 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration and Evaluation of Bias in Cyberbullying Detection with Machine Learning
Nov 30, 2024



It is well known that the usefulness of a machine learning model is due to its ability to generalize to unseen data. This study uses three popular cyberbullying datasets to explore the effects of data, how it's collected, and how it's labeled, on the resulting machine learning models. The bias introduced from differing definitions of cyberbullying and from data collection is discussed in detail. An emphasis is made on the impact of dataset expansion methods, which utilize current data points to fetch and label new ones. Furthermore, explicit testing is performed to evaluate the ability of a model to generalize to unseen datasets through cross-dataset evaluation. As hypothesized, the models have a significant drop in the Macro F1 Score, with an average drop of 0.222. As such, this study effectively highlights the importance of dataset curation and cross-dataset testing for creating models with real-world applicability. The experiments and other code can be found at https://github.com/rootdrew27/cyberbullying-ml.
Software Repositories and Machine Learning Research in Cyber Security
Nov 01, 2023In today's rapidly evolving technological landscape and advanced software development, the rise in cyber security attacks has become a pressing concern. The integration of robust cyber security defenses has become essential across all phases of software development. It holds particular significance in identifying critical cyber security vulnerabilities at the initial stages of the software development life cycle, notably during the requirement phase. Through the utilization of cyber security repositories like The Common Attack Pattern Enumeration and Classification (CAPEC) from MITRE and the Common Vulnerabilities and Exposures (CVE) databases, attempts have been made to leverage topic modeling and machine learning for the detection of these early-stage vulnerabilities in the software requirements process. Past research themes have returned successful outcomes in attempting to automate vulnerability identification for software developers, employing a mixture of unsupervised machine learning methodologies such as LDA and topic modeling. Looking ahead, in our pursuit to improve automation and establish connections between software requirements and vulnerabilities, our strategy entails adopting a variety of supervised machine learning techniques. This array encompasses Support Vector Machines (SVM), Na\"ive Bayes, random forest, neural networking and eventually transitioning into deep learning for our investigation. In the face of the escalating complexity of cyber security, the question of whether machine learning can enhance the identification of vulnerabilities in diverse software development scenarios is a paramount consideration, offering crucial assistance to software developers in developing secure software.
Hybrid Deepfake Detection Utilizing MLP and LSTM
Apr 21, 2023



The growing reliance of society on social media for authentic information has done nothing but increase over the past years. This has only raised the potential consequences of the spread of misinformation. One of the growing methods in popularity is to deceive users using a deepfake. A deepfake is an invention that has come with the latest technological advancements, which enables nefarious online users to replace their face with a computer generated, synthetic face of numerous powerful members of society. Deepfake images and videos now provide the means to mimic important political and cultural figures to spread massive amounts of false information. Models that can detect these deepfakes to prevent the spread of misinformation are now of tremendous necessity. In this paper, we propose a new deepfake detection schema utilizing two deep learning algorithms: long short term memory and multilayer perceptron. We evaluate our model using a publicly available dataset named 140k Real and Fake Faces to detect images altered by a deepfake with accuracies achieved as high as 74.7%
Leveraging Deep Learning Approaches for Deepfake Detection: A Review
Apr 04, 2023Conspicuous progression in the field of machine learning and deep learning have led the jump of highly realistic fake media, these media oftentimes referred as deepfakes. Deepfakes are fabricated media which are generated by sophisticated AI that are at times very difficult to set apart from the real media. So far, this media can be uploaded to the various social media platforms, hence advertising it to the world got easy, calling for an efficacious countermeasure. Thus, one of the optimistic counter steps against deepfake would be deepfake detection. To undertake this threat, researchers in the past have created models to detect deepfakes based on ML/DL techniques like Convolutional Neural Networks. This paper aims to explore different methodologies with an intention to achieve a cost-effective model with a higher accuracy with different types of the datasets, which is to address the generalizability of the dataset.
Machine Learning Based Approach to Recommend MITRE ATT&CK Framework for Software Requirements and Design Specifications
Feb 10, 2023



Engineering more secure software has become a critical challenge in the cyber world. It is very important to develop methodologies, techniques, and tools for developing secure software. To develop secure software, software developers need to think like an attacker through mining software repositories. These aim to analyze and understand the data repositories related to software development. The main goal is to use these software repositories to support the decision-making process of software development. There are different vulnerability databases like Common Weakness Enumeration (CWE), Common Vulnerabilities and Exposures database (CVE), and CAPEC. We utilized a database called MITRE. MITRE ATT&CK tactics and techniques have been used in various ways and methods, but tools for utilizing these tactics and techniques in the early stages of the software development life cycle (SDLC) are lacking. In this paper, we use machine learning algorithms to map requirements to the MITRE ATT&CK database and determine the accuracy of each mapping depending on the data split.
