 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Less, Know More: State-Aware Reasoning Compression with Knowledge Guidance for Efficient Reasoning
Apr 10, 2026Large Reasoning Models (LRMs) achieve strong performance on complex tasks by leveraging long Chain-of-Thought (CoT), but often suffer from overthinking, leading to excessive reasoning steps and high inference latency. Existing CoT compression methods struggle to balance accuracy and efficiency, and lack fine-grained, step-level adaptation to redundancy and reasoning bias. Therefore, we propose State-Aware Reasoning Compression with Knowledge Guidance (STACK), a framework that performs step-wise CoT compression by explicitly modeling stage-specific redundancy sources and integrating with a retrieval-augmented guidance. STACK constructs online long-short contrastive samples and dynamically switches between knowledge-guided compression for uncertain or biased reasoning state and self-prompted compression for overly long but confident state, complemented by an answer-convergence-based early stopping mechanism to suppress redundant verification. We further propose a reward-difference-driven training strategy by combining Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO), enabling models to learn state-conditioned compression strategies. Experiments on three mathematical reasoning benchmarks show that STACK achieves a superior accuracy-efficiency balance, reducing average response length by 59.9% while improving accuracy by 4.8 points over existing methods.
Response Quality Assessment for Retrieval-Augmented Generation via Conditional Conformal Factuality
Jun 26, 2025Existing research on Retrieval-Augmented Generation (RAG) primarily focuses on improving overall question-answering accuracy, often overlooking the quality of sub-claims within generated responses. Recent methods that attempt to improve RAG trustworthiness, such as through auto-evaluation metrics, lack probabilistic guarantees or require ground truth answers. To address these limitations, we propose Conformal-RAG, a novel framework inspired by recent applications of conformal prediction (CP) on large language models (LLMs). Conformal-RAG leverages CP and internal information from the RAG mechanism to offer statistical guarantees on response quality. It ensures group-conditional coverage spanning multiple sub-domains without requiring manual labelling of conformal sets, making it suitable for complex RAG applications. Compared to existing RAG auto-evaluation methods, Conformal-RAG offers statistical guarantees on the quality of refined sub-claims, ensuring response reliability without the need for ground truth answers. Additionally, our experiments demonstrate that by leveraging information from the RAG system, Conformal-RAG retains up to 60\% more high-quality sub-claims from the response compared to direct applications of CP to LLMs, while maintaining the same reliability guarantee.
Textual Bayes: Quantifying Uncertainty in LLM-Based Systems
Jun 11, 2025



Although large language models (LLMs) are becoming increasingly capable of solving challenging real-world tasks, accurately quantifying their uncertainty remains a critical open problem, which limits their applicability in high-stakes domains. This challenge is further compounded by the closed-source, black-box nature of many state-of-the-art LLMs. Moreover, LLM-based systems can be highly sensitive to the prompts that bind them together, which often require significant manual tuning (i.e., prompt engineering). In this work, we address these challenges by viewing LLM-based systems through a Bayesian lens. We interpret prompts as textual parameters in a statistical model, allowing us to use a small training dataset to perform Bayesian inference over these prompts. This novel perspective enables principled uncertainty quantification over both the model's textual parameters and its downstream predictions, while also incorporating prior beliefs about these parameters expressed in free-form text. To perform Bayesian inference, a difficult problem even for well-studied data modalities, we introduce Metropolis-Hastings through LLM Proposals (MHLP), a novel Markov chain Monte Carlo (MCMC) algorithm that combines prompt optimization techniques with standard MCMC methods. MHLP is a turnkey modification to existing LLM pipelines, including those that rely exclusively on closed-source models. Empirically, we demonstrate that our method yields improvements in both predictive accuracy and uncertainty quantification (UQ) on a range of LLM benchmarks and UQ tasks. More broadly, our work demonstrates a viable path for incorporating methods from the rich Bayesian literature into the era of LLMs, paving the way for more reliable and calibrated LLM-based systems.
Bridging External and Parametric Knowledge: Mitigating Hallucination of LLMs with Shared-Private Semantic Synergy in Dual-Stream Knowledge
Jun 06, 2025Retrieval-augmented generation (RAG) is a cost-effective approach to mitigate the hallucination of Large Language Models (LLMs) by incorporating the retrieved external knowledge into the generation process. However, external knowledge may conflict with the parametric knowledge of LLMs. Furthermore, current LLMs lack inherent mechanisms for resolving such knowledge conflicts, making traditional RAG methods suffer from degraded performance and stability. Thus, we propose a Dual-Stream Knowledge-Augmented Framework for Shared-Private Semantic Synergy (DSSP-RAG). Central to the framework is a novel approach that refines self-attention into a mixed-attention, distinguishing shared and private semantics for a controlled internal-external knowledge integration. To effectively facilitate DSSP in RAG, we further introduce an unsupervised hallucination detection method based on cognitive uncertainty, ensuring the necessity of introducing knowledge, and an Energy Quotient (EQ) based on attention difference matrices to reduce noise in the retrieved external knowledge. Extensive experiments on benchmark datasets show that DSSP-RAG can effectively resolve conflicts and enhance the complementarity of dual-stream knowledge, leading to superior performance over strong baselines.
