 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Text2Cohort: Democratizing the NCI Imaging Data Commons with Natural Language Cohort Discovery
May 12, 2023

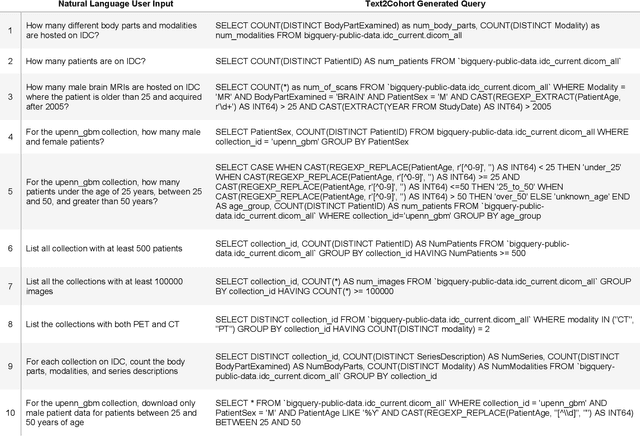

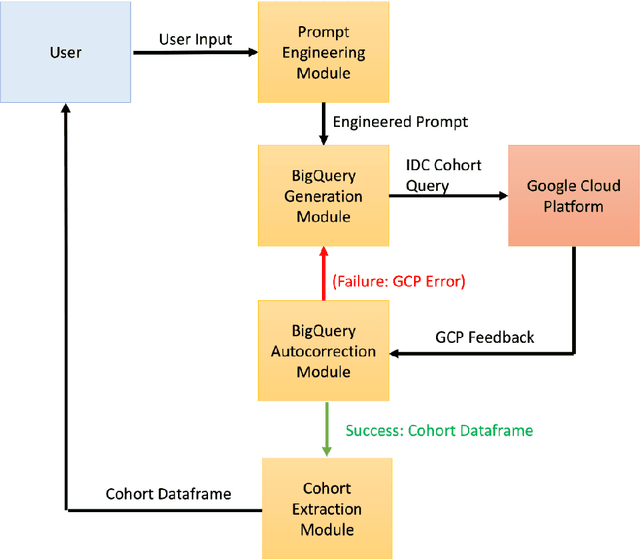
The Imaging Data Commons (IDC) is a cloud-based database that provides researchers with open access to cancer imaging data and tools for analysis, with the goal of facilitating collaboration in medical imaging research. However, querying the IDC database for cohort discovery and access to imaging data has a significant learning curve for researchers due to its complex and technical nature. We developed Text2Cohort, a large language model (LLM) based toolkit to facilitate natural language cohort discovery by translating user input into IDC database queries through prompt engineering and returning the query's response to the user. Furthermore, autocorrection is implemented to resolve syntax and semantic errors in queries by passing the errors back to the model for interpretation and correction. We evaluate Text2Cohort on 50 natural language user inputs ranging from information extraction to cohort discovery. The resulting queries and outputs were verified by two computer scientists to measure Text2Cohort's accuracy and F1 score. Text2Cohort successfully generated queries and their responses with an 88% accuracy and F1 score of 0.94. However, it failed to generate queries for six user inputs due to syntax and semantic errors. Our results indicate that Text2Cohort succeeded at generating queries with correct responses, but occasionally failed due to a poor understanding of the data schema. Despite these shortcomings, Text2Cohort demonstrates the utility of LLMs to enable researchers to discover and curate cohorts using data hosted on IDC with incredible accuracy using natural language in a more intuitive and user-friendly way, thus democratizing access to the IDC.
