 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Denoising Bottleneck with Mutual Information Maximization for Video Multimodal Fusion
May 25, 2023
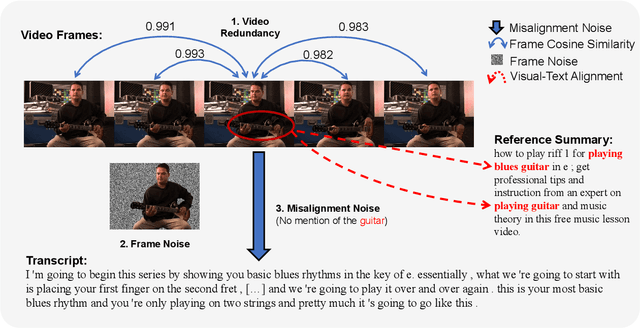
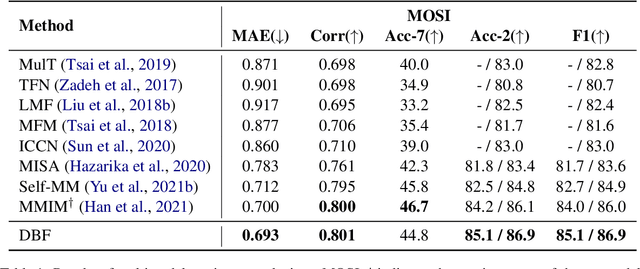
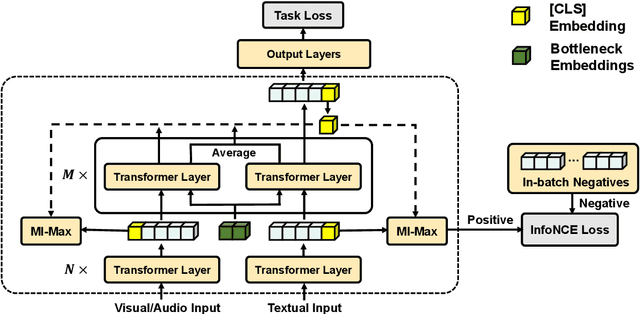
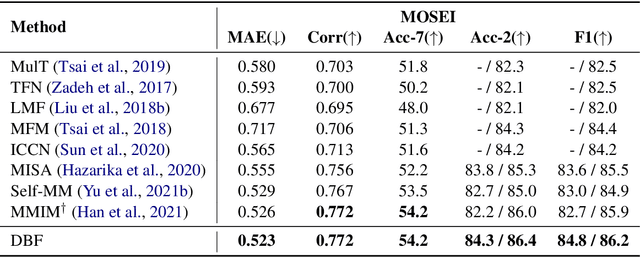
Video multimodal fusion aims to integrate multimodal signals in videos, such as visual, audio and text, to make a complementary prediction with multiple modalities contents. However, unlike other image-text multimodal tasks, video has longer multimodal sequences with more redundancy and noise in both visual and audio modalities. Prior denoising methods like forget gate are coarse in the granularity of noise filtering. They often suppress the redundant and noisy information at the risk of losing critical information. Therefore, we propose a denoising bottleneck fusion (DBF) model for fine-grained video multimodal fusion. On the one hand, we employ a bottleneck mechanism to filter out noise and redundancy with a restrained receptive field. On the other hand, we use a mutual information maximization module to regulate the filter-out module to preserve key information within different modalities. Our DBF model achieves significant improvement over current state-of-the-art baselines on multiple benchmarks covering multimodal sentiment analysis and multimodal summarization tasks. It proves that our model can effectively capture salient features from noisy and redundant video, audio, and text inputs. The code for this paper is publicly available at https://github.com/WSXRHFG/DBF.
