 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Fine-Tuning Two-Step Diffusion Models via Learning Differentiable Latent-Space Surrogate Reward
Nov 22, 2024Recent research has shown that fine-tuning diffusion models (DMs) with arbitrary rewards, including non-differentiable ones, is feasible with reinforcement learning (RL) techniques, enabling flexible model alignment. However, applying existing RL methods to timestep-distilled DMs is challenging for ultra-fast ($\le2$-step) image generation. Our analysis suggests several limitations of policy-based RL methods such as PPO or DPO toward this goal. Based on the insights, we propose fine-tuning DMs with learned differentiable surrogate rewards. Our method, named LaSRO, learns surrogate reward models in the latent space of SDXL to convert arbitrary rewards into differentiable ones for efficient reward gradient guidance. LaSRO leverages pre-trained latent DMs for reward modeling and specifically targets image generation $\le2$ steps for reward optimization, enhancing generalizability and efficiency. LaSRO is effective and stable for improving ultra-fast image generation with different reward objectives, outperforming popular RL methods including PPO and DPO. We further show LaSRO's connection to value-based RL, providing theoretical insights. See our webpage at https://sites.google.com/view/lasro.
KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models
May 28, 2023



Image ad understanding is a crucial task with wide real-world applications. Although highly challenging with the involvement of diverse atypical scenes, real-world entities, and reasoning over scene-texts, how to interpret image ads is relatively under-explored, especially in the era of foundational vision-language models (VLMs) featuring impressive generalizability and adaptability. In this paper, we perform the first empirical study of image ad understanding through the lens of pre-trained VLMs. We benchmark and reveal practical challenges in adapting these VLMs to image ad understanding. We propose a simple feature adaptation strategy to effectively fuse multimodal information for image ads and further empower it with knowledge of real-world entities. We hope our study draws more attention to image ad understanding which is broadly relevant to the advertising industry.
Chain-of-Thought Predictive Control
Apr 03, 2023



We study generalizable policy learning from demonstrations for complex low-level control tasks (e.g., contact-rich object manipulations). We propose an imitation learning method that incorporates the idea of temporal abstraction and the planning capabilities from Hierarchical RL (HRL) in a novel and effective manner. As a step towards decision foundation models, our design can utilize scalable, albeit highly sub-optimal, demonstrations. Specifically, we find certain short subsequences of the demos, i.e. the chain-of-thought (CoT), reflect their hierarchical structures by marking the completion of subgoals in the tasks. Our model learns to dynamically predict the entire CoT as coherent and structured long-term action guidance and consistently outperforms typical two-stage subgoal-conditioned policies. On the other hand, such CoT facilitates generalizable policy learning as they exemplify the decision patterns shared among demos (even those with heavy noises and randomness). Our method, Chain-of-Thought Predictive Control (CoTPC), significantly outperforms existing ones on challenging low-level manipulation tasks from scalable yet highly sub-optimal demos.
MetaCLUE: Towards Comprehensive Visual Metaphors Research
Dec 19, 2022



Creativity is an indispensable part of human cognition and also an inherent part of how we make sense of the world. Metaphorical abstraction is fundamental in communicating creative ideas through nuanced relationships between abstract concepts such as feelings. While computer vision benchmarks and approaches predominantly focus on understanding and generating literal interpretations of images, metaphorical comprehension of images remains relatively unexplored. Towards this goal, we introduce MetaCLUE, a set of vision tasks on visual metaphor. We also collect high-quality and rich metaphor annotations (abstract objects, concepts, relationships along with their corresponding object boxes) as there do not exist any datasets that facilitate the evaluation of these tasks. We perform a comprehensive analysis of state-of-the-art models in vision and language based on our annotations, highlighting strengths and weaknesses of current approaches in visual metaphor Classification, Localization, Understanding (retrieval, question answering, captioning) and gEneration (text-to-image synthesis) tasks. We hope this work provides a concrete step towards developing AI systems with human-like creative capabilities.
Improving Policy Optimization with Generalist-Specialist Learning
Jun 26, 2022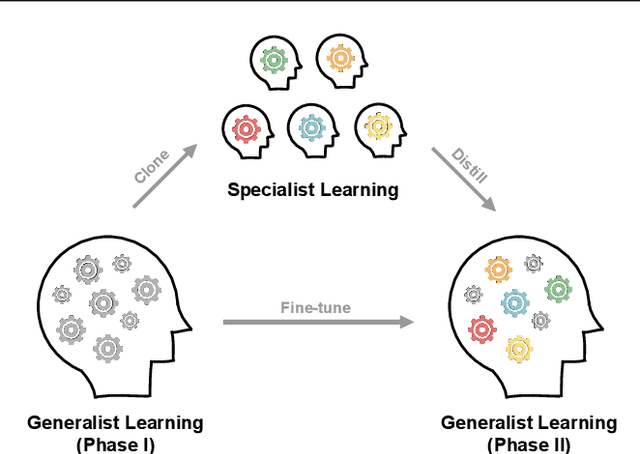

