 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Lens Blur Fields
Oct 17, 2023

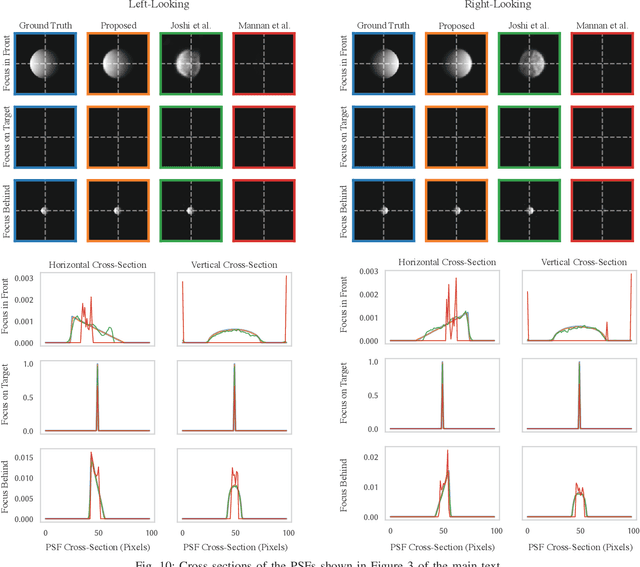


Optical blur is an inherent property of any lens system and is challenging to model in modern cameras because of their complex optical elements. To tackle this challenge, we introduce a high-dimensional neural representation of blur$-$$\textit{the lens blur field}$$-$and a practical method for acquiring it. The lens blur field is a multilayer perceptron (MLP) designed to (1) accurately capture variations of the lens 2D point spread function over image plane location, focus setting and, optionally, depth and (2) represent these variations parametrically as a single, sensor-specific function. The representation models the combined effects of defocus, diffraction, aberration, and accounts for sensor features such as pixel color filters and pixel-specific micro-lenses. To learn the real-world blur field of a given device, we formulate a generalized non-blind deconvolution problem that directly optimizes the MLP weights using a small set of focal stacks as the only input. We also provide a first-of-its-kind dataset of 5D blur fields$-$for smartphone cameras, camera bodies equipped with a variety of lenses, etc. Lastly, we show that acquired 5D blur fields are expressive and accurate enough to reveal, for the first time, differences in optical behavior of smartphone devices of the same make and model.
MosaiQ: Quantum Generative Adversarial Networks for Image Generation on NISQ Computers
Aug 22, 2023Quantum machine learning and vision have come to the fore recently, with hardware advances enabling rapid advancement in the capabilities of quantum machines. Recently, quantum image generation has been explored with many potential advantages over non-quantum techniques; however, previous techniques have suffered from poor quality and robustness. To address these problems, we introduce, MosaiQ, a high-quality quantum image generation GAN framework that can be executed on today's Near-term Intermediate Scale Quantum (NISQ) computers.
Hierarchical Concept Discovery Models: A Concept Pyramid Scheme
Oct 03, 2023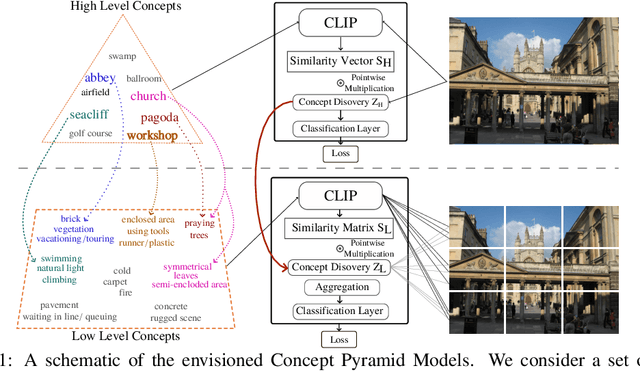
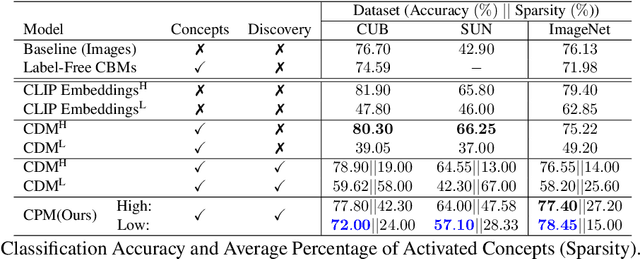
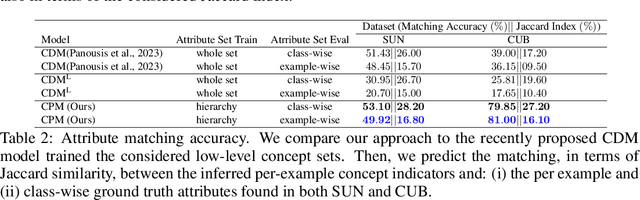

Deep Learning algorithms have recently gained significant attention due to their impressive performance. However, their high complexity and un-interpretable mode of operation hinders their confident deployment in real-world safety-critical tasks. This work targets ante hoc interpretability, and specifically Concept Bottleneck Models (CBMs). Our goal is to design a framework that admits a highly interpretable decision making process with respect to human understandable concepts, on multiple levels of granularity. To this end, we propose a novel hierarchical concept discovery formulation leveraging: (i) recent advances in image-text models, and (ii) an innovative formulation for multi-level concept selection via data-driven and sparsity inducing Bayesian arguments. Within this framework, concept information does not solely rely on the similarity between the whole image and general unstructured concepts; instead, we introduce the notion of concept hierarchy to uncover and exploit more granular concept information residing in patch-specific regions of the image scene. As we experimentally show, the proposed construction not only outperforms recent CBM approaches, but also yields a principled framework towards interpetability.