Address Matching Based On Hierarchical Information
May 10, 2023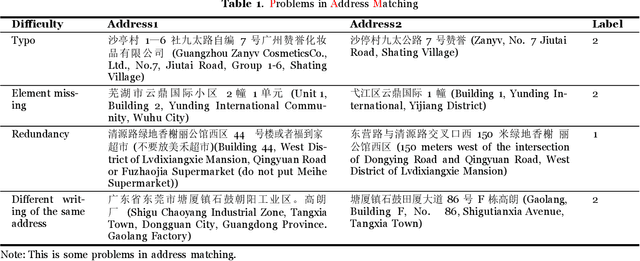
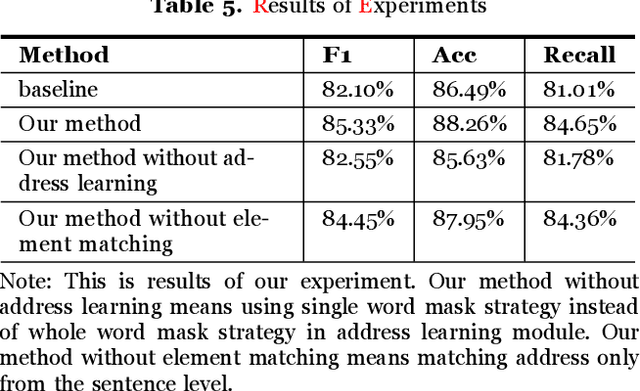
There is evidence that address matching plays a crucial role in many areas such as express delivery, online shopping and so on. Address has a hierarchical structure, in contrast to unstructured texts, which can contribute valuable information for address matching. Based on this idea, this paper proposes a novel method to leverage the hierarchical information in deep learning method that not only improves the ability of existing methods to handle irregular address, but also can pay closer attention to the special part of address. Experimental findings demonstrate that the proposed method improves the current approach by 3.2% points.
PMET: Precise Model Editing in a Transformer
Aug 22, 2023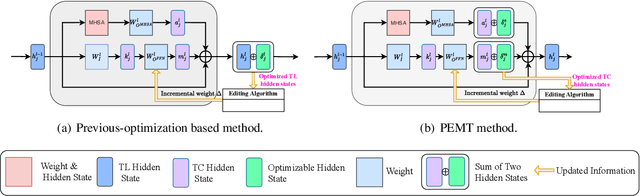
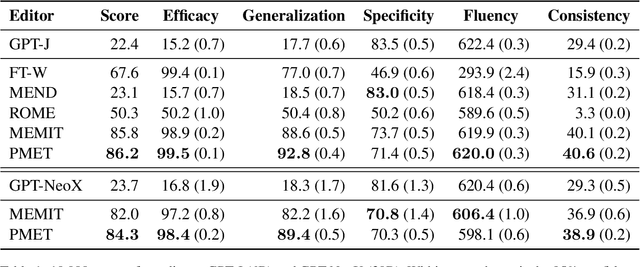
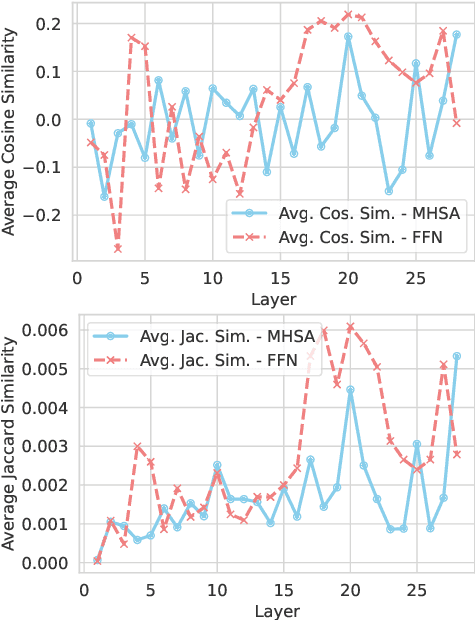
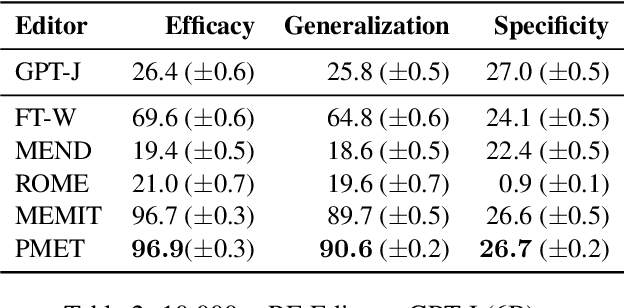
Model editing techniques modify a minor proportion of knowledge in Large Language Models (LLMs) at a relatively low cost, which have demonstrated notable success. Existing methods assume Transformer Layer (TL) hidden states are values of key-value memories of the Feed-Forward Network (FFN). They usually optimize the TL hidden states to memorize target knowledge and use it to update the weights of the FFN in LLMs. However, the information flow of TL hidden states comes from three parts: Multi-Head Self-Attention (MHSA), FFN, and residual connections. Existing methods neglect the fact that the TL hidden states contains information not specifically required for FFN. Consequently, the performance of model editing decreases. To achieve more precise model editing, we analyze hidden states of MHSA and FFN, finding that MHSA encodes certain general knowledge extraction patterns. This implies that MHSA weights do not require updating when new knowledge is introduced. Based on above findings, we introduce PMET, which simultaneously optimizes Transformer Component (TC, namely MHSA and FFN) hidden states, while only using the optimized TC hidden states of FFN to precisely update FFN weights. Our experiments demonstrate that PMET exhibits state-of-the-art performance on both the COUNTERFACT and zsRE datasets. Our ablation experiments substantiate the effectiveness of our enhancements, further reinforcing the finding that the MHSA encodes certain general knowledge extraction patterns and indicating its storage of a small amount of factual knowledge. Our code is available at https://github.com/xpq-tech/PMET.git.
