 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Event Abstraction for Enterprise Collaboration Systems to Support Social Process Mining
Aug 09, 2023
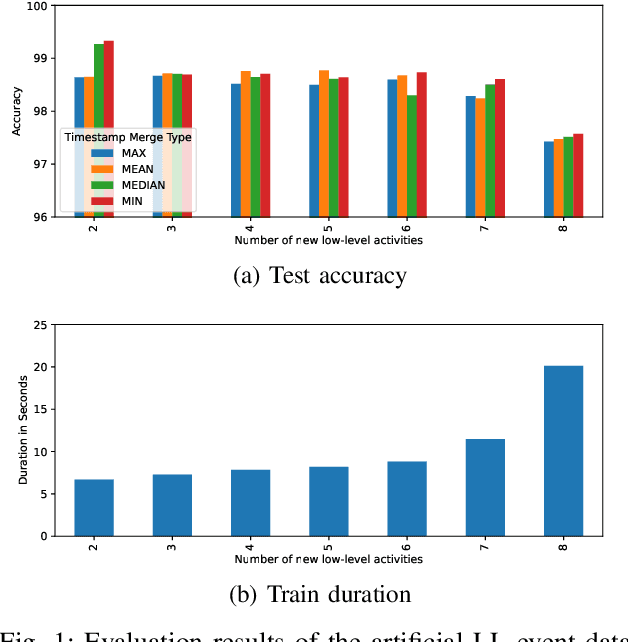
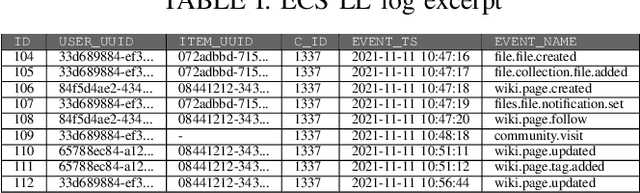
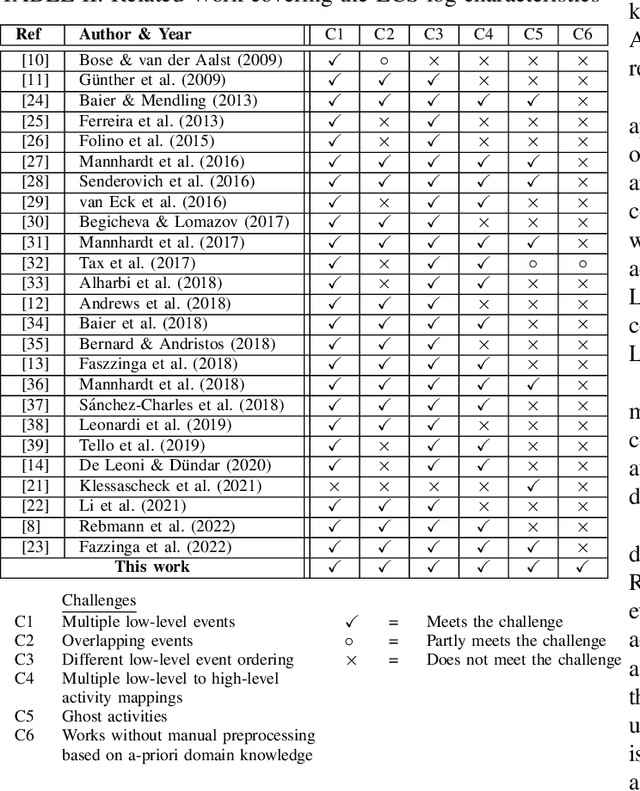
One aim of Process Mining (PM) is the discovery of process models from event logs of information systems. PM has been successfully applied to process-oriented enterprise systems but is less suited for communication- and document-oriented Enterprise Collaboration Systems (ECS). ECS event logs are very fine-granular and PM applied to their logs results in spaghetti models. A common solution for this is event abstraction, i.e., converting low-level logs into more abstract high-level logs before running discovery algorithms. ECS logs come with special characteristics that have so far not been fully addressed by existing event abstraction approaches. We aim to close this gap with a tailored ECS event abstraction (ECSEA) approach that trains a model by comparing recorded actual user activities (high-level traces) with the system-generated low-level traces (extracted from the ECS). The model allows us to automatically convert future low-level traces into an abstracted high-level log that can be used for PM. Our evaluation shows that the algorithm produces accurate results. ECSEA is a preprocessing method that is essential for the interpretation of collaborative work activity in ECS, which we call Social Process Mining.
