 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback
May 29, 2024



Diffusion-based text-to-video (T2V) models have achieved significant success but continue to be hampered by the slow sampling speed of their iterative sampling processes. To address the challenge, consistency models have been proposed to facilitate fast inference, albeit at the cost of sample quality. In this work, we aim to break the quality bottleneck of a video consistency model (VCM) to achieve $\textbf{both fast and high-quality video generation}$. We introduce T2V-Turbo, which integrates feedback from a mixture of differentiable reward models into the consistency distillation (CD) process of a pre-trained T2V model. Notably, we directly optimize rewards associated with single-step generations that arise naturally from computing the CD loss, effectively bypassing the memory constraints imposed by backpropagating gradients through an iterative sampling process. Remarkably, the 4-step generations from our T2V-Turbo achieve the highest total score on VBench, even surpassing Gen-2 and Pika. We further conduct human evaluations to corroborate the results, validating that the 4-step generations from our T2V-Turbo are preferred over the 50-step DDIM samples from their teacher models, representing more than a tenfold acceleration while improving video generation quality.
KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models
May 28, 2023



Image ad understanding is a crucial task with wide real-world applications. Although highly challenging with the involvement of diverse atypical scenes, real-world entities, and reasoning over scene-texts, how to interpret image ads is relatively under-explored, especially in the era of foundational vision-language models (VLMs) featuring impressive generalizability and adaptability. In this paper, we perform the first empirical study of image ad understanding through the lens of pre-trained VLMs. We benchmark and reveal practical challenges in adapting these VLMs to image ad understanding. We propose a simple feature adaptation strategy to effectively fuse multimodal information for image ads and further empower it with knowledge of real-world entities. We hope our study draws more attention to image ad understanding which is broadly relevant to the advertising industry.
LayoutGPT: Compositional Visual Planning and Generation with Large Language Models
May 24, 2023



Attaining a high degree of user controllability in visual generation often requires intricate, fine-grained inputs like layouts. However, such inputs impose a substantial burden on users when compared to simple text inputs. To address the issue, we study how Large Language Models (LLMs) can serve as visual planners by generating layouts from text conditions, and thus collaborate with visual generative models. We propose LayoutGPT, a method to compose in-context visual demonstrations in style sheet language to enhance the visual planning skills of LLMs. LayoutGPT can generate plausible layouts in multiple domains, ranging from 2D images to 3D indoor scenes. LayoutGPT also shows superior performance in converting challenging language concepts like numerical and spatial relations to layout arrangements for faithful text-to-image generation. When combined with a downstream image generation model, LayoutGPT outperforms text-to-image models/systems by 20-40% and achieves comparable performance as human users in designing visual layouts for numerical and spatial correctness. Lastly, LayoutGPT achieves comparable performance to supervised methods in 3D indoor scene synthesis, demonstrating its effectiveness and potential in multiple visual domains.
Discriminative Diffusion Models as Few-shot Vision and Language Learners
May 18, 2023



Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
MetaCLUE: Towards Comprehensive Visual Metaphors Research
Dec 19, 2022



Creativity is an indispensable part of human cognition and also an inherent part of how we make sense of the world. Metaphorical abstraction is fundamental in communicating creative ideas through nuanced relationships between abstract concepts such as feelings. While computer vision benchmarks and approaches predominantly focus on understanding and generating literal interpretations of images, metaphorical comprehension of images remains relatively unexplored. Towards this goal, we introduce MetaCLUE, a set of vision tasks on visual metaphor. We also collect high-quality and rich metaphor annotations (abstract objects, concepts, relationships along with their corresponding object boxes) as there do not exist any datasets that facilitate the evaluation of these tasks. We perform a comprehensive analysis of state-of-the-art models in vision and language based on our annotations, highlighting strengths and weaknesses of current approaches in visual metaphor Classification, Localization, Understanding (retrieval, question answering, captioning) and gEneration (text-to-image synthesis) tasks. We hope this work provides a concrete step towards developing AI systems with human-like creative capabilities.
Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis
Dec 09, 2022