Out of the Box Thinking: Improving Customer Lifetime Value Modelling via Expert Routing and Game Whale Detection
Aug 24, 2023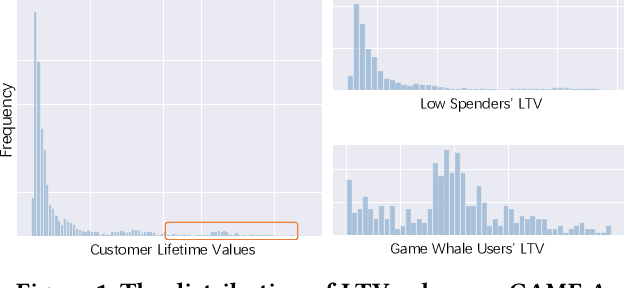

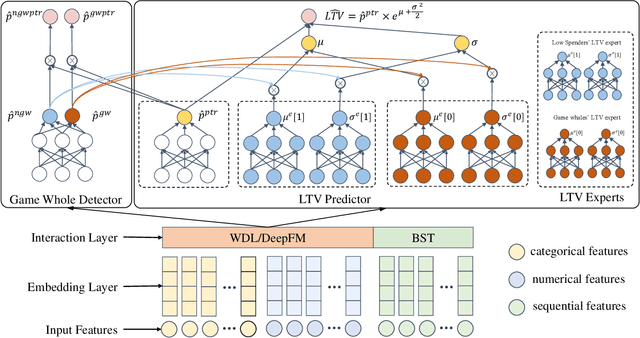
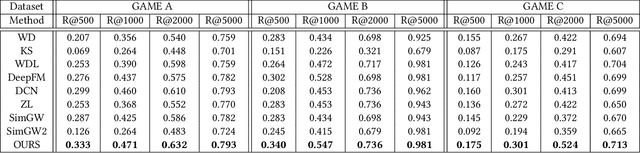
Customer lifetime value (LTV) prediction is essential for mobile game publishers trying to optimize the advertising investment for each user acquisition based on the estimated worth. In mobile games, deploying microtransactions is a simple yet effective monetization strategy, which attracts a tiny group of game whales who splurge on in-game purchases. The presence of such game whales may impede the practicality of existing LTV prediction models, since game whales' purchase behaviours always exhibit varied distribution from general users. Consequently, identifying game whales can open up new opportunities to improve the accuracy of LTV prediction models. However, little attention has been paid to applying game whale detection in LTV prediction, and existing works are mainly specialized for the long-term LTV prediction with the assumption that the high-quality user features are available, which is not applicable in the UA stage. In this paper, we propose ExpLTV, a novel multi-task framework to perform LTV prediction and game whale detection in a unified way. In ExpLTV, we first innovatively design a deep neural network-based game whale detector that can not only infer the intrinsic order in accordance with monetary value, but also precisely identify high spenders (i.e., game whales) and low spenders. Then, by treating the game whale detector as a gating network to decide the different mixture patterns of LTV experts assembling, we can thoroughly leverage the shared information and scenario-specific information (i.e., game whales modelling and low spenders modelling). Finally, instead of separately designing a purchase rate estimator for two tasks, we design a shared estimator that can preserve the inner task relationships. The superiority of ExpLTV is further validated via extensive experiments on three industrial datasets.