Leveraging the Edge and Cloud for V2X-Based Real-Time Object Detection in Autonomous Driving
Aug 09, 2023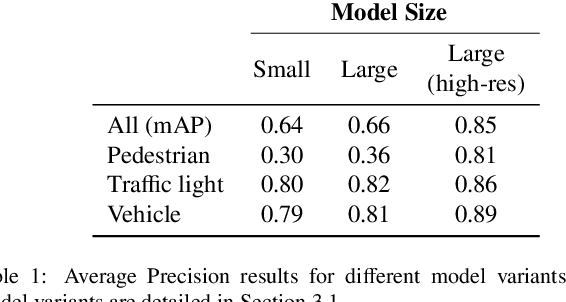
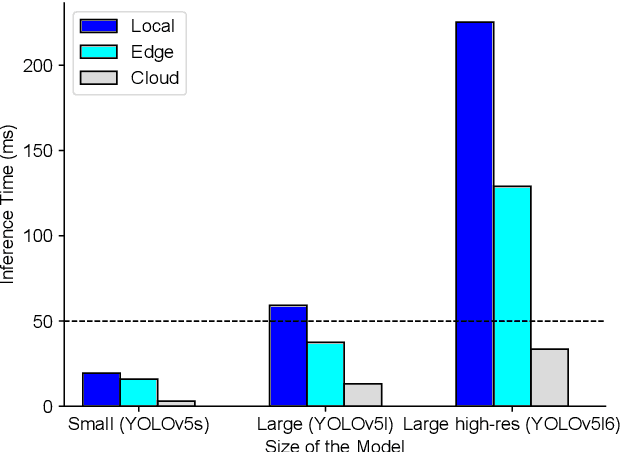
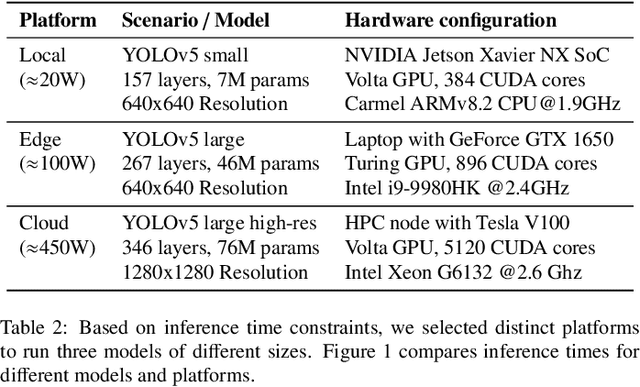
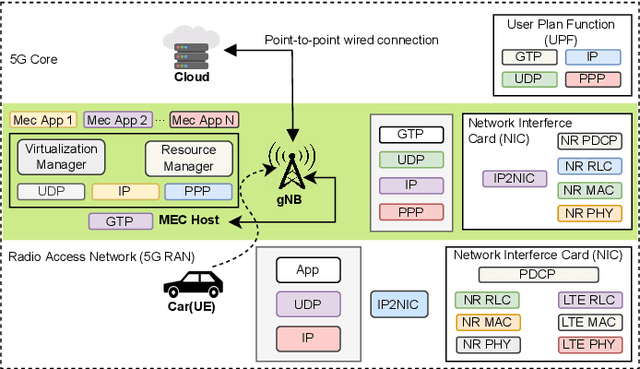
Environmental perception is a key element of autonomous driving because the information received from the perception module influences core driving decisions. An outstanding challenge in real-time perception for autonomous driving lies in finding the best trade-off between detection quality and latency. Major constraints on both computation and power have to be taken into account for real-time perception in autonomous vehicles. Larger object detection models tend to produce the best results, but are also slower at runtime. Since the most accurate detectors cannot run in real-time locally, we investigate the possibility of offloading computation to edge and cloud platforms, which are less resource-constrained. We create a synthetic dataset to train object detection models and evaluate different offloading strategies. Using real hardware and network simulations, we compare different trade-offs between prediction quality and end-to-end delay. Since sending raw frames over the network implies additional transmission delays, we also explore the use of JPEG and H.265 compression at varying qualities and measure their impact on prediction metrics. We show that models with adequate compression can be run in real-time on the cloud while outperforming local detection performance.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 08, 2023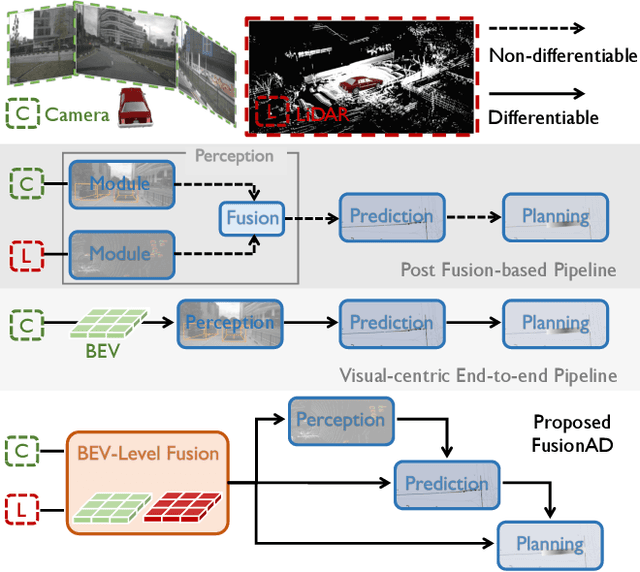