Large-scale diffusion models have achieved state-of-the-art results on text-to-image synthesis (T2I) tasks. Despite their ability to generate high-quality yet creative images, we observe that attribution-binding and compositional capabilities are still considered major challenging issues, especially when involving multiple objects. In this work, we improve the compositional skills of T2I models, specifically more accurate attribute binding and better image compositions. To do this, we incorporate linguistic structures with the diffusion guidance process based on the controllable properties of manipulating cross-attention layers in diffusion-based T2I models. We observe that keys and values in cross-attention layers have strong semantic meanings associated with object layouts and content. Therefore, we can better preserve the compositional semantics in the generated image by manipulating the cross-attention representations based on linguistic insights. Built upon Stable Diffusion, a SOTA T2I model, our structured cross-attention design is efficient that requires no additional training samples. We achieve better compositional skills in qualitative and quantitative results, leading to a 5-8% advantage in head-to-head user comparison studies. Lastly, we conduct an in-depth analysis to reveal potential causes of incorrect image compositions and justify the properties of cross-attention layers in the generation process.
CPL: Counterfactual Prompt Learning for Vision and Language Models
Oct 19, 2022
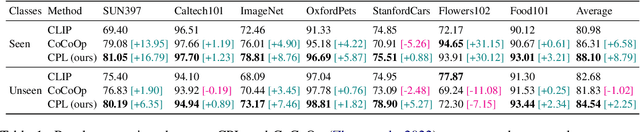
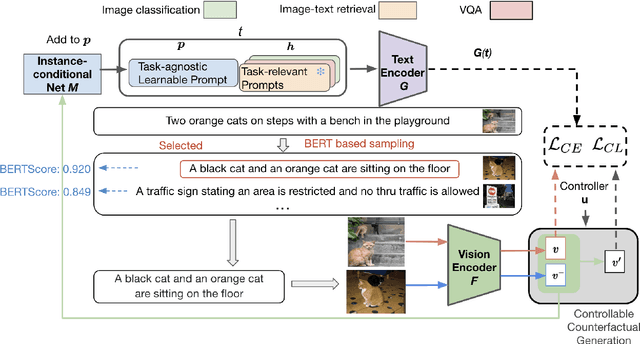
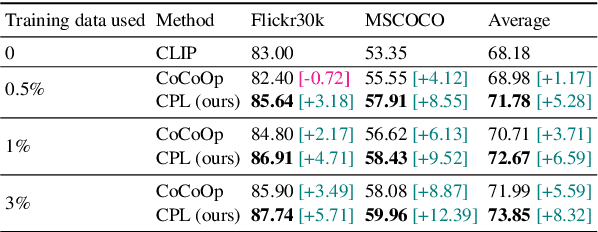
Prompt tuning is a new few-shot transfer learning technique that only tunes the learnable prompt for pre-trained vision and language models such as CLIP. However, existing prompt tuning methods tend to learn spurious or entangled representations, which leads to poor generalization to unseen concepts. Towards non-spurious and efficient prompt learning from limited examples, this paper presents a novel \underline{\textbf{C}}ounterfactual \underline{\textbf{P}}rompt \underline{\textbf{L}}earning (CPL) method for vision and language models, which simultaneously employs counterfactual generation and contrastive learning in a joint optimization framework. Particularly, CPL constructs counterfactual by identifying minimal non-spurious feature change between semantically-similar positive and negative samples that causes concept change, and learns more generalizable prompt representation from both factual and counterfactual examples via contrastive learning. Extensive experiments demonstrate that CPL can obtain superior few-shot performance on different vision and language tasks than previous prompt tuning methods on CLIP. On image classification, we achieve 3.55\% average relative improvement on unseen classes across seven datasets; on image-text retrieval and visual question answering, we gain up to 4.09\% and 25.08\% relative improvements across three few-shot scenarios on unseen test sets respectively.
Diagnosing Vision-and-Language Navigation: What Really Matters
Mar 30, 2021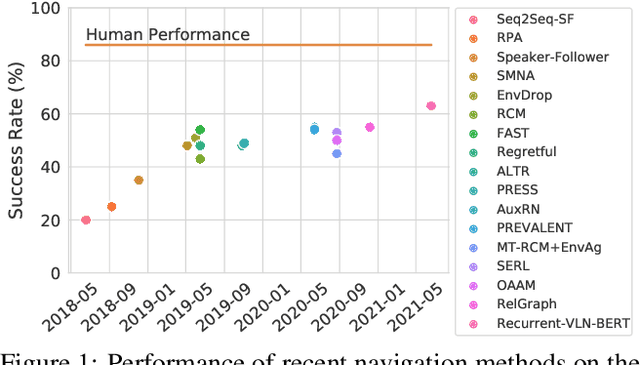