MapPrior: Bird's-Eye View Map Layout Estimation with Generative Models
Aug 24, 2023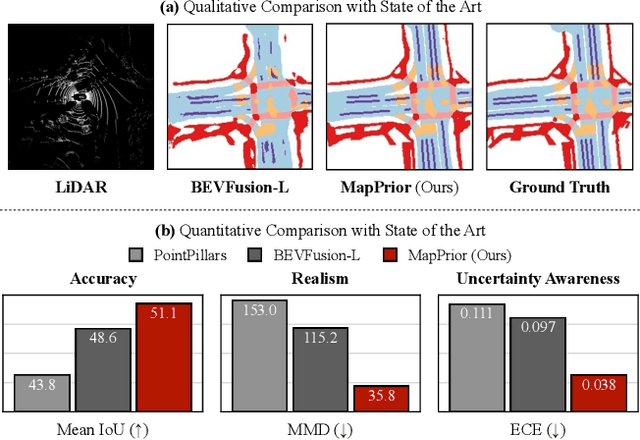
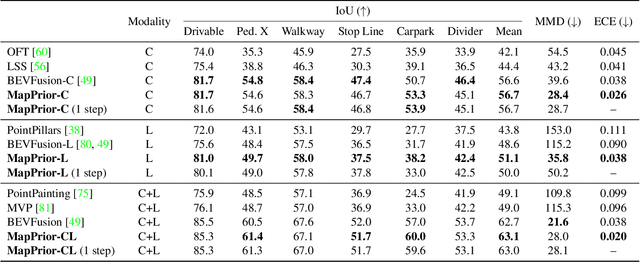
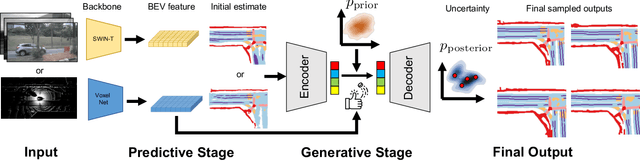
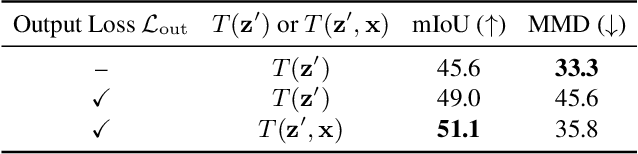
Despite tremendous advancements in bird's-eye view (BEV) perception, existing models fall short in generating realistic and coherent semantic map layouts, and they fail to account for uncertainties arising from partial sensor information (such as occlusion or limited coverage). In this work, we introduce MapPrior, a novel BEV perception framework that combines a traditional discriminative BEV perception model with a learned generative model for semantic map layouts. Our MapPrior delivers predictions with better accuracy, realism, and uncertainty awareness. We evaluate our model on the large-scale nuScenes benchmark. At the time of submission, MapPrior outperforms the strongest competing method, with significantly improved MMD and ECE scores in camera- and LiDAR-based BEV perception.
End-to-End Document Classification and Key Information Extraction using Assignment Optimization
Jun 01, 2023

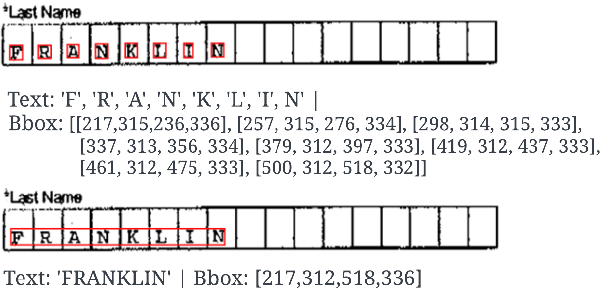
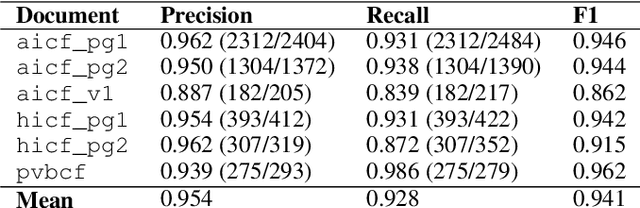
We propose end-to-end document classification and key information extraction (KIE) for automating document processing in forms. Through accurate document classification we harness known information from templates to enhance KIE from forms. We use text and layout encoding with a cosine similarity measure to classify visually-similar documents. We then demonstrate a novel application of mixed integer programming by using assignment optimization to extract key information from documents. Our approach is validated on an in-house dataset of noisy scanned forms. The best performing document classification approach achieved 0.97 f1 score. A mean f1 score of 0.94 for the KIE task suggests there is significant potential in applying optimization techniques. Abation results show that the method relies on document preprocessing techniques to mitigate Type II errors and achieve optimal performance.
