 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From CLIP to DINO: Visual Encoders Shout in Multi-modal Large Language Models
Oct 13, 2023
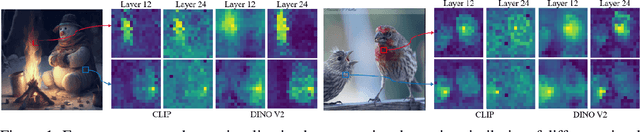
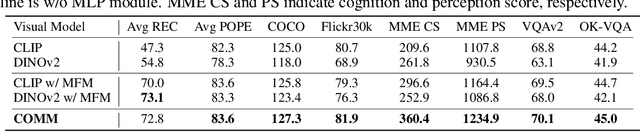
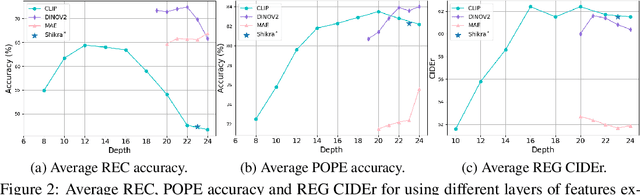
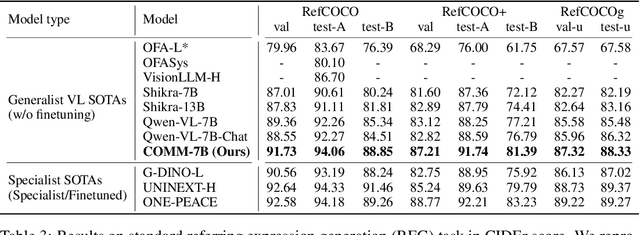
Multi-modal Large Language Models (MLLMs) have made significant strides in expanding the capabilities of Large Language Models (LLMs) through the incorporation of visual perception interfaces. Despite the emergence of exciting applications and the availability of diverse instruction tuning data, existing approaches often rely on CLIP or its variants as the visual branch, and merely extract features from the deep layers. However, these methods lack a comprehensive analysis of the visual encoders in MLLMs. In this paper, we conduct an extensive investigation into the effectiveness of different vision encoders within MLLMs. Our findings reveal that the shallow layer features of CLIP offer particular advantages for fine-grained tasks such as grounding and region understanding. Surprisingly, the vision-only model DINO, which is not pretrained with text-image alignment, demonstrates promising performance as a visual branch within MLLMs. By simply equipping it with an MLP layer for alignment, DINO surpasses CLIP in fine-grained related perception tasks. Building upon these observations, we propose a simple yet effective feature merging strategy, named COMM, that integrates CLIP and DINO with Multi-level features Merging, to enhance the visual capabilities of MLLMs. We evaluate COMM through comprehensive experiments on a wide range of benchmarks, including image captioning, visual question answering, visual grounding, and object hallucination. Experimental results demonstrate the superior performance of COMM compared to existing methods, showcasing its enhanced visual capabilities within MLLMs. Code will be made available at https://github.com/YuchenLiu98/COMM.