VR Facial Animation for Immersive Telepresence Avatars
Apr 24, 2023

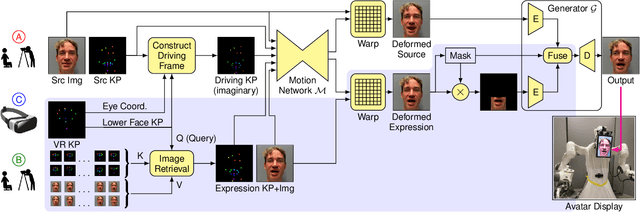
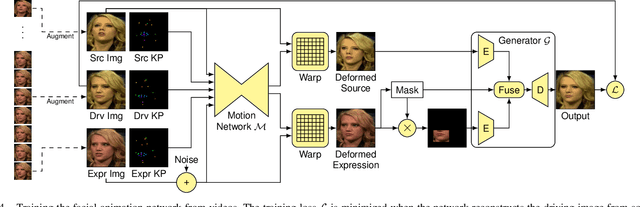
VR Facial Animation is necessary in applications requiring clear view of the face, even though a VR headset is worn. In our case, we aim to animate the face of an operator who is controlling our robotic avatar system. We propose a real-time capable pipeline with very fast adaptation for specific operators. In a quick enrollment step, we capture a sequence of source images from the operator without the VR headset which contain all the important operator-specific appearance information. During inference, we then use the operator keypoint information extracted from a mouth camera and two eye cameras to estimate the target expression and head pose, to which we map the appearance of a source still image. In order to enhance the mouth expression accuracy, we dynamically select an auxiliary expression frame from the captured sequence. This selection is done by learning to transform the current mouth keypoints into the source camera space, where the alignment can be determined accurately. We, furthermore, demonstrate an eye tracking pipeline that can be trained in less than a minute, a time efficient way to train the whole pipeline given a dataset that includes only complete faces, show exemplary results generated by our method, and discuss performance at the ANA Avatar XPRIZE semifinals.
FreMAE: Fourier Transform Meets Masked Autoencoders for Medical Image Segmentation
Apr 21, 2023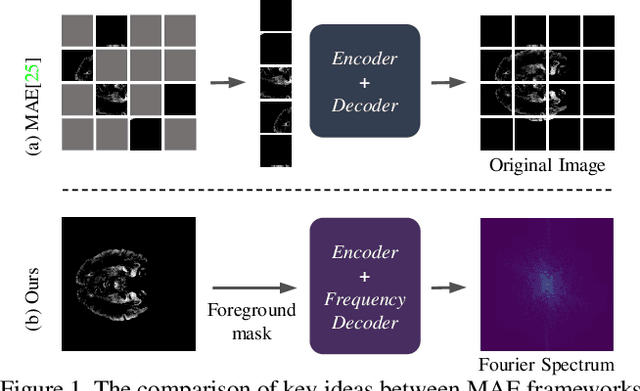
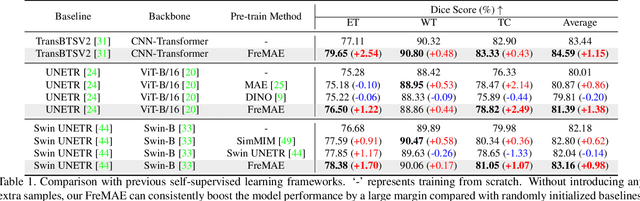
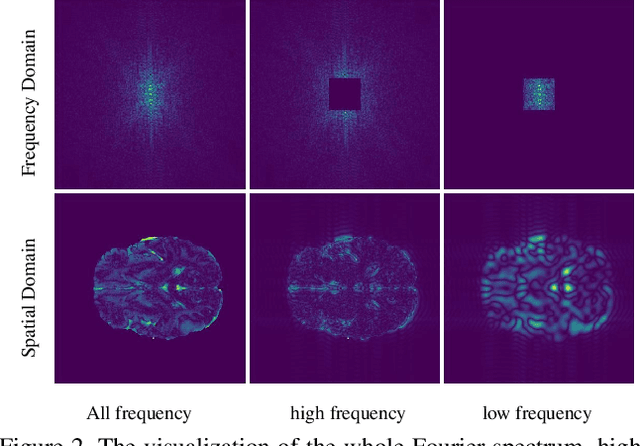
The research community has witnessed the powerful potential of self-supervised Masked Image Modeling (MIM), which enables the models capable of learning visual representation from unlabeled data. In this paper, to incorporate both the crucial global structural information and local details for dense prediction tasks, we alter the perspective to the frequency domain and present a new MIM-based framework named FreMAE for self-supervised pre-training for medical image segmentation. Based on the observations that the detailed structural information mainly lies in the high-frequency components and the high-level semantics are abundant in the low-frequency counterparts, we further incorporate multi-stage supervision to guide the representation learning during the pre-training phase. Extensive experiments on three benchmark datasets show the superior advantage of our proposed FreMAE over previous state-of-the-art MIM methods. Compared with various baselines trained from scratch, our FreMAE could consistently bring considerable improvements to the model performance. To the best our knowledge, this is the first attempt towards MIM with Fourier Transform in medical image segmentation.
