 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LCReg: Long-Tailed Image Classification with Latent Categories based Recognition
Sep 13, 2023
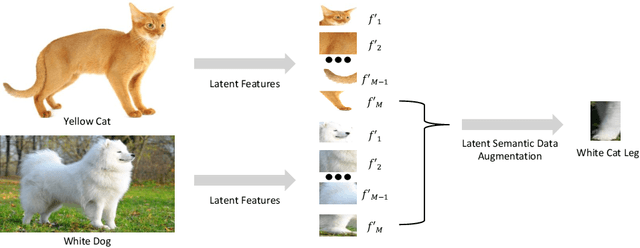
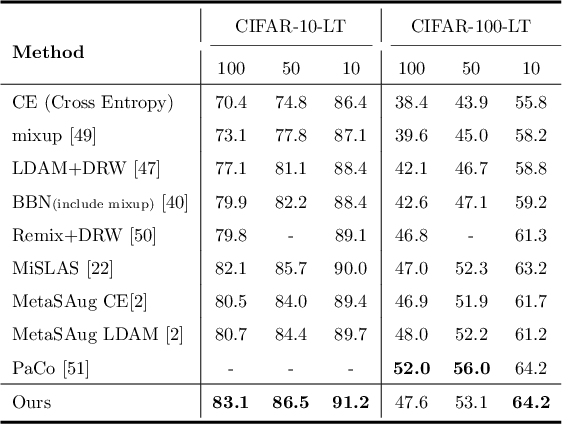
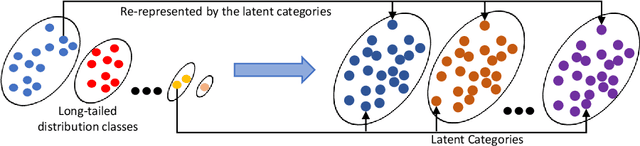
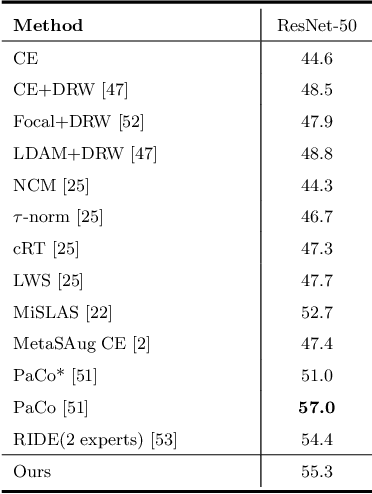
In this work, we tackle the challenging problem of long-tailed image recognition. Previous long-tailed recognition approaches mainly focus on data augmentation or re-balancing strategies for the tail classes to give them more attention during model training. However, these methods are limited by the small number of training images for the tail classes, which results in poor feature representations. To address this issue, we propose the Latent Categories based long-tail Recognition (LCReg) method. Our hypothesis is that common latent features shared by head and tail classes can be used to improve feature representation. Specifically, we learn a set of class-agnostic latent features shared by both head and tail classes, and then use semantic data augmentation on the latent features to implicitly increase the diversity of the training sample. We conduct extensive experiments on five long-tailed image recognition datasets, and the results show that our proposed method significantly improves the baselines.
SSHNN: Semi-Supervised Hybrid NAS Network for Echocardiographic Image Segmentation
Sep 09, 2023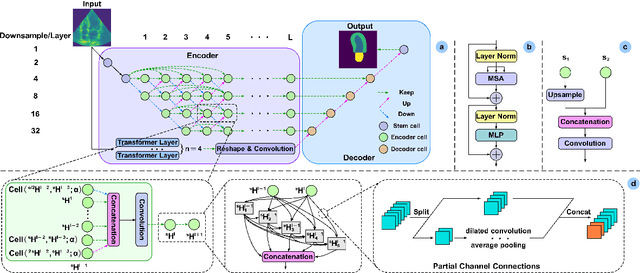
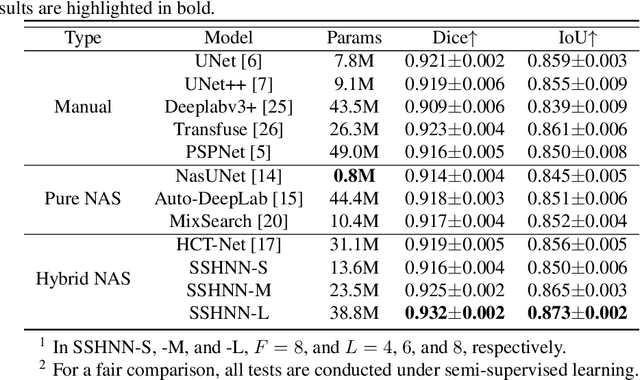

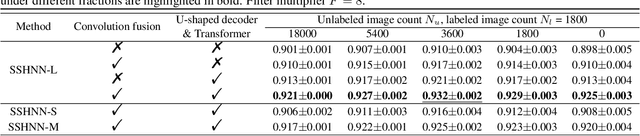
Accurate medical image segmentation especially for echocardiographic images with unmissable noise requires elaborate network design. Compared with manual design, Neural Architecture Search (NAS) realizes better segmentation results due to larger search space and automatic optimization, but most of the existing methods are weak in layer-wise feature aggregation and adopt a ``strong encoder, weak decoder" structure, insufficient to handle global relationships and local details. To resolve these issues, we propose a novel semi-supervised hybrid NAS network for accurate medical image segmentation termed SSHNN. In SSHNN, we creatively use convolution operation in layer-wise feature fusion instead of normalized scalars to avoid losing details, making NAS a stronger encoder. Moreover, Transformers