 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Backchannel Detection and Agreement Estimation from Video with Transformer Networks
Jun 02, 2023



Listeners use short interjections, so-called backchannels, to signify attention or express agreement. The automatic analysis of this behavior is of key importance for human conversation analysis and interactive conversational agents. Current state-of-the-art approaches for backchannel analysis from visual behavior make use of two types of features: features based on body pose and features based on facial behavior. At the same time, transformer neural networks have been established as an effective means to fuse input from different data sources, but they have not yet been applied to backchannel analysis. In this work, we conduct a comprehensive evaluation of multi-modal transformer architectures for automatic backchannel analysis based on pose and facial information. We address both the detection of backchannels as well as the task of estimating the agreement expressed in a backchannel. In evaluations on the MultiMediate'22 backchannel detection challenge, we reach 66.4% accuracy with a one-layer transformer architecture, outperforming the previous state of the art. With a two-layer transformer architecture, we furthermore set a new state of the art (0.0604 MSE) on the task of estimating the amount of agreement expressed in a backchannel.
Leveraging the Triple Exponential Moving Average for Fast-Adaptive Moment Estimation
Jun 02, 2023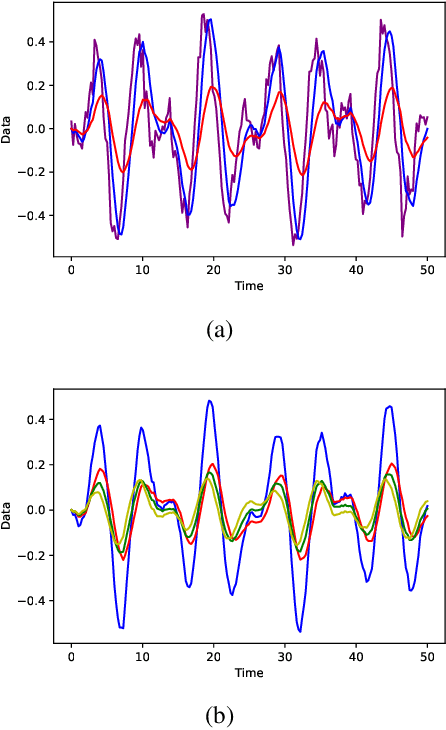
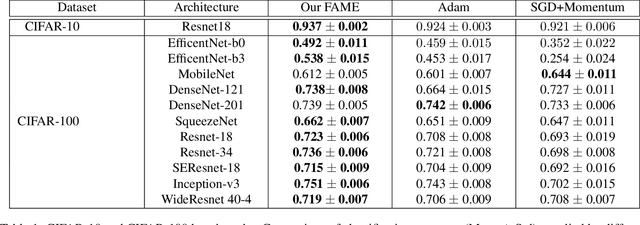
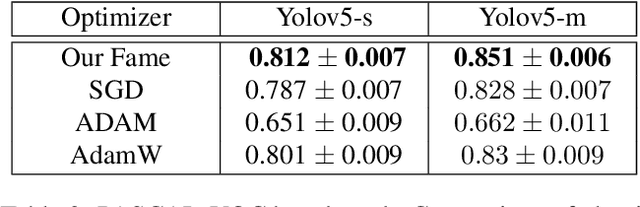
Network optimization is a crucial step in the field of deep learning, as it directly affects the performance of models in various domains such as computer vision. Despite the numerous optimizers that have been developed over the years, the current methods are still limited in their ability to accurately and quickly identify gradient trends, which can lead to sub-optimal network performance. In this paper, we propose a novel deep optimizer called Fast-Adaptive Moment Estimation (FAME), which for the first time estimates gradient moments using a Triple Exponential Moving Average (TEMA). Incorporating TEMA into the optimization process provides richer and more accurate information on data changes and trends, as compared to the standard Exponential Moving Average used in essentially all current leading adaptive optimization methods. Our proposed FAME optimizer has been extensively validated through a wide range of benchmarks, including CIFAR-10, CIFAR-100, PASCAL-VOC, MS-COCO, and Cityscapes, using 14 different learning architectures, six optimizers, and various vision tasks, including detection, classification and semantic understanding. The results demonstrate that our FAME optimizer outperforms other leading optimizers in terms of both robustness and accuracy.