Hybrid Deepfake Detection Utilizing MLP and LSTM
Apr 21, 2023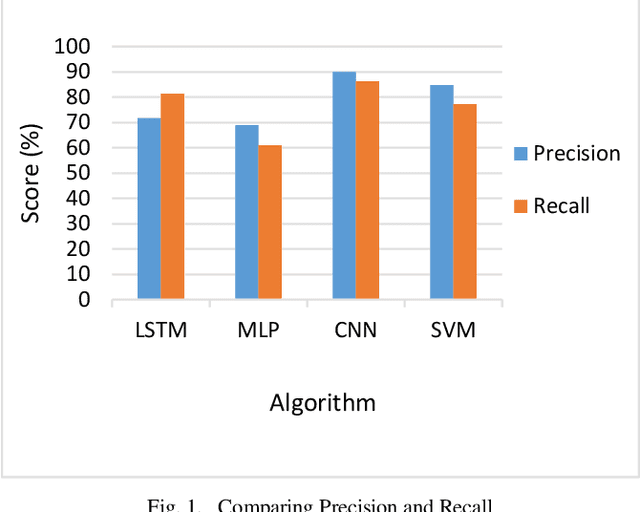
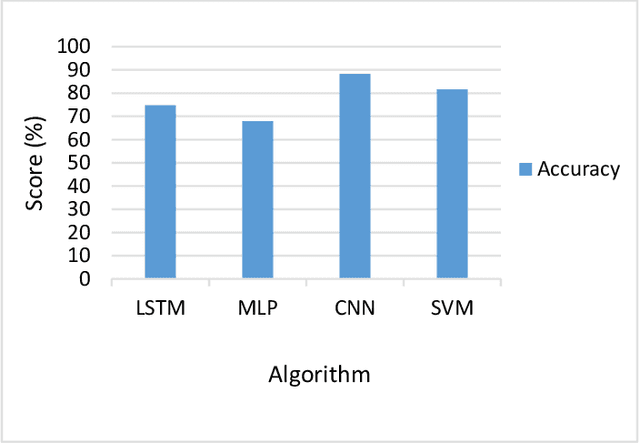
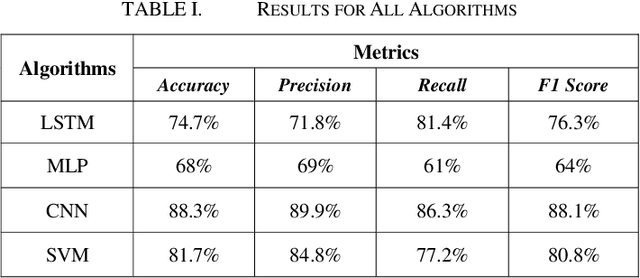
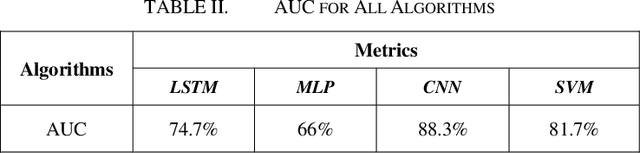
The growing reliance of society on social media for authentic information has done nothing but increase over the past years. This has only raised the potential consequences of the spread of misinformation. One of the growing methods in popularity is to deceive users using a deepfake. A deepfake is an invention that has come with the latest technological advancements, which enables nefarious online users to replace their face with a computer generated, synthetic face of numerous powerful members of society. Deepfake images and videos now provide the means to mimic important political and cultural figures to spread massive amounts of false information. Models that can detect these deepfakes to prevent the spread of misinformation are now of tremendous necessity. In this paper, we propose a new deepfake detection schema utilizing two deep learning algorithms: long short term memory and multilayer perceptron. We evaluate our model using a publicly available dataset named 140k Real and Fake Faces to detect images altered by a deepfake with accuracies achieved as high as 74.7%
Poses as Queries: Image-to-LiDAR Map Localization with Transformers
