 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dolphins: Multimodal Language Model for Driving
Dec 01, 2023
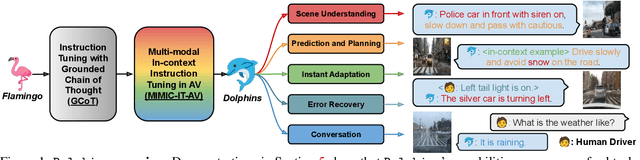


The quest for fully autonomous vehicles (AVs) capable of navigating complex real-world scenarios with human-like understanding and responsiveness. In this paper, we introduce Dolphins, a novel vision-language model architected to imbibe human-like abilities as a conversational driving assistant. Dolphins is adept at processing multimodal inputs comprising video (or image) data, text instructions, and historical control signals to generate informed outputs corresponding to the provided instructions. Building upon the open-sourced pretrained Vision-Language Model, OpenFlamingo, we first enhance Dolphins's reasoning capabilities through an innovative Grounded Chain of Thought (GCoT) process. Then we tailored Dolphins to the driving domain by constructing driving-specific instruction data and conducting instruction tuning. Through the utilization of the BDD-X dataset, we designed and consolidated four distinct AV tasks into Dolphins to foster a holistic understanding of intricate driving scenarios. As a result, the distinctive features of Dolphins are characterized into two dimensions: (1) the ability to provide a comprehensive understanding of complex and long-tailed open-world driving scenarios and solve a spectrum of AV tasks, and (2) the emergence of human-like capabilities including gradient-free instant adaptation via in-context learning and error recovery via reflection.
Text-Guided 3D Face Synthesis -- From Generation to Editing
Dec 01, 2023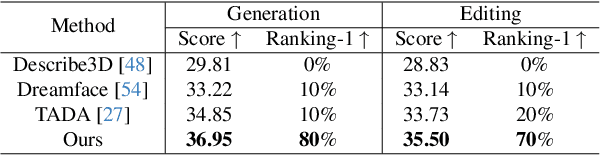
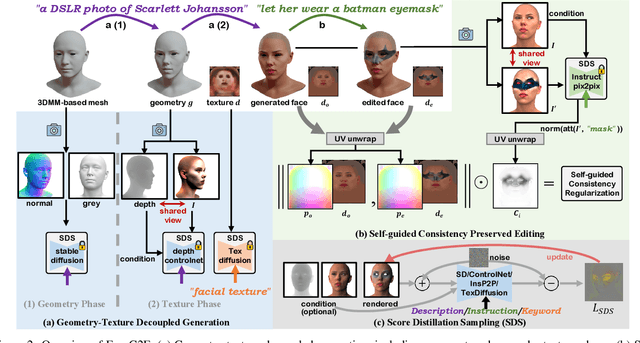
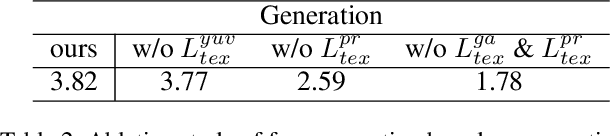
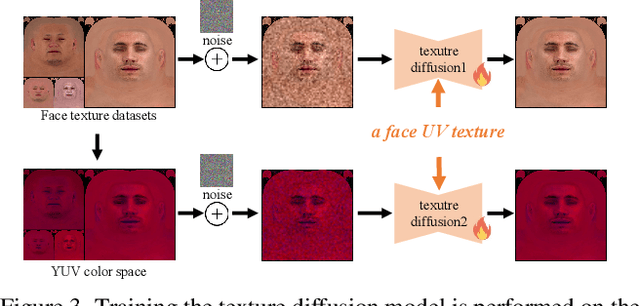
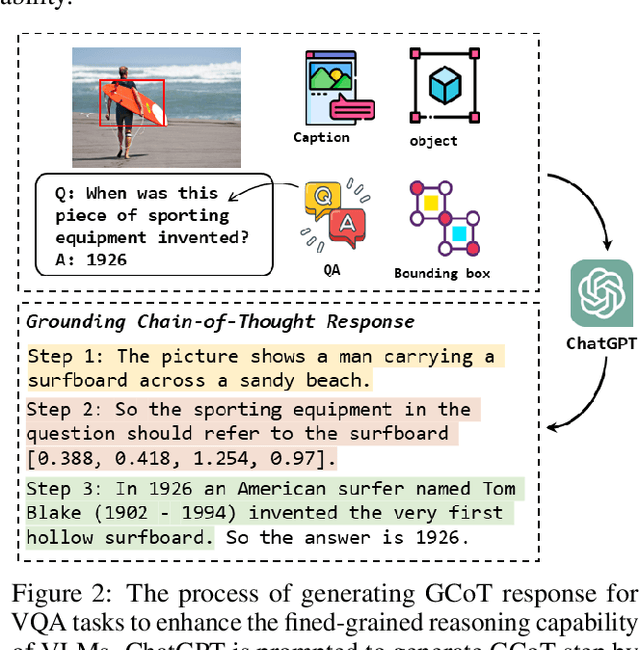
Text-guided 3D face synthesis has achieved remarkable results by leveraging text-to-image (T2I) diffusion models. However, most existing works focus solely on the direct generation, ignoring the editing, restricting them from synthesizing customized 3D faces through iterative adjustments. In this paper, we propose a unified text-guided framework from face generation to editing. In the generation stage, we propose a geometry-texture decoupled generation to mitigate