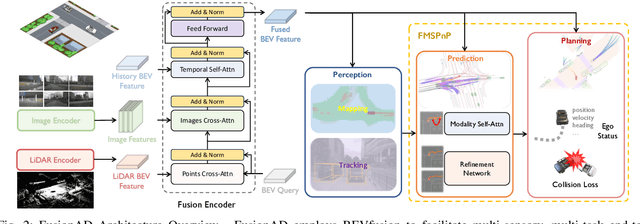
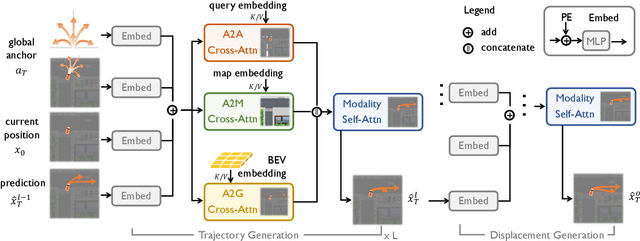
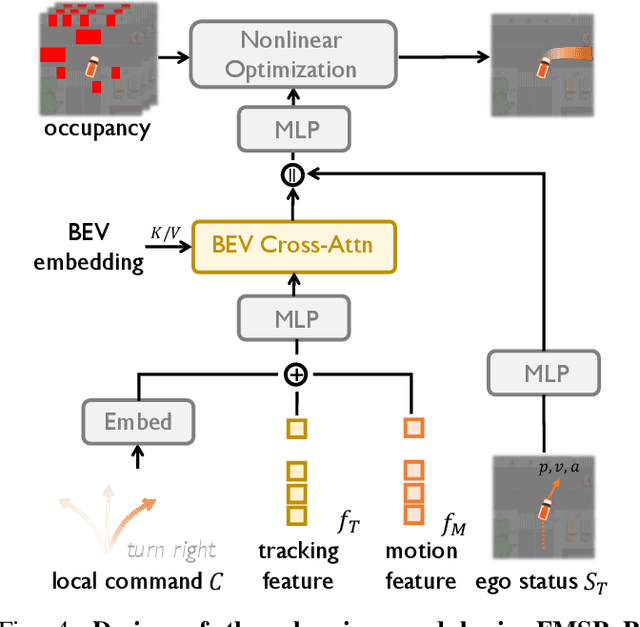
Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
Social Media, Topic Modeling and Sentiment Analysis in Municipal Decision Support
Aug 08, 2023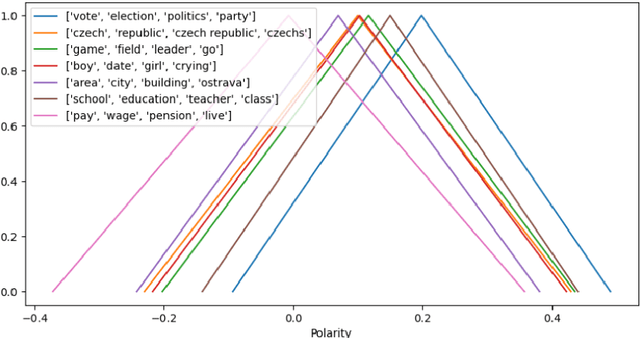
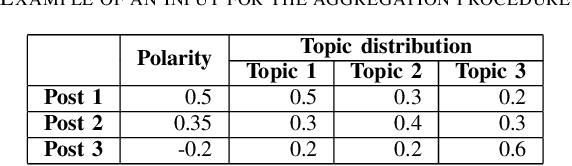

Many cities around the world are aspiring to become. However, smart initiatives often give little weight to the opinions of average citizens. Social media are one of the most important sources of citizen opinions. This paper presents a prototype of a framework for processing social media posts with municipal decision-making in mind. The framework consists of a sequence of three steps: (1) determining the sentiment polarity of each social media post (2) identifying prevalent topics and mapping these topics to individual posts, and (3) aggregating these two pieces of information into a fuzzy number representing the overall sentiment expressed towards each topic. Optionally, the fuzzy number can be reduced into a tuple of two real numbers indicating the "amount" of positive and negative opinion expressed towards each topic. The framework is demonstrated on tweets published from Ostrava, Czechia over a period of about two months. This application illustrates how fuzzy numbers represent sentiment in a richer way and capture the diversity of opinions expressed on social media.
Auditory Attention Decoding with Task-Related Multi-View Contrastive Learning
Aug 08, 2023
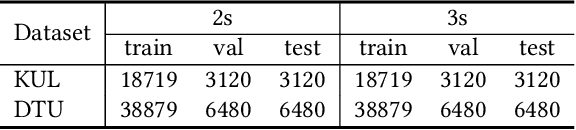

The human brain can easily focus on one speaker and suppress others in scenarios such as a cocktail party. Recently, researchers found that auditory attention can be decoded from the electroencephalogram (EEG) data. However, most existing deep learning methods are difficult to use prior knowledge of different views (that is attended speech and EEG are task-related views) and extract an unsatisfactory representation. Inspired by Broadbent's filter model, we decode auditory attention in a multi-view paradigm and extract the most relevant and important information utilizing the missing view. Specifically, we propose an auditory attention decoding (AAD) method based on multi-view VAE with task-related multi-view contrastive (TMC) learning. Employing TMC learning in multi-view VAE can utilize the missing view to accumulate prior knowledge of different views into the fusion of representation, and extract the approximate task-related representation. We examine our method on two popular AAD datasets, and demonstrate the superiority of our method by comparing it to the state-of-the-art method.