May 07, 2023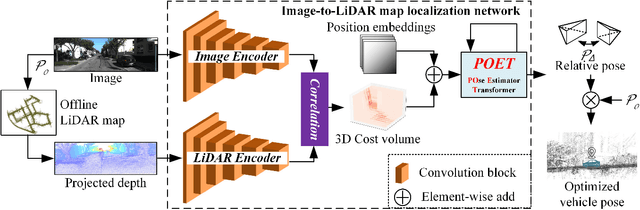
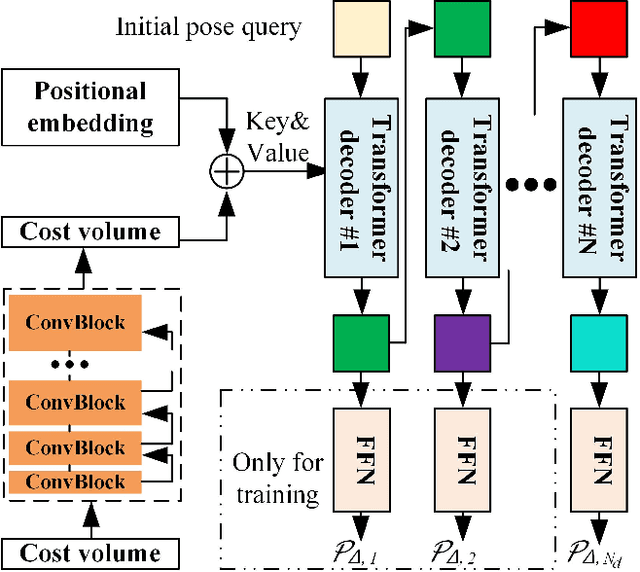

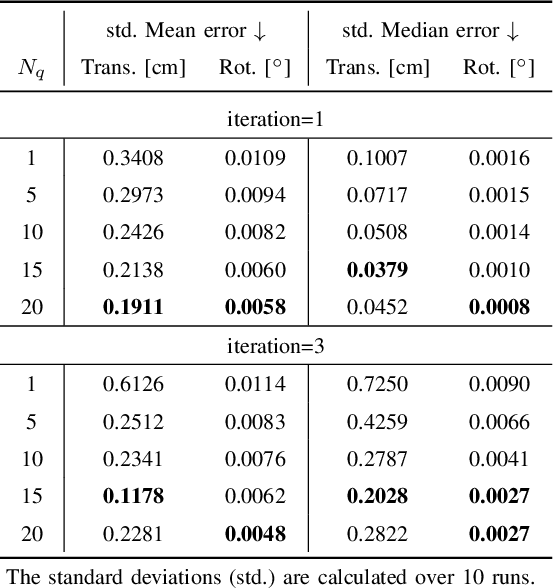
High-precision vehicle localization with commercial setups is a crucial technique for high-level autonomous driving tasks. Localization with a monocular camera in LiDAR map is a newly emerged approach that achieves promising balance between cost and accuracy, but estimating pose by finding correspondences between such cross-modal sensor data is challenging, thereby damaging the localization accuracy. In this paper, we address the problem by proposing a novel Transformer-based neural network to register 2D images into 3D LiDAR map in an end-to-end manner. Poses are implicitly represented as high-dimensional feature vectors called pose queries and can be iteratively updated by interacting with the retrieved relevant information from cross-model features using attention mechanism in a proposed POse Estimator Transformer (POET) module. Moreover, we apply a multiple hypotheses aggregation method that estimates the final poses by performing parallel optimization on multiple randomly initialized pose queries to reduce the network uncertainty. Comprehensive analysis and experimental results on public benchmark conclude that the proposed image-to-LiDAR map localization network could achieve state-of-the-art performances in challenging cross-modal localization tasks.
