 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Estimation of control area in badminton doubles with pose information from top and back view drone videos
May 07, 2023
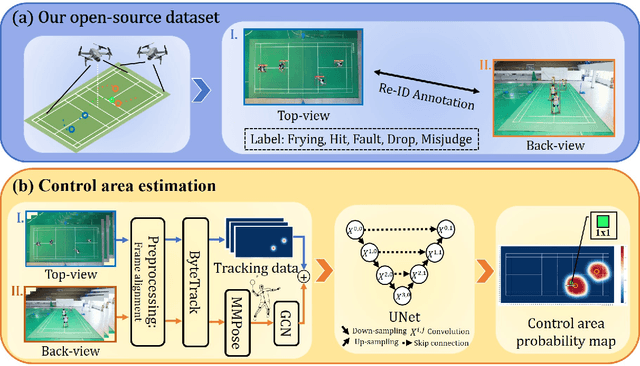

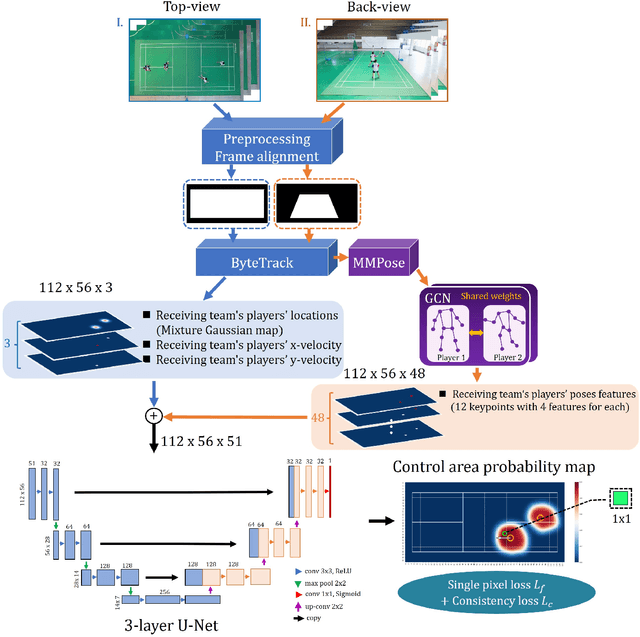
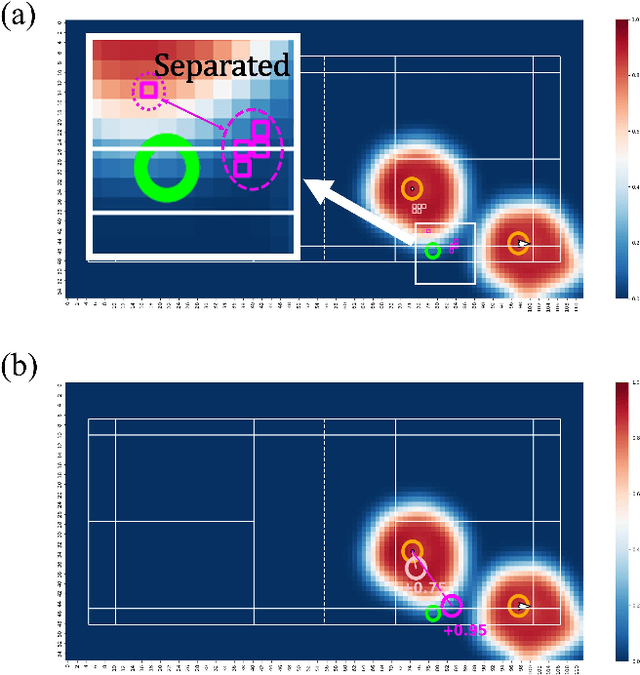
The application of visual tracking to the performance analysis of sports players in dynamic competitions is vital for effective coaching. In racket sports, most previous studies have focused on analyzing and assessing singles players without occlusion in broadcast videos and discrete representations (e.g., stroke) that ignore meaningful spatial distributions. In this work, we present the first annotated drone dataset from top and back views in badminton doubles and propose a framework to estimate the control area probability map, which can be used to evaluate teamwork performance. We present an efficient framework of deep neural networks that enables the calculation of full probability surfaces, which utilizes the embedding of a Gaussian mixture map of players' positions and graph convolution of their poses. In the experiment, we verify our approach by comparing various baselines and discovering the correlations between the score and control area. Furthermore, we propose the practical application of assessing optimal positioning to provide instructions during a game. Our approach can visually and quantitatively evaluate players' movements, providing valuable insights into doubles teamwork.