the loss of geometric details caused by coupling. Besides, decoupling enables us to utilize the generated geometry as a condition for texture generation, yielding highly geometry-texture aligned results. We further employ a fine-tuned texture diffusion model to enhance texture quality in both RGB and YUV space. In the editing stage, we first employ a pre-trained diffusion model to update facial geometry or texture based on the texts. To enable sequential editing, we introduce a UV domain consistency preservation regularization, preventing unintentional changes to irrelevant facial attributes. Besides, we propose a self-guided consistency weight strategy to improve editing efficacy while preserving consistency. Through comprehensive experiments, we showcase our method's superiority in face synthesis. Project page: https://faceg2e.github.io/.
Self-Supervised Learning of Whole and Component-Based Semantic Representations for Person Re-Identification
Dec 01, 2023Interactive Segmentation Models (ISMs) like the Segment Anything Model have significantly improved various computer vision tasks, yet their application to Person Re-identification (ReID) remains limited. On the other hand, existing semantic pre-training models for ReID often have limitations like predefined parsing ranges or coarse semantics. Additionally, ReID and Clothes-Changing ReID (CC-ReID) are usually treated separately due to their different domains. This paper investigates whether utilizing precise human-centric semantic representation can boost the ReID performance and improve the generalization among various ReID tasks. We propose SemReID, a self-supervised ReID model that leverages ISMs for adaptive part-based semantic extraction, contributing to the improvement of ReID performance. SemReID additionally refines its semantic representation through techniques such as image masking and KoLeo regularization. Evaluation across three types of ReID datasets -- standard ReID, CC-ReID, and unconstrained ReID -- demonstrates superior performance compared to state-of-the-art methods. In addition, recognizing the scarcity of large person datasets with fine-grained semantics, we introduce the novel LUPerson-Part dataset to assist ReID methods in acquiring the fine-grained part semantics for robust performance.