Multi-agent Continual Coordination via Progressive Task Contextualization
May 07, 2023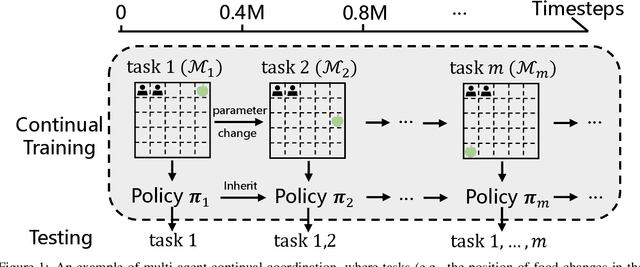
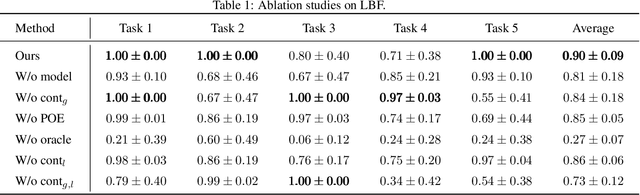
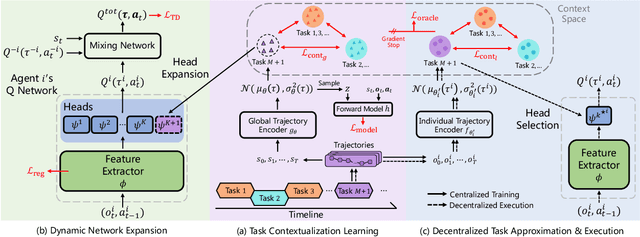
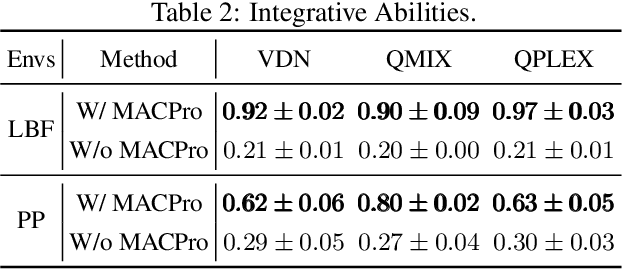
Cooperative Multi-agent Reinforcement Learning (MARL) has attracted significant attention and played the potential for many real-world applications. Previous arts mainly focus on facilitating the coordination ability from different aspects (e.g., non-stationarity, credit assignment) in single-task or multi-task scenarios, ignoring the stream of tasks that appear in a continual manner. This ignorance makes the continual coordination an unexplored territory, neither in problem formulation nor efficient algorithms designed. Towards tackling the mentioned issue, this paper proposes an approach Multi-Agent Continual Coordination via Progressive Task Contextualization, dubbed MACPro. The key point lies in obtaining a factorized policy, using shared feature extraction layers but separated independent task heads, each specializing in a specific class of tasks. The task heads can be progressively expanded based on the learned task contextualization. Moreover, to cater to the popular CTDE paradigm in MARL, each agent learns to predict and adopt the most relevant policy head based on local information in a decentralized manner. We show in multiple multi-agent benchmarks that existing continual learning methods fail, while MACPro is able to achieve close-to-optimal performance. More results also disclose the effectiveness of MACPro from multiple aspects like high generalization ability.
MMRDN: Consistent Representation for Multi-View Manipulation Relationship Detection in Object-Stacked Scenes
Apr 25, 2023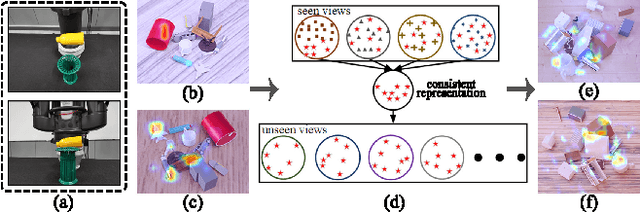
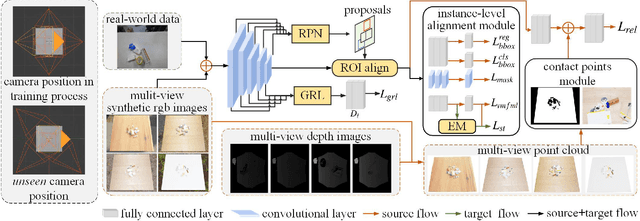
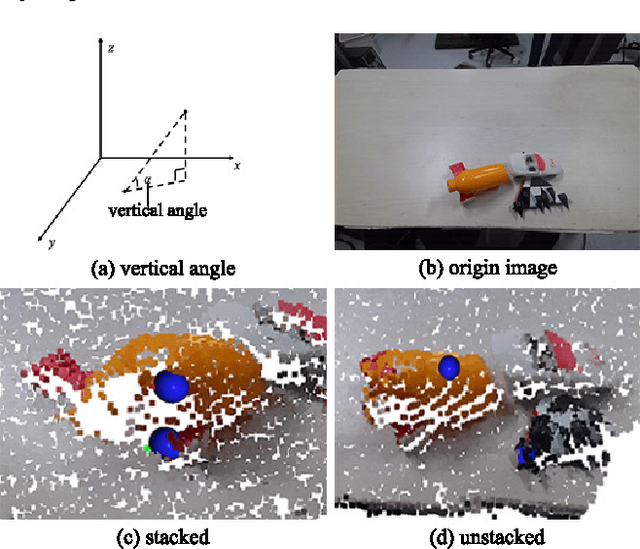
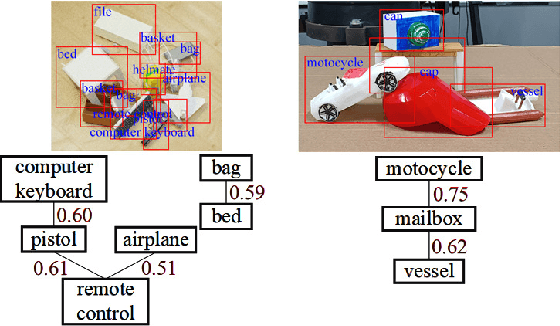
Manipulation relationship detection (MRD) aims to guide the robot to grasp objects in the right order, which is important to ensure the safety and reliability of grasping in object stacked scenes. Previous works infer manipulation relationship by deep neural network trained with data collected from a predefined view, which has limitation in visual dislocation in unstructured environments. Multi-view data provide more comprehensive information in space, while a challenge of multi-view MRD is domain shift. In this paper, we propose a novel multi-view fusion framework, namely multi-view MRD