Using Deep Learning to Detecting Deepfakes
Jul 27, 2022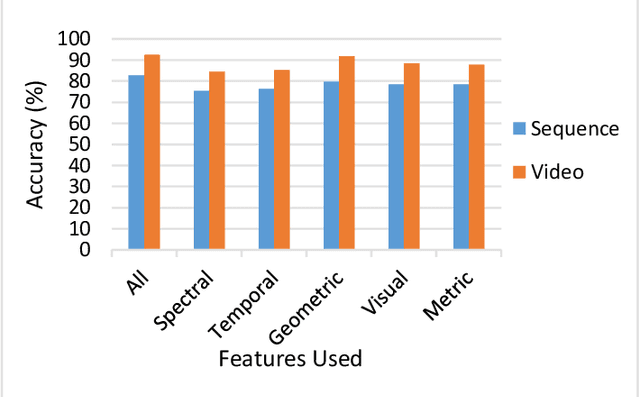
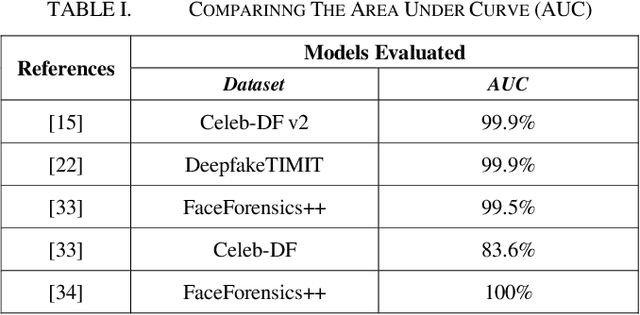
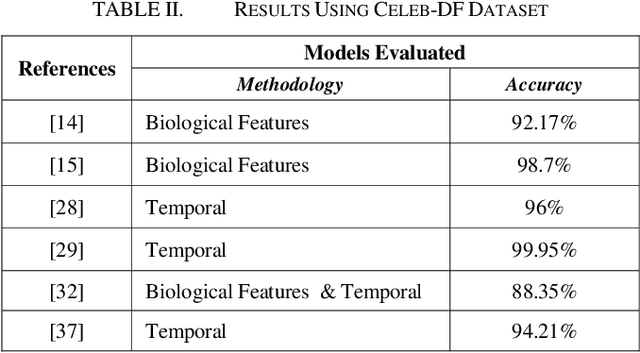
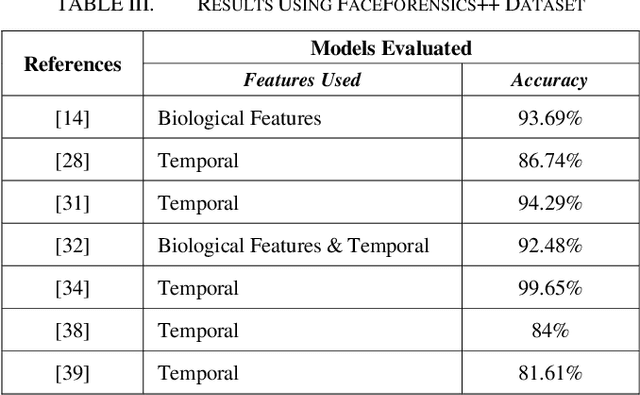
In the recent years, social media has grown to become a major source of information for many online users. This has given rise to the spread of misinformation through deepfakes. Deepfakes are videos or images that replace one persons face with another computer-generated face, often a more recognizable person in society. With the recent advances in technology, a person with little technological experience can generate these videos. This enables them to mimic a power figure in society, such as a president or celebrity, creating the potential danger of spreading misinformation and other nefarious uses of deepfakes. To combat this online threat, researchers have developed models that are designed to detect deepfakes. This study looks at various deepfake detection models that use deep learning algorithms to combat this looming threat. This survey focuses on providing a comprehensive overview of the current state of deepfake detection models and the unique approaches many researchers take to solving this problem. The benefits, limitations, and suggestions for future work will be thoroughly discussed throughout this paper.
