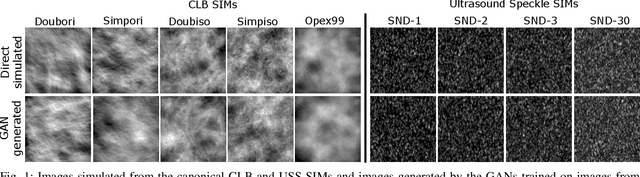
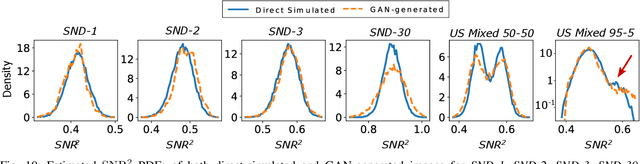
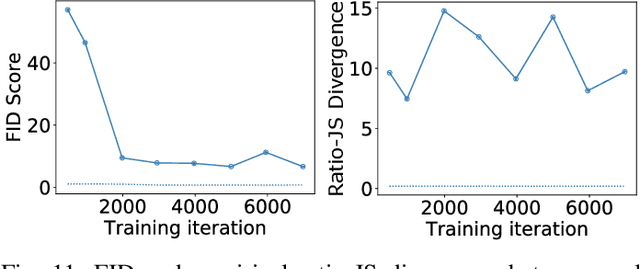
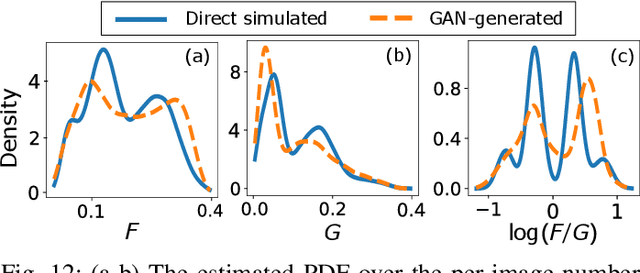
In recent years, generative adversarial networks (GANs) have gained tremendous popularity for potential applications in medical imaging, such as medical image synthesis, restoration, reconstruction, translation, as well as objective image quality assessment. Despite the impressive progress in generating high-resolution, perceptually realistic images, it is not clear if modern GANs reliably learn the statistics that are meaningful to a downstream medical imaging application. In this work, the ability of a state-of-the-art GAN to learn the statistics of canonical stochastic image models (SIMs) that are relevant to objective assessment of image quality is investigated. It is shown that although the employed GAN successfully learned several basic first- and second-order statistics of the specific medical SIMs under consideration and generated images with high perceptual quality, it failed to correctly learn several per-image statistics pertinent to the these SIMs, highlighting the urgent need to assess medical image GANs in terms of objective measures of image quality.
Evaluating Procedures for Establishing Generative Adversarial Network-based Stochastic Image Models in Medical Imaging
Apr 07, 2022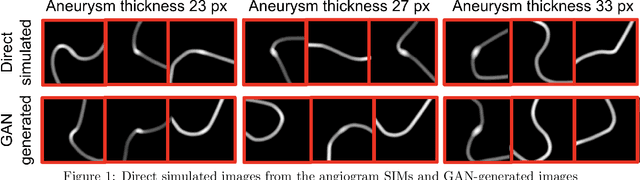
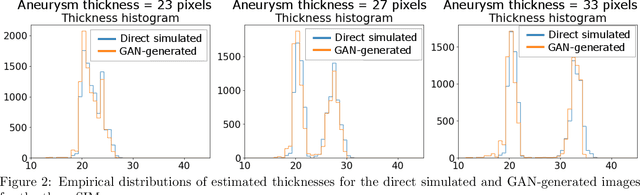
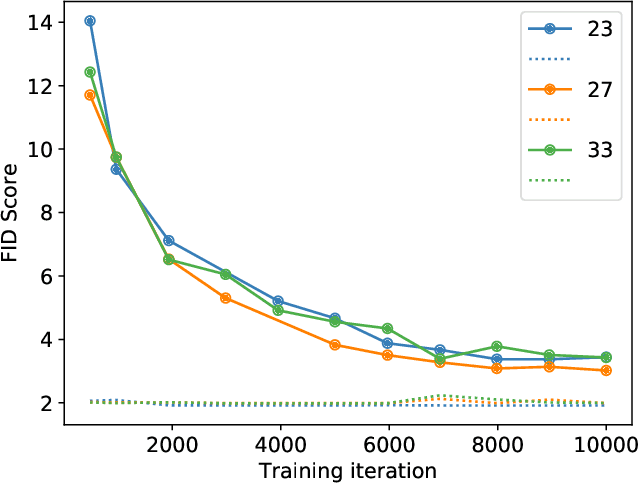
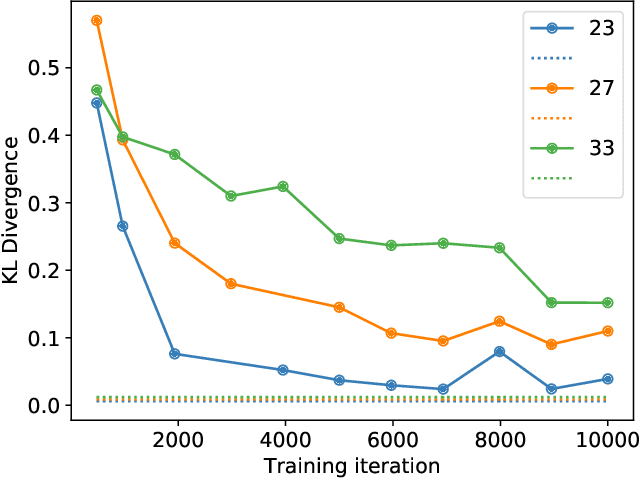
Modern generative models, such as generative adversarial networks (GANs), hold tremendous promise for several areas of medical imaging, such as unconditional medical image synthesis, image restoration, reconstruction and translation, and optimization of imaging systems. However, procedures for establishing stochastic image models (SIMs) using GANs remain generic and do not address specific issues relevant to medical imaging. In this work, canonical SIMs that simulate realistic vessels in angiography images are employed to evaluate procedures for establishing SIMs using GANs. The GAN-based SIM is compared to the canonical SIM based