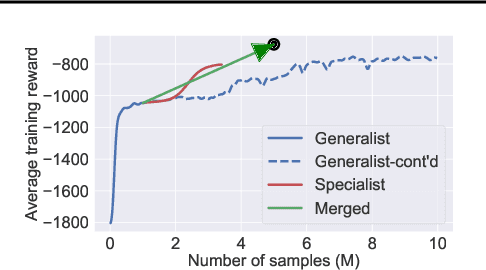

Generalization in deep reinforcement learning over unseen environment variations usually requires policy learning over a large set of diverse training variations. We empirically observe that an agent trained on many variations (a generalist) tends to learn faster at the beginning, yet its performance plateaus at a less optimal level for a long time. In contrast, an agent trained only on a few variations (a specialist) can often achieve high returns under a limited computational budget. To have the best of both worlds, we propose a novel generalist-specialist training framework. Specifically, we first train a generalist on all environment variations; when it fails to improve, we launch a large population of specialists with weights cloned from the generalist, each trained to master a selected small subset of variations. We finally resume the training of the generalist with auxiliary rewards induced by demonstrations of all specialists. In particular, we investigate the timing to start specialist training and compare strategies to learn generalists with assistance from specialists. We show that this framework pushes the envelope of policy learning on several challenging and popular benchmarks including Procgen, Meta-World and ManiSkill.
Learning to Act with Affordance-Aware Multimodal Neural SLAM
Feb 04, 2022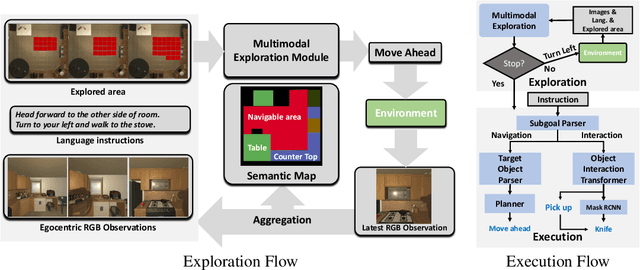