Hybrid-Supervised Dual-Search: Leveraging Automatic Learning for Loss-free Multi-Exposure Image Fusion
Sep 03, 2023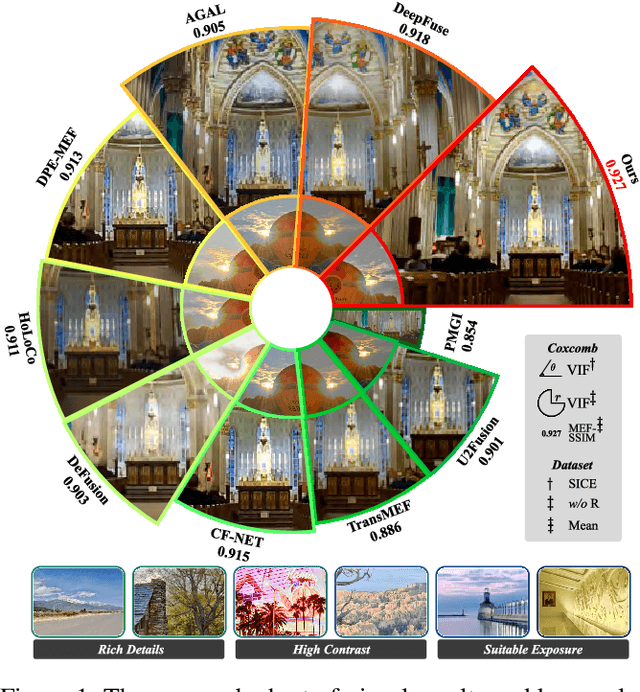

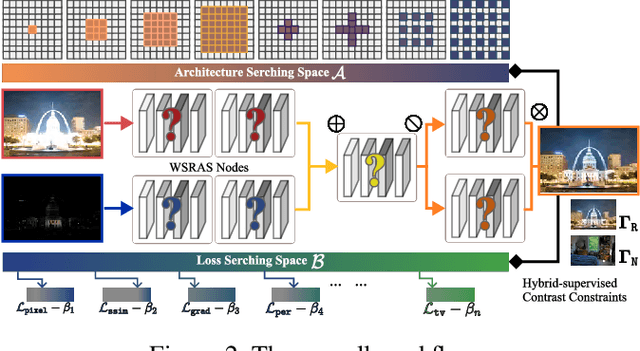
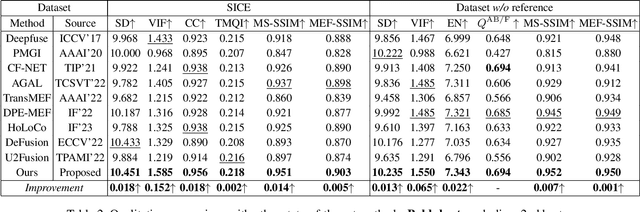
Multi-exposure image fusion (MEF) has emerged as a prominent solution to address the limitations of digital imaging in representing varied exposure levels. Despite its advancements, the field grapples with challenges, notably the reliance on manual designs for network structures and loss functions, and the constraints of utilizing simulated reference images as ground truths. Consequently, current methodologies often suffer from color distortions and exposure artifacts, further complicating the quest for authentic image representation. In addressing these challenges, this paper presents a Hybrid-Supervised Dual-Search approach for MEF, dubbed HSDS-MEF, which introduces a bi-level optimization search scheme for automatic design of both network structures and loss functions. More specifically, we harnesses a unique dual research mechanism rooted in a novel weighted structure refinement architecture search. Besides, a hybrid supervised contrast constraint seamlessly guides and integrates with searching process, facilitating a more adaptive and comprehensive search for optimal loss functions. We realize the state-of-the-art performance in comparison to various competitive schemes, yielding a 10.61% and 4.38% improvement in Visual Information Fidelity (VIF) for general and no-reference scenarios, respectively, while providing results with high contrast, rich details and colors.