PARTNER: Level up the Polar Representation for LiDAR 3D Object Detection
Aug 08, 2023
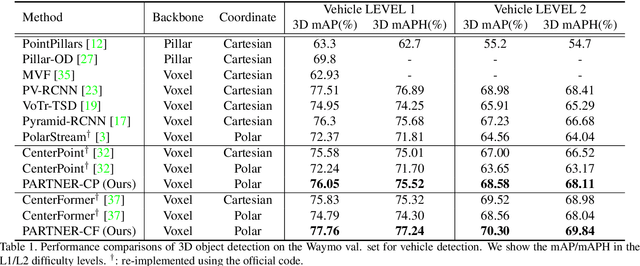
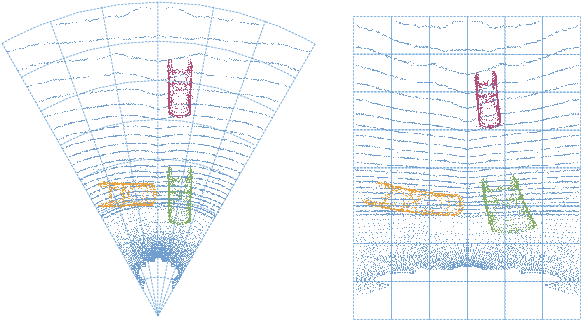
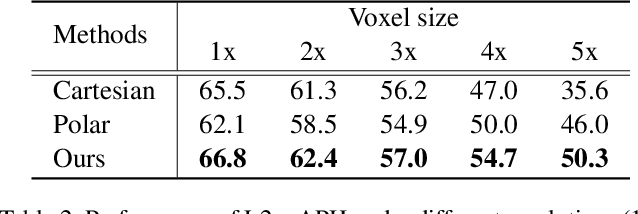
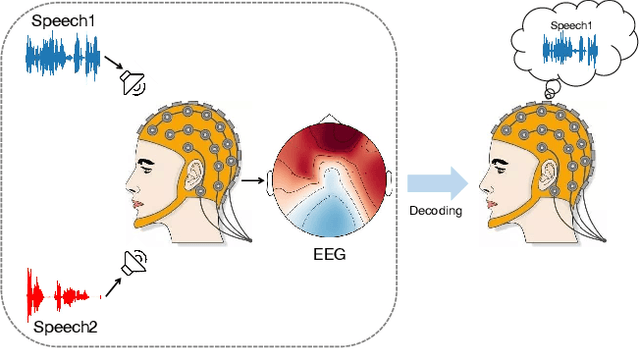
Recently, polar-based representation has shown promising properties in perceptual tasks. In addition to Cartesian-based approaches, which separate point clouds unevenly, representing point clouds as polar grids has been recognized as an alternative due to (1) its advantage in robust performance under different resolutions and (2) its superiority in streaming-based approaches. However, state-of-the-art polar-based detection methods inevitably suffer from the feature distortion problem because of the non-uniform division of polar representation, resulting in a non-negligible performance gap compared to Cartesian-based approaches. To tackle this issue, we present PARTNER, a novel 3D object detector in the polar coordinate. PARTNER alleviates the dilemma of feature distortion with global representation re-alignment and facilitates the regression by introducing instance-level geometric information into the detection head. Extensive experiments show overwhelming advantages in streaming-based detection and different resolutions. Furthermore, our method outperforms the previous polar-based works with remarkable margins of 3.68% and 9.15% on Waymo and ONCE validation set, thus achieving competitive results over the state-of-the-art methods.