Frame-Event Alignment and Fusion Network for High Frame Rate Tracking
May 25, 2023
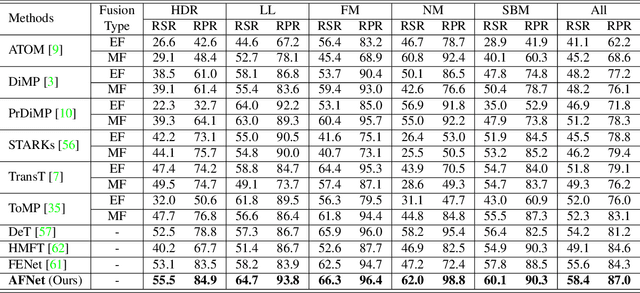
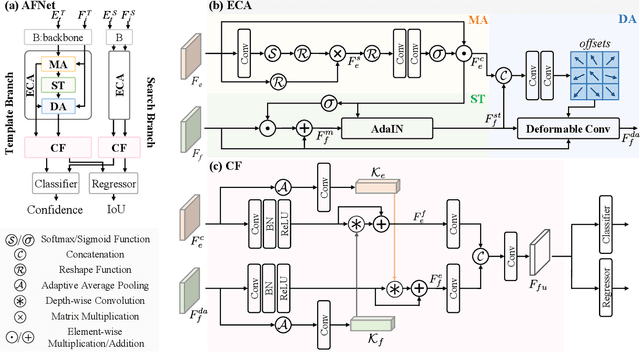
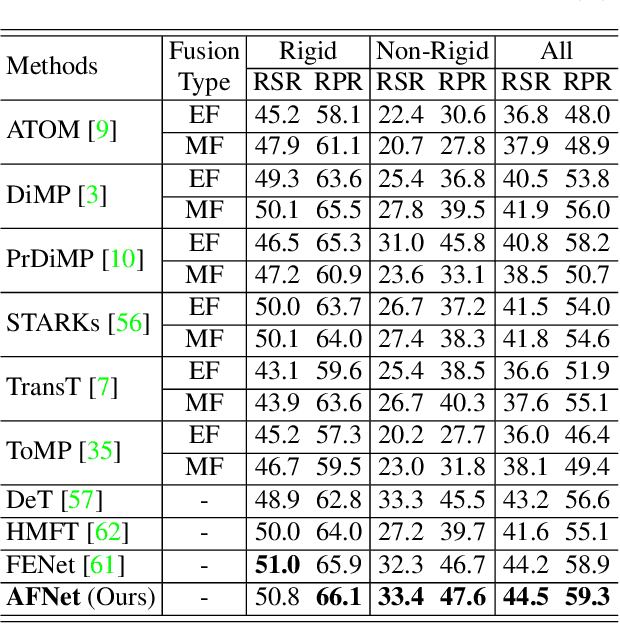
Most existing RGB-based trackers target low frame rate benchmarks of around 30 frames per second. This setting restricts the tracker's functionality in the real world, especially for fast motion. Event-based cameras as bioinspired sensors provide considerable potential for high frame rate tracking due to their high temporal resolution. However, event-based cameras cannot offer fine-grained texture information like conventional cameras. This unique complementarity motivates us to combine conventional frames and events for high frame rate object tracking under various challenging conditions. Inthispaper, we propose an end-to-end network consisting of multi-modality alignment and fusion modules to effectively combine meaningful information from both modalities at different measurement rates. The alignment module is responsible for cross-style and cross-frame-rate alignment between frame and event modalities under the guidance of the moving cues furnished by events. While the fusion module is accountable for emphasizing valuable features and suppressing noise information by the mutual complement between the two modalities. Extensive experiments show that the proposed approach outperforms state-of-the-art trackers by a significant margin in high frame rate tracking. With the FE240hz dataset, our approach achieves high frame rate tracking up to 240Hz.