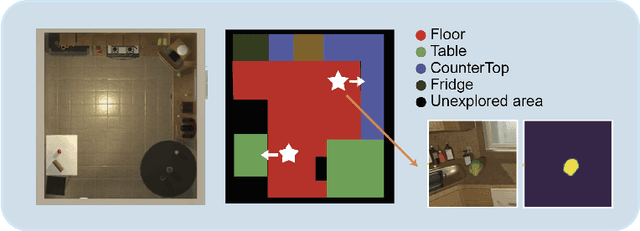
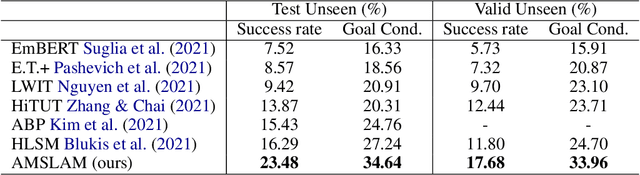
Recent years have witnessed an emerging paradigm shift toward embodied artificial intelligence, in which an agent must learn to solve challenging tasks by interacting with its environment. There are several challenges in solving embodied multimodal tasks, including long-horizon planning, vision-and-language grounding, and efficient exploration. We focus on a critical bottleneck, namely the performance of planning and navigation. To tackle this challenge, we propose a Neural SLAM approach that, for the first time, utilizes several modalities for exploration, predicts an affordance-aware semantic map, and plans over it at the same time. This significantly improves exploration efficiency, leads to robust long-horizon planning, and enables effective vision-and-language grounding. With the proposed Affordance-aware Multimodal Neural SLAM (AMSLAM) approach, we obtain more than $40\%$ improvement over prior published work on the ALFRED benchmark and set a new state-of-the-art generalization performance at a success rate of $23.48\%$ on the test unseen scenes.
TRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance
Nov 16, 2021
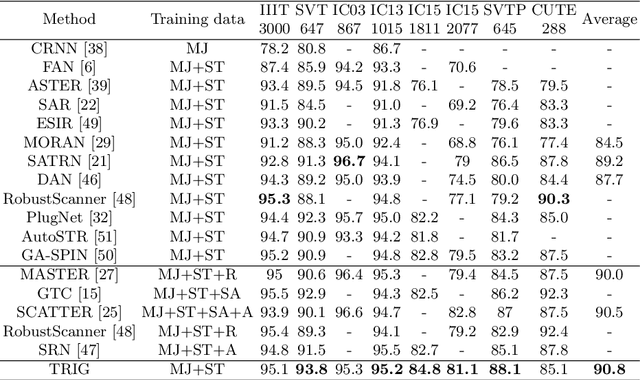
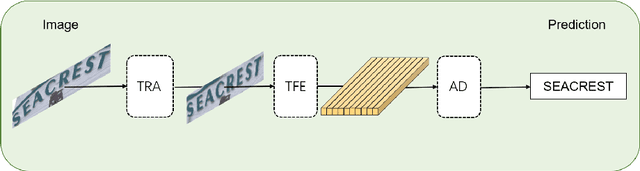
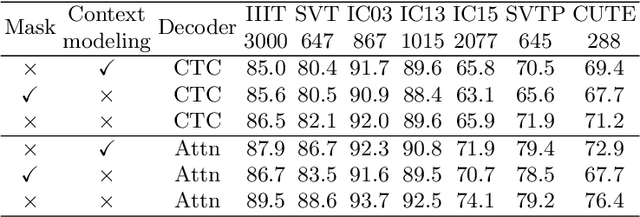
Scene text recognition (STR) is an important bridge between images and text, attracting abundant research attention. While convolutional neural networks (CNNS) have achieved remarkable progress in this task, most of the existing works need an extra module (context modeling module) to help CNN to capture global dependencies to solve the inductive bias and strengthen the relationship between text features. Recently, the transformer has been proposed as a promising network for global context modeling by self-attention mechanism, but one of the main shortcomings, when applied to recognition, is the efficiency. We propose a 1-D split to address the challenges of complexity and replace the CNN with the transformer encoder to reduce the need for a context modeling module. Furthermore, recent methods use a frozen initial embedding to guide the decoder to decode the features to text, leading to a loss of accuracy. We propose to use a learnable initial embedding learned from the transformer encoder to make it adaptive to different input images. Above all, we introduce a novel architecture for text recognition, named TRansformer-based text recognizer with Initial embedding Guidance (TRIG), composed of three stages (transformation, feature extraction, and prediction). Extensive experiments show that our approach can achieve state-of-the-art on text recognition benchmarks.
LUMINOUS: Indoor Scene Generation for Embodied AI Challenges
Nov 10, 2021