on its ability to reproduce those statistics that are meaningful to the particular medically realistic SIM considered. It is shown that evaluating GANs using classical metrics and medically relevant metrics may lead to different conclusions about the fidelity of the trained GANs. This work highlights the need for the development of objective metrics for evaluating GANs.
Deep neural networks-based denoising models for CT imaging and their efficacy
Nov 18, 2021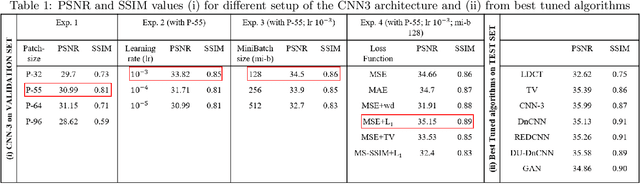
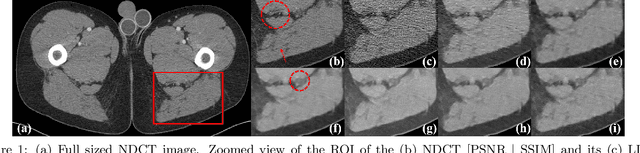
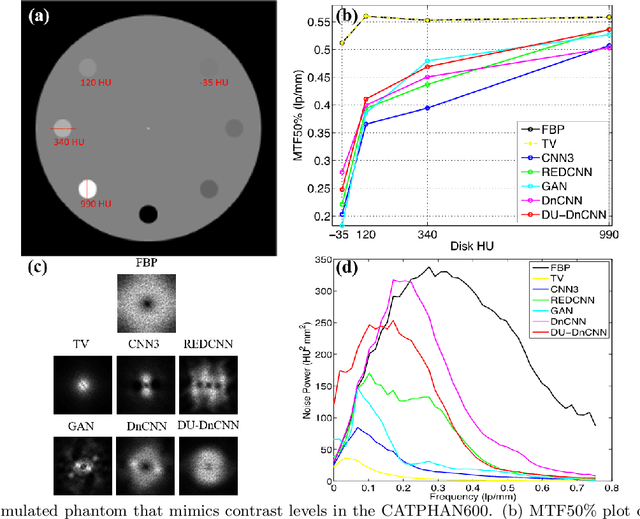
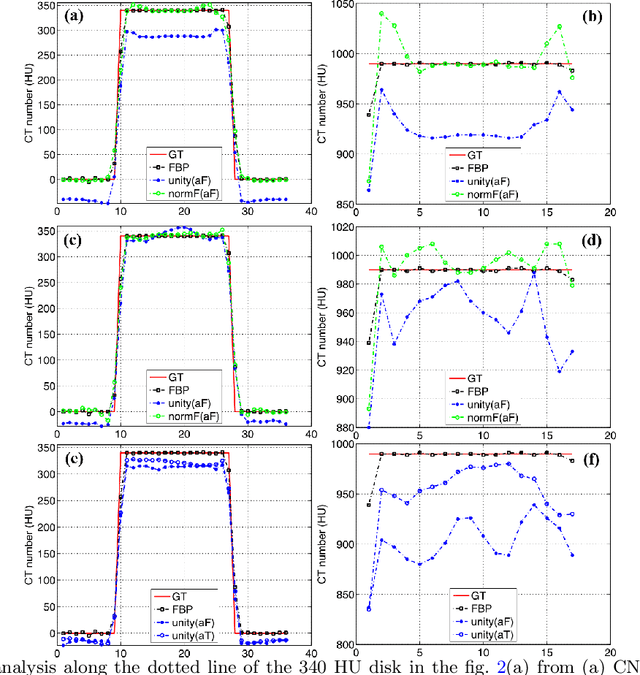
Most of the Deep Neural Networks (DNNs) based CT image denoising literature shows that DNNs outperform traditional iterative methods in terms of metrics such as the RMSE, the PSNR and the SSIM. In many instances, using the same metrics, the DNN results from low-dose inputs are also shown to be comparable to their high-dose counterparts. However, these metrics do not reveal if the DNN results preserve the visibility of subtle lesions or if they alter the CT image properties such as the noise texture. Accordingly, in this work, we seek to examine the image quality of the DNN results from a holistic viewpoint for low-dose CT image denoising. First, we build a library of advanced DNN denoising architectures. This library is comprised of denoising architectures such as the DnCNN, U-Net, Red-Net, GAN, etc. Next, each network is modeled, as well as trained, such that it yields its best performance in terms of the PSNR and SSIM. As such, data inputs (e.g. training patch-size, reconstruction kernel) and numeric-optimizer inputs (e.g. minibatch size, learning rate, loss function) are accordingly tuned. Finally, outputs from thus trained networks are further subjected to a series of CT bench testing metrics such as the contrast-dependent MTF, the NPS and the HU accuracy. These metrics are employed to perform a more nuanced study of the resolution of the DNN outputs' low-contrast features, their noise textures, and their CT number accuracy to better understand the impact each DNN algorithm has on these underlying attributes of image quality.