are introduced for the compensation of global context and U-shaped decoder is designed to efficiently connect global context with local features. Specifically, we implement a semi-supervised algorithm Mean-Teacher to overcome the limited volume problem of labeled medical image dataset. Extensive experiments on CAMUS echocardiography dataset demonstrate that SSHNN outperforms state-of-the-art approaches and realizes accurate segmentation. Code will be made publicly available.
Towards Better Multi-modal Keyphrase Generation via Visual Entity Enhancement and Multi-granularity Image Noise Filtering
Sep 09, 2023
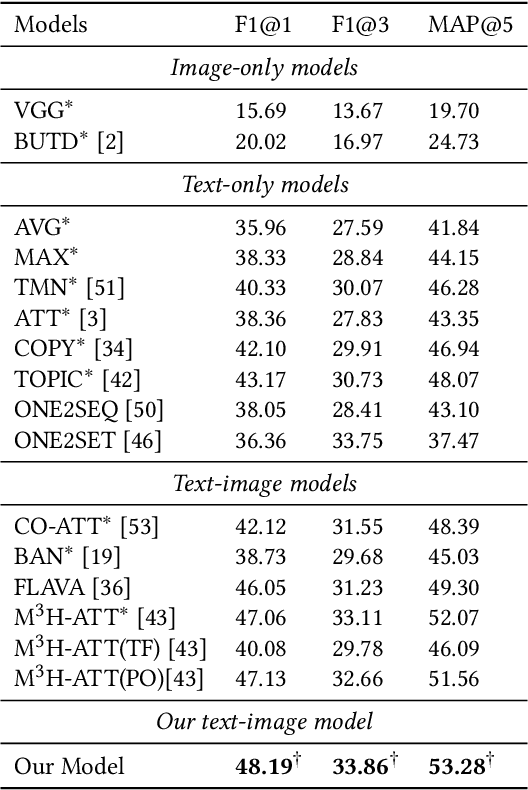
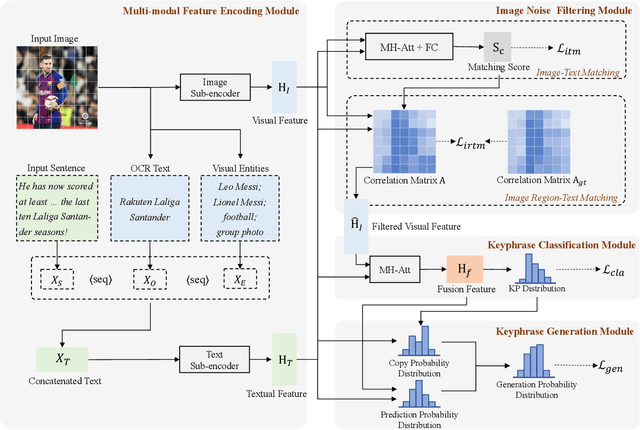
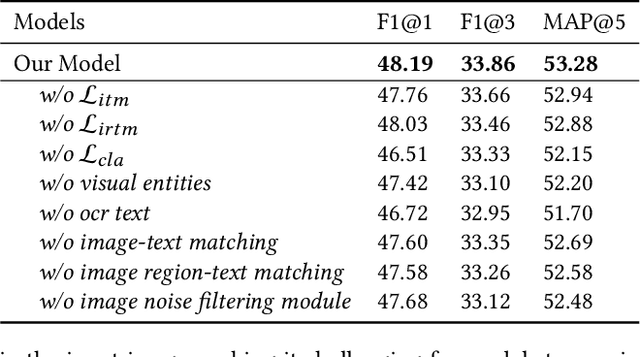
Multi-modal keyphrase generation aims to produce a set of keyphrases that represent the core points of the input text-image pair. In this regard, dominant methods mainly focus on multi-modal fusion for keyphrase generation. Nevertheless, there are still two main drawbacks: 1) only a limited number of sources, such as image captions, can be utilized to provide auxiliary information. However, they may not be sufficient for the subsequent keyphrase generation. 2) the input text and image are often not perfectly matched, and thus the image may introduce noise into the model. To address these limitations, in this paper, we propose a novel multi-modal keyphrase generation model, which not only enriches the model input with external knowledge, but also effectively filters image noise. First, we introduce external visual entities of the image as the supplementary input to the model, which benefits the cross-modal semantic alignment for keyphrase generation. Second, we simultaneously calculate an image-text matching score and image region-text correlation scores to perform multi-granularity image noise filtering. Particularly, we introduce the correlation scores between image regions and ground-truth keyphrases to refine the calculation of the previously-mentioned correlation scores. To demonstrate the effectiveness of our model, we conduct several groups of experiments on the benchmark dataset. Experimental results and in-depth analyses show that our model achieves the state-of-the-art performance. Our code is available on https://github.com/DeepLearnXMU/MM-MKP.