Mimicking the Thinking Process for Emotion Recognition in Conversation with Prompts and Paraphrasing
Jun 11, 2023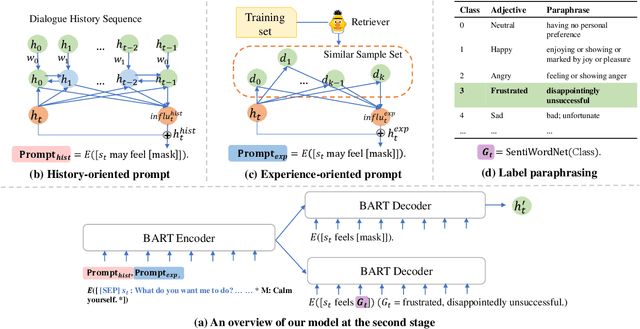
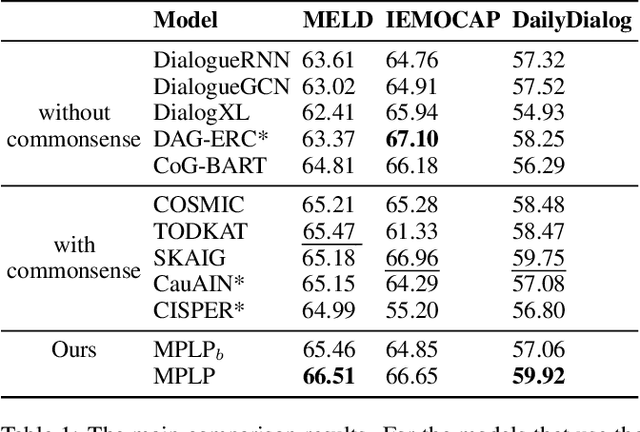
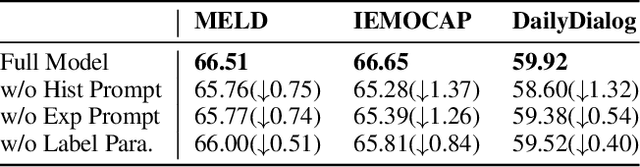
Emotion recognition in conversation, which aims to predict the emotion for all utterances, has attracted considerable research attention in recent years. It is a challenging task since the recognition of the emotion in one utterance involves many complex factors, such as the conversational context, the speaker's background, and the subtle difference between emotion labels. In this paper, we propose a novel framework which mimics the thinking process when modeling these factors. Specifically, we first comprehend the conversational context with a history-oriented prompt to selectively gather information from predecessors of the target utterance. We then model the speaker's background with an experience-oriented prompt to retrieve the similar utterances from all conversations. We finally differentiate the subtle label semantics with a paraphrasing mechanism to elicit the intrinsic label related knowledge. We conducted extensive experiments on three benchmarks. The empirical results demonstrate the superiority of our proposed framework over the state-of-the-art baselines.