Machine and Deep Learning Applications to Mouse Dynamics for Continuous User Authentication
May 26, 2022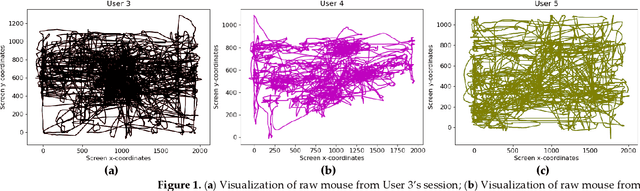
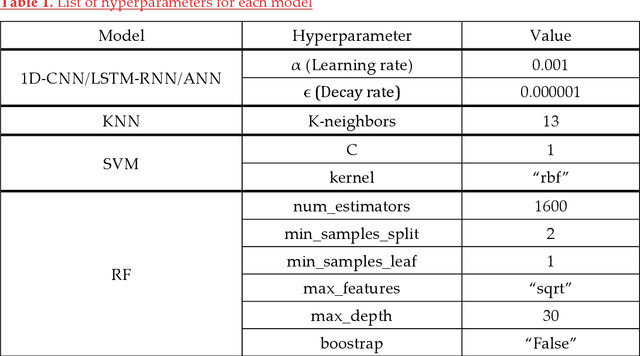
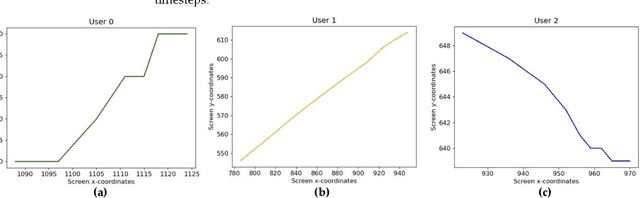
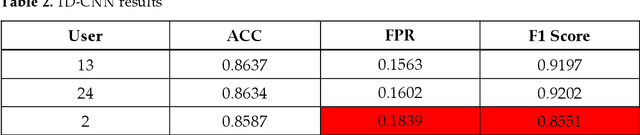
Static authentication methods, like passwords, grow increasingly weak with advancements in technology and attack strategies. Continuous authentication has been proposed as a solution, in which users who have gained access to an account are still monitored in order to continuously verify that the user is not an imposter who had access to the user credentials. Mouse dynamics is the behavior of a users mouse movements and is a biometric that has shown great promise for continuous authentication schemes. This article builds upon our previous published work by evaluating our dataset of 40 users using three machine learning and deep learning algorithms. Two evaluation scenarios are considered: binary classifiers are used for user authentication, with the top performer being a 1-dimensional convolutional neural network with a peak average test accuracy of 85.73% across the top 10 users. Multi class classification is also examined using an artificial neural network which reaches an astounding peak accuracy of 92.48% the highest accuracy we have seen for any classifier on this dataset.
Evaluation of a User Authentication Schema Using Behavioral Biometrics and Machine Learning