Video Colorization with Pre-trained Text-to-Image Diffusion Models
Jun 02, 2023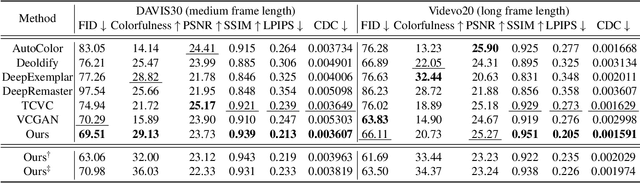
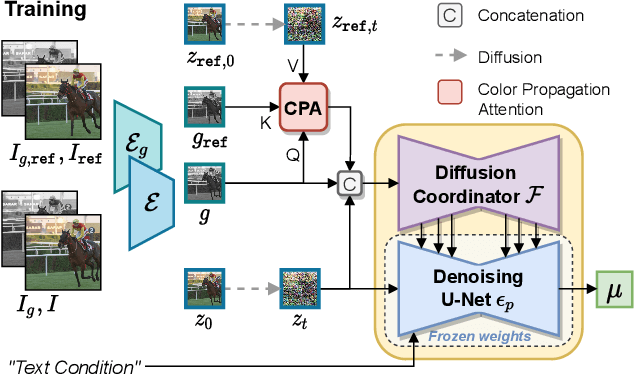
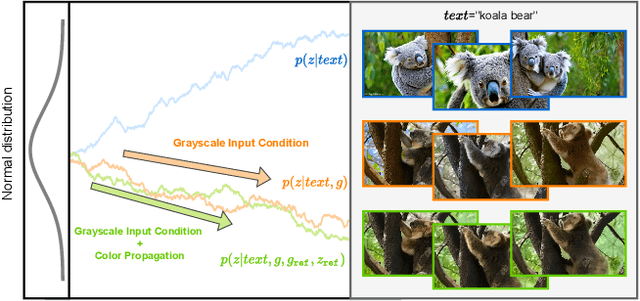

Video colorization is a challenging task that involves inferring plausible and temporally consistent colors for grayscale frames. In this paper, we present ColorDiffuser, an adaptation of a pre-trained text-to-image latent diffusion model for video colorization. With the proposed adapter-based approach, we repropose the pre-trained text-to-image model to accept input grayscale video frames, with the optional text description, for video colorization. To enhance the temporal coherence and maintain the vividness of colorization across frames, we propose two novel techniques: the Color Propagation Attention and Alternated Sampling Strategy. Color Propagation Attention enables the model to refine its colorization decision based on a reference latent frame, while Alternated Sampling Strategy captures spatiotemporal dependencies by using the next and previous adjacent latent frames alternatively as reference during the generative diffusion sampling steps. This encourages bidirectional color information propagation between adjacent video frames, leading to improved color consistency across frames. We conduct extensive experiments on benchmark datasets, and the results demonstrate the effectiveness of our proposed framework. The evaluations show that ColorDiffuser achieves state-of-the-art performance in video colorization, surpassing existing methods in terms of color fidelity, temporal consistency, and visual quality.