REACT2023: the first Multi-modal Multiple Appropriate Facial Reaction Generation Challenge
Jun 11, 2023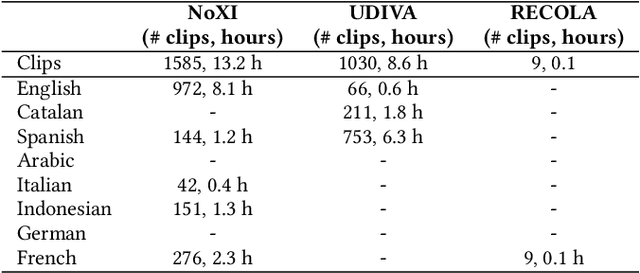
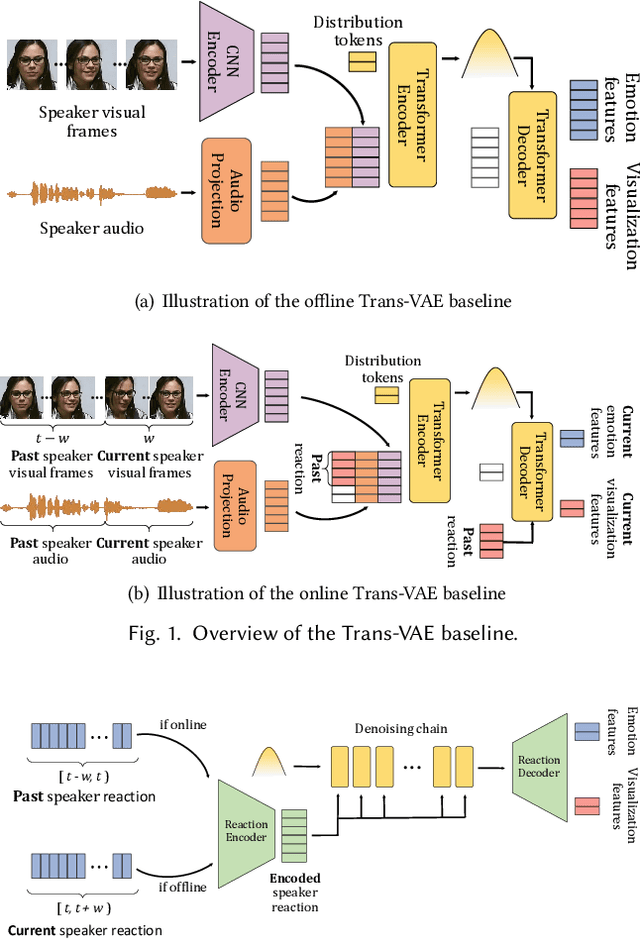
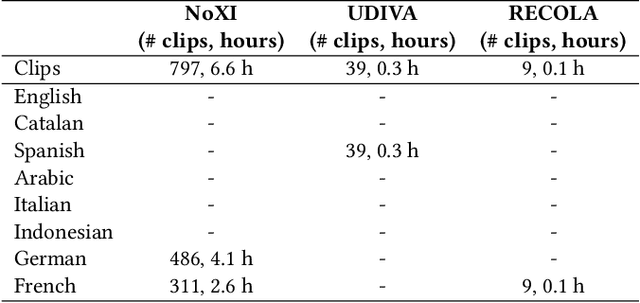
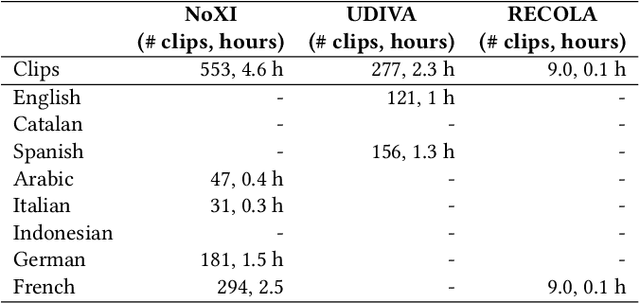
The Multi-modal Multiple Appropriate Facial Reaction Generation Challenge (REACT2023) is the first competition event focused on evaluating multimedia processing and machine learning techniques for generating human-appropriate facial reactions in various dyadic interaction scenarios, with all participants competing strictly under the same conditions. The goal of the challenge is to provide the first benchmark test set for multi-modal information processing and to foster collaboration among the audio, visual, and audio-visual affective computing communities, to compare the relative merits of the approaches to automatic appropriate facial reaction generation under different spontaneous dyadic interaction conditions. This paper presents: (i) novelties, contributions and guidelines of the REACT2023 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at \url{https://github.com/reactmultimodalchallenge/baseline_react2023}.