No Token Left Behind: Efficient Vision Transformer via Dynamic Token Idling
Oct 09, 2023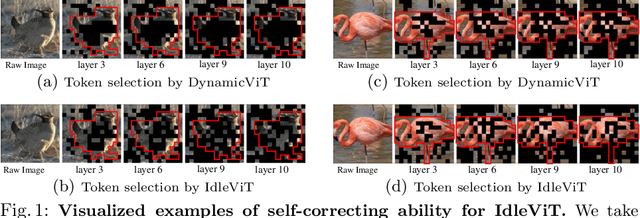
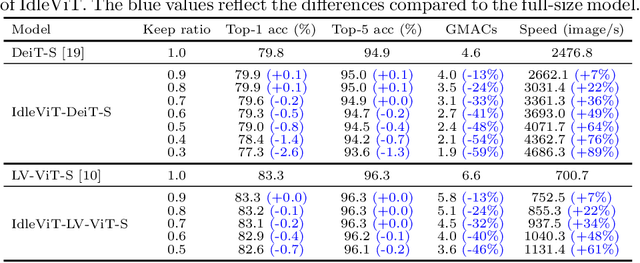
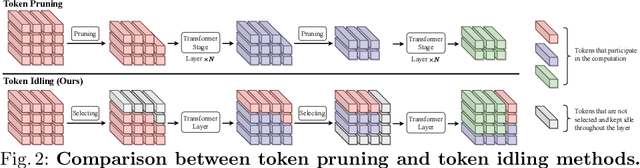

Vision Transformers (ViTs) have demonstrated outstanding performance in computer vision tasks, yet their high computational complexity prevents their deployment in computing resource-constrained environments. Various token pruning techniques have been introduced to alleviate the high computational burden of ViTs by dynamically dropping image tokens. However, some undesirable pruning at early stages may result in permanent loss of image information in subsequent layers, consequently hindering model performance. To address this problem, we propose IdleViT, a dynamic token-idle-based method that achieves an excellent trade-off between performance and efficiency. Specifically, in each layer, IdleViT selects a subset of the image tokens to participate in computations while keeping the rest of the tokens idle and directly passing them to this layer's output. By allowing the idle tokens to be re-selected in the following layers, IdleViT mitigates the negative impact of improper pruning in the early stages. Furthermore, inspired by the normalized graph cut, we devise a token cut loss on the attention map as regularization to improve IdleViT's token selection ability. Our method is simple yet effective and can be extended to pyramid ViTs since no token is completely dropped. Extensive experimental results on various ViT architectures have shown that IdleViT can diminish the complexity of pretrained ViTs by up to 33\% with no more than 0.2\% accuracy decrease on ImageNet, after finetuning for only 30 epochs. Notably, when the keep ratio is 0.5, IdleViT outperforms the state-of-the-art EViT on DeiT-S by 0.5\% higher accuracy and even faster inference speed. The source code is available in the supplementary material.
SDDM: Score-Decomposed Diffusion Models on Manifolds for Unpaired Image-to-Image Translation
Aug 04, 2023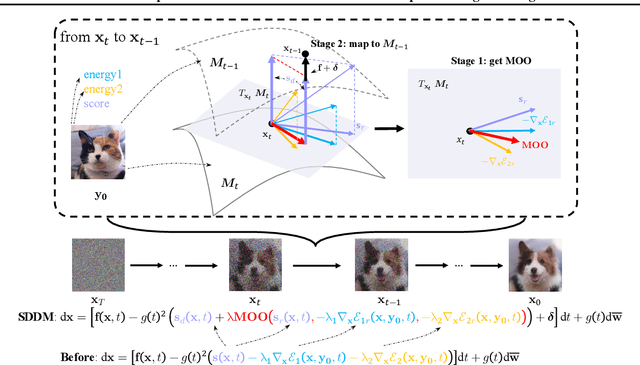
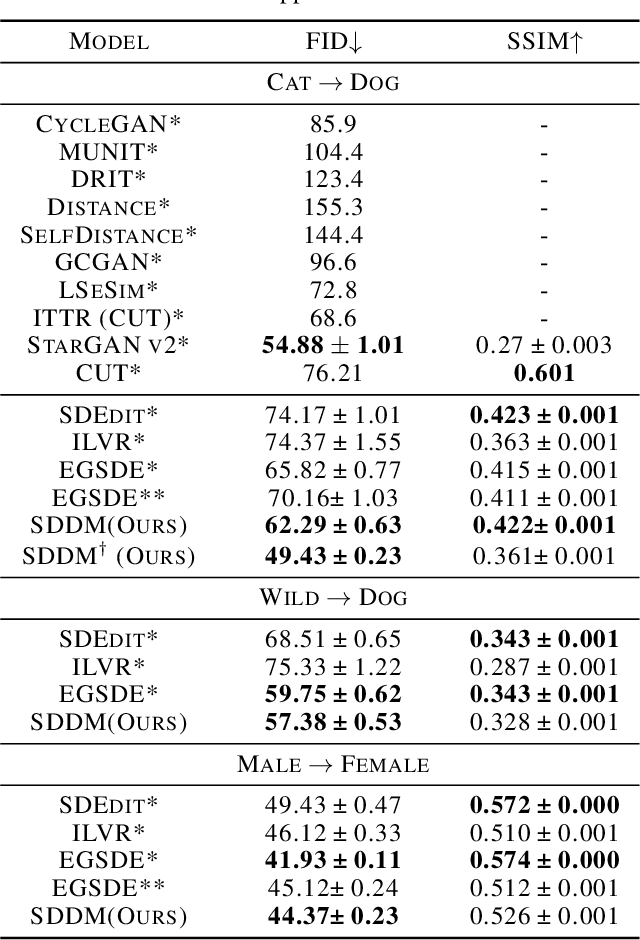
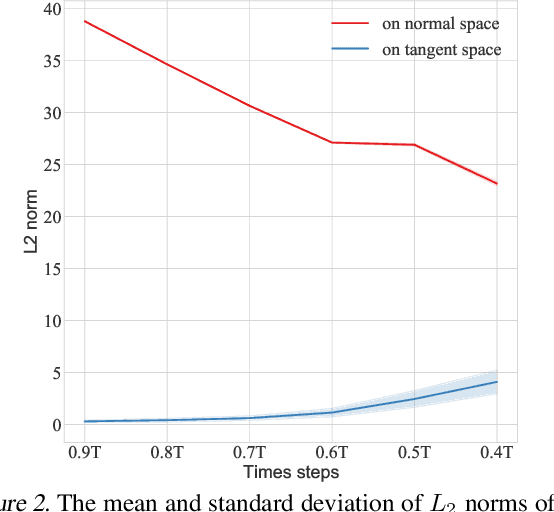

Recent score-based diffusion models (SBDMs) show promising results in unpaired image-to-image translation (I2I). However, existing methods, either energy-based or statistically-based, provide no explicit form of the interfered intermediate generative distributions. This work presents a new score-decomposed diffusion model (SDDM) on manifolds to explicitly optimize the tangled distributions during