Using Caterpillar to Nibble Small-Scale Images
May 28, 2023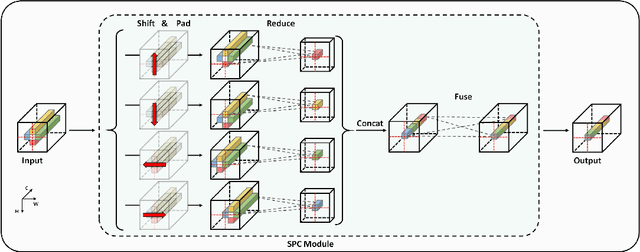
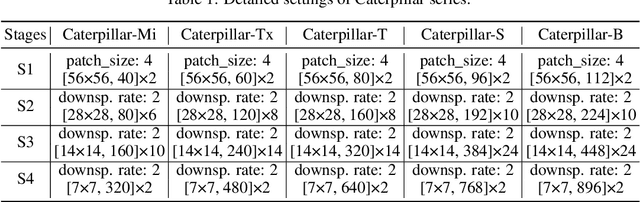
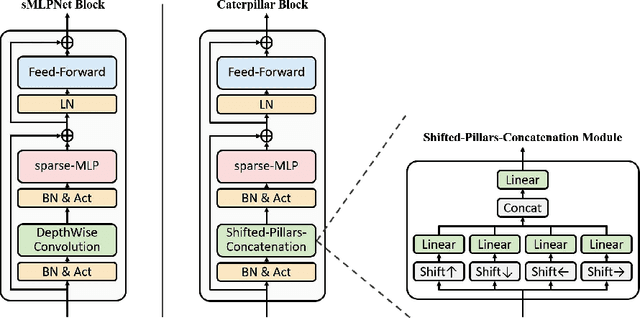
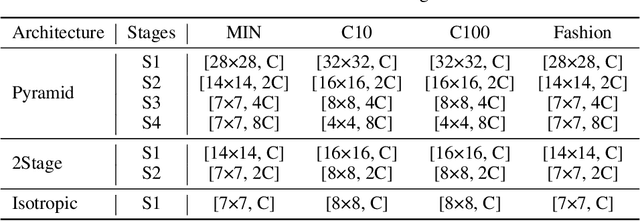
Recently, MLP-based models have become popular and attained significant performance on medium-scale datasets (e.g., ImageNet-1k). However, their direct applications to small-scale images remain limited. To address this issue, we design a new MLP-based network, namely Caterpillar, by proposing a key module of Shifted-Pillars-Concatenation (SPC) for exploiting the inductive bias of locality. SPC consists of two processes: (1) Pillars-Shift, which is to shift all pillars within an image along different directions to generate copies, and (2) Pillars-Concatenation, which is to capture the local information from discrete shift neighborhoods of the shifted copies. Extensive experiments demonstrate its strong scalability and superior performance on popular small-scale datasets, and the competitive performance on ImageNet-1K to recent state-of-the-art methods.
KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models
May 28, 2023


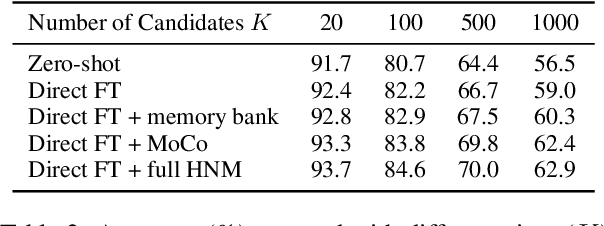
Image ad understanding is a crucial task with wide real-world applications. Although highly challenging with the involvement of diverse atypical scenes, real-world entities, and reasoning over scene-texts, how to interpret image ads is relatively under-explored, especially in the era of foundational vision-language models (VLMs) featuring impressive generalizability and adaptability. In this paper, we perform the first empirical study of image ad understanding through the lens of pre-trained VLMs. We benchmark and reveal practical challenges in adapting these VLMs to image ad understanding. We propose a simple feature adaptation strategy to effectively fuse multimodal information for image ads and further empower it with knowledge of real-world entities. We hope our study draws more attention to image ad understanding which is broadly relevant to the advertising industry.
Retrieving Multimodal Information for Augmented Generation: A Survey
Mar 20, 2023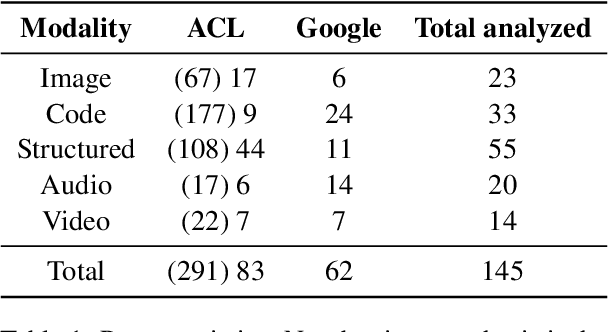
In this survey, we review methods that retrieve multimodal knowledge to assist and augment generative models. This group of works focuses on retrieving grounding contexts from external sources, including images, codes, tables, graphs, and audio. As multimodal learning and generative AI have become more and more impactful, such retrieval augmentation offers a promising solution to important concerns such as factuality, reasoning, interpretability, and robustness. We provide an in-depth review of retrieval-augmented generation in different modalities and discuss potential future directions. As this is an emerging field, we continue to add new papers and methods.