VBSF-TLD: Validation-Based Approach for Soft Computing-Inspired Transfer Learning in Drone Detection
Jun 11, 2023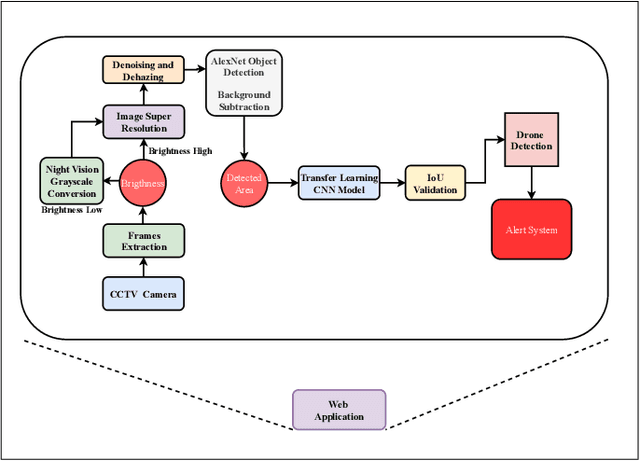


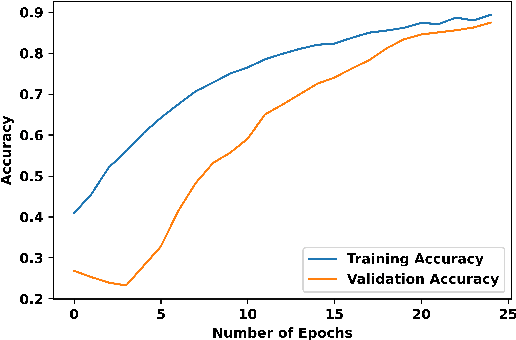
With the increasing utilization of Internet of Things (IoT) enabled drones in diverse applications like photography, delivery, and surveillance, concerns regarding privacy and security have become more prominent. Drones have the ability to capture sensitive information, compromise privacy, and pose security risks. As a result, the demand for advanced technology to automate drone detection has become crucial. This paper presents a project on a transfer-based drone detection scheme, which forms an integral part of a computer vision-based module and leverages transfer learning to enhance performance. By harnessing the knowledge of pre-trained models from a related domain, transfer learning enables improved results even with limited training data. To evaluate the scheme's performance, we conducted tests on benchmark datasets, including the Drone-vs-Bird Dataset and the UAVDT dataset. Notably, the scheme's effectiveness is highlighted by its IOU-based validation results, demonstrating the potential of deep learning-based technology in automating drone detection in critical areas such as airports, military bases, and other high-security zones.
Between-Sample Relationship in Learning Tabular Data Using Graph and Attention Networks
Jun 11, 2023Traditional machine learning assumes samples in tabular data to be independent and identically distributed (i.i.d). This assumption may miss useful information within and between sample relationships in representation learning. This paper relaxes the i.i.d assumption to learn tabular data representations by incorporating between-sample relationships for the first time using graph neural networks (GNN). We investigate our hypothesis using several GNNs and state-of-the-art (SOTA) deep attention models to learn the between-sample relationship on ten tabular data sets by comparing them to traditional machine learning methods. GNN methods show the best performance on tabular data with large feature-to-sample ratios. Our results reveal that attention-based GNN methods outperform traditional machine learning on five data sets and SOTA deep tabular learning methods on three data sets. Between-sample learning via GNN and deep attention methods yield the best classification accuracy on seven of the ten data sets. This suggests that the i.i.d assumption may not always hold for most tabular data sets.
A Probabilistic Framework for Modular Continual Learning
Jun 11, 2023
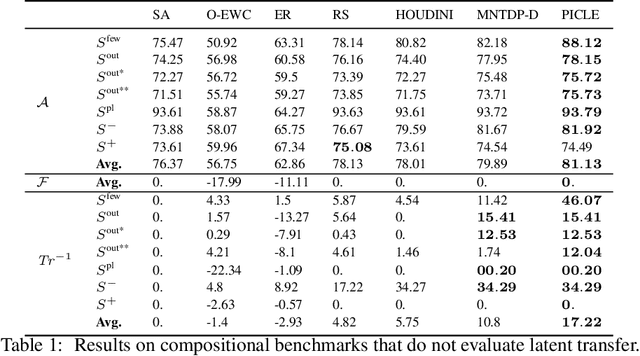

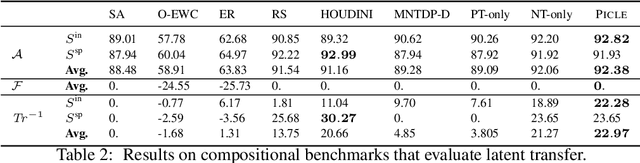
Modular approaches, which use a different composition of modules for each problem and avoid forgetting by design, have been shown to be a promising direction in continual learning (CL). However, searching through the large, discrete space of possible module compositions is a challenge because evaluating a composition's performance requires a round of neural network training. To address this challenge, we develop a modular CL framework, called PICLE, that accelerates search by using a probabilistic model to cheaply compute the fitness of each composition. The model combines prior knowledge about good module compositions with dataset-specific information. Its use is complemented by splitting up the search space into subsets, such as perceptual and latent subsets. We show that PICLE is the first modular CL algorithm to achieve different types of transfer while scaling to large search spaces. We evaluate it on two benchmark suites designed to capture different desiderata of CL techniques. On these benchmarks, PICLE offers significantly better performance than state-of-the-art CL baselines.