* 13 pages, 9 figures, SPIE proceeding
Objective task-based evaluation of artificial intelligence-based medical imaging methods: Framework, strategies and role of the physician
Jul 20, 2021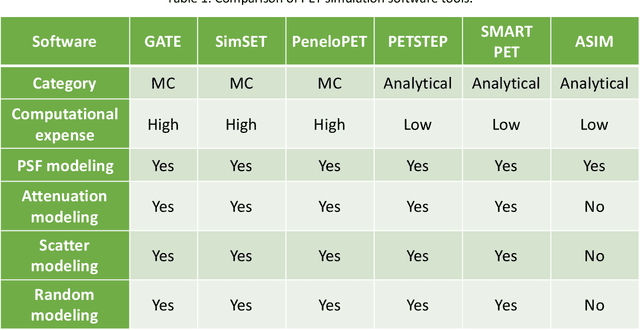
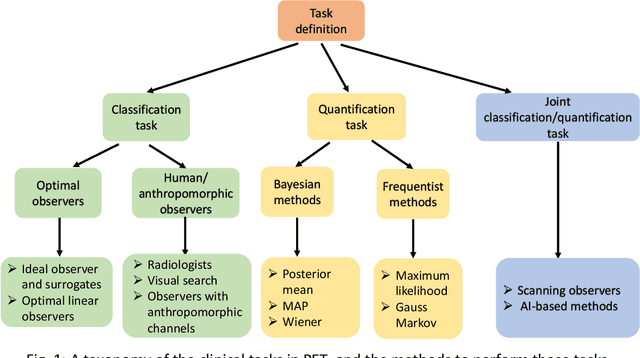
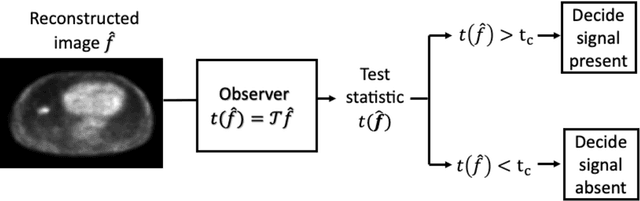
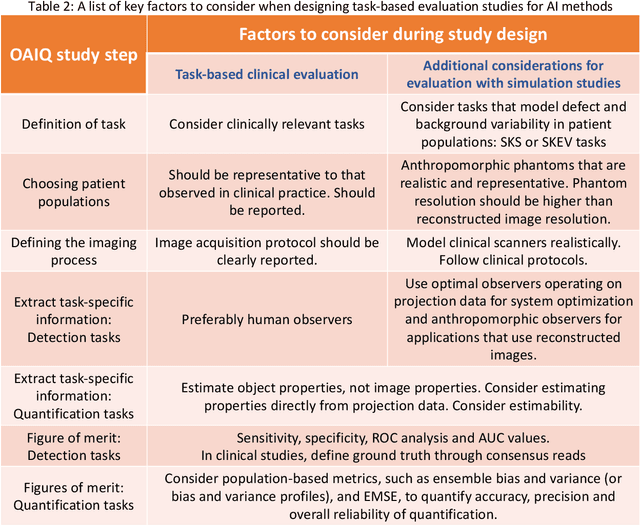
Artificial intelligence (AI)-based methods are showing promise in multiple medical-imaging applications. Thus, there is substantial interest in clinical translation of these methods, requiring in turn, that they be evaluated rigorously. In this paper, our goal is to lay out a framework for objective task-based evaluation of AI methods. We will also provide a list of tools available in the literature to conduct this evaluation. Further, we outline the important role of physicians in conducting these evaluation studies. The examples in this paper will be proposed in the context of PET with a focus on neural-network-based methods. However, the framework is also applicable to evaluate other medical-imaging modalities and other types of AI methods.