TEC-Net: Vision Transformer Embrace Convolutional Neural Networks for Medical Image Segmentation
Jun 07, 2023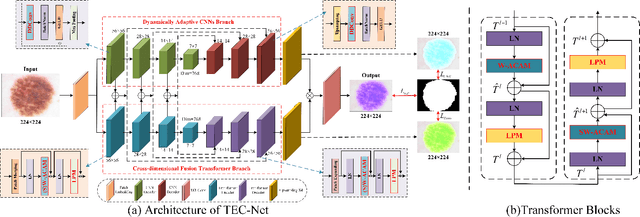
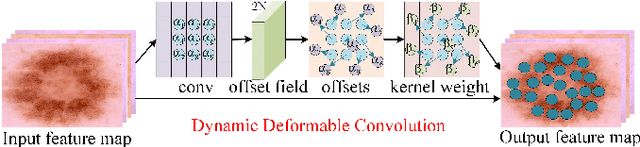
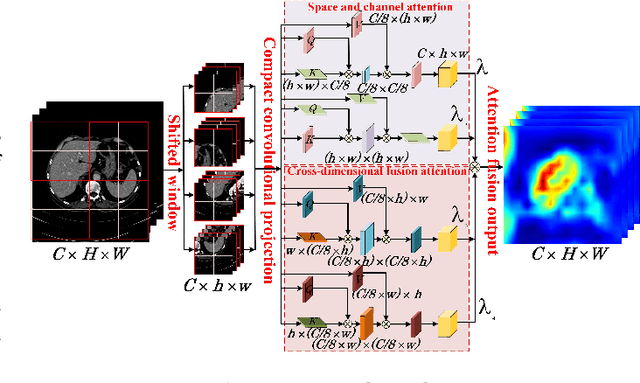
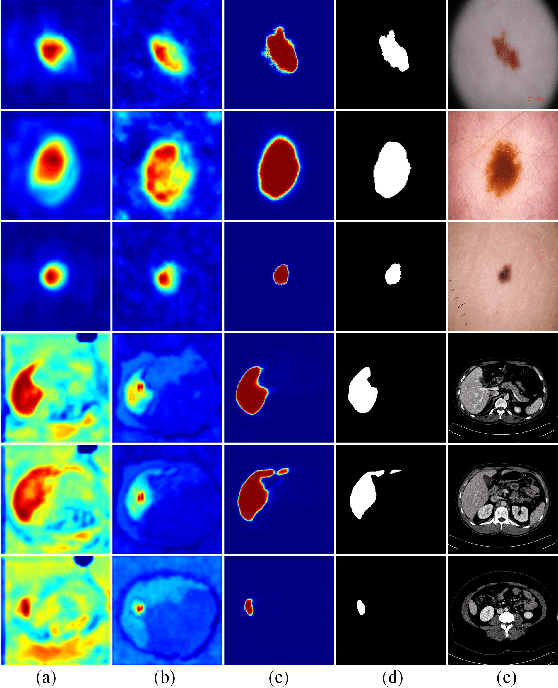
The hybrid architecture of convolution neural networks (CNN) and Transformer has been the most popular method for medical image segmentation. However, the existing networks based on the hybrid architecture suffer from two problems. First, although the CNN branch can capture image local features by using convolution operation, the vanilla convolution is unable to achieve adaptive extraction of image features. Second, although the Transformer branch can model the global information of images, the conventional self-attention only focuses on the spatial self-attention of images and ignores the channel and cross-dimensional self-attention leading to low segmentation accuracy for medical images with complex backgrounds. To solve these problems, we propose vision Transformer embrace convolutional neural networks for medical image segmentation (TEC-Net). Our network has two advantages. First, dynamic deformable convolution (DDConv) is designed in the CNN branch, which not only overcomes the difficulty of adaptive feature extraction using fixed-size convolution kernels, but also solves the defect that different inputs share the same convolution kernel parameters, effectively improving the feature expression ability of CNN branch. Second, in the Transformer branch, a (shifted)-window adaptive complementary attention module ((S)W-ACAM) and compact convolutional projection are designed to enable the network to fully learn the cross-dimensional long-range dependency of medical images with few parameters and calculations. Experimental results show that the proposed TEC-Net provides better medical image segmentation results than SOTA methods including CNN and Transformer networks. In addition, our TEC-Net requires fewer parameters and computational costs and does not rely on pre-training. The code is publicly available at https://github.com/SR0920/TEC-Net.