network (MMRDN), which is trained by 2D and 3D multi-view data. We project the 2D data from different views into a common hidden space and fit the embeddings with a set of Von-Mises-Fisher distributions to learn the consistent representations. Besides, taking advantage of position information within the 3D data, we select a set of $K$ Maximum Vertical Neighbors (KMVN) points from the point cloud of each object pair, which encodes the relative position of these two objects. Finally, the features of multi-view 2D and 3D data are concatenated to predict the pairwise relationship of objects. Experimental results on the challenging REGRAD dataset show that MMRDN outperforms the state-of-the-art methods in multi-view MRD tasks. The results also demonstrate that our model trained by synthetic data is capable to transfer to real-world scenarios.
MG-ShopDial: A Multi-Goal Conversational Dataset for e-Commerce
Apr 25, 2023

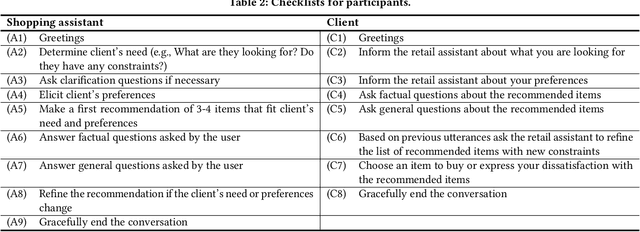
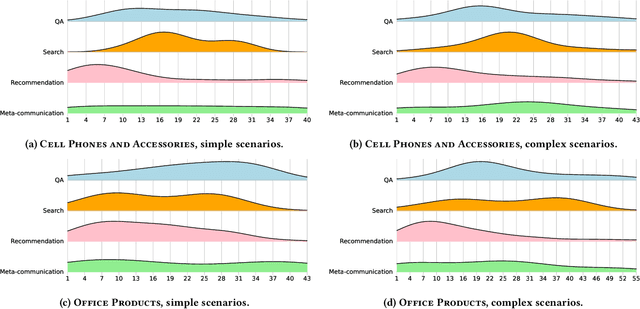
Conversational systems can be particularly effective in supporting complex information seeking scenarios with evolving information needs. Finding the right products on an e-commerce platform is one such scenario, where a conversational agent would need to be able to provide search capabilities over the item catalog, understand and make recommendations based on the user's preferences, and answer a range of questions related to items and their usage. Yet, existing conversational datasets do not fully support the idea of mixing different conversational goals (i.e., search, recommendation, and question answering) and instead focus on a single goal. To address this, we introduce MG-ShopDial: a dataset of conversations mixing different goals in the domain of e-commerce. Specifically, we make the following contributions. First, we develop a coached human-human data collection protocol where each dialogue participant is given a set of instructions, instead of a specific script or answers to choose from. Second, we implement a data collection tool to facilitate the collection of multi-goal conversations via a web chat interface, using the above protocol. Third, we create the MG-ShopDial collection, which contains 64 high-quality dialogues with a total of 2,196 utterances for e-commerce scenarios of varying complexity. The dataset is additionally annotated with both intents and goals on the utterance level. Finally, we present an analysis of this dataset and identify multi-goal conversational patterns.
