 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First Drop of Ink: Nonlinear Impact of Misleading Information in Long-Context Reasoning
May 11, 2026As large language models are increasingly deployed in retrieval-augmented generation and agentic systems that accumulate extensive context, understanding how distracting information affects long-context performance becomes critical. Prior work shows that semantically relevant yet misleading documents degrade performance, but the quantitative relationship between the proportion of distractors and performance remains unstudied. In this work, we systematically vary the hard-distractor proportion in fixed-length contexts, revealing a striking nonlinear pattern: as the proportion of hard distractors increases, performance drops sharply within the first small fraction, while the remainder of the range yields only marginal additional decline. We term this ''The First Drop of Ink'' effect, analogous to how a single drop of ink contaminates water. Our theoretical and empirical analyses grounded in attention mechanics show that hard distractors capture disproportionate attention even at small proportions, with diminishing marginal impact as their proportion grows. Controlled experiments further show that filtering gains mainly come from context-length reduction rather than distractor removal; substantial recovery requires reducing the hard-distractor proportion to near zero, highlighting the importance of upstream retrieval precision.
Is CLIP Cross-Eyed? Revealing and Mitigating Center Bias in the CLIP Family
Apr 07, 2026Recent research has shown that contrastive vision-language models such as CLIP often lack fine-grained understanding of visual content. While a growing body of work has sought to address this limitation, we identify a distinct failure mode in the CLIP family, which we term center bias, that persists even in recent model variants. Specifically, CLIP tends to disproportionately focus on the central region of an image, overlooking important objects located near the boundaries. This limitation is fundamental as failure to recognize relevant objects makes it difficult to perform any sophisticated tasks that depend on those objects. To understand the underlying causes of the limitation, we conduct analyses from both representation and attention perspectives. Using interpretability methods, i.e., embedding decomposition and attention map analysis, we find that relevant concepts especially those associated with off-center objects vanish from the model's embedding in the final representation due to information loss during the aggregation of visual embeddings, particularly the reliance on pooling mechanisms. Finally, we show that this bias can be alleviated with training-free strategies such as visual prompting and attention redistribution by redirecting models' attention to off-center regions.
Steering Vector Fields for Context-Aware Inference-Time Control in Large Language Models
Feb 02, 2026Steering vectors (SVs) offer a lightweight way to control large language models (LLMs) at inference time by shifting hidden activations, providing a practical middle ground between prompting and fine-tuning. Yet SVs can be unreliable in practice. Some concepts are unsteerable, and even when steering helps on average it can backfire for a non-trivial fraction of inputs. Reliability also degrades in long-form generation and multi-attribute steering. We take a geometric view of these failures. A static SV applies the same update vector everywhere in representation space, implicitly assuming that the concept-improving direction is constant across contexts. When the locally effective direction varies with the current activation, a single global vector can become misaligned, which yields weak or reversed effects. Guided by this perspective, we propose Steering Vector Fields (SVF), which learns a differentiable concept scoring function whose local gradient defines the steering direction at each activation, making interventions explicitly context-dependent. This formulation supports coordinated multi-layer interventions in a shared, aligned concept space, and enables efficient long-form and multi-attribute control within a unified framework. Across multiple LLMs and steering tasks, SVF delivers stronger and more reliable control, improving the practicality of inference-time steering.
Language Steering for Multilingual In-Context Learning
Feb 02, 2026While multilingual large language models have gained widespread adoption, their performance on non-English languages remains substantially inferior to English. This disparity is particularly evident in in-context learning scenarios, where providing demonstrations in English but testing on non-English inputs leads to significant performance degradation. In this paper, we hypothesize that LLMs develop a universal semantic space for understanding languages, where different languages are encoded as distinct directions within this space. Based on this hypothesis, we propose language vectors -- a training-free language steering approach that leverages activation differences between source and target languages to guide model behavior. We steer the model generations by adding the vector to the intermediate model activations during inference. This is done to make the model's internal representations shift towards the target language space without any parameter updates. We evaluate our method across three datasets and test on a total of 19 languages on three different models. Our results show consistent improvements on multilingual in-context learning over baselines across all tasks and languages tested. Beyond performance gains, hierarchical clustering of steering vectors reveals meaningful linguistic structure aligned with language families. These vectors also successfully transfer across tasks, demonstrating that these representations are task-agnostic.
Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance
May 22, 2025Embodied agents empowered by large language models (LLMs) have shown strong performance in household object rearrangement tasks. However, these tasks primarily focus on single-turn interactions with simplified instructions, which do not truly reflect the challenges of providing meaningful assistance to users. To provide personalized assistance, embodied agents must understand the unique semantics that users assign to the physical world (e.g., favorite cup, breakfast routine) by leveraging prior interaction history to interpret dynamic, real-world instructions. Yet, the effectiveness of embodied agents in utilizing memory for personalized assistance remains largely underexplored. To address this gap, we present MEMENTO, a personalized embodied agent evaluation framework designed to comprehensively assess memory utilization capabilities to provide personalized assistance. Our framework consists of a two-stage memory evaluation process design that enables quantifying the impact of memory utilization on task performance. This process enables the evaluation of agents' understanding of personalized knowledge in object rearrangement tasks by focusing on its role in goal interpretation: (1) the ability to identify target objects based on personal meaning (object semantics), and (2) the ability to infer object-location configurations from consistent user patterns, such as routines (user patterns). Our experiments across various LLMs reveal significant limitations in memory utilization, with even frontier models like GPT-4o experiencing a 30.5% performance drop when required to reference multiple memories, particularly in tasks involving user patterns. These findings, along with our detailed analyses and case studies, provide valuable insights for future research in developing more effective personalized embodied agents. Project website: https://connoriginal.github.io/MEMENTO
Adaptive Helpfulness-Harmlessness Alignment with Preference Vectors
Apr 27, 2025



Ensuring that large language models (LLMs) are both helpful and harmless is a critical challenge, as overly strict constraints can lead to excessive refusals, while permissive models risk generating harmful content. Existing approaches, such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO), attempt to balance these trade-offs but suffer from performance conflicts, limited controllability, and poor extendability. To address these issues, we propose Preference Vector, a novel framework inspired by task arithmetic. Instead of optimizing multiple preferences within a single objective, we train separate models on individual preferences, extract behavior shifts as preference vectors, and dynamically merge them at test time. This modular approach enables fine-grained, user-controllable preference adjustments and facilitates seamless integration of new preferences without retraining. Experiments show that our proposed Preference Vector framework improves helpfulness without excessive conservatism, allows smooth control over preference trade-offs, and supports scalable multi-preference alignment.
SHA256 at SemEval-2025 Task 4: Selective Amnesia -- Constrained Unlearning for Large Language Models via Knowledge Isolation
Apr 17, 2025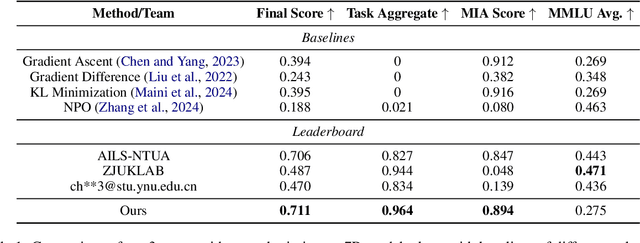
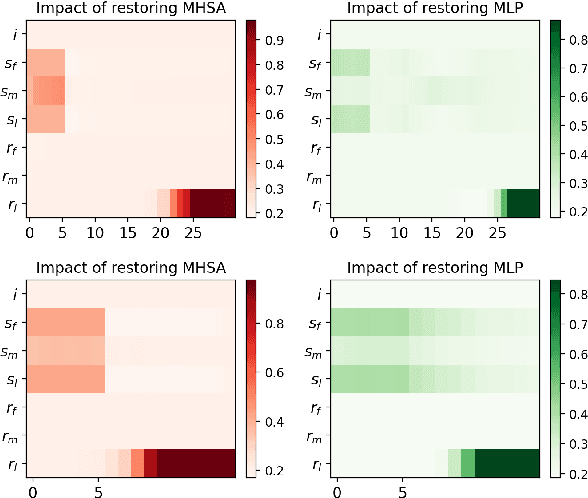
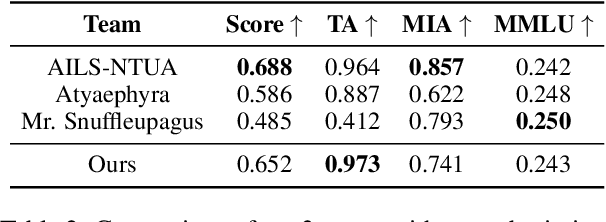
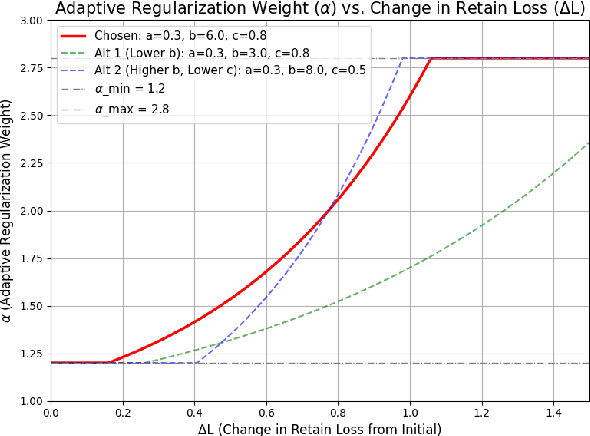
Large language models (LLMs) frequently memorize sensitive information during training, posing risks when deploying publicly accessible models. Current machine unlearning methods struggle to selectively remove specific data associations without degrading overall model capabilities. This paper presents our solution to SemEval-2025 Task 4 on targeted unlearning, which introduces a two-stage methodology that combines causal mediation analysis with layer-specific optimization. Through systematic causal tracing experiments on OLMo architectures (1B and 7B parameters), we identify the critical role of the first few transformer layers (layers 0-5) in storing subject-attribute associations within MLP modules. Building on this insight, we develop a constrained optimization approach that freezes upper layers while applying a novel joint loss function to lower layers-simultaneously maximizing forget set loss via output token cross-entropy penalties and minimizing retain set deviation through adaptive regularization. Our method achieves 2nd place in the 1B model track, demonstrating strong task performance while maintaining 88% of baseline MMLU accuracy. These results establish causal-informed layer optimization as a promising paradigm for efficient, precise unlearning in LLMs, offering a significant step forward in addressing data privacy concerns in AI systems.