Visually-Aware Context Modeling for News Image Captioning
Aug 16, 2023
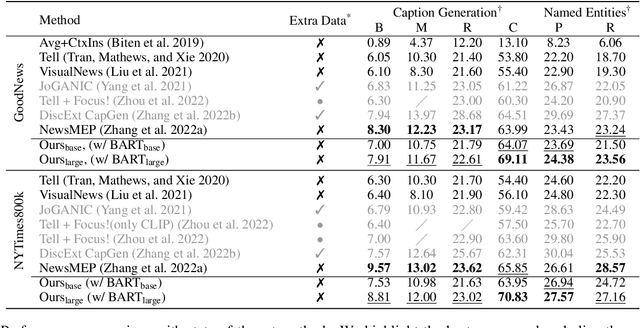
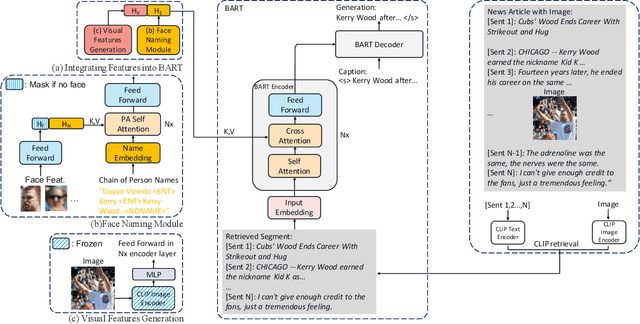
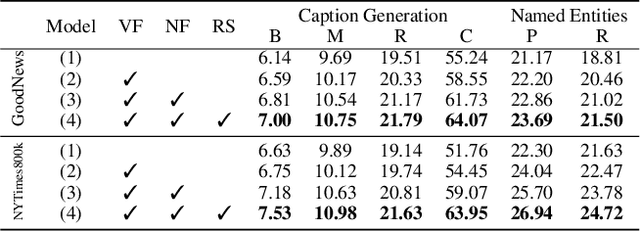
The goal of News Image Captioning is to generate an image caption according to the content of both a news article and an image. To leverage the visual information effectively, it is important to exploit the connection between the context in the articles/captions and the images. Psychological studies indicate that human faces in images draw higher attention priorities. On top of that, humans often play a central role in news stories, as also proven by the face-name co-occurrence pattern we discover in existing News Image Captioning datasets. Therefore, we design a face-naming module for faces in images and names in captions/articles to learn a better name embedding. Apart from names, which can be directly linked to an image area (faces), news image captions mostly contain context information that can only be found in the article. Humans typically address this by searching for relevant information from the article based on the image. To emulate this thought process, we design a retrieval strategy using CLIP to retrieve sentences that are semantically close to the image. We conduct extensive experiments to demonstrate the efficacy of our framework. Without using additional paired data, we establish the new state-of-the-art performance on two News Image Captioning datasets, exceeding the previous state-of-the-art by 5 CIDEr points. We will release code upon acceptance.