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models
Jun 07, 2023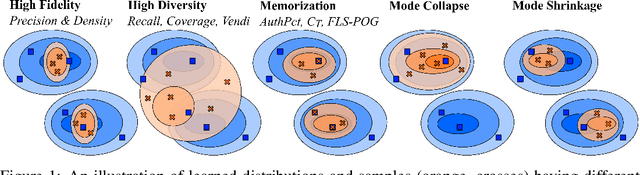

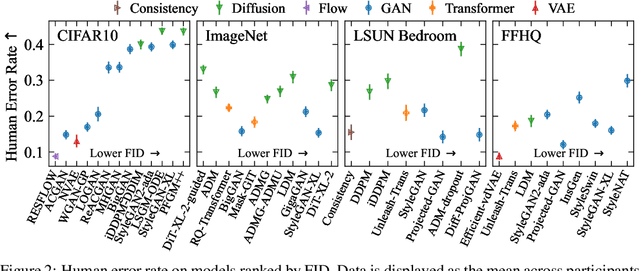
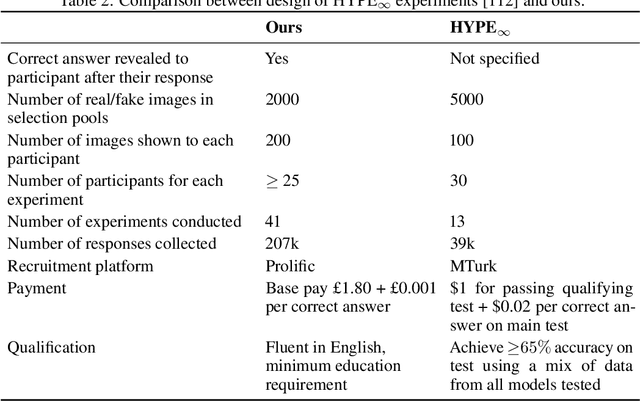
We systematically study a wide variety of image-based generative models spanning semantically-diverse datasets to understand and improve the feature extractors and metrics used to evaluate them. Using best practices in psychophysics, we measure human perception of image realism for generated samples by conducting the largest experiment evaluating generative models to date, and find that no existing metric strongly correlates with human evaluations. Comparing to 16 modern metrics for evaluating the overall performance, fidelity, diversity, and memorization of generative models, we find that the state-of-the-art perceptual realism of diffusion models as judged by humans is not reflected in commonly reported metrics such as FID. This discrepancy is not explained by diversity in generated samples, though one cause is over-reliance on Inception-V3. We address these flaws through a study of alternative self-supervised feature extractors, find that the semantic information encoded by individual networks strongly depends on their training procedure, and show that DINOv2-ViT-L/14 allows for much richer evaluation of generative models. Next, we investigate data memorization, and find that generative models do memorize training examples on simple, smaller datasets like CIFAR10, but not necessarily on more complex datasets like ImageNet. However, our experiments show that current metrics do not properly detect memorization; none in the literature is able to separate memorization from other phenomena such as underfitting or mode shrinkage. To facilitate further development of generative models and their evaluation we release all generated image datasets, human evaluation data, and a modular library to compute 16 common metrics for 8 different encoders at https://github.com/layer6ai-labs/dgm-eval.
GPT4Image: Can Large Pre-trained Models Help Vision Models on Perception Tasks?