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
Apr 17, 2023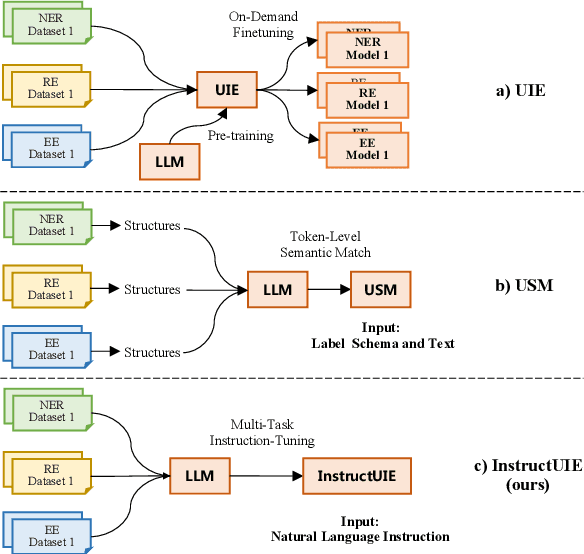
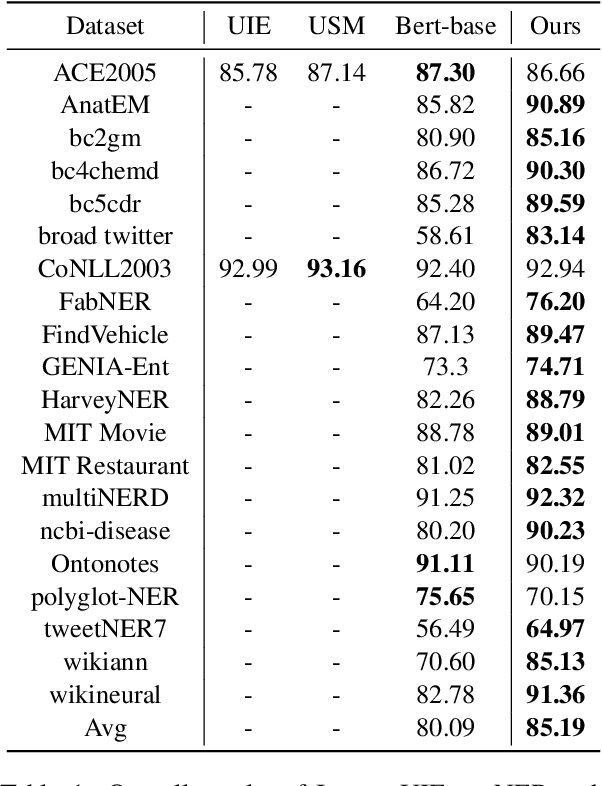
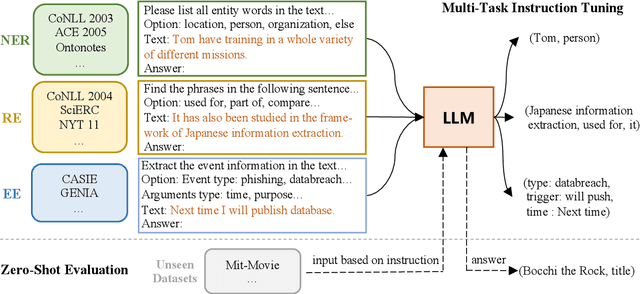
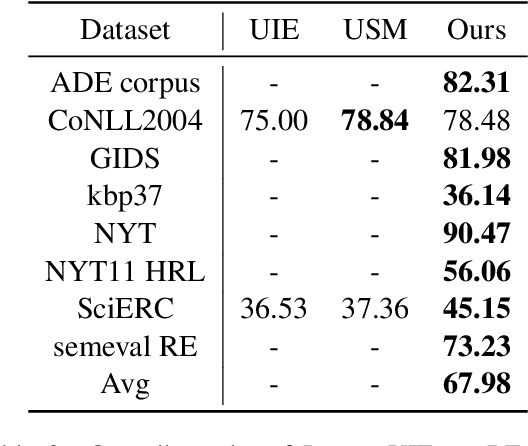
Large language models have unlocked strong multi-task capabilities from reading instructive prompts. However, recent studies have shown that existing large models still have difficulty with information extraction tasks. For example, gpt-3.5-turbo achieved an F1 score of 18.22 on the Ontonotes dataset, which is significantly lower than the state-of-the-art performance. In this paper, we propose InstructUIE, a unified information extraction framework based on instruction tuning, which can uniformly model various information extraction tasks and capture the inter-task dependency. To validate the proposed method, we introduce IE INSTRUCTIONS, a benchmark of 32 diverse information extraction datasets in a unified text-to-text format with expert-written instructions. Experimental results demonstrate that our method achieves comparable performance to Bert in supervised settings and significantly outperforms the state-of-the-art and gpt3.5 in zero-shot settings.