May 07, 2022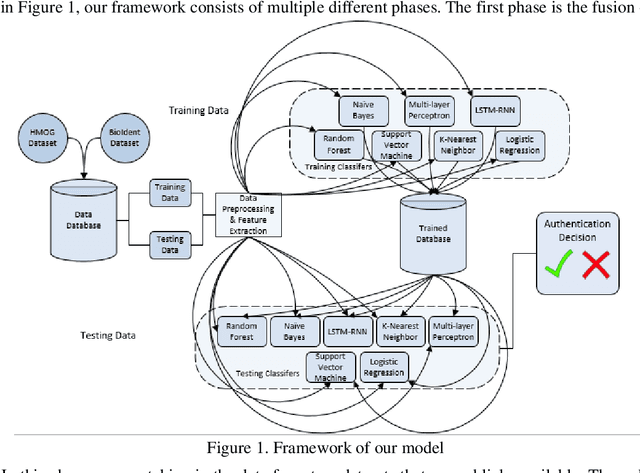
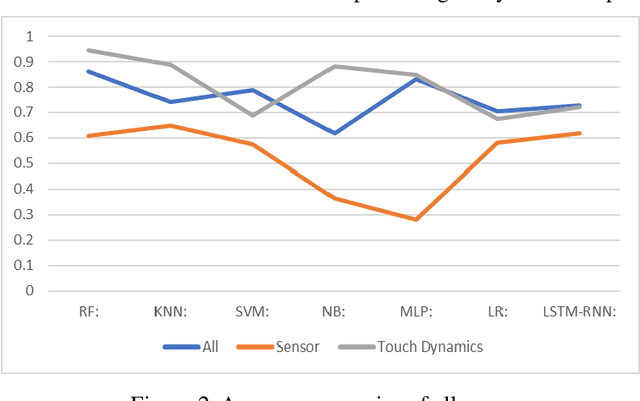
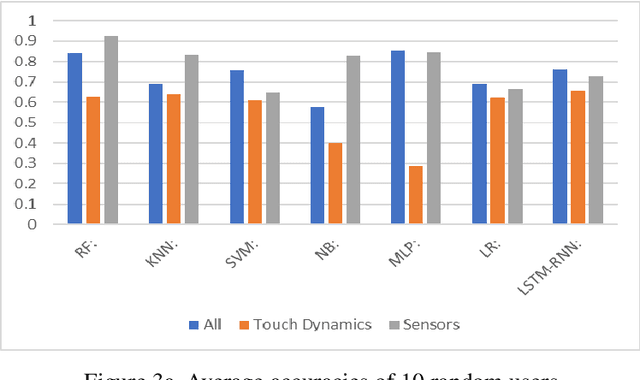
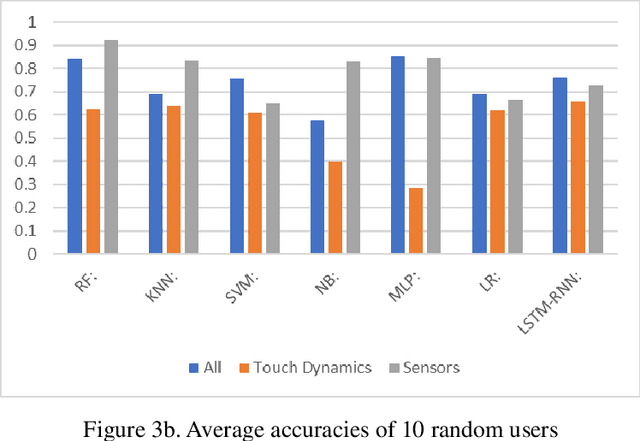
The amount of secure data being stored on mobile devices has grown immensely in recent years. However, the security measures protecting this data have stayed static, with few improvements being done to the vulnerabilities of current authentication methods such as physiological biometrics or passwords. Instead of these methods, behavioral biometrics has recently been researched as a solution to these vulnerable authentication methods. In this study, we aim to contribute to the research being done on behavioral biometrics by creating and evaluating a user authentication scheme using behavioral biometrics. The behavioral biometrics used in this study include touch dynamics and phone movement, and we evaluate the performance of different single-modal and multi-modal combinations of the two biometrics. Using two publicly available datasets - BioIdent and Hand Movement Orientation and Grasp (H-MOG), this study uses seven common machine learning algorithms to evaluate performance. The algorithms used in the evaluation include Random Forest, Support Vector Machine, K-Nearest Neighbor, Naive Bayes, Logistic Regression, Multilayer Perceptron, and Long Short-Term Memory Recurrent Neural Networks, with accuracy rates reaching as high as 86%.