APR: Online Distant Point Cloud Registration Through Aggregated Point Cloud Reconstruction
May 04, 2023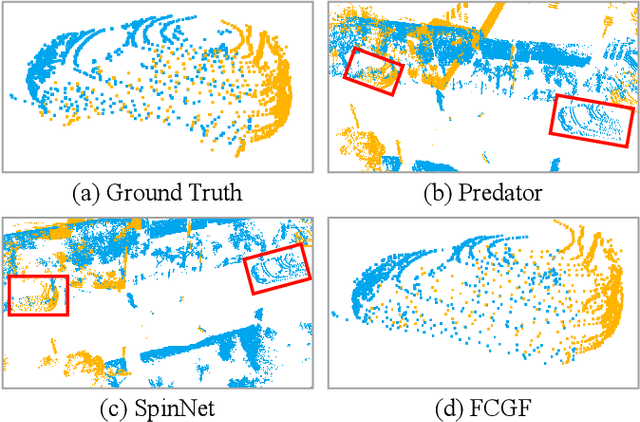
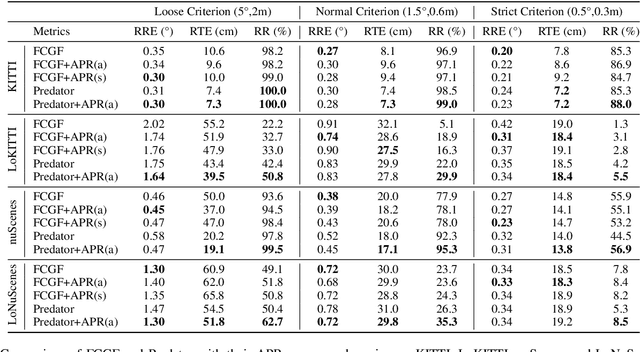
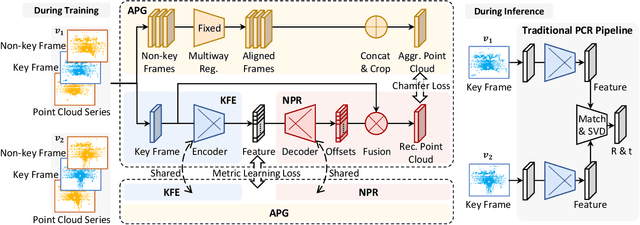
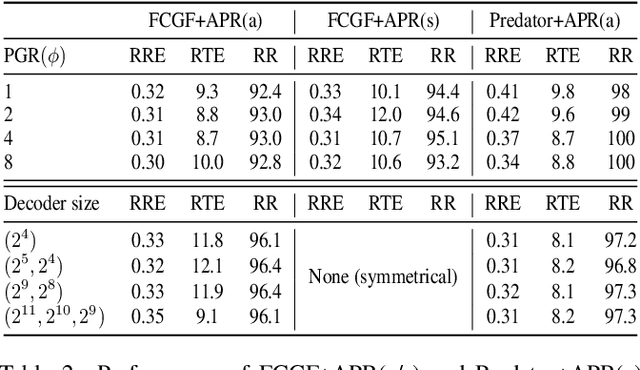
For many driving safety applications, it is of great importance to accurately register LiDAR point clouds generated on distant moving vehicles. However, such point clouds have extremely different point density and sensor perspective on the same object, making registration on such point clouds very hard. In this paper, we propose a novel feature extraction framework, called APR, for online distant point cloud registration. Specifically, APR leverages an autoencoder design, where the autoencoder reconstructs a denser aggregated point cloud with several frames instead of the original single input point cloud. Our design forces the encoder to extract features with rich local geometry information based on one single input point cloud. Such features are then used for online distant point cloud registration. We conduct extensive experiments against state-of-the-art (SOTA) feature extractors on KITTI and nuScenes datasets. Results show that APR outperforms all other extractors by a large margin, increasing average registration recall of SOTA extractors by 7.1% on LoKITTI and 4.6% on LoNuScenes.
Mining fMRI Dynamics with Parcellation Prior for Brain Disease Diagnosis
May 04, 2023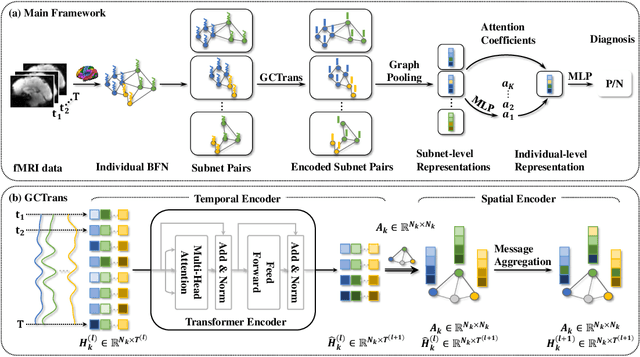
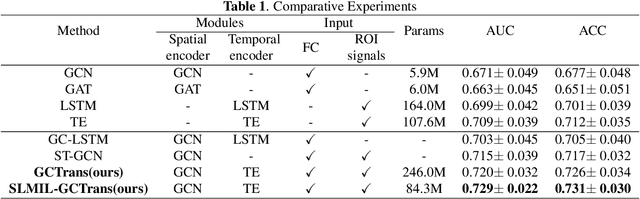
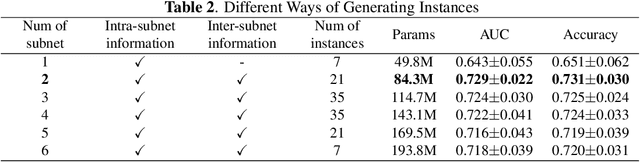
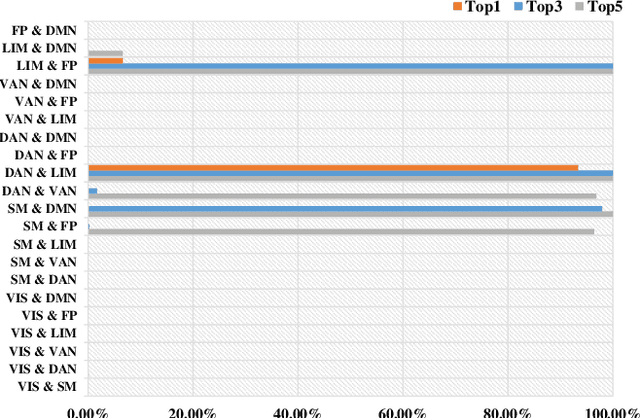
To characterize atypical brain dynamics under diseases, prevalent studies investigate functional magnetic resonance imaging (fMRI). However, most of the existing analyses compress rich spatial-temporal information as the brain functional networks (BFNs) and directly investigate the whole-brain network without neurological priors about functional subnetworks. We thus propose a novel graph learning framework to mine fMRI signals with topological priors from brain parcellation for disease diagnosis. Specifically, we 1) detect diagnosis-related temporal features using a "Transformer" for a higher-level BFN construction, and process it with a following graph convolutional network, and 2) apply an attention-based multiple instance learning strategy to emphasize the disease-affected subnetworks to further enhance the diagnosis performance and interpretability. Experiments demonstrate higher effectiveness of our method than compared methods in the diagnosis of early mild cognitive impairment. More importantly, our method is capable of localizing crucial brain subnetworks during the diagnosis, providing insights into the pathogenic source of mild cognitive impairment.