DRESS: Disentangled Representation-based Self-Supervised Meta-Learning for Diverse Tasks
Mar 12, 2025Meta-learning represents a strong class of approaches for solving few-shot learning tasks. Nonetheless, recent research suggests that simply pre-training a generic encoder can potentially surpass meta-learning algorithms. In this paper, we first discuss the reasons why meta-learning fails to stand out in these few-shot learning experiments, and hypothesize that it is due to the few-shot learning tasks lacking diversity. We propose DRESS, a task-agnostic Disentangled REpresentation-based Self-Supervised meta-learning approach that enables fast model adaptation on highly diversified few-shot learning tasks. Specifically, DRESS utilizes disentangled representation learning to create self-supervised tasks that can fuel the meta-training process. Furthermore, we also propose a class-partition based metric for quantifying the task diversity directly on the input space. We validate the effectiveness of DRESS through experiments on datasets with multiple factors of variation and varying complexity. The results suggest that DRESS is able to outperform competing methods on the majority of the datasets and task setups. Through this paper, we advocate for a re-examination of proper setups for task adaptation studies, and aim to reignite interest in the potential of meta-learning for solving few-shot learning tasks via disentangled representations.
Conformal Prediction Sets Can Cause Disparate Impact
Oct 02, 2024Although conformal prediction is a promising method for quantifying the uncertainty of machine learning models, the prediction sets it outputs are not inherently actionable. Many applications require a single output to act on, not several. To overcome this, prediction sets can be provided to a human who then makes an informed decision. In any such system it is crucial to ensure the fairness of outcomes across protected groups, and researchers have proposed that Equalized Coverage be used as the standard for fairness. By conducting experiments with human participants, we demonstrate that providing prediction sets can increase the unfairness of their decisions. Disquietingly, we find that providing sets that satisfy Equalized Coverage actually increases unfairness compared to marginal coverage. Instead of equalizing coverage, we propose to equalize set sizes across groups which empirically leads to more fair outcomes.
Benchmarking Robust Self-Supervised Learning Across Diverse Downstream Tasks
Jul 18, 2024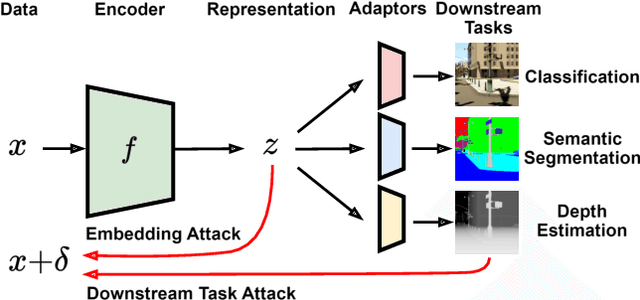
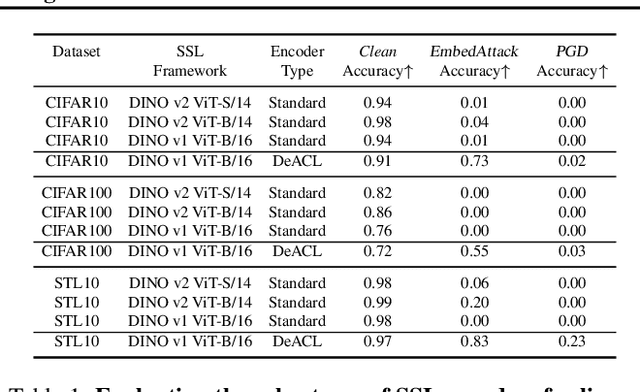
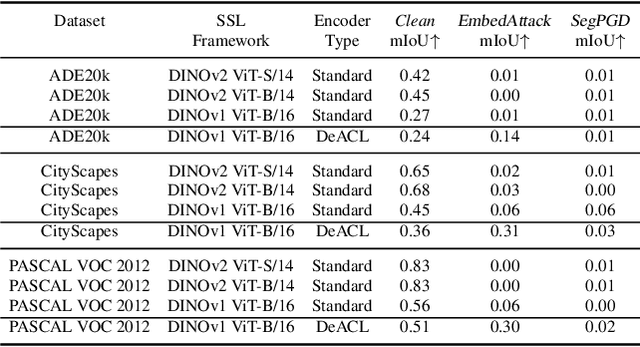
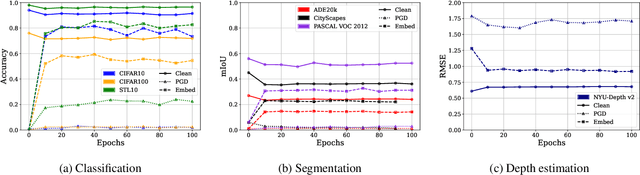
Large-scale vision models have become integral in many applications due to their unprecedented performance and versatility across downstream tasks. However, the robustness of these foundation models has primarily been explored for a single task, namely image classification. The vulnerability of other common vision tasks, such as semantic segmentation and depth estimation, remains largely unknown. We present a comprehensive empirical evaluation of the adversarial robustness of self-supervised vision encoders across multiple downstream tasks. Our attacks operate in the encoder embedding space and at the downstream task output level. In both cases, current state-of-the-art adversarial fine-tuning techniques tested only for classification significantly degrade clean and robust performance on other tasks. Since the purpose of a foundation model is to cater to multiple applications at once, our findings reveal the need to enhance encoder robustness more broadly. Our code is available at ${github.com/layer6ai-labs/ssl-robustness}$.
Tabular Data Contrastive Learning via Class-Conditioned and Feature-Correlation Based Augmentation
Apr 30, 2024