Deep Demixing: Reconstructing the Evolution of Network Epidemics
Jun 11, 2023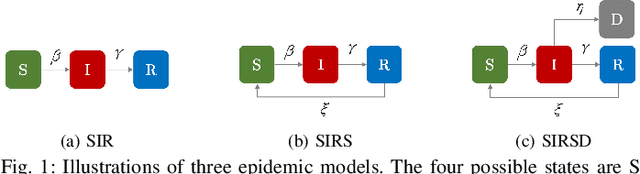
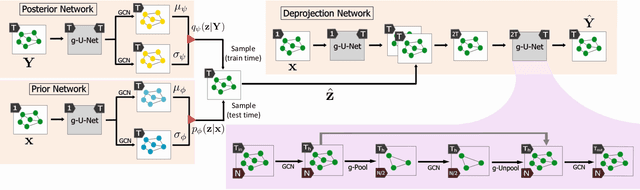
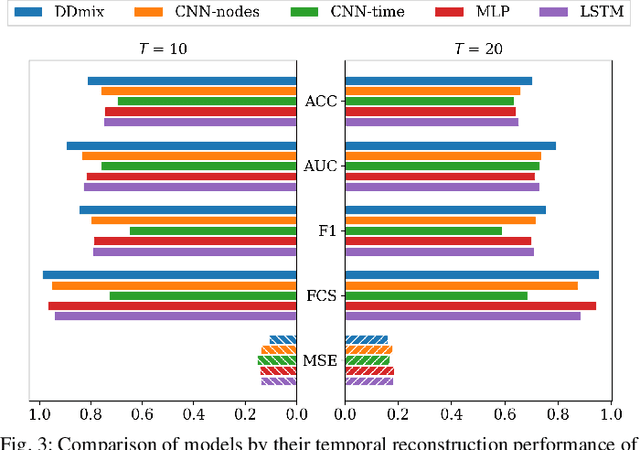
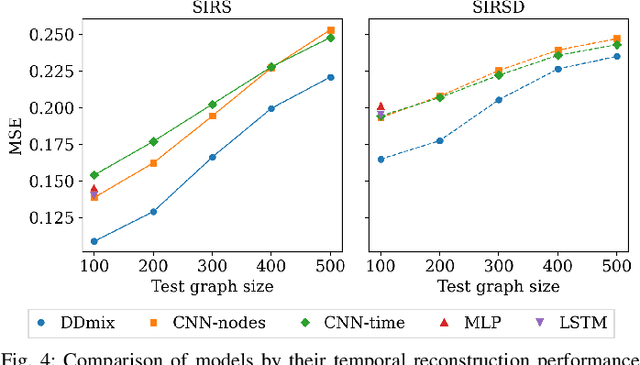
We propose the deep demixing (DDmix) model, a graph autoencoder that can reconstruct epidemics evolving over networks from partial or aggregated temporal information. Assuming knowledge of the network topology but not of the epidemic model, our goal is to estimate the complete propagation path of a disease spread. A data-driven approach is leveraged to overcome the lack of model awareness. To solve this inverse problem, DDmix is proposed as a graph conditional variational autoencoder that is trained from past epidemic spreads. DDmix seeks to capture key aspects of the underlying (unknown) spreading dynamics in its latent space. Using epidemic spreads simulated in synthetic and real-world networks, we demonstrate the accuracy of DDmix by comparing it with multiple (non-graph-aware) learning algorithms. The generalizability of DDmix is highlighted across different types of networks. Finally, we showcase that a simple post-processing extension of our proposed method can help identify super-spreaders in the reconstructed propagation path.