OnUVS: Online Feature Decoupling Framework for High-Fidelity Ultrasound Video Synthesis
Aug 16, 2023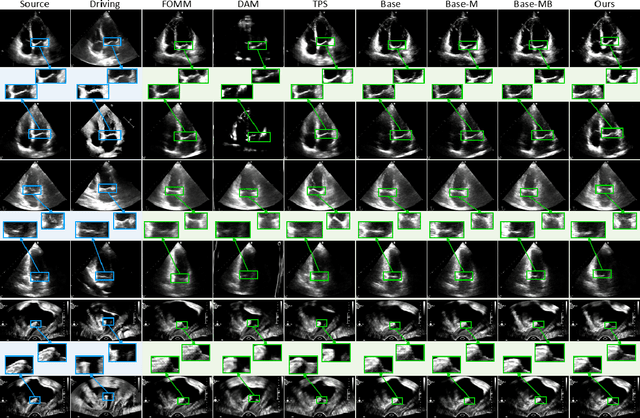

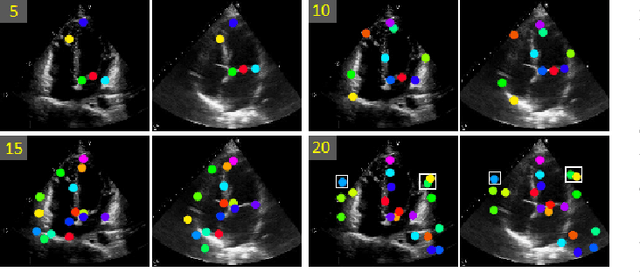
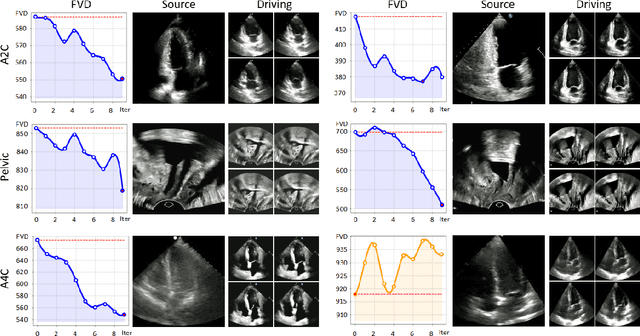
Ultrasound (US) imaging is indispensable in clinical practice. To diagnose certain diseases, sonographers must observe corresponding dynamic anatomic structures to gather comprehensive information. However, the limited availability of specific US video cases causes teaching difficulties in identifying corresponding diseases, which potentially impacts the detection rate of such cases. The synthesis of US videos may represent a promising solution to this issue. Nevertheless, it is challenging to accurately animate the intricate motion of dynamic anatomic structures while preserving image fidelity. To address this, we present a novel online feature-decoupling framework called OnUVS for high-fidelity US video synthesis. Our highlights can be summarized by four aspects. First, we introduced anatomic information into keypoint learning through a weakly-supervised training strategy, resulting in improved preservation of anatomical integrity and motion while minimizing the labeling burden. Second, to better preserve the integrity and textural information of US images, we implemented a dual-decoder that decouples the content and textural features in the generator. Third, we adopted a multiple-feature discriminator to extract a comprehensive range of visual cues, thereby enhancing the sharpness and fine details of the generated videos. Fourth, we constrained the motion trajectories of keypoints during online learning to enhance the fluidity of generated videos. Our validation and user studies on in-house echocardiographic and pelvic floor US videos showed that OnUVS synthesizes US videos with high fidelity.
MEDOE: A Multi-Expert Decoder and Output Ensemble Framework for Long-tailed Semantic Segmentation
Aug 16, 2023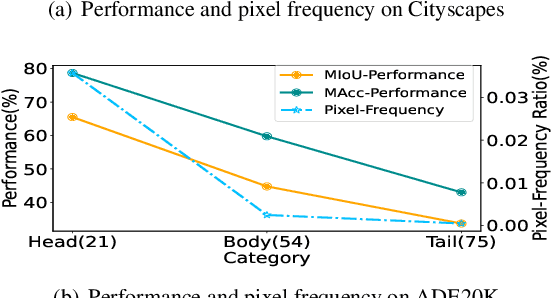
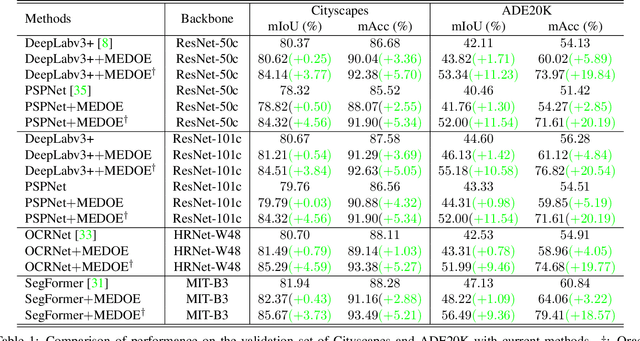

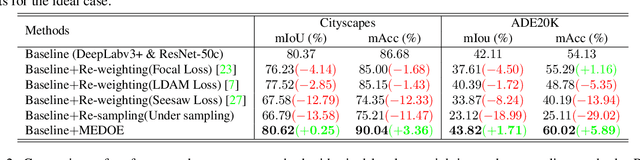
Long-tailed distribution of semantic categories, which has been often ignored in conventional methods, causes unsatisfactory performance in semantic segmentation on tail categories. In this paper, we focus on the problem of long-tailed semantic segmentation. Although some long-tailed recognition methods (e.g., re-sampling/re-weighting) have been proposed in other problems, they can probably compromise crucial contextual information and are thus hardly adaptable to the problem of long-tailed semantic segmentation. To address this issue, we propose MEDOE, a novel framework for long-tailed semantic segmentation via contextual information ensemble-and-grouping. The proposed two-sage framework comprises a multi-expert decoder (MED) and a multi-expert output ensemble (MOE). Specifically, the MED includes several "experts". Based on the pixel frequency distribution, each expert takes the dataset masked according to the specific categories as input and generates contextual information self-adaptively for classification; The MOE adopts learnable decision weights for the ensemble of the experts' outputs. As a model-agnostic framework, our MEDOE can be flexibly and efficiently coupled with various popular deep neural networks (e.g., DeepLabv3+, OCRNet, and PSPNet) to improve their performance in long-tailed semantic segmentation. Experimental results show that the proposed framework outperforms the current methods on both Cityscapes and ADE20K datasets by up to 1.78% in mIoU and 5.89% in mAcc.