YOLIC: An Efficient Method for Object Localization and Classification on Edge Devices
Jul 30, 2023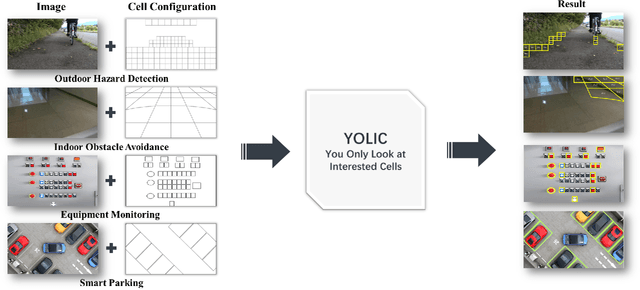
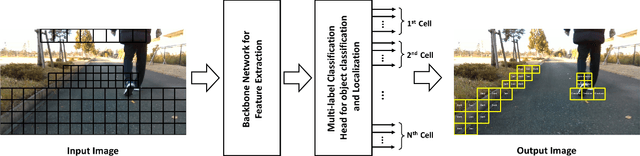


In the realm of Tiny AI, we introduce ``You Only Look at Interested Cells" (YOLIC), an efficient method for object localization and classification on edge devices. Through seamlessly blending the strengths of semantic segmentation and object detection, YOLIC offers superior computational efficiency and precision. By adopting Cells of Interest for classification instead of individual pixels, YOLIC encapsulates relevant information, reduces computational load, and enables rough object shape inference. Importantly, the need for bounding box regression is obviated, as YOLIC capitalizes on the predetermined cell configuration that provides information about potential object location, size, and shape. To tackle the issue of single-label classification limitations, a multi-label classification approach is applied to each cell for effectively recognizing overlapping or closely situated objects. This paper presents extensive experiments on multiple datasets to demonstrate that YOLIC achieves detection performance comparable to the state-of-the-art YOLO algorithms while surpassing in speed, exceeding 30fps on a Raspberry Pi 4B CPU. All resources related to this study, including datasets, cell designer, image annotation tool, and source code, have been made publicly available on our project website at https://kai3316.github.io/yolic.github.io
Successive Pose Estimation and Beam Tracking for mmWave Vehicular Communication Systems
Jul 30, 2023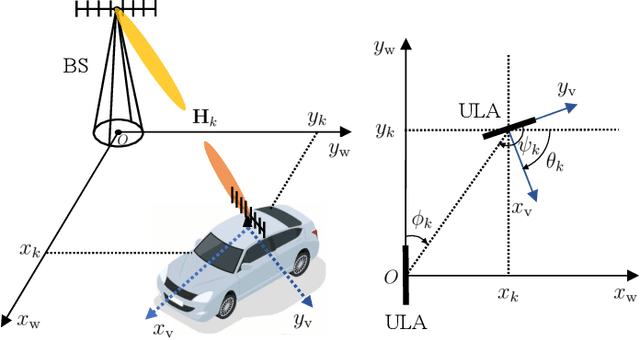

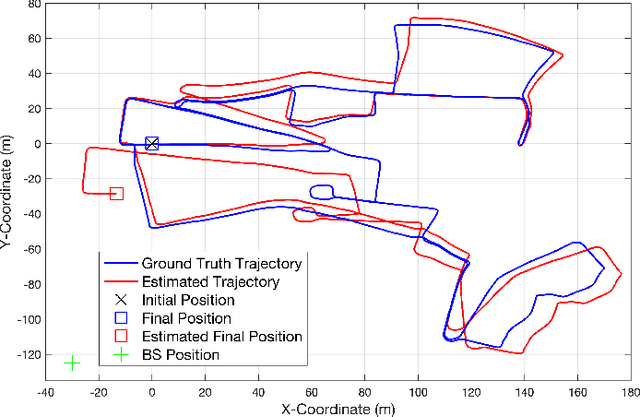
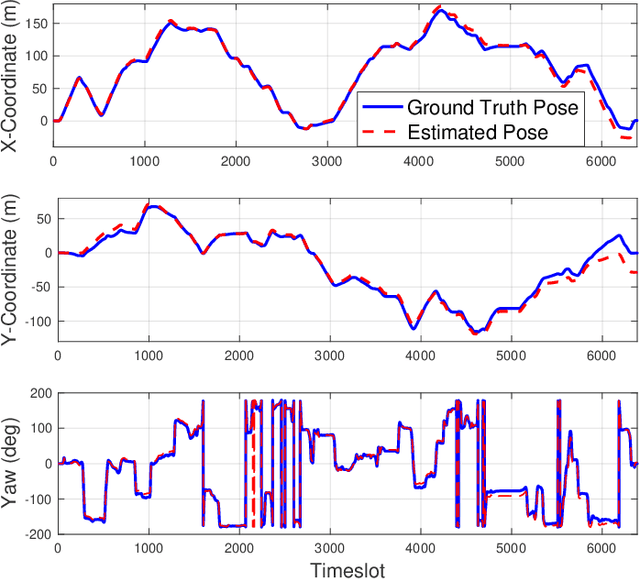
The millimeter wave (mmWave) radar sensing-aided communications in vehicular mobile communication systems is investigated. To alleviate the beam training overhead under high mobility scenarios, a successive pose estimation and beam tracking (SPEBT) scheme is proposed to facilitate mmWave communications with the assistance of mmWave radar sensing. The proposed SPEBT scheme first resorts to a Fast Conservative Filtering for Efficient and Accurate Radar