Large-scale Foundation Models and Generative AI for BigData Neuroscience
Oct 27, 2023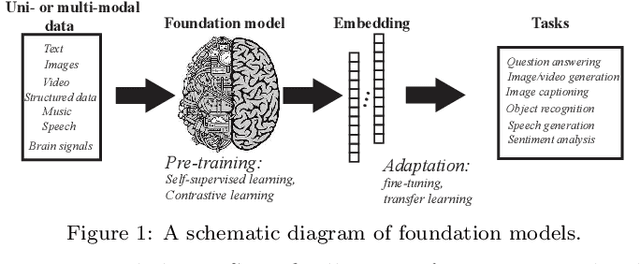

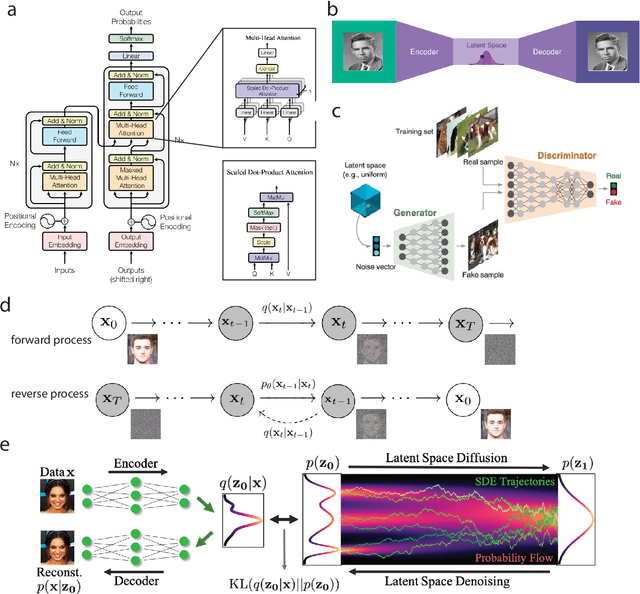

Recent advances in machine learning have made revolutionary breakthroughs in computer games, image and natural language understanding, and scientific discovery. Foundation models and large-scale language models (LLMs) have recently achieved human-like intelligence thanks to BigData. With the help of self-supervised learning (SSL) and transfer learning, these models may potentially reshape the landscapes of neuroscience research and make a significant impact on the future. Here we present a mini-review on recent advances in foundation models and generative AI models as well as their applications in neuroscience, including natural language and speech, semantic memory, brain-machine interfaces (BMIs), and data augmentation. We argue that this paradigm-shift framework will open new avenues for many neuroscience research directions and discuss the accompanying challenges and opportunities.
HWD: A Novel Evaluation Score for Styled Handwritten Text Generation
Oct 31, 2023Styled Handwritten Text Generation (Styled HTG) is an important task in document analysis, aiming to generate text images with the handwriting of given reference images. In recent years, there has been significant progress in the development of deep learning models for tackling this task. Being able to measure the performance of HTG models via a meaningful and representative criterion is key for fostering the development of this research topic. However, despite the current adoption of scores for natural image generation evaluation, assessing the quality of generated handwriting remains challenging. In light of this, we devise the Handwriting Distance (HWD), tailored for HTG evaluation. In particular, it works in the feature space of a network specifically trained to extract handwriting style features from the variable-lenght input images and exploits a perceptual distance to compare the subtle geometric features of handwriting. Through extensive experimental evaluation on different word-level and line-level datasets of handwritten text images, we demonstrate the suitability of the proposed HWD as a score for Styled HTG. The pretrained model used as backbone will be released to ease the adoption of the score, aiming to provide a valuable tool for evaluating HTG models and thus contributing to advancing this important research area.
SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction
Oct 31, 2023Recently video generation has achieved substantial progress with realistic results. Nevertheless, existing AI-generated videos are usually very short clips ("shot-level") depicting a single scene. To deliver a coherent long video ("story-level"), it is desirable to have creative transition and prediction effects across different clips. This paper presents a short-to-long video diffusion model, SEINE, that focuses on generative transition and prediction. The goal is to generate high-quality long videos with smooth and creative transitions between scenes and varying lengths of shot-level videos. Specifically, we propose a random-mask video diffusion model to automatically generate transitions based on textual descriptions. By providing the images of different scenes as inputs, combined with text-based control, our model generates transition videos that ensure coherence and visual quality. Furthermore, the model can be readily extended to various tasks such as image-to-video animation and autoregressive video prediction. To conduct a comprehensive evaluation of this new generative task, we propose three assessing criteria for smooth and creative transition: temporal consistency, semantic similarity, and video-text semantic alignment. Extensive experiments validate the effectiveness of our approach over existing methods for generative transition and prediction, enabling the creation of story-level long videos. Project page: https://vchitect.github.io/SEINE-project/ .
Visual Storytelling with Question-Answer Plans
Oct 17, 2023Visual storytelling aims to generate compelling narratives from image sequences. Existing models often focus on enhancing the representation of the image sequence, e.g., with external knowledge sources or advanced graph structures. Despite recent progress, the stories are often repetitive, illogical, and lacking in detail. To mitigate these issues, we present a novel framework which integrates visual representations with pretrained language models and planning. Our model translates the image sequence into a visual prefix, a sequence of continuous embeddings which language models can interpret. It also leverages a sequence of question-answer pairs as a blueprint plan for selecting salient visual concepts and determining how they should be assembled into a narrative. Automatic and human evaluation on the VIST benchmark (Huang et al., 2016) demonstrates that blueprint-based models generate stories that are more coherent, interesting, and natural compared to competitive baselines and state-of-the-art systems.
Cultural and Linguistic Diversity Improves Visual Representations
Oct 22, 2023Computer vision often treats perception as objective, and this assumption gets reflected in the way that datasets are collected and models are trained. For instance, image descriptions in different languages are typically assumed to be translations of the same semantic content. However, work in cross-cultural psychology and linguistics has shown that individuals differ in their visual perception depending on their cultural background and the language they speak. In this paper, we demonstrate significant differences in semantic content across languages in both dataset and model-produced captions. When data is multilingual as opposed to monolingual, captions have higher semantic coverage on average, as measured by scene graph, embedding, and linguistic complexity. For example, multilingual captions have on average 21.8% more objects, 24.5% more relations, and 27.1% more attributes than a set of monolingual captions. Moreover, models trained on content from different languages perform best against test data from those languages, while those trained on multilingual content perform consistently well across all evaluation data compositions. Our research provides implications for how diverse modes of perception can improve image understanding.