Graph Relation Aware Continual Learning
Aug 16, 2023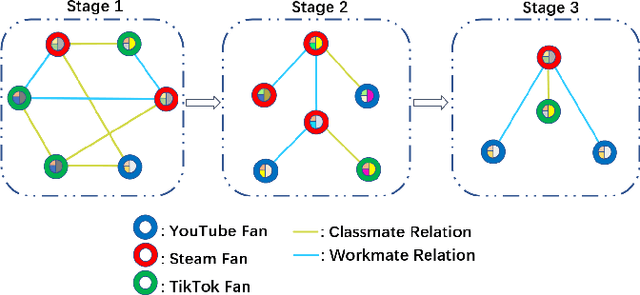
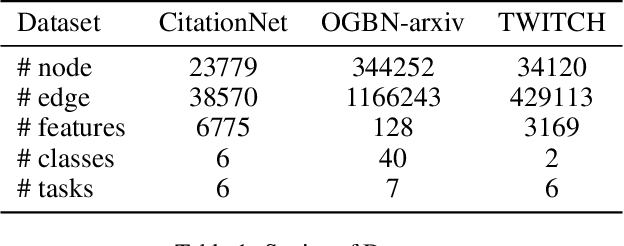
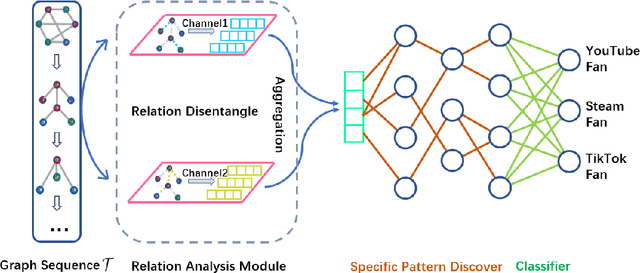
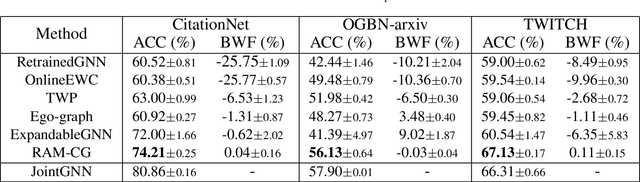
Continual graph learning (CGL) studies the problem of learning from an infinite stream of graph data, consolidating historical knowledge, and generalizing it to the future task. At once, only current graph data are available. Although some recent attempts have been made to handle this task, we still face two potential challenges: 1) most of existing works only manipulate on the intermediate graph embedding and ignore intrinsic properties of graphs. It is non-trivial to differentiate the transferred information across graphs. 2) recent attempts take a parameter-sharing policy to transfer knowledge across time steps or progressively expand new architecture given shifted graph distribution. Learning a single model could loss discriminative information for each graph task while the model expansion scheme suffers from high model complexity. In this paper, we point out that latent relations behind graph edges can be attributed as an invariant factor for the evolving graphs and the statistical information of latent relations evolves. Motivated by this, we design a relation-aware adaptive model, dubbed as RAM-CG, that consists of a relation-discovery modular to explore latent relations behind edges and a task-awareness masking classifier to accounts for the shifted. Extensive experiments show that RAM-CG provides significant 2.2%, 6.9% and 6.6% accuracy improvements over the state-of-the-art results on CitationNet, OGBN-arxiv and TWITCH dataset, respective.