Feature Attention Network (FA-Net): A Deep-Learning Based Approach for Underwater Single Image Enhancement
Aug 30, 2023Underwater image processing and analysis have been a hotspot of study in recent years, as more emphasis has been focused to underwater monitoring and usage of marine resources. Compared with the open environment, underwater image encountered with more complicated conditions such as light abortion, scattering, turbulence, nonuniform illumination and color diffusion. Although considerable advances and enhancement techniques achieved in resolving these issues, they treat low-frequency information equally across the entire channel, which results in limiting the network's representativeness. We propose a deep learning and feature-attention-based end-to-end network (FA-Net) to solve this problem. In particular, we propose a Residual Feature Attention Block (RFAB), containing the channel attention, pixel attention, and residual learning mechanism with long and short skip connections. RFAB allows the network to focus on learning high-frequency information while skipping low-frequency information on multi-hop connections. The channel and pixel attention mechanism considers each channel's different features and the uneven distribution of haze over different pixels in the image. The experimental results shows that the FA-Net propose by us provides higher accuracy, quantitatively and qualitatively and superiority to previous state-of-the-art methods.
* Fourteenth International Conference on Digital Image Processing (ICDIP 2022), 2022, Wuhan, China, May 20-23, 2022.8 pages.5 Figures.doi: 10.1117/12.2644516
MOFA: A Model Simplification Roadmap for Image Restoration on Mobile Devices
Aug 24, 2023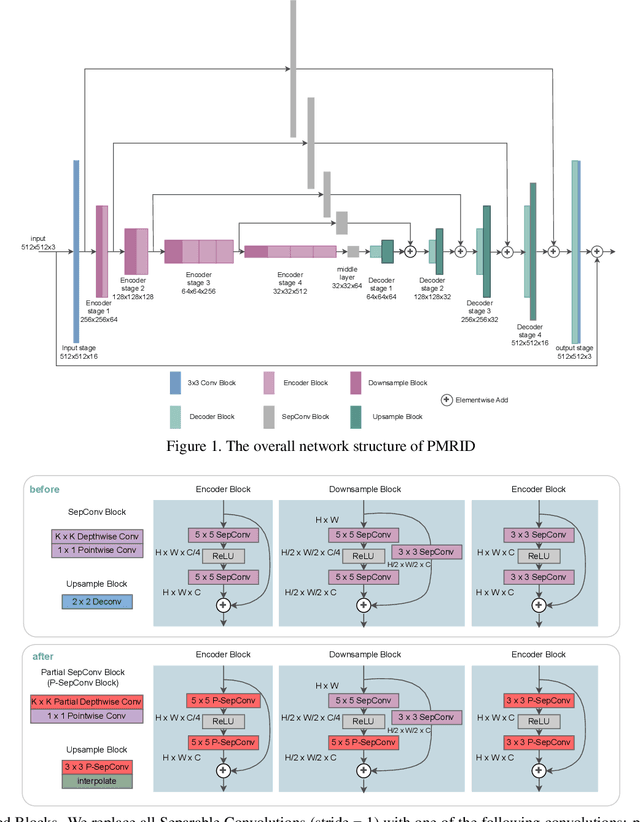
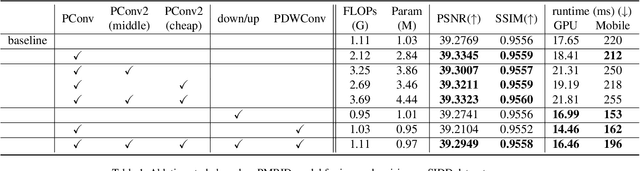
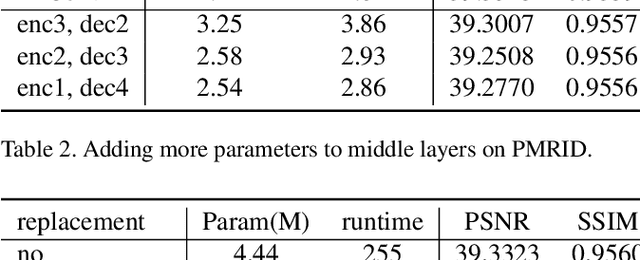

Image restoration aims to restore high-quality images from degraded counterparts and has seen significant advancements through deep learning techniques. The technique has been widely applied to mobile devices for tasks such as mobile photography. Given the resource limitations on mobile devices, such as memory constraints and runtime requirements, the efficiency of models during deployment becomes paramount. Nevertheless, most previous works have primarily concentrated on analyzing the efficiency of single modules and improving them individually. This