Contrastive Visual Data Augmentation
Feb 24, 2025Large multimodal models (LMMs) often struggle to recognize novel concepts, as they rely on pre-trained knowledge and have limited ability to capture subtle visual details. Domain-specific knowledge gaps in training also make them prone to confusing visually similar, commonly misrepresented, or low-resource concepts. To help LMMs better align nuanced visual features with language, improving their ability to recognize and reason about novel or rare concepts, we propose a Contrastive visual Data Augmentation (CoDA) strategy. CoDA extracts key contrastive textual and visual features of target concepts against the known concepts they are misrecognized as, and then uses multimodal generative models to produce targeted synthetic data. Automatic filtering of extracted features and augmented images is implemented to guarantee their quality, as verified by human annotators. We show the effectiveness and efficiency of CoDA on low-resource concept and diverse scene recognition datasets including INaturalist and SUN. We additionally collect NovelSpecies, a benchmark dataset consisting of newly discovered animal species that are guaranteed to be unseen by LMMs. LLaVA-1.6 1-shot updating results on these three datasets show CoDA significantly improves SOTA visual data augmentation strategies by 12.3% (NovelSpecies), 5.1% (SUN), and 6.0% (iNat) absolute gains in accuracy.
FARM: Functional Group-Aware Representations for Small Molecules
Oct 02, 2024



We introduce Functional Group-Aware Representations for Small Molecules (FARM), a novel foundation model designed to bridge the gap between SMILES, natural language, and molecular graphs. The key innovation of FARM lies in its functional group-aware tokenization, which incorporates functional group information directly into the representations. This strategic reduction in tokenization granularity in a way that is intentionally interfaced with key drivers of functional properties (i.e., functional groups) enhances the model's understanding of chemical language, expands the chemical lexicon, more effectively bridging SMILES and natural language, and ultimately advances the model's capacity to predict molecular properties. FARM also represents molecules from two perspectives: by using masked language modeling to capture atom-level features and by employing graph neural networks to encode the whole molecule topology. By leveraging contrastive learning, FARM aligns these two views of representations into a unified molecular embedding. We rigorously evaluate FARM on the MoleculeNet dataset, where it achieves state-of-the-art performance on 10 out of 12 tasks. These results highlight FARM's potential to improve molecular representation learning, with promising applications in drug discovery and pharmaceutical research.
ARMADA: Attribute-Based Multimodal Data Augmentation
Aug 19, 2024



In Multimodal Language Models (MLMs), the cost of manually annotating high-quality image-text pair data for fine-tuning and alignment is extremely high. While existing multimodal data augmentation frameworks propose ways to augment image-text pairs, they either suffer from semantic inconsistency between texts and images, or generate unrealistic images, causing knowledge gap with real world examples. To address these issues, we propose Attribute-based Multimodal Data Augmentation (ARMADA), a novel multimodal data augmentation method via knowledge-guided manipulation of visual attributes of the mentioned entities. Specifically, we extract entities and their visual attributes from the original text data, then search for alternative values for the visual attributes under the guidance of knowledge bases (KBs) and large language models (LLMs). We then utilize an image-editing model to edit the images with the extracted attributes. ARMADA is a novel multimodal data generation framework that: (i) extracts knowledge-grounded attributes from symbolic KBs for semantically consistent yet distinctive image-text pair generation, (ii) generates visually similar images of disparate categories using neighboring entities in the KB hierarchy, and (iii) uses the commonsense knowledge of LLMs to modulate auxiliary visual attributes such as backgrounds for more robust representation of original entities. Our empirical results over four downstream tasks demonstrate the efficacy of our framework to produce high-quality data and enhance the model performance. This also highlights the need to leverage external knowledge proxies for enhanced interpretability and real-world grounding.