 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAIL: Region-Aware Instructive Learning for Semi-Supervised Tooth Segmentation in CBCT
May 06, 2025Semi-supervised learning has become a compelling approach for 3D tooth segmentation from CBCT scans, where labeled data is minimal. However, existing methods still face two persistent challenges: limited corrective supervision in structurally ambiguous or mislabeled regions during supervised training and performance degradation caused by unreliable pseudo-labels on unlabeled data. To address these problems, we propose Region-Aware Instructive Learning (RAIL), a dual-group dual-student, semi-supervised framework. Each group contains two student models guided by a shared teacher network. By alternating training between the two groups, RAIL promotes intergroup knowledge transfer and collaborative region-aware instruction while reducing overfitting to the characteristics of any single model. Specifically, RAIL introduces two instructive mechanisms. Disagreement-Focused Supervision (DFS) Controller improves supervised learning by instructing predictions only within areas where student outputs diverge from both ground truth and the best student, thereby concentrating supervision on structurally ambiguous or mislabeled areas. In the unsupervised phase, Confidence-Aware Learning (CAL) Modulator reinforces agreement in regions with high model certainty while reducing the effect of low-confidence predictions during training. This helps prevent our model from learning unstable patterns and improves the overall reliability of pseudo-labels. Extensive experiments on four CBCT tooth segmentation datasets show that RAIL surpasses state-of-the-art methods under limited annotation. Our code will be available at https://github.com/Tournesol-Saturday/RAIL.
SSHNN: Semi-Supervised Hybrid NAS Network for Echocardiographic Image Segmentation
Sep 09, 2023



Accurate medical image segmentation especially for echocardiographic images with unmissable noise requires elaborate network design. Compared with manual design, Neural Architecture Search (NAS) realizes better segmentation results due to larger search space and automatic optimization, but most of the existing methods are weak in layer-wise feature aggregation and adopt a ``strong encoder, weak decoder" structure, insufficient to handle global relationships and local details. To resolve these issues, we propose a novel semi-supervised hybrid NAS network for accurate medical image segmentation termed SSHNN. In SSHNN, we creatively use convolution operation in layer-wise feature fusion instead of normalized scalars to avoid losing details, making NAS a stronger encoder. Moreover, Transformers are introduced for the compensation of global context and U-shaped decoder is designed to efficiently connect global context with local features. Specifically, we implement a semi-supervised algorithm Mean-Teacher to overcome the limited volume problem of labeled medical image dataset. Extensive experiments on CAMUS echocardiography dataset demonstrate that SSHNN outperforms state-of-the-art approaches and realizes accurate segmentation. Code will be made publicly available.
Registration-Free Hybrid Learning Empowers Simple Multimodal Imaging System for High-quality Fusion Detection
Jul 07, 2023



Multimodal fusion detection always places high demands on the imaging system and image pre-processing, while either a high-quality pre-registration system or image registration processing is costly. Unfortunately, the existing fusion methods are designed for registered source images, and the fusion of inhomogeneous features, which denotes a pair of features at the same spatial location that expresses different semantic information, cannot achieve satisfactory performance via these methods. As a result, we propose IA-VFDnet, a CNN-Transformer hybrid learning framework with a unified high-quality multimodal feature matching module (AKM) and a fusion module (WDAF), in which AKM and DWDAF work in synergy to perform high-quality infrared-aware visible fusion detection, which can be applied to smoke and wildfire detection. Furthermore, experiments on the M3FD dataset validate the superiority of the proposed method, with IA-VFDnet achieving the best detection performance than other state-of-the-art methods under conventional registered conditions. In addition, the first unregistered multimodal smoke and wildfire detection benchmark is openly available in this letter.
Breast Cancer Immunohistochemical Image Generation: a Benchmark Dataset and Challenge Review
May 05, 2023



For invasive breast cancer, immunohistochemical (IHC) techniques are often used to detect the expression level of human epidermal growth factor receptor-2 (HER2) in breast tissue to formulate a precise treatment plan. From the perspective of saving manpower, material and time costs, directly generating IHC-stained images from hematoxylin and eosin (H&E) stained images is a valuable research direction. Therefore, we held the breast cancer immunohistochemical image generation challenge, aiming to explore novel ideas of deep learning technology in pathological image generation and promote research in this field. The challenge provided registered H&E and IHC-stained image pairs, and participants were required to use these images to train a model that can directly generate IHC-stained images from corresponding H&E-stained images. We selected and reviewed the five highest-ranking methods based on their PSNR and SSIM metrics, while also providing overviews of the corresponding pipelines and implementations. In this paper, we further analyze the current limitations in the field of breast cancer immunohistochemical image generation and forecast the future development of this field. We hope that the released dataset and the challenge will inspire more scholars to jointly study higher-quality IHC-stained image generation.