paper examines the efficiency across different layers. We propose a roadmap that can be applied to further accelerate image restoration models prior to deployment while simultaneously increasing PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index). The roadmap first increases the model capacity by adding more parameters to partial convolutions on FLOPs non-sensitive layers. Then, it applies partial depthwise convolution coupled with decoupling upsampling/downsampling layers to accelerate the model speed. Extensive experiments demonstrate that our approach decreases runtime by up to 13% and reduces the number of parameters by up to 23%, while increasing PSNR and SSIM on several image restoration datasets. Source Code of our method is available at \href{https://github.com/xiangyu8/MOFA}{https://github.com/xiangyu8/MOFA}.
SAM-guided Unsupervised Domain Adaptation for 3D Segmentation
Oct 16, 2023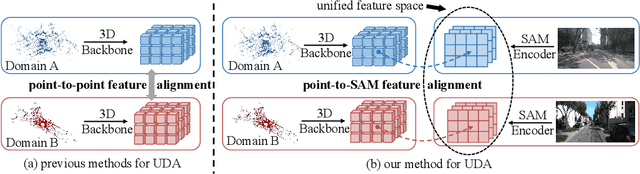
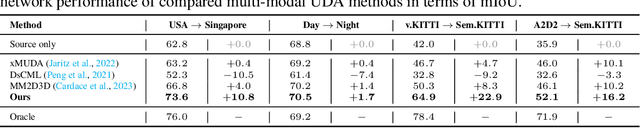
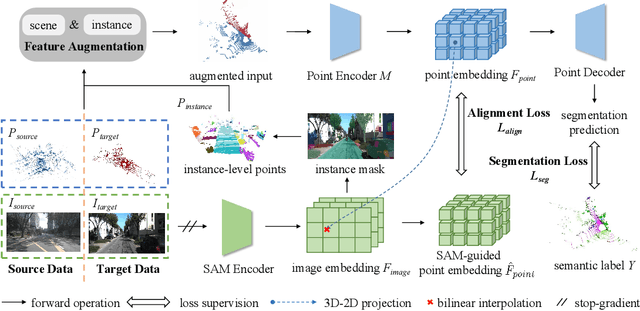
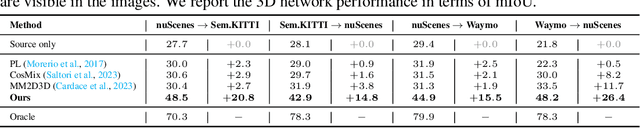
Unsupervised domain adaptation (UDA) in 3D segmentation tasks presents a formidable challenge, primarily stemming from the sparse and unordered nature of point cloud data. Especially for LiDAR point clouds, the domain discrepancy becomes obvious across varying capture scenes, fluctuating weather conditions, and the diverse array of LiDAR devices in use. While previous UDA methodologies have often sought to mitigate this gap by aligning features between source and target domains, this approach falls short when applied to 3D segmentation due to the substantial domain variations. Inspired by the remarkable generalization capabilities exhibited by the vision foundation model, SAM, in the realm of image segmentation, our approach leverages the wealth of general knowledge embedded within SAM to unify feature representations across diverse 3D domains and further solves the 3D domain adaptation problem. Specifically, we harness the corresponding images associated with point clouds to facilitate knowledge transfer and propose an innovative hybrid feature augmentation methodology, which significantly enhances the alignment between the 3D feature space and SAM's feature space, operating at both the scene and instance levels. Our method is evaluated on many widely-recognized datasets and achieves state-of-the-art performance.