A Probabilistic Method to Predict Classifier Accuracy on Larger Datasets given Small Pilot Data
Nov 29, 2023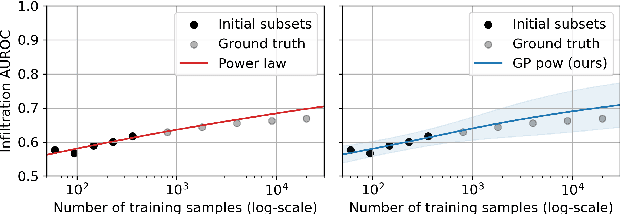

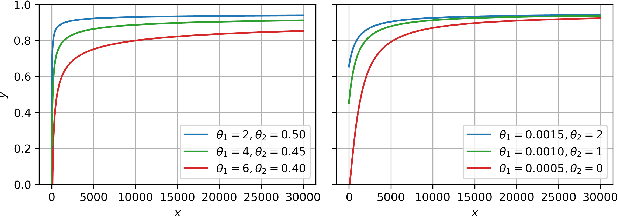
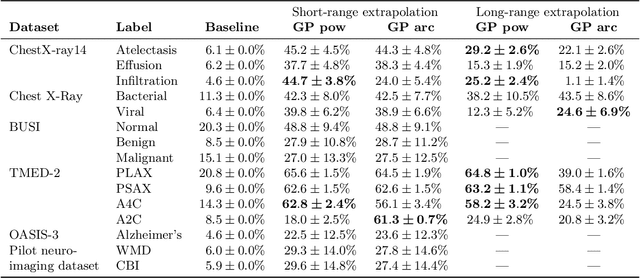
Practitioners building classifiers often start with a smaller pilot dataset and plan to grow to larger data in the near future. Such projects need a toolkit for extrapolating how much classifier accuracy may improve from a 2x, 10x, or 50x increase in data size. While existing work has focused on finding a single "best-fit" curve using various functional forms like power laws, we argue that modeling and assessing the uncertainty of predictions is critical yet has seen less attention. In this paper, we propose a Gaussian process model to obtain probabilistic extrapolations of accuracy or similar performance metrics as dataset size increases. We evaluate our approach in terms of error, likelihood, and coverage across six datasets. Though we focus on medical tasks and image modalities, our open source approach generalizes to any kind of classifier.
Computer Vision for Increased Operative Efficiency via Identification of Instruments in the Neurosurgical Operating Room: A Proof-of-Concept Study
Dec 03, 2023Objectives Computer vision (CV) is a field of artificial intelligence that enables machines to interpret and understand images and videos. CV has the potential to be of assistance in the operating room (OR) to track surgical instruments. We built a CV algorithm for identifying surgical instruments in the neurosurgical operating room as a potential solution for surgical instrument tracking and management to decrease surgical waste and opening of unnecessary tools. Methods We collected 1660 images of 27 commonly used neurosurgical instruments. Images were labeled using the VGG Image Annotator and split into 80% training and 20% testing sets in order to train a U-Net Convolutional Neural Network using 5-fold cross validation. Results Our U-Net achieved a tool identification accuracy of 80-100% when distinguishing 25 classes of instruments, with 19/25 classes having accuracy over 90%. The model performance was not adequate for sub classifying Adson, Gerald, and Debakey forceps, which had accuracies of 60-80%. Conclusions We demonstrated the viability of using machine learning to accurately identify surgical instruments. Instrument identification could help optimize surgical tray packing, decrease tool usage and waste, decrease incidence of instrument misplacement events, and assist in timing of routine instrument maintenance. More training data will be needed to increase accuracy across all surgical instruments that would appear in a neurosurgical operating room. Such technology has the potential to be used as a method to be used for proving what tools are truly needed in each type of operation allowing surgeons across the world to do more with less.
Consistency Prototype Module and Motion Compensation for Few-Shot Action Recognition (CLIP-CP$\mathbf{M^2}$C)
Dec 02, 2023Recently, few-shot action recognition has significantly progressed by learning the feature discriminability and designing suitable comparison methods. Still, there are the following restrictions. (a) Previous works are mainly based on visual mono-modal. Although some multi-modal works use labels as supplementary to construct prototypes of support videos, they can not use this information for query videos. The labels are not used efficiently. (b) Most of the works ignore the motion feature of video, although the motion features are essential for distinguishing. We proposed a Consistency Prototype and Motion Compensation Network(CLIP-CP$M^2$C) to address these issues. Firstly, we use the CLIP for multi-modal few-shot action recognition with the text-image comparison for domain adaption. Secondly, in order to make the amount of information between the prototype and the query more similar, we propose a novel method to compensate for the text(prompt) information of query videos when text(prompt) does not exist, which depends on a Consistency Loss. Thirdly, we use the differential features of the adjacent frames in two directions as the motion features, which explicitly embeds the network with motion dynamics. We also apply the Consistency Loss to the motion features. Extensive experiments on standard benchmark datasets demonstrate that the proposed method can compete with state-of-the-art results. Our code is available at the URL: https://github.com/xxx/xxx.git.
StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D
Dec 02, 2023In the realm of text-to-3D generation, utilizing 2D diffusion models through score distillation sampling (SDS) frequently leads to issues such as blurred appearances and multi-faced geometry, primarily due to the intrinsically noisy nature of the SDS loss. Our analysis identifies the core of these challenges as the interaction among noise levels in the 2D diffusion process, the architecture of the diffusion network, and the 3D model representation. To overcome these limitations, we present StableDreamer, a methodology incorporating three advances. First, inspired by InstructNeRF2NeRF, we formalize the equivalence of the SDS generative prior and a simple supervised L2 reconstruction loss. This finding provides a novel tool to debug SDS, which we use to show the impact of time-annealing noise levels on reducing multi-faced geometries. Second, our analysis shows that while image-space diffusion contributes to geometric precision, latent-space diffusion is crucial for vivid color rendition. Based on this observation, StableDreamer introduces a two-stage training strategy that effectively combines these aspects, resulting in high-fidelity 3D models. Third, we adopt an anisotropic 3D Gaussians representation, replacing Neural Radiance Fields (NeRFs), to enhance the overall quality, reduce memory usage during training, and accelerate rendering speeds, and better capture semi-transparent objects. StableDreamer reduces multi-face geometries, generates fine details, and converges stably.
Deep Learning as a Method for Inversion of NMR Signals
Nov 22, 2023The concept of deep learning is employed for the inversion of NMR signals and it is shown that NMR signal inversion can be considered as an image-to-image regression problem, which can be treated with a convolutional neural net. It is further outlined, that inversion through deep learning provides a clear efficiency and usability advantage compared to regularization techniques such as Tikhonov and modified total generalized variation (MTGV), because no hyperparemeter selection prior to reconstruction is necessary. The inversion network is applied to simulated NMR signals and the results compared with Tikhonov- and MTGV-regularization. The comparison shows that inversion via deep learning is significantly faster than the latter regularization methods and also outperforms both regularization techniques in nearly all instances.
Adversarial Prompt Tuning for Vision-Language Models
Nov 19, 2023With the rapid advancement of multimodal learning, pre-trained Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capacities in bridging the gap between visual and language modalities. However, these models remain vulnerable to adversarial attacks, particularly in the image modality, presenting considerable security risks. This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in VLMs. AdvPT innovatively leverages learnable text prompts and aligns them with adversarial image embeddings, to address the vulnerabilities inherent in VLMs without the need for extensive parameter training or modification of the model architecture. We demonstrate that AdvPT improves resistance against white-box and black-box adversarial attacks and exhibits a synergistic effect when combined with existing image-processing-based defense techniques, further boosting defensive capabilities. Comprehensive experimental analyses provide insights into adversarial prompt tuning, a novel paradigm devoted to improving resistance to adversarial images through textual input modifications, paving the way for future robust multimodal learning research. These findings open up new possibilities for enhancing the security of VLMs. Our code will be available upon publication of the paper.
EMIT-Diff: Enhancing Medical Image Segmentation via Text-Guided Diffusion Model
Oct 19, 2023Large-scale, big-variant, and high-quality data are crucial for developing robust and successful deep-learning models for medical applications since they potentially enable better generalization performance and avoid overfitting. However, the scarcity of high-quality labeled data always presents significant challenges. This paper proposes a novel approach to address this challenge by developing controllable diffusion models for medical image synthesis, called EMIT-Diff. We leverage recent diffusion probabilistic models to generate realistic and diverse synthetic medical image data that preserve the essential characteristics of the original medical images by incorporating edge information of objects to guide the synthesis process. In our approach, we ensure that the synthesized samples adhere to medically relevant constraints and preserve the underlying structure of imaging data. Due to the random sampling process by the diffusion model, we can generate an arbitrary number of synthetic images with diverse appearances. To validate the effectiveness of our proposed method, we conduct an extensive set of medical image segmentation experiments on multiple datasets, including Ultrasound breast (+13.87%), CT spleen (+0.38%), and MRI prostate (+7.78%), achieving significant improvements over the baseline segmentation methods. For the first time, to our best knowledge, the promising results demonstrate the effectiveness of our EMIT-Diff for medical image segmentation tasks and show the feasibility of introducing a first-ever text-guided diffusion model for general medical image segmentation tasks. With carefully designed ablation experiments, we investigate the influence of various data augmentation ratios, hyper-parameter settings, patch size for generating random merging mask settings, and combined influence with different network architectures.