Evaluation of Look-ahead Economic Dispatch Using Reinforcement Learning
Sep 21, 2022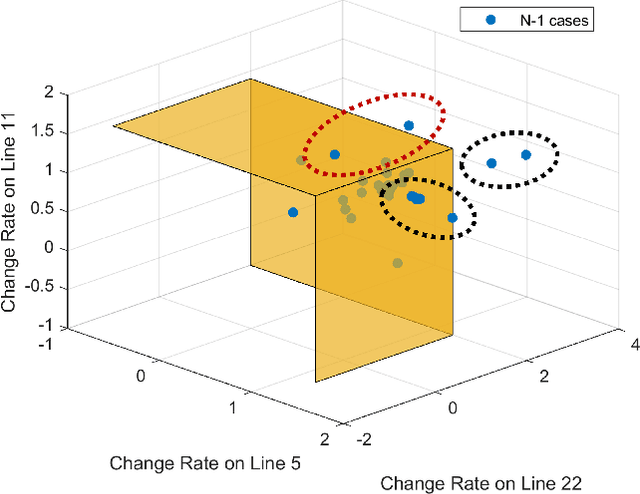
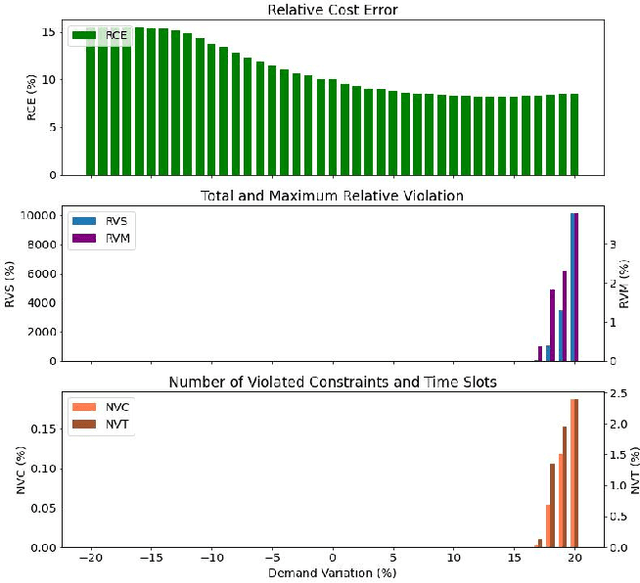

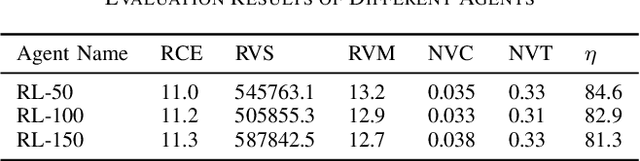
Modern power systems are experiencing a variety of challenges driven by renewable energy, which calls for developing novel dispatch methods such as reinforcement learning (RL). Evaluation of these methods as well as the RL agents are largely under explored. In this paper, we propose an evaluation approach to analyze the performance of RL agents in a look-ahead economic dispatch scheme. This approach is conducted by scanning multiple operational scenarios. In particular, a scenario generation method is developed to generate the network scenarios and demand scenarios for evaluation, and network structures are aggregated according to the change rates of power flow. Then several metrics are defined to evaluate the agents' performance from the perspective of economy and security. In the case study, we use a modified IEEE 30-bus system to illustrate the effectiveness of the proposed evaluation approach, and the simulation results reveal good and rapid adaptation to different scenarios. The comparison between different RL agents is also informative to offer advice for a better design of the learning strategies.
Construct Informative Triplet with Two-stage Hard-sample Generation
Dec 04, 2021In this paper, we propose a robust sample generation scheme to construct informative triplets. The proposed hard sample generation is a two-stage synthesis framework that produces hard samples through effective positive and negative sample generators in two stages, respectively. The first stage stretches the anchor-positive pairs with piecewise linear manipulation and enhances the quality of generated samples by skillfully designing a conditional generative adversarial network to lower the risk of mode collapse. The second stage utilizes an adaptive reverse metric constraint to generate the final hard samples. Extensive experiments on several benchmark datasets verify that our method achieves superior performance than the existing hard-sample generation algorithms. Besides, we also find that our proposed hard sample generation method combining the existing triplet mining strategies can further boost the deep metric learning performance.