Video Language Planning
Oct 16, 2023We are interested in enabling visual planning for complex long-horizon tasks in the space of generated videos and language, leveraging recent advances in large generative models pretrained on Internet-scale data. To this end, we present video language planning (VLP), an algorithm that consists of a tree search procedure, where we train (i) vision-language models to serve as both policies and value functions, and (ii) text-to-video models as dynamics models. VLP takes as input a long-horizon task instruction and current image observation, and outputs a long video plan that provides detailed multimodal (video and language) specifications that describe how to complete the final task. VLP scales with increasing computation budget where more computation time results in improved video plans, and is able to synthesize long-horizon video plans across different robotics domains: from multi-object rearrangement, to multi-camera bi-arm dexterous manipulation. Generated video plans can be translated into real robot actions via goal-conditioned policies, conditioned on each intermediate frame of the generated video. Experiments show that VLP substantially improves long-horizon task success rates compared to prior methods on both simulated and real robots (across 3 hardware platforms).
Transparent Anomaly Detection via Concept-based Explanations
Oct 16, 2023Advancements in deep learning techniques have given a boost to the performance of anomaly detection. However, real-world and safety-critical applications demand a level of transparency and reasoning beyond accuracy. The task of anomaly detection (AD) focuses on finding whether a given sample follows the learned distribution. Existing methods lack the ability to reason with clear explanations for their outcomes. Hence to overcome this challenge, we propose Transparent {A}nomaly Detection {C}oncept {E}xplanations (ACE). ACE is able to provide human interpretable explanations in the form of concepts along with anomaly prediction. To the best of our knowledge, this is the first paper that proposes interpretable by-design anomaly detection. In addition to promoting transparency in AD, it allows for effective human-model interaction. Our proposed model shows either higher or comparable results to black-box uninterpretable models. We validate the performance of ACE across three realistic datasets - bird classification on CUB-200-2011, challenging histopathology slide image classification on TIL-WSI-TCGA, and gender classification on CelebA. We further demonstrate that our concept learning paradigm can be seamlessly integrated with other classification-based AD methods.
Prompt-tuning latent diffusion models for inverse problems
Oct 02, 2023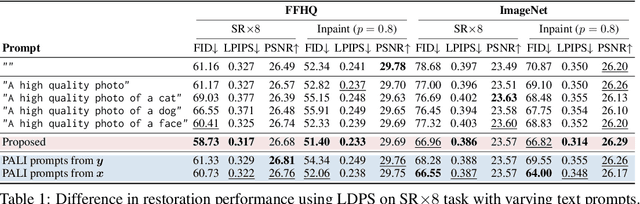
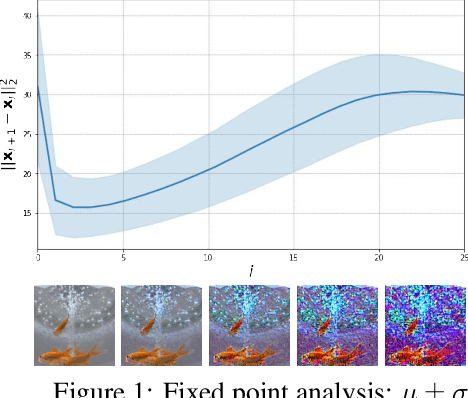
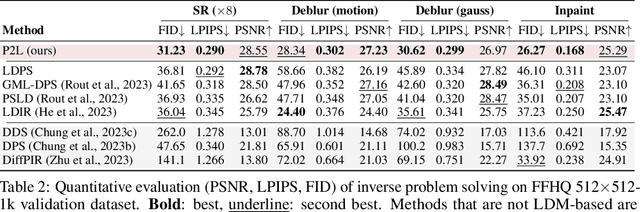

We propose a new method for solving imaging inverse problems using text-to-image latent diffusion models as general priors. Existing methods using latent diffusion models for inverse problems typically rely on simple null text prompts, which can lead to suboptimal performance. To address this limitation, we introduce a method for prompt tuning, which jointly optimizes the text embedding on-the-fly while running the reverse diffusion process. This allows us to generate images that are more faithful to the diffusion prior. In addition, we propose a method to keep the evolution of latent variables within the range space of the encoder, by projection. This helps to reduce image artifacts, a major problem when using latent diffusion models instead of pixel-based diffusion models. Our combined method, called P2L, outperforms both image- and latent-diffusion model-based inverse problem solvers on a variety of tasks, such as super-resolution, deblurring, and inpainting.