Contrastive learning is a model pre-training technique by first creating similar views of the original data, and then encouraging the data and its corresponding views to be close in the embedding space. Contrastive learning has witnessed success in image and natural language data, thanks to the domain-specific augmentation techniques that are both intuitive and effective. Nonetheless, in tabular domain, the predominant augmentation technique for creating views is through corrupting tabular entries via swapping values, which is not as sound or effective. We propose a simple yet powerful improvement to this augmentation technique: corrupting tabular data conditioned on class identity. Specifically, when corrupting a specific tabular entry from an anchor row, instead of randomly sampling a value in the same feature column from the entire table uniformly, we only sample from rows that are identified to be within the same class as the anchor row. We assume the semi-supervised learning setting, and adopt the pseudo labeling technique for obtaining class identities over all table rows. We also explore the novel idea of selecting features to be corrupted based on feature correlation structures. Extensive experiments show that the proposed approach consistently outperforms the conventional corruption method for tabular data classification tasks. Our code is available at https://github.com/willtop/Tabular-Class-Conditioned-SSL.
Conformal Prediction Sets Improve Human Decision Making
Feb 01, 2024



In response to everyday queries, humans explicitly signal uncertainty and offer alternative answers when they are unsure. Machine learning models that output calibrated prediction sets through conformal prediction mimic this human behaviour; larger sets signal greater uncertainty while providing alternatives. In this work, we study the usefulness of conformal prediction sets as an aid for human decision making by conducting a pre-registered randomized controlled trial with conformal prediction sets provided to human subjects. With statistical significance, we find that when humans are given conformal prediction sets their accuracy on tasks improves compared to fixed-size prediction sets with the same coverage guarantee. The results show that quantifying model uncertainty with conformal prediction is helpful for human-in-the-loop decision making and human-AI teams.
Equirectangular image construction method for standard CNNs for Semantic Segmentation
Oct 13, 2023



360{\deg} spherical images have advantages of wide view field, and are typically projected on a planar plane for processing, which is known as equirectangular image. The object shape in equirectangular images can be distorted and lack translation invariance. In addition, there are few publicly dataset of equirectangular images with labels, which presents a challenge for standard CNNs models to process equirectangular images effectively. To tackle this problem, we propose a methodology for converting a perspective image into equirectangular image. The inverse transformation of the spherical center projection and the equidistant cylindrical projection are employed. This enables the standard CNNs to learn the distortion features at different positions in the equirectangular image and thereby gain the ability to semantically the equirectangular image. The parameter, {\phi}, which determines the projection position of the perspective image, has been analyzed using various datasets and models, such as UNet, UNet++, SegNet, PSPNet, and DeepLab v3+. The experiments demonstrate that an optimal value of {\phi} for effective semantic segmentation of equirectangular images is 6{\pi}/16 for standard CNNs. Compared with the other three types of methods (supervised learning, unsupervised learning and data augmentation), the method proposed in this paper has the best average IoU value of 43.76%. This value is 23.85%, 10.7% and 17.23% higher than those of other three methods, respectively.