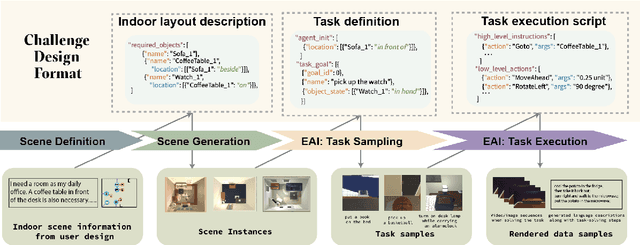
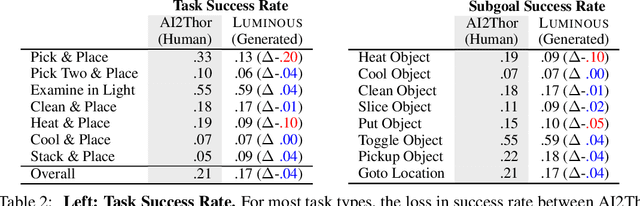
Learning-based methods for training embodied agents typically require a large number of high-quality scenes that contain realistic layouts and support meaningful interactions. However, current simulators for Embodied AI (EAI) challenges only provide simulated indoor scenes with a limited number of layouts. This paper presents Luminous, the first research framework that employs state-of-the-art indoor scene synthesis algorithms to generate large-scale simulated scenes for Embodied AI challenges. Further, we automatically and quantitatively evaluate the quality of generated indoor scenes via their ability to support complex household tasks. Luminous incorporates a novel scene generation algorithm (Constrained Stochastic Scene Generation (CSSG)), which achieves competitive performance with human-designed scenes. Within Luminous, the EAI task executor, task instruction generation module, and video rendering toolkit can collectively generate a massive multimodal dataset of new scenes for the training and evaluation of Embodied AI agents. Extensive experimental results demonstrate the effectiveness of the data generated by Luminous, enabling the comprehensive assessment of embodied agents on generalization and robustness.
IFR: Iterative Fusion Based Recognizer For Low Quality Scene Text Recognition
Aug 13, 2021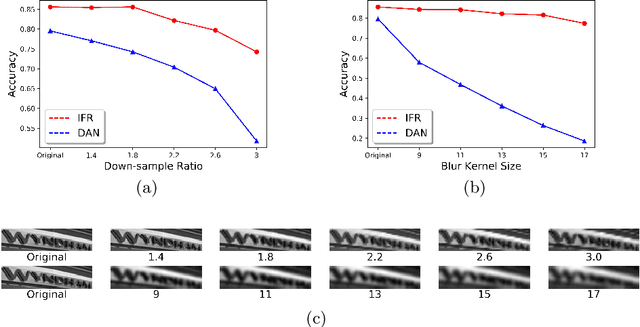
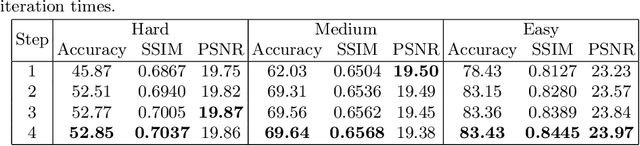


Although recent works based on deep learning have made progress in improving recognition accuracy on scene text recognition, how to handle low-quality text images in end-to-end deep networks remains a research challenge. In this paper, we propose an Iterative Fusion based Recognizer (IFR) for low quality scene text recognition, taking advantage of refined text images input and robust feature representation. IFR contains two branches which focus on scene text recognition and low quality scene text image recovery respectively. We utilize an iterative collaboration between two branches, which can effectively alleviate the impact of low quality input. A feature fusion module is proposed to strengthen the feature representation of the two branches, where the features from the Recognizer are Fused with image Restoration branch, referred to as RRF. Without changing the recognition network structure, extensive quantitative and qualitative experimental results show that the proposed method significantly outperforms the baseline methods in boosting the recognition accuracy of benchmark datasets and low resolution images in TextZoom dataset.
ManiSkill: Learning-from-Demonstrations Benchmark for Generalizable Manipulation Skills
Aug 09, 2021
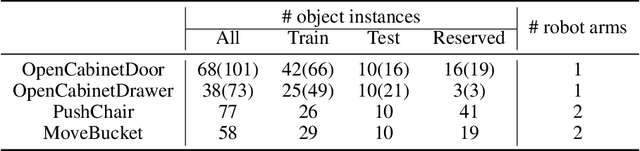
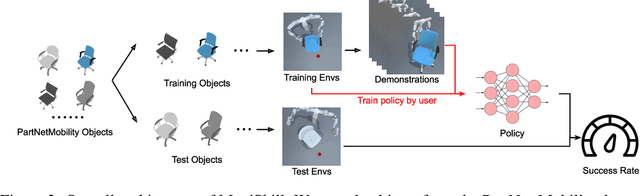

Learning generalizable manipulation skills is central for robots to achieve task automation in environments with endless scene and object variations. However, existing robot learning environments are limited in both scale and diversity of 3D assets (especially of articulated objects), making it difficult to train and evaluate the generalization ability of agents over novel objects. In this work, we focus on object-level generalization and propose SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill), a large-scale learning-from-demonstrations benchmark for articulated object manipulation with 3D visual input (point cloud and RGB-D image). ManiSkill supports object-level variations by utilizing a rich and diverse set of articulated objects, and each task is carefully designed for learning manipulations on a single category of objects. We equip ManiSkill with a large number of high-quality demonstrations to facilitate learning-from-demonstrations approaches and perform evaluations on baseline algorithms. We believe that ManiSkill can encourage the robot learning community to explore more on learning generalizable object manipulation skills.