image generation. SDDM derives manifolds to make the distributions of adjacent time steps separable and decompose the score function or energy guidance into an image ``denoising" part and a content ``refinement" part. To refine the image in the same noise level, we equalize the refinement parts of the score function and energy guidance, which permits multi-objective optimization on the manifold. We also leverage the block adaptive instance normalization module to construct manifolds with lower dimensions but still concentrated with the perturbed reference image. SDDM outperforms existing SBDM-based methods with much fewer diffusion steps on several I2I benchmarks.
Research on Key Technologies of Infrastructure Digitalization based on Multimodal Spatial Data
Oct 22, 2023Since NASA put forward the concept of the digital twin in 2010, many industries have put forward the dynamic goal of digital development, and the transportation industry is also among them. With more and more companies laying out on this virgin land, the digital twin transportation industry has grown rapidly and gradually formed a complete scientific research system. However, under the largely mature framework, there are still many loophole problems that need to be solved. In the process of constructing a road network with point cloud information, we summarize several major features of the point cloud collected by laser scanners and analyze the potential problems of constructing the network, such as misjudging the feature points as ground points and grid voids. On this basis, we reviewed relevant literature and proposed targeted solutions, such as building a point cloud pyramid modeled after the image pyramid, expanding the virtual grid, etc., applying CSF for ground-point cloud extraction, and constructing a road network model using the PTD (progressive density-based filter) algorithm. For the problem of road sign detection, we optimize the remote sensing data in the ground point cloud by enhancing the information density using edge detection, improving the data quality by removing the low intensity points, and achieving 90% accuracy of road text recognition using PaddleOCR and Densenet. As for the real-time digital twin traffic, we design the P2PRN network using the backbone of MPR-GAN for 2D feature generation and SuperGlue for 2D feature matching, rendering the viewpoints according to the matching optimization points, completing the multimodal matching task after several iterations, and successfully calculating the road camera position with 10{\deg} and 15m accuracy.