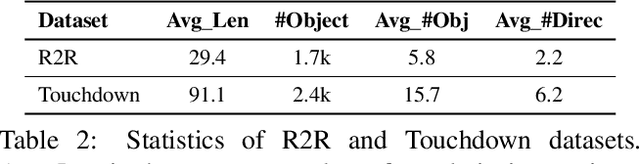
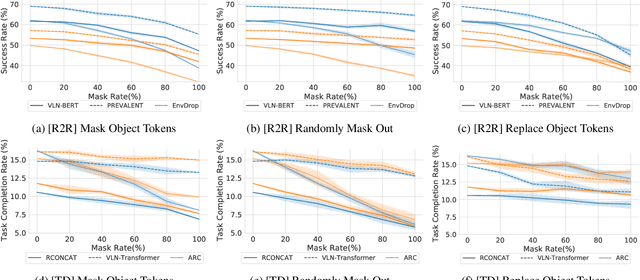
Vision-and-language navigation (VLN) is a multimodal task where an agent follows natural language instructions and navigates in visual environments. Multiple setups have been proposed, and researchers apply new model architectures or training techniques to boost navigation performance. However, recent studies witness a slow-down in the performance improvements in both indoor and outdoor VLN tasks, and the agents' inner mechanisms for making navigation decisions remain unclear. To the best of our knowledge, the way the agents perceive the multimodal input is under-studied and clearly needs investigations. In this work, we conduct a series of diagnostic experiments to unveil agents' focus during navigation. Results show that indoor navigation agents refer to both object tokens and direction tokens in the instruction when making decisions. In contrast, outdoor navigation agents heavily rely on direction tokens and have a poor understanding of the object tokens. Furthermore, instead of merely staring at surrounding objects, indoor navigation agents can set their sights on objects further from the current viewpoint. When it comes to vision-and-language alignments, many models claim that they are able to align object tokens with certain visual targets, but we cast doubt on the reliability of such alignments.
A Framework for Deep Constrained Clustering
Jan 07, 2021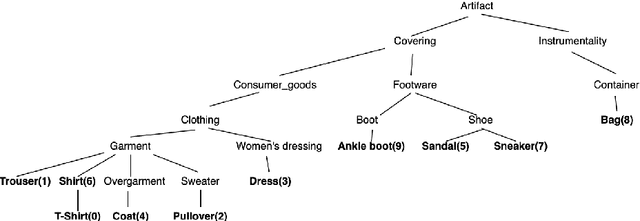

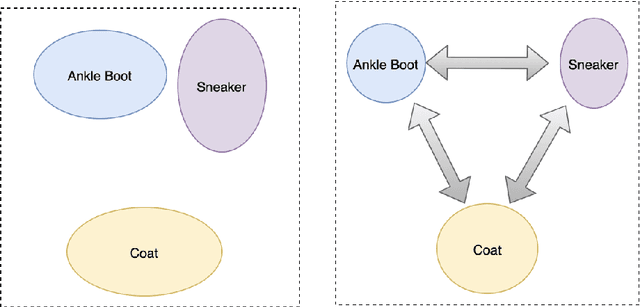
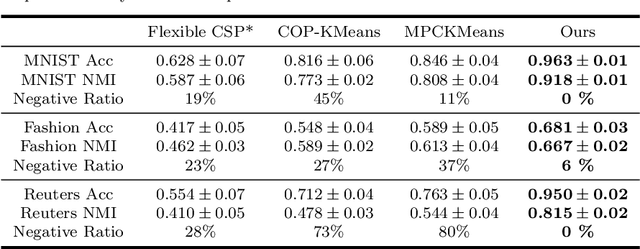
The area of constrained clustering has been extensively explored by researchers and used by practitioners. Constrained clustering formulations exist for popular algorithms such as k-means, mixture models, and spectral clustering but have several limitations. A fundamental strength of deep learning is its flexibility, and here we explore a deep learning framework for constrained clustering and in particular explore how it can extend the field of constrained clustering. We show that our framework can not only handle standard together/apart constraints (without the well documented negative effects reported earlier) generated from labeled side information but more complex constraints generated from new types of side information such as continuous values and high-level domain knowledge. Furthermore, we propose an efficient training paradigm that is generally applicable to these four types of constraints. We validate the effectiveness of our approach by empirical results on both image and text datasets. We also study the robustness of our framework when learning with noisy constraints and show how different components of our framework contribute to the final performance. Our source code is available at $\href{https://github.com/blueocean92/deep_constrained_clustering}{\text{URL}}$.
Towards Understanding Sample Variance in Visually Grounded Language Generation: Evaluations and Observations
Oct 07, 2020
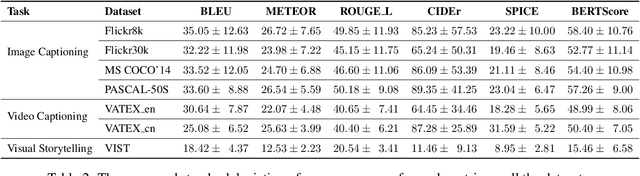
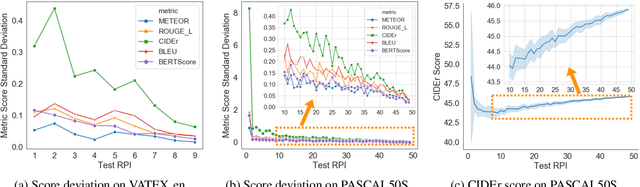
A major challenge in visually grounded language generation is to build robust benchmark datasets and models that can generalize well in real-world settings. To do this, it is critical to ensure that our evaluation protocols are correct, and benchmarks are reliable. In this work, we set forth to design a set of experiments to understand an important but often ignored problem in visually grounded language generation: given that humans have different utilities and visual attention, how will the sample variance in multi-reference datasets affect the models' performance? Empirically, we study several multi-reference datasets and corresponding vision-and-language tasks. We show that it is of paramount importance to report variance in experiments; that human-generated references could vary drastically in different datasets/tasks, revealing the nature of each task; that metric-wise, CIDEr has shown systematically larger variances than others. Our evaluations on reference-per-instance shed light on the design of reliable datasets in the future.