PML: Progressive Margin Loss for Long-tailed Age Classification
Mar 03, 2021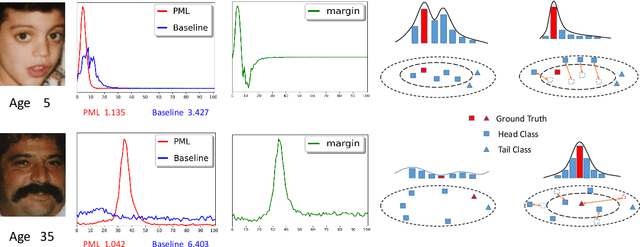
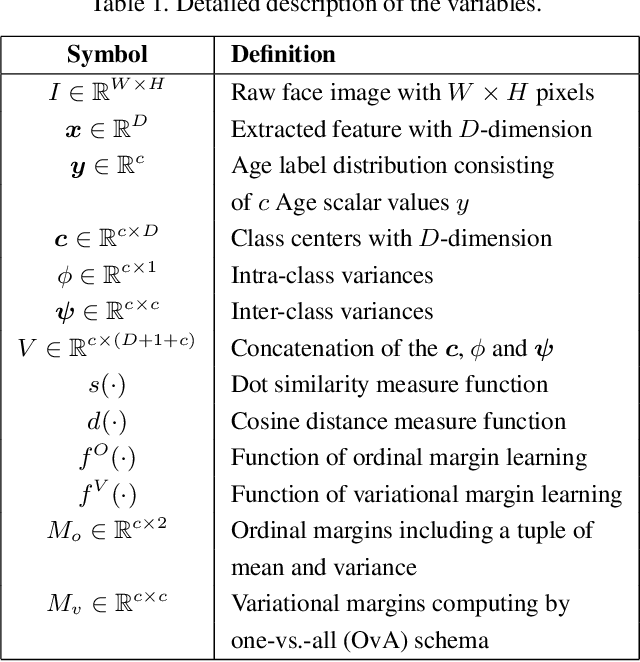
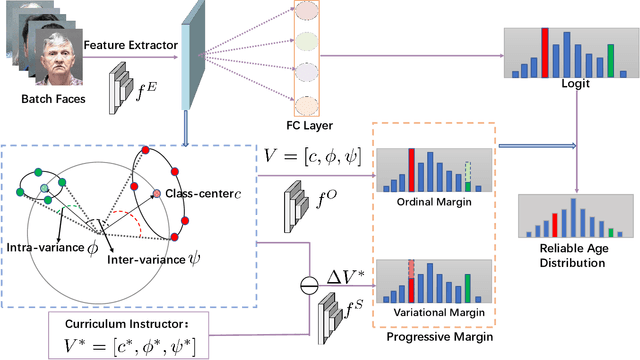
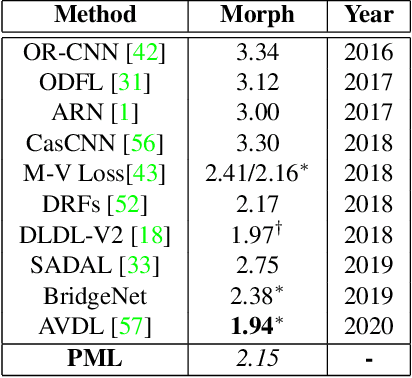
In this paper, we propose a progressive margin loss (PML) approach for unconstrained facial age classification. Conventional methods make strong assumption on that each class owns adequate instances to outline its data distribution, likely leading to bias prediction where the training samples are sparse across age classes. Instead, our PML aims to adaptively refine the age label pattern by enforcing a couple of margins, which fully takes in the in-between discrepancy of the intra-class variance, inter-class variance and class center. Our PML typically incorporates with the ordinal margin and the variational margin, simultaneously plugging in the globally-tuned deep neural network paradigm. More specifically, the ordinal margin learns to exploit the correlated relationship of the real-world age labels. Accordingly, the variational margin is leveraged to minimize the influence of head classes that misleads the prediction of tailed samples. Moreover, our optimization carefully seeks a series of indicator curricula to achieve robust and efficient model training. Extensive experimental results on three face aging datasets demonstrate that our PML achieves compelling performance compared to state of the arts. Code will be made publicly.