ASPIRE: Language-Guided Augmentation for Robust Image Classification
Aug 19, 2023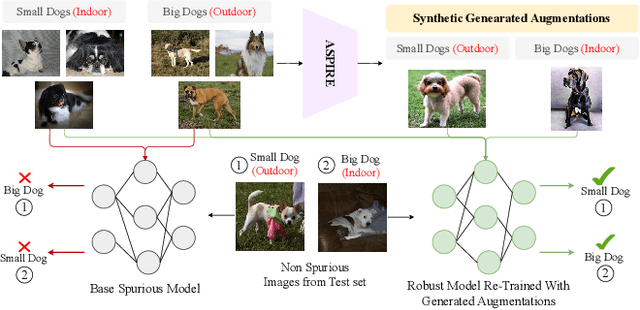
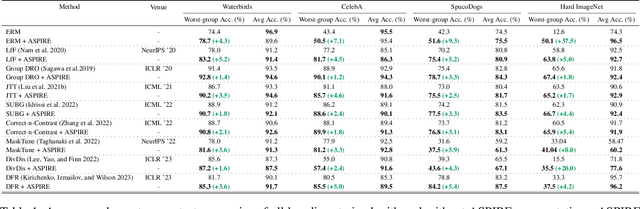
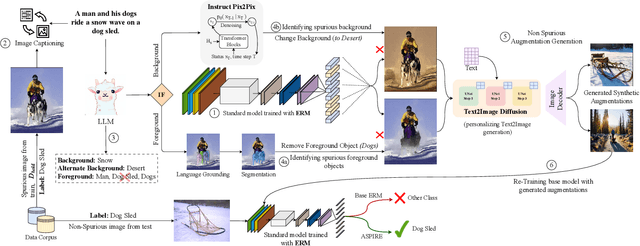
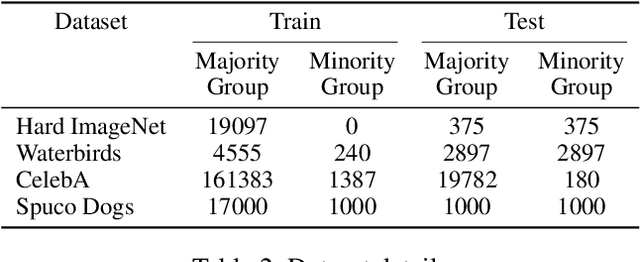
Neural image classifiers can often learn to make predictions by overly relying on non-predictive features that are spuriously correlated with the class labels in the training data. This leads to poor performance in real-world atypical scenarios where such features are absent. Supplementing the training dataset with images without such spurious features can aid robust learning against spurious correlations via better generalization. This paper presents ASPIRE (Language-guided data Augmentation for SPurIous correlation REmoval), a simple yet effective solution for expanding the training dataset with synthetic images without spurious features. ASPIRE, guided by language, generates these images without requiring any form of additional supervision or existing examples. Precisely, we employ LLMs to first extract foreground and background features from textual descriptions of an image, followed by advanced language-guided image editing to discover the features that are spuriously correlated with the class label. Finally, we personalize a text-to-image generation model to generate diverse in-domain images without spurious features. We demonstrate the effectiveness of ASPIRE on 4 datasets, including the very challenging Hard ImageNet dataset, and 9 baselines and show that ASPIRE improves the classification accuracy of prior methods by 1% - 38%. Code soon at: https://github.com/Sreyan88/ASPIRE.