odometry (Fast-CFEAR) approach to estimate the vehicle pose consisting of 2-dimensional position and yaw from radar point clouds collected by mmWave radar sensor. Then, the pose estimation information is fed into an extend Kalman filter to perform beam tracking for the line-of-sight channel. Owing to the intrinsic robustness of mmWave radar sensing, the proposed SPEBT scheme is capable of operating reliably under extreme weather/illumination conditions and large-scale global navigation satellite systems (GNSS)-denied environments. The practical deployment of the SPEBT scheme is verified through rigorous testing on a real-world sensing dataset. Simulation results demonstrate that the proposed SPEBT scheme is capable of providing precise pose estimation information and accurate beam tracking output, while reducing the proportion of beam training overhead to less than 5% averagely.
Med-HALT: Medical Domain Hallucination Test for Large Language Models
Jul 28, 2023

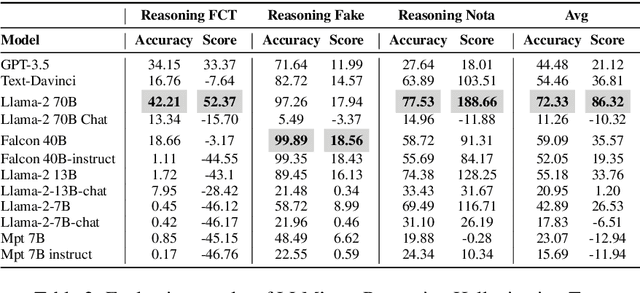
This research paper focuses on the challenges posed by hallucinations in large language models (LLMs), particularly in the context of the medical domain. Hallucination, wherein these models generate plausible yet unverified or incorrect information, can have serious consequences in healthcare applications. We propose a new benchmark and dataset, Med-HALT (Medical Domain Hallucination Test), designed specifically to evaluate and reduce hallucinations. Med-HALT provides a diverse multinational dataset derived from medical examinations across various countries and includes multiple innovative testing modalities. Med-HALT includes two categories of tests reasoning and memory-based hallucination tests, designed to assess LLMs's problem-solving and information retrieval abilities. Our study evaluated leading LLMs, including Text Davinci, GPT-3.5, LlaMa-2, MPT, and Falcon, revealing significant differences in their performance. The paper provides detailed insights into the dataset, promoting transparency and reproducibility. Through this work, we aim to contribute to the development of safer and more reliable language models in healthcare. Our benchmark can be found at medhalt.github.io