Jun 07, 2023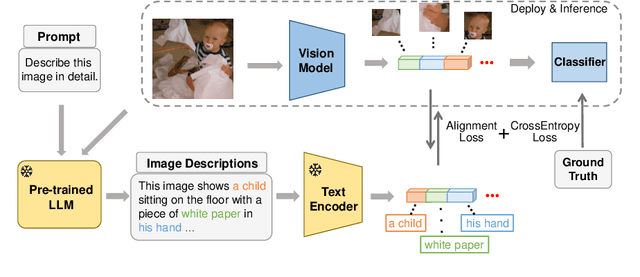
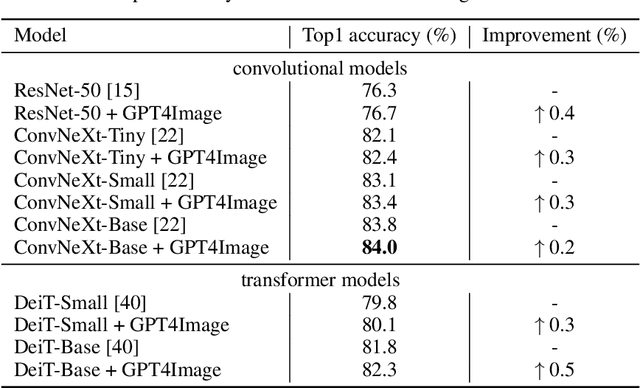

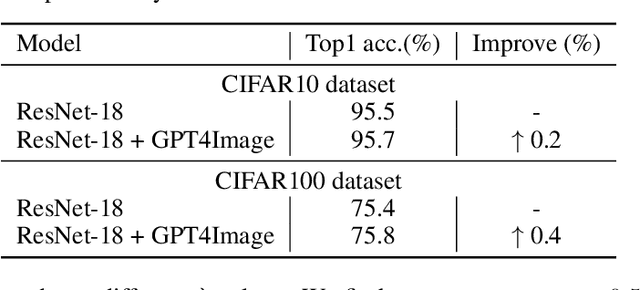
The recent upsurge in pre-trained large models (e.g. GPT-4) has swept across the entire deep learning community. Such powerful large language models (LLMs) demonstrate advanced generative ability and multimodal understanding capability, which quickly achieve new state-of-the-art performances on a variety of benchmarks. The pre-trained LLM usually plays the role as a universal AI model that can conduct various tasks, including context reasoning, article analysis and image content comprehension. However, considering the prohibitively high memory and computational cost for implementing such a large model, the conventional models (such as CNN and ViT), are still essential for many visual perception tasks. In this paper, we propose to enhance the representation ability of ordinary vision models for perception tasks (e.g. image classification) by taking advantage of large pre-trained models. We present a new learning paradigm in which the knowledge extracted from large pre-trained models are utilized to help models like CNN and ViT learn enhanced representations and achieve better performance. Firstly, we curate a high quality description set by prompting a multimodal LLM to generate descriptive text for all training images. Furthermore, we feed these detailed descriptions into a pre-trained encoder to extract text embeddings with rich semantic information that encodes the content of images. During training, text embeddings will serve as extra supervising signals and be aligned with image representations learned by vision models. The alignment process helps vision models learn better and achieve higher accuracy with the assistance of pre-trained LLMs. We conduct extensive experiments to verify that the proposed algorithm consistently improves the performance for various vision models with heterogeneous architectures.
A bioinspired three-stage model for camouflaged object detection
May 22, 2023
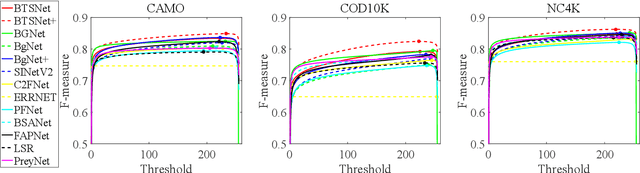


Camouflaged objects are typically assimilated into their backgrounds and exhibit fuzzy boundaries. The complex environmental conditions and the high intrinsic similarity between camouflaged targets and their surroundings pose significant challenges in accurately locating and segmenting these objects in their entirety. While existing methods have demonstrated remarkable performance in various real-world scenarios, they still face limitations when confronted with difficult cases, such as small targets, thin structures, and indistinct boundaries. Drawing inspiration from human visual perception when observing images containing camouflaged objects, we propose a three-stage model that enables coarse-to-fine segmentation in a single iteration. Specifically, our model employs three decoders to sequentially process subsampled features, cropped features, and high-resolution original features. This proposed approach not only reduces computational overhead but also mitigates interference caused by background noise. Furthermore, considering the significance of multi-scale information, we have designed a multi-scale feature enhancement module that enlarges the receptive field while preserving detailed structural cues. Additionally, a boundary enhancement module has been developed to enhance performance by leveraging boundary information. Subsequently, a mask-guided fusion module is proposed to generate fine-grained results by integrating coarse prediction maps with high-resolution feature maps. Our network surpasses state-of-the-art CNN-based counterparts without unnecessary complexities. Upon acceptance of the paper, the source code will be made publicly available at https://github.com/clelouch/BTSNet.