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function
May 26, 2023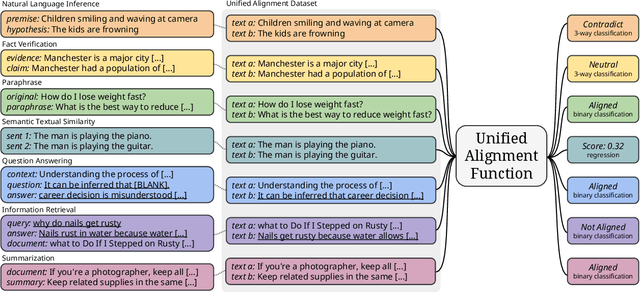
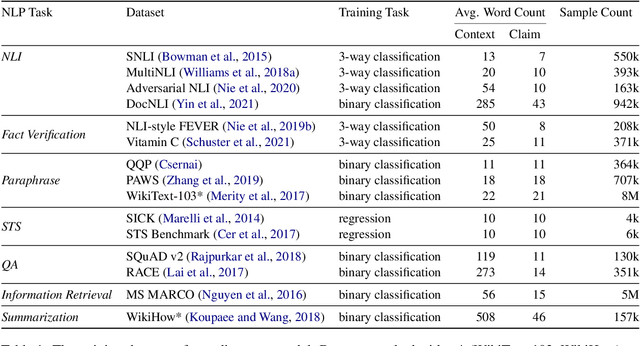
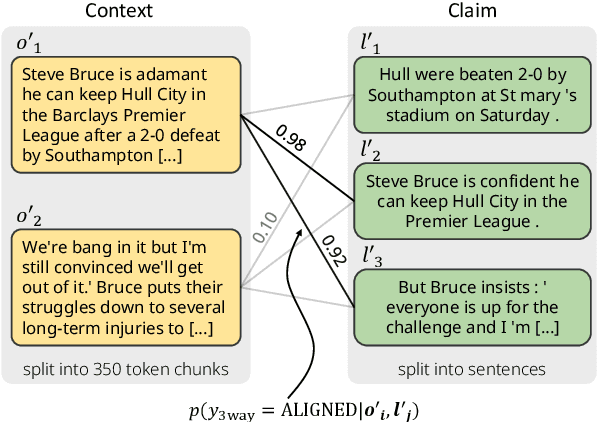
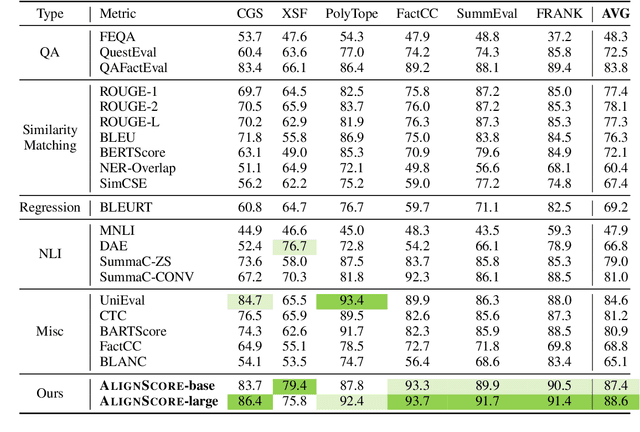
Many text generation applications require the generated text to be factually consistent with input information. Automatic evaluation of factual consistency is challenging. Previous work has developed various metrics that often depend on specific functions, such as natural language inference (NLI) or question answering (QA), trained on limited data. Those metrics thus can hardly assess diverse factual inconsistencies (e.g., contradictions, hallucinations) that occur in varying inputs/outputs (e.g., sentences, documents) from different tasks. In this paper, we propose AlignScore, a new holistic metric that applies to a variety of factual inconsistency scenarios as above. AlignScore is based on a general function of information alignment between two arbitrary text pieces. Crucially, we develop a unified training framework of the alignment function by integrating a large diversity of data sources, resulting in 4.7M training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic similarity, and summarization). We conduct extensive experiments on large-scale benchmarks including 22 evaluation datasets, where 19 of the datasets were never seen in the alignment training. AlignScore achieves substantial improvement over a wide range of previous metrics. Moreover, AlignScore (355M parameters) matches or even outperforms metrics based on ChatGPT and GPT-4 that are orders of magnitude larger.
AMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model
May 26, 2023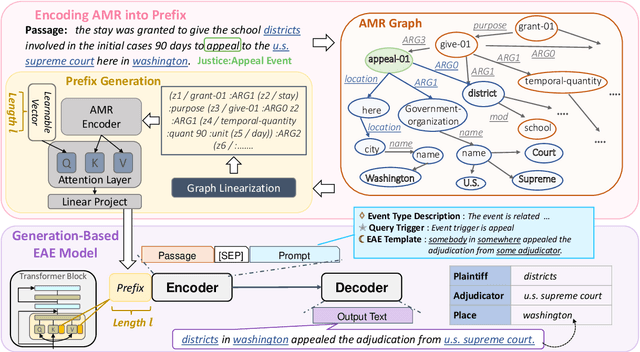
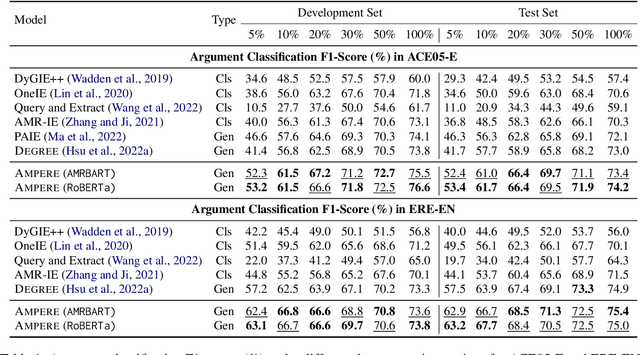
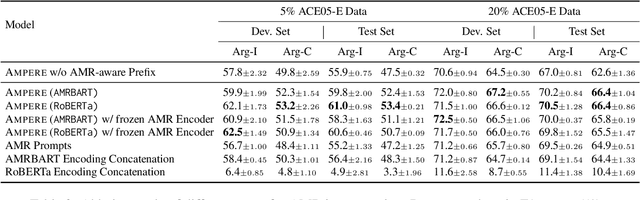
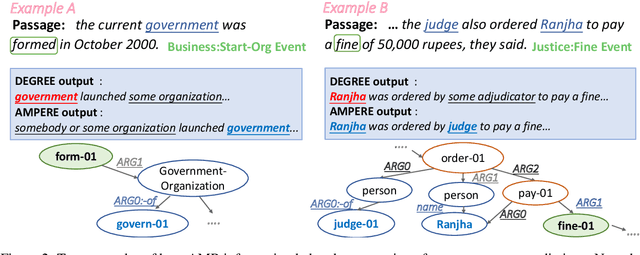
Event argument extraction (EAE) identifies event arguments and their specific roles for a given event. Recent advancement in generation-based EAE models has shown great performance and generalizability over classification-based models. However, existing generation-based EAE models mostly focus on problem re-formulation and prompt design, without incorporating additional information that has been shown to be effective for classification-based models, such as the abstract meaning representation (AMR) of the input passages. Incorporating such information into generation-based models is challenging due to the heterogeneous nature of the natural language form prevalently used in generation-based models and the structured form of AMRs. In this work, we study strategies to incorporate AMR into generation-based EAE models. We propose AMPERE, which generates AMR-aware prefixes for every layer of the generation model. Thus, the prefix introduces AMR information to the generation-based EAE model and then improves the generation. We also introduce an adjusted copy mechanism to AMPERE to help overcome potential noises brought by the AMR graph. Comprehensive experiments and analyses on ACE2005 and ERE datasets show that AMPERE can get 4% - 10% absolute F1 score improvements with reduced training data and it is in general powerful across different training sizes.