SAMUS: Adapting Segment Anything Model for Clinically-Friendly and Generalizable Ultrasound Image Segmentation
Sep 13, 2023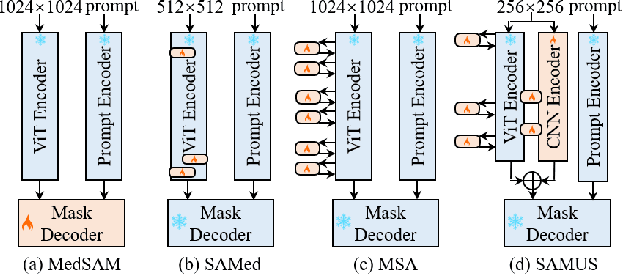
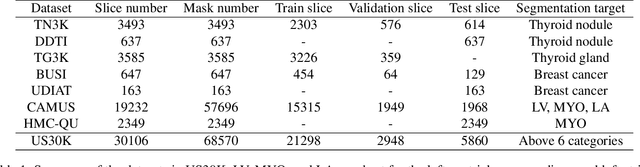
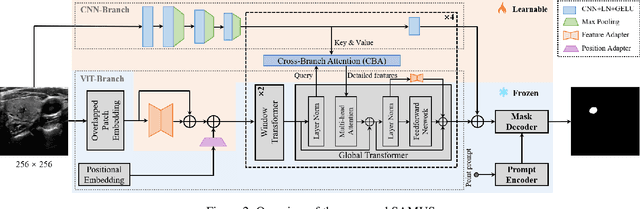
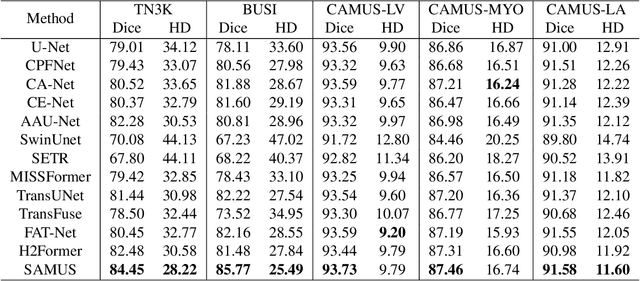
Segment anything model (SAM), an eminent universal image segmentation model, has recently gathered considerable attention within the domain of medical image segmentation. Despite the remarkable performance of SAM on natural images, it grapples with significant performance degradation and limited generalization when confronted with medical images, particularly with those involving objects of low contrast, faint boundaries, intricate shapes, and diminutive sizes. In this paper, we propose SAMUS, a universal model tailored for ultrasound image segmentation. In contrast to previous SAM-based universal models, SAMUS pursues not only better generalization but also lower deployment cost, rendering it more suitable for clinical applications. Specifically, based on SAM, a parallel CNN branch is introduced to inject local features into the ViT encoder through cross-branch attention for better medical image segmentation. Then, a position adapter and a feature adapter are developed to adapt SAM from natural to medical domains and from requiring large-size inputs (1024x1024) to small-size inputs (256x256) for more clinical-friendly deployment. A comprehensive ultrasound dataset, comprising about 30k images and 69k masks and covering six object categories, is collected for verification. Extensive comparison experiments demonstrate SAMUS's superiority against the state-of-the-art task-specific models and universal foundation models under both task-specific evaluation and generalization evaluation. Moreover, SAMUS is deployable on entry-level GPUs, as it has been liberated from the constraints of long sequence encoding. The code, data, and models will be released at https://github.com/xianlin7/SAMUS.
RigNet++: Efficient Repetitive Image Guided Network for Depth Completion
Sep 01, 2023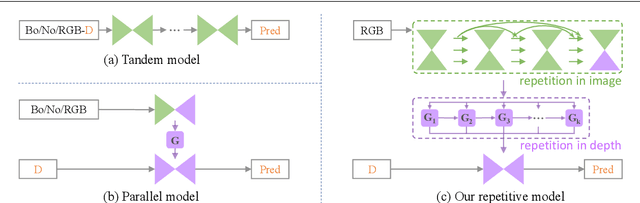
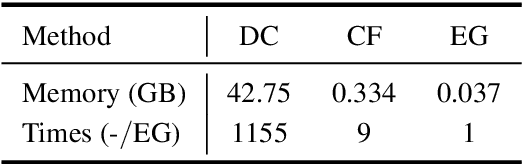
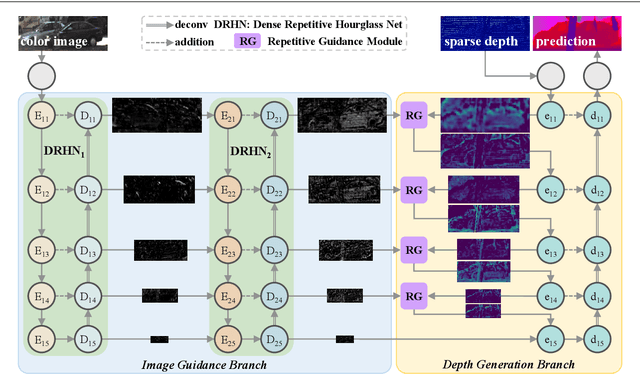

Depth completion aims to recover dense depth maps from sparse ones, where color images are often used to facilitate this task. Recent depth methods primarily focus on image guided learning frameworks. However, blurry guidance in the image and unclear structure in the depth still impede their performance. To tackle these challenges, we explore an efficient repetitive design in our image guided network to gradually and sufficiently recover depth values. Specifically, the efficient repetition is embodied in both the image guidance branch and depth generation branch. In the former branch, we design a dense repetitive hourglass network to extract discriminative image features of complex environments, which can provide powerful contextual instruction for depth prediction. In the latter branch, we introduce a repetitive guidance module based on dynamic convolution, in which an efficient convolution factorization is proposed to reduce the complexity while modeling high-frequency structures progressively. Extensive experiments indicate that our approach achieves superior or competitive results on KITTI, VKITTI, NYUv2, 3D60, and Matterport3D datasets.