Deep Cardiac MRI Reconstruction with ADMM
Oct 10, 2023
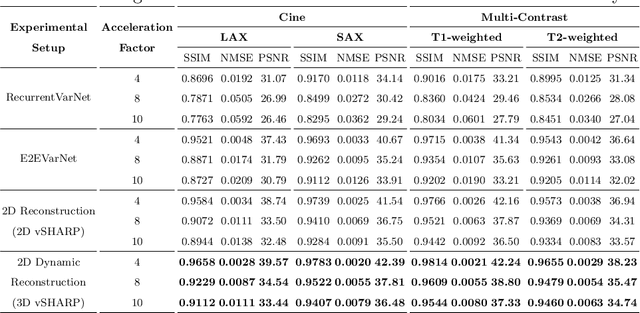


Cardiac magnetic resonance imaging is a valuable non-invasive tool for identifying cardiovascular diseases. For instance, Cine MRI is the benchmark modality for assessing the cardiac function and anatomy. On the other hand, multi-contrast (T1 and T2) mapping has the potential to assess pathologies and abnormalities in the myocardium and interstitium. However, voluntary breath-holding and often arrhythmia, in combination with MRI's slow imaging speed, can lead to motion artifacts, hindering real-time acquisition image quality. Although performing accelerated acquisitions can facilitate dynamic imaging, it induces aliasing, causing low reconstructed image quality in Cine MRI and inaccurate T1 and T2 mapping estimation. In this work, inspired by related work in accelerated MRI reconstruction, we present a deep learning (DL)-based method for accelerated cine and multi-contrast reconstruction in the context of dynamic cardiac imaging. We formulate the reconstruction problem as a least squares regularized optimization task, and employ vSHARP, a state-of-the-art DL-based inverse problem solver, which incorporates half-quadratic variable splitting and the alternating direction method of multipliers with neural networks. We treat the problem in two setups; a 2D reconstruction and a 2D dynamic reconstruction task, and employ 2D and 3D deep learning networks, respectively. Our method optimizes in both the image and k-space domains, allowing for high reconstruction fidelity. Although the target data is undersampled with a Cartesian equispaced scheme, we train our model using both Cartesian and simulated non-Cartesian undersampling schemes to enhance generalization of the model to unseen data. Furthermore, our model adopts a deep neural network to learn and refine the sensitivity maps of multi-coil k-space data. Lastly, our method is jointly trained on both, undersampled cine and multi-contrast data.
Text2Control3D: Controllable 3D Avatar Generation in Neural Radiance Fields using Geometry-Guided Text-to-Image Diffusion Model
Sep 07, 2023
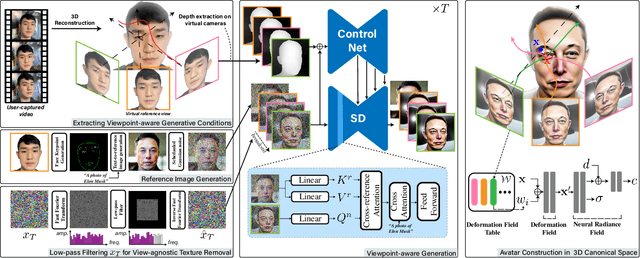

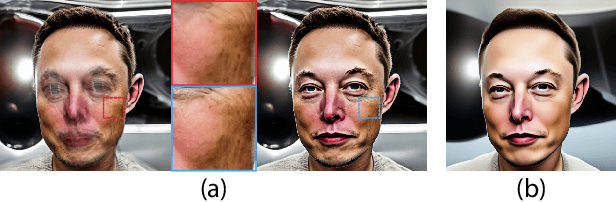
Recent advances in diffusion models such as ControlNet have enabled geometrically controllable, high-fidelity text-to-image generation. However, none of them addresses the question of adding such controllability to text-to-3D generation. In response, we propose Text2Control3D, a controllable text-to-3D avatar generation method whose facial expression is controllable given a monocular video casually captured with hand-held camera. Our main strategy is to construct the 3D avatar in Neural Radiance Fields (NeRF) optimized with a set of controlled viewpoint-aware images that we generate from ControlNet, whose condition input is the depth map extracted from the input video. When generating the viewpoint-aware images, we utilize cross-reference attention to inject well-controlled, referential facial expression and appearance via cross attention. We also conduct low-pass filtering of Gaussian latent of the diffusion model in order to ameliorate the viewpoint-agnostic texture problem we observed from our empirical analysis, where the viewpoint-aware images contain identical textures on identical pixel positions that are incomprehensible in 3D. Finally, to train NeRF with the images that are viewpoint-aware yet are not strictly consistent in geometry, our approach considers per-image geometric variation as a view of deformation from a shared 3D canonical space. Consequently, we construct the 3D avatar in a canonical space of deformable NeRF by learning a set of per-image deformation via deformation field table. We demonstrate the empirical results and discuss the effectiveness of our method.
MS-UNet-v2: Adaptive Denoising Method and Training Strategy for Medical Image Segmentation with Small Training Data
Sep 07, 2023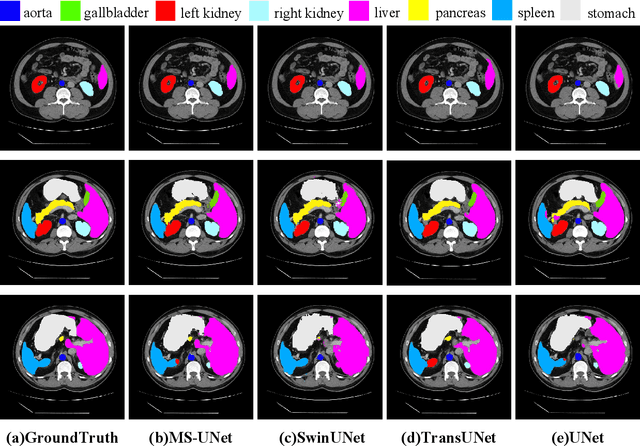
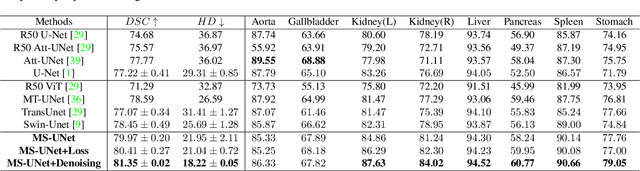
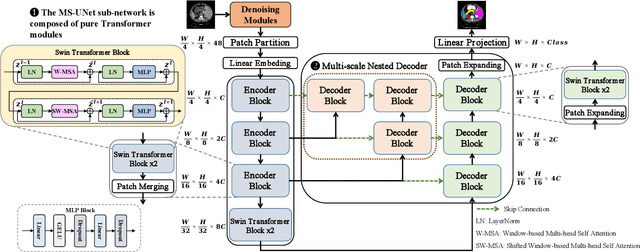

Models based on U-like structures have improved the performance of medical image segmentation. However, the single-layer decoder structure of U-Net is too "thin" to exploit enough information, resulting in large semantic differences between the encoder and decoder parts. Things get worse if the number of training sets of data is not sufficiently large, which is common in medical image processing tasks where annotated data are more difficult to obtain than other tasks. Based on this observation, we propose a novel U-Net model named MS-UNet for the medical image segmentation task in this study. Instead of the single-layer U-Net decoder structure used in Swin-UNet and TransUnet, we specifically design a multi-scale nested decoder based on the Swin Transformer for U-Net. The proposed multi-scale nested decoder structure allows the feature mapping between the decoder and encoder to be semantically closer, thus enabling the network to learn more detailed features. In addition, we propose a novel edge loss and a plug-and-play fine-tuning Denoising module, which not only effectively improves the segmentation performance of MS-UNet, but could also be applied to other models individually. Experimental results show that MS-UNet could effectively improve the network performance with more efficient feature learning capability and exhibit more advanced performance, especially in the extreme case with a small amount of training data, and the proposed Edge loss and Denoising module could significantly enhance the segmentation performance of MS-UNet.
CrowdRec: 3D Crowd Reconstruction from Single Color Images
Oct 10, 2023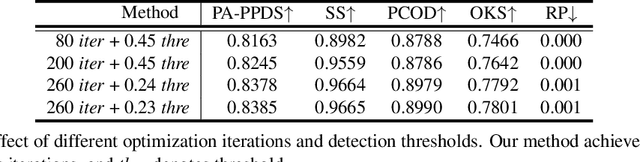
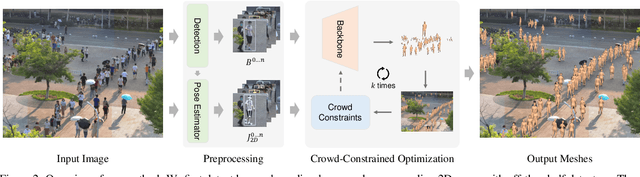


This is a technical report for the GigaCrowd challenge. Reconstructing 3D crowds from monocular images is a challenging problem due to mutual occlusions, server depth ambiguity, and complex spatial distribution. Since no large-scale 3D crowd dataset can be used to train a robust model, the current multi-person mesh recovery methods can hardly achieve satisfactory performance in crowded scenes. In this paper, we exploit the crowd features and propose a crowd-constrained optimization to improve the common single-person method on crowd images. To avoid scale variations, we first detect human bounding-boxes and 2D poses from the original images with off-the-shelf detectors. Then, we train a single-person mesh recovery network using existing in-the-wild image datasets. To promote a more reasonable spatial distribution, we further propose a crowd constraint to refine the single-person network parameters. With the optimization, we can obtain accurate body poses and shapes with reasonable absolute positions from a large-scale crowd image using a single-person backbone. The code will be publicly available at~\url{https://github.com/boycehbz/CrowdRec}.
Geom-Erasing: Geometry-Driven Removal of Implicit Concept in Diffusion Models
Oct 10, 2023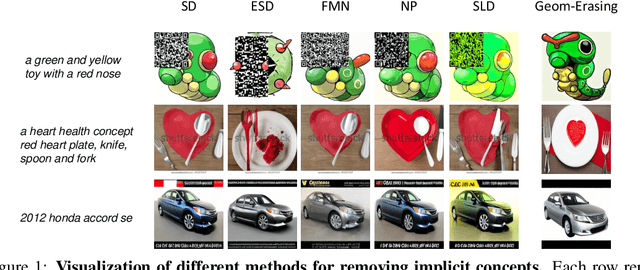

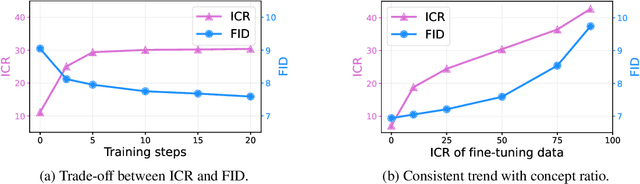
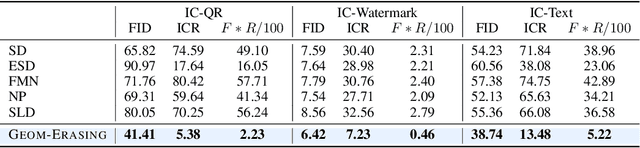
Fine-tuning diffusion models through personalized datasets is an acknowledged method for improving generation quality across downstream tasks, which, however, often inadvertently generates unintended concepts such as watermarks and QR codes, attributed to the limitations in image sources and collecting methods within specific downstream tasks. Existing solutions suffer from eliminating these unintentionally learned implicit concepts, primarily due to the dependency on the model's ability to recognize concepts that it actually cannot discern. In this work, we introduce Geom-Erasing, a novel approach that successfully removes the implicit concepts with either an additional accessible classifier or detector model to encode geometric information of these concepts into text domain. Moreover, we propose Implicit Concept, a novel image-text dataset imbued with three implicit concepts (i.e., watermarks, QR codes, and text) for training and evaluation. Experimental results demonstrate that Geom-Erasing not only identifies but also proficiently eradicates implicit concepts, revealing a significant improvement over the existing methods. The integration of geometric information marks a substantial progression in the precise removal of implicit concepts in diffusion models.