A Close Look into Human Activity Recognition Models using Deep Learning
Apr 26, 2022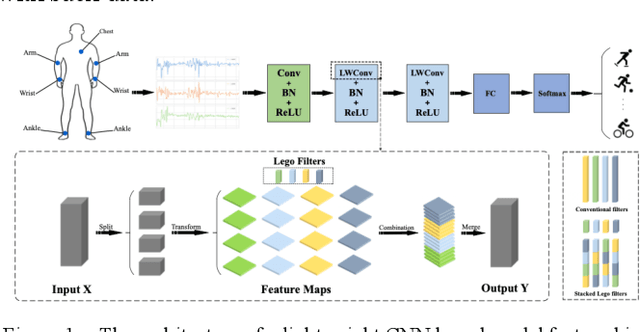
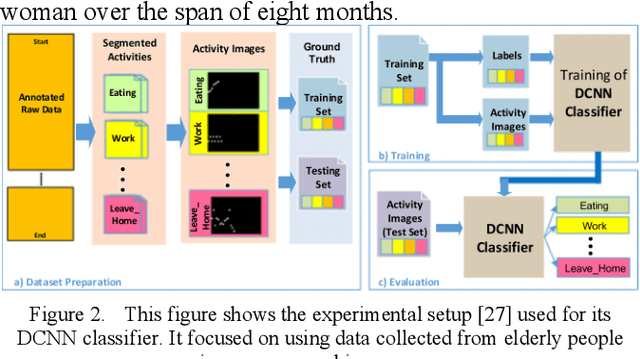
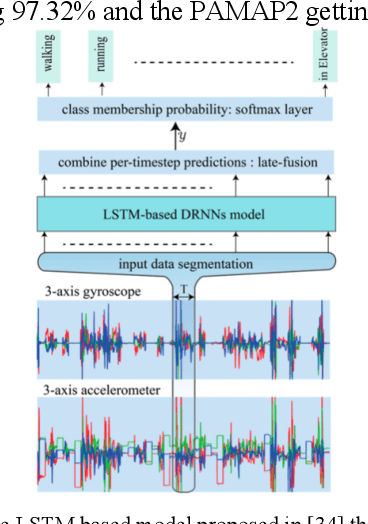
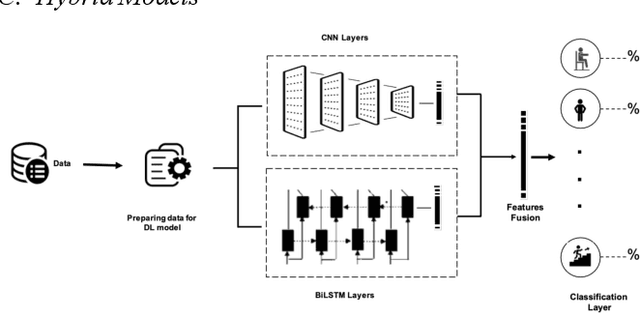
Human activity recognition using deep learning techniques has become increasing popular because of its high effectivity with recognizing complex tasks, as well as being relatively low in costs compared to more traditional machine learning techniques. This paper surveys some state-of-the-art human activity recognition models that are based on deep learning architecture and has layers containing Convolution Neural Networks (CNN), Long Short-Term Memory (LSTM), or a mix of more than one type for a hybrid system. The analysis outlines how the models are implemented to maximize its effectivity and some of the potential limitations it faces.
Human Activity Recognition models using Limited Consumer Device Sensors and Machine Learning
Jan 21, 2022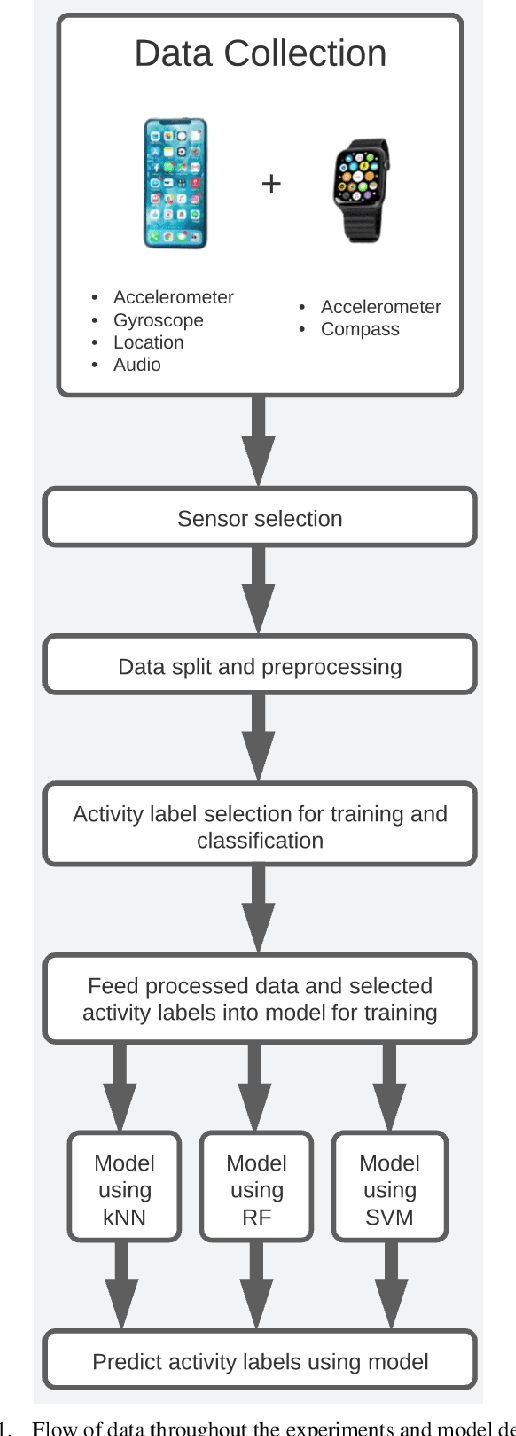
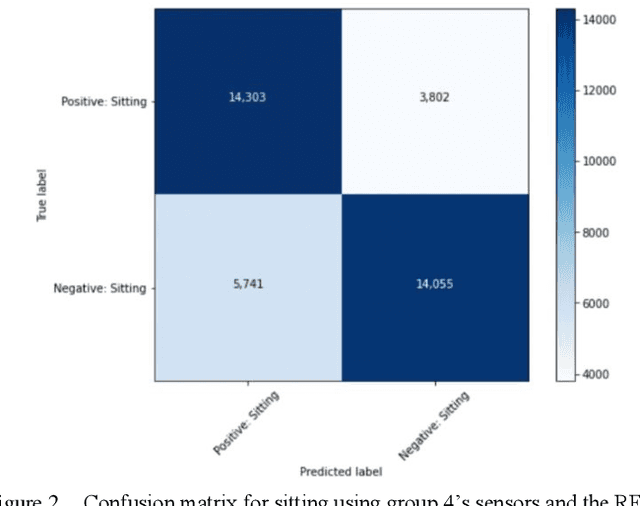
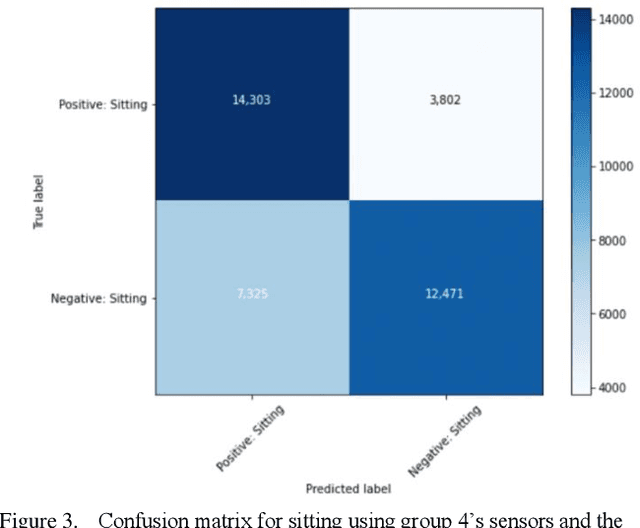
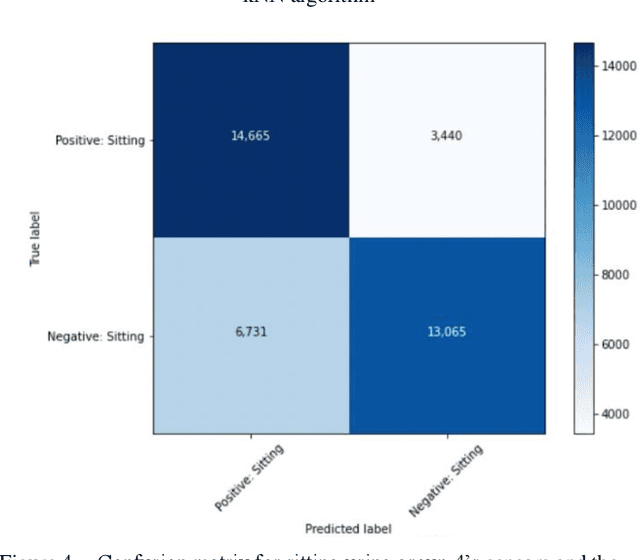
Human activity recognition has grown in popularity with its increase of applications within daily lifestyles and medical environments. The goal of having efficient and reliable human activity recognition brings benefits such as accessible use and better allocation of resources; especially in the medical industry. Activity recognition and classification can be obtained using many sophisticated data recording setups, but there is also a need in observing how performance varies among models that are strictly limited to using sensor data from easily accessible devices: smartphones and smartwatches. This paper presents the findings of different models that are limited to train using such sensors. The models are trained using either the k-Nearest Neighbor, Support Vector Machine, or Random Forest classifier algorithms. Performance and evaluations are done by comparing various model performances using different combinations of mobile sensors and how they affect recognitive performances of models. Results show promise for models trained strictly using limited sensor data collected from only smartphones and smartwatches